术语
首先在Seata里边有这么几个概念,
TC、TM、RM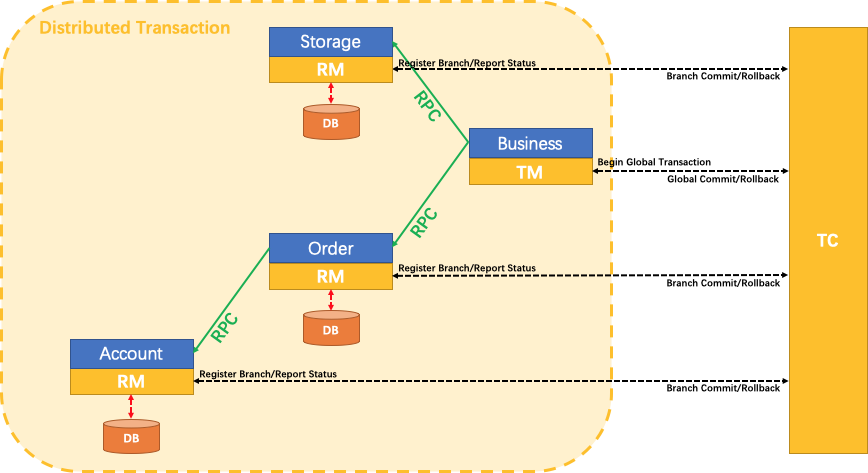
TC 事务协调者
我们现在假设是下单业务,下单业务要调用我们三个远程服务。
那通过TC 就要协调这三个远程服务到底是都要提交还是都要回滚。
这个 TC 类似于我们二阶提交协议的那个 Transaction Manager(总事务管理器),
TM 事务管理器
它是Business 这一块的,负责控制我们的总事务
相当于我们要做 Business 方法的时候,它要调用三个远程方法。所以 Business 有一个事务管理器,它来负责开启我们的总事务。
RM 资源管理器
资源管理器是在各个的服务里边,相当于它直接和当前服务的数据库来交互。
相当于我们在 spring 单体模式下使用的@Transactional,可以把它称为资源管理器。
所以现在这三者的角色就是
- TC 来负责协调全局。
- TM 是来控制我们这个大事务。
- 每一个微服务里边自己的事务是用 RM 这个叫资源管理器来控制的。
工作流程
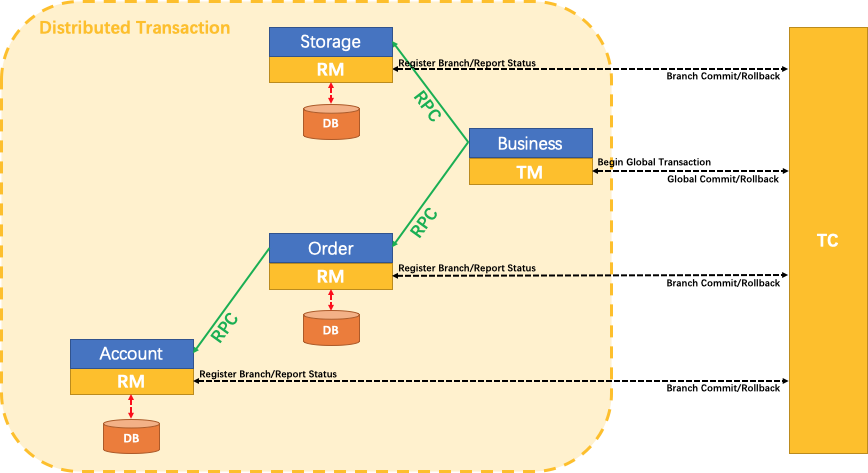
我们现在要执行一个大下单业务 Business
大下单业务的 TM(事务管理器)先会告诉 TC(事务协调者)它要准备开启一个全局事务。
事务协调者就知道,TM(事务管理器)现在可能要跨服务开一个全局的事务,要么这些都成功,要么这些都失败。
只要TM(事务管理器)告诉了这个TC(事务协调者),它要开始全局事务了,那接下来它调用第一个微服务的事务方法的时候。
我们这个 Storage 服务就会在 TC(事务协调者)注册一下,我们称为分支。我们把这个事务称为分支事务,就是最上面 Storage 那个
相当于它的 RM(资源管理器)会告诉 TC(事务协调者),它有一个分支事务,并且它要实时汇报它的事务状态,它这个分支是提交成功还是失败回滚, TC(事务协调者)都能实时的知道。
然后我们这个大业务,调完了它第一个远程服务,
接下来调我们第二个远程服务 Order
第二个远程服务的 RM(资源管理器)也会在 TC(事务协调者)注册自己的分支事务,并且实时给TC(事务协调者)汇报它当前的事务状态。
接下来要调到第三个远程服务 Account,然后第三个微服务的RM(资源管理器)也会在 TC(事务协调者)注册自己的分支事务,并且汇报状态。
那这样就好了。
大事务只要一开启,每调一个小事务,TC(事务协调者)都知道这个小事务成了还是败了。
假设我们调到最后一个,最后一个这个小事务给 TC(事务协调者)汇报状态。说执行失败了,我得回滚了。
所以呢第四个分支事务相当于回滚了,回滚了怎么办?
TC(事务协调者)知道我们的大事务,已经调成功两个了。前两个事务都已经提交了,但是第三个事务给回滚了,TC(事务协调者)就会命令前两个事务也回滚。
这就是他们三者的关系。
小结
TM(事务管理器)开一个全局事务。
TC(事务协调者)来协调我们这个全局事务里边牵扯到的各个分支事务。
AT 模式下的 UNDO_LOG
每一个要使用分布式事务的数据库都需要一个 UNDO_LOG 表。
我们如果使用 Seata AT(Auto Transaction)模式,自动事务模式。
我们要建一个 UNDO_LOG 表,翻译过来就是回滚日志表。
回滚日志就是将失败状态的数据恢复到失败之前的状态,至于这个 AT 模式,那是因为这个回滚是自动做的。
因为我们只要在 Seata AT 模式下,TC(事务协调者) 只要调分支事务,成功之后就会提交事务,但是如果有一个分支事务失败了,失败的这个可以自己回滚,但是已提交的事务要怎么回滚?
已提交的事务要怎么回滚?
已提交的我们只能做一个反向补偿。
这个反向补偿,我们以前如果使用 TCC 模式,我们自己可以写一段代码,比如我们之前加二了,我们调用自己写的反向补偿代码给它减二。
但是我们现在是自动模式,用户不用写这个代码,不写这个代码怎么办呢?
所以我们就需要一个UNDO_LOG 表,每一个微服务都需要。
比如 Storage 服务,在它的数据库里边,除了它正常的业务表以外,它还需要有一个回滚日志表。
相当于它无论干了什么,比如说给这条记录加二了,都得在回滚日志里边记录一下:给谁谁谁刚才加二了。
那如果它都提交成功了,当执行到最后一个的时候,TC 又让它回滚,怎么办呢?
它其实没法回滚,只能说恢复以前的状态。我们加二前的状态呢是减二,那我呢就给你再减二,恢复以前的状态。
这一块它是怎么做的?
它是利用魔改数据库,相当于有魔法一样把这个数据库直接改掉。
比如:我们这有条加二的记录,原来它的值是八,加二以后变成十,结果被人给回滚了。
它是这么做的,它先在UNDO_LOG 里面记录了一下这条记录没改变之前值,比如是八。
如果它失败回滚了,那它就回过头把我们数据库里边的这个十再改回去,改成八。
所以它相当于在我们事务执行之前,它先读取一下这个状态是几,最后再改回来,这就是它的这种模式,AT 模式。
使用 Seata 0.7.1
我们使用 Seata 的时候,只需要使用一个注解@GlobalTransactional,将全局事务标在我们业务方法上就行了。
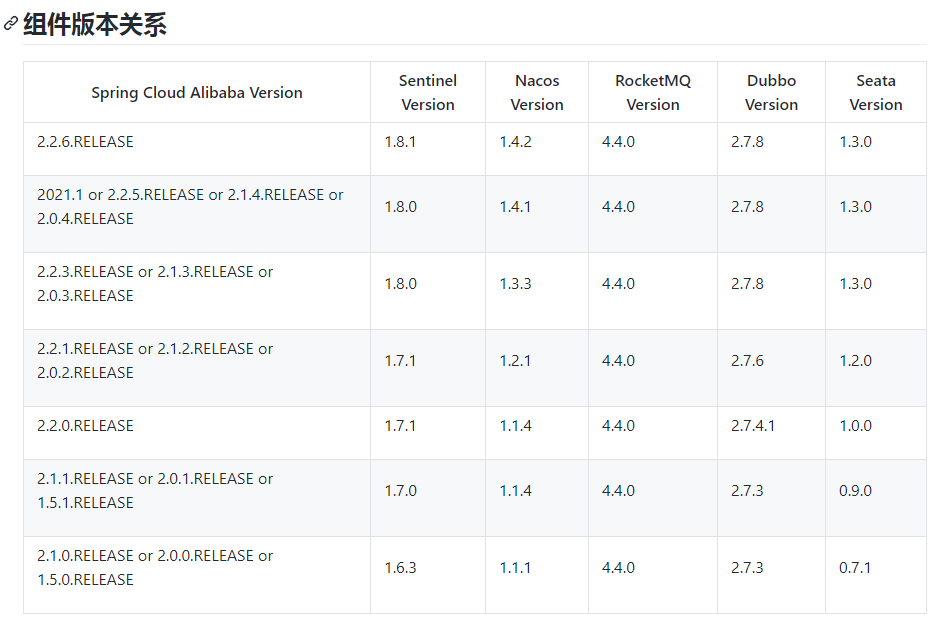
选择 seata 版本之前切记要与 cloud alibaba 版本匹配,版本说明,否则会出现很多问题!
一、添加 UNDO_LOG 表
每一个要使用分布式事务的数据库都需要一个 UNDO_LOG 表。
CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
二、Linux 安装 Seata 0.7.1
cd /opt
# 创建文件夹
mkdir seata
# 进入
cd seata
# 下载
wget https://github.com/seata/seata/releases/download/v0.7.1/seata-server-0.7.1.tar.gz
# 解压
tar -xvf seata-server-0.1.1.tar.gz
# 修改配置
vi conf/registry.conf
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
serverAddr = "192.168.2.190:8848"
namespace = "public"
cluster = "default"
}
}
# 切换到bin目录
cd bin/
# 启动 seata-server
sh seata-server.sh -p 8091 -h 192.168.2.190
查看注册中心,发现服务已经添加进来了,启动成功!
三、导入依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
四、代理数据源
所有想要用到分布式事务的微服务中使用seata DataSourceProxy代理自己的数据源
@Configuration
public class SeataConfig {
@Autowired
DataSourceProperties dataSourceProperties;
@Bean
public DataSource dataSource(DataSourceProperties dataSourceProperties){
HikariDataSource dataSource = dataSourceProperties.initializeDataSourceBuilder()
.type(HikariDataSource.class).build();
if (StringUtils.hasText(dataSourceProperties.getName())) {
dataSource.setPoolName(dataSourceProperties.getName());
}
return new DataSourceProxy(dataSource);
}
}
五、添加配置文件
每个要使用分布式事务的微服务服务中都要添加这两个文件
registry.conf
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
serverAddr = "192.168.2.190:8848"
namespace = "public"
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:1001/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
file.conf
vgroup_mapping需要修改
举例:在vgroup_mapping.后面追加你的服务名gulimall-ware再加-fescar-service-group
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#vgroup->rgroup
vgroup_mapping.gulimall-ware-fescar-service-group = "default"
#only support single node
default.grouplist = "192.168.2.190:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
}
## transaction log store
store {
## store mode: file、db
mode = "file"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
committing-retry-delay = 30
asyn-committing-retry-delay = 30
rollbacking-retry-delay = 30
timeout-retry-delay = 30
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}
六、启动项目
给分布式大事务的入口方法,添加全局事务@GlobalTransactional,即可实现分布式事务管理
结论
使用 Seata 来控制事务,它在执行过程中,首先有几大步,要获取全局锁、还有其它各种锁,要隔离都是要使用各种锁机制。
这样的话,做一个事务的时候,我们会发现它要加超多的锁,一加锁以后,相当于把并发变成串行化了。
这样的话,当系统高并发起来的时候,假设是订单系统,如果都这么做,所有人可能都得等待上一个订单下完,才能下下一个订单,这样整个系统就没法用了。

若有收获,就点个赞吧
0 人点赞
