为什么会有分布式事务
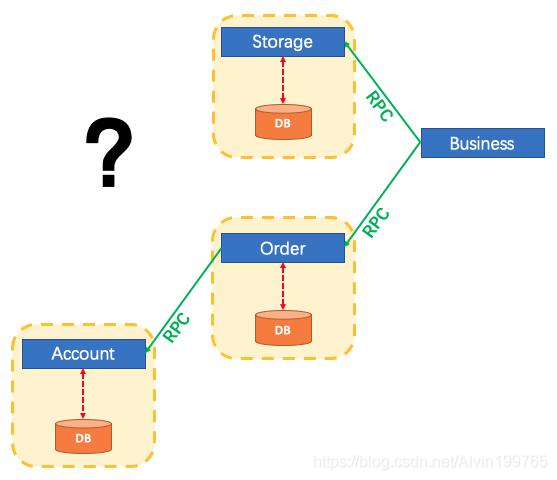
我们还是以我们之前的下单场景为例。比如我们来看这张图。这张图跟我们之前的下单场景稍微有些不一样,我们就以它为例,
我们现在有一个业务叫下单,就是我们的 business 这个业务,然后它首先要调用我们三个功能。第一个是我们扣库存,然后接下来是保存订单,订单保存完了我们可能还要扣减积分。
只有这三个功能同时调用成功了,我们这个单才算是下成功。
如果是我们以前的单体应用,我们将这三处代码全部写在一个系统里边。而且我们全部连想的是一个数据库。
那这样的话,我们使用本地事务就可以非常方便的控制住。只要有一个失败,大家全体回滚。
但是正是由于我们分布式系统的出现。
由于我们这个业务太大,我们不可能将所有业务全写进一个项目里边。所以我们拆分成了好多微服务。比如我们的库存服务,我们的订单服务。还有我们的用户账户服务,
我们现在拆分了三个服务,而且每个服务还是连自己的数据库操作自己的数据,还互相没有关系。
再加上分布式系统之间部署还可能不在一块。
比如我们这个库存服务在一号机器,订单在二号,账户在三号机器。
那这样我们想要完成整个下单逻辑,我们就要远程调用这三个机器的各个方法。
分布式系统带来的问题
问题一
比如机器宕机,我们二号执行完了,想要调用我们三号业务。但是三号业务这个机器宕机了,那一宕机以后,会出现什么问题呢?
其实是二号,它不能感知到我们这个三号到底是执行成了还是败了。
如果是我们在二号调三号之前,它给炸了,那还好,我们二号知道它连不上三号,那把自己也回滚一下。
问题二
但是如果是我们二号调了三号机器的代码,有请求给它发过去了,然后三号机器代码可能都执行完了,正好在执行完的那一刻就要给它返回的时候,它给炸了。
那这样的话,二号机器就永远等不到它的返回,会认为它已经宕机了。
但是此时的二号机器,它是没办法知道我们三号机器到底是执行成了还是执行败了。
就算我们需要查三号机器成了还是败了,它都宕机了,也没法查了。
所以现在可能会由于机器宕机的问题,我们想要同步它们之间的状态不好同步。
因为我们想要让一个失败,大家全体失败,来做一个事务。
问题三
或者由于网络异常,比如三号机器一切都执行成功了。然后把所有的成功消息都返回给订单服务了
结果我们消息刚发出去,老鼠把网线咬断了。那我们这个消息传不出去了,怎么办?
所以现在我们这个二号还是不知道我们这个三号机器它到底执行的状态怎么样。
那它们三个就无法同步我们的事务状态,
再加上我们分布式系统里边如果引入了更多中间件,一些消息中间件。造成的丢失乱序,包括一些数据的发送错误,我们经常类型转换转成了这个空指针异常的类型转不过来的。
但实际人家远程。执行成功了,只是你业务代码出了问题,
还有我们一些不可靠的这些网络 tCP 连接等等。
只要是我们这些网络的问题、机器服务节点故障的问题都会导致我们某一个机器的状态,它的这个成功失败,别的机器可能没办法感知。
那这样想要在分布式系统里边做事务,想协调一号、二号、三号机器,它们整体要么都回滚,要么都成功,这就非常难。
这就是我们的分布式事务。
只要我们有微服务,我们的业务太大,我们拆成微服务部署在了不同机器。
那我们在后来的业务开发中,我们一定百分百避免不了我们的分布式事务。
这个东西就是躲得过初一,躲不过十五。我们可以提前设计一些,比如我们前几个业务,我们通过自己的设计,我们把数据库揉在一起或者怎么着,我们终于躲过了分布式事务,但在后边一些复杂的业务又出现远程调用。我们总是躲不过。
我们不可能将所有的代码全部放在一个项目里边。因为现在的项目的规模都太大了,没有任何机器能负担住一个大型项目的运行。
所以只要是微服务架构,分布式事务就是无法避免的。
如何解决分布式事务?
分布式事务出现的原因就是我们节点之间互相的状态不能同步,包括网络状况问题。
我们这些数据互相感知不到,现在我们就希望有人能协调这个事情。
当然我们做这个之前我们先来考虑一下我们分布式系统里边的一些定理。
它既然能叫定理,就是我们不能打破的一个理论。
那我们在分布式系统里边有一个叫 CAP 原则,也叫 CAP 定理。

若有收获,就点个赞吧
0 人点赞
