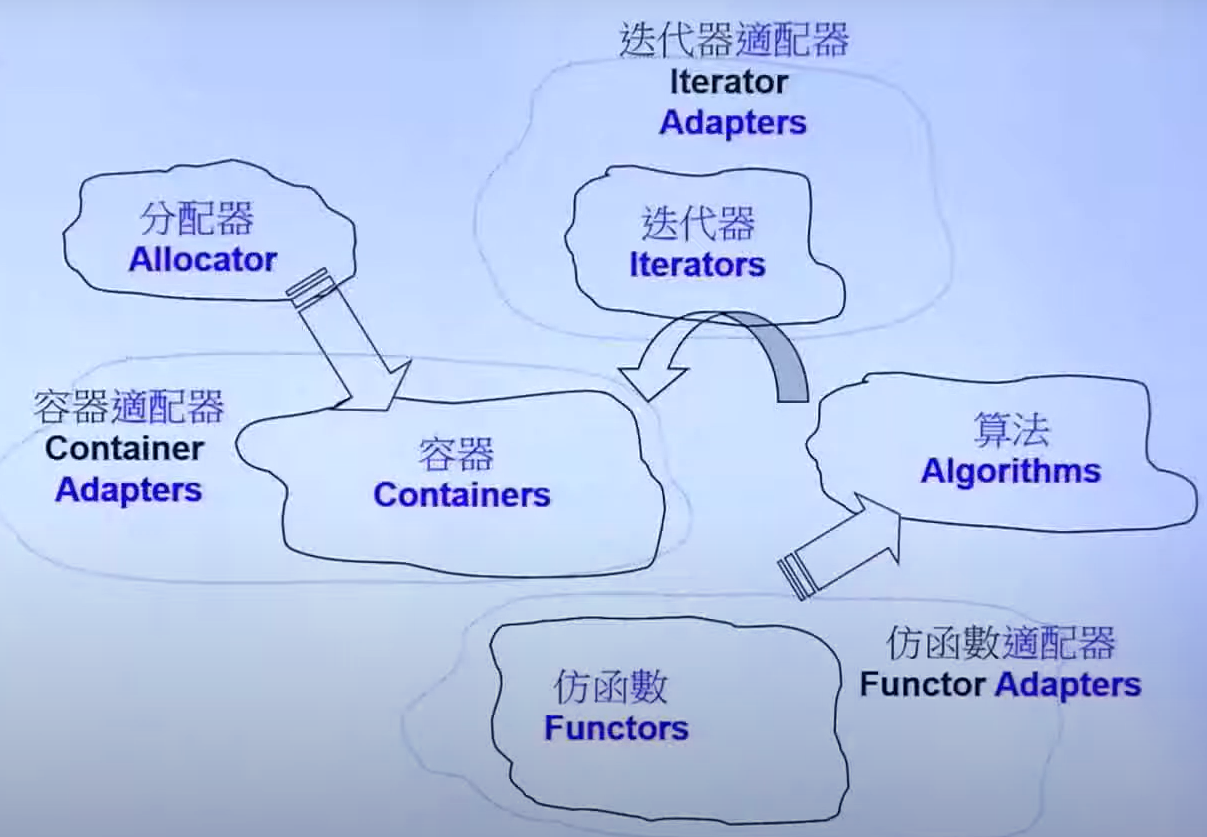
1. 序列式容器
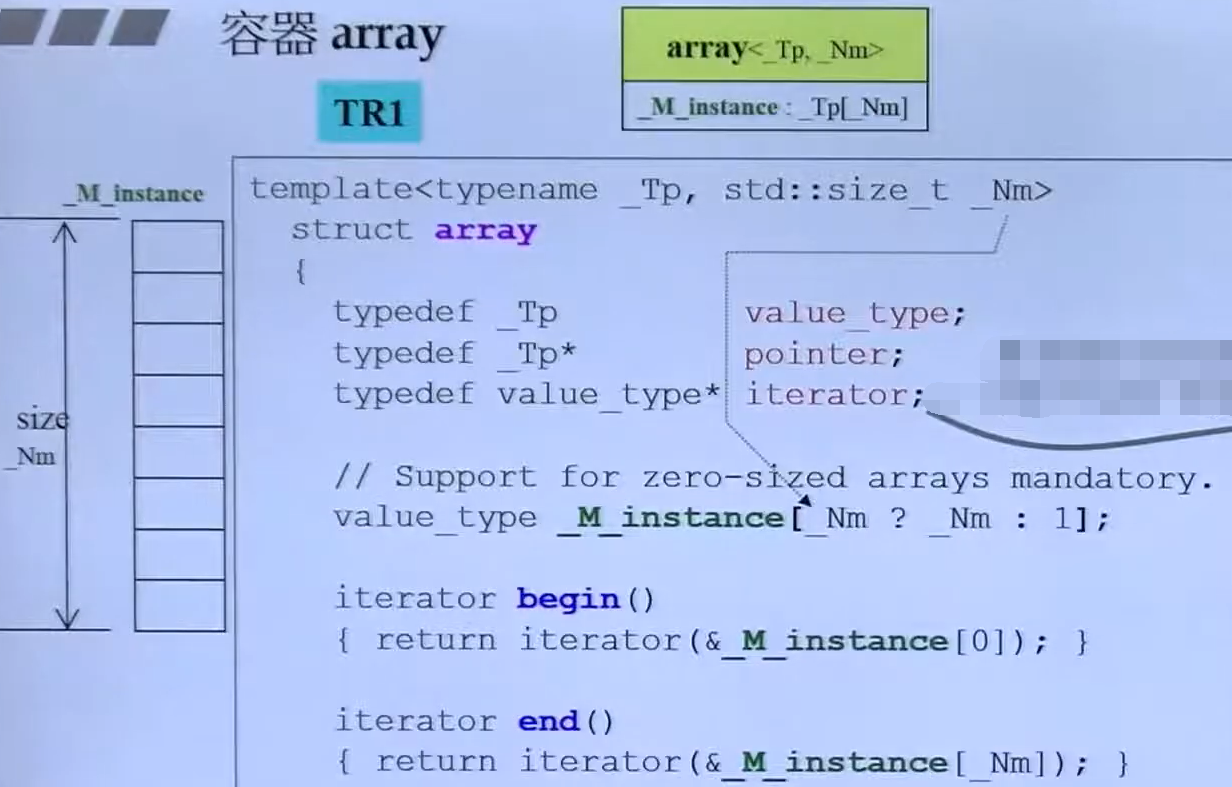
1.1 array
不允许扩充,在使用时指定内存大小 array
//如果传入的_Nm = 0,则array数组默认分配的内存为1value_type _M _instance[ Nm ? _ Nm : 1];
1.2 vector
每次都是成倍扩充,很浪费内存,但是找起来很方便
push_back() pop_back()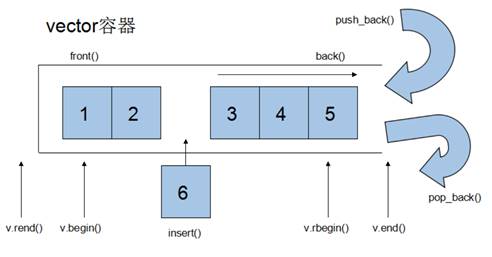
//操作符重载[]reference operator[] (size_type n){return *(begin() + n);}
1.3 list
空间利用率很高,但是找起来很麻烦,每次都要遍历一遍
push_back() pop_back()
push_front() pop_front()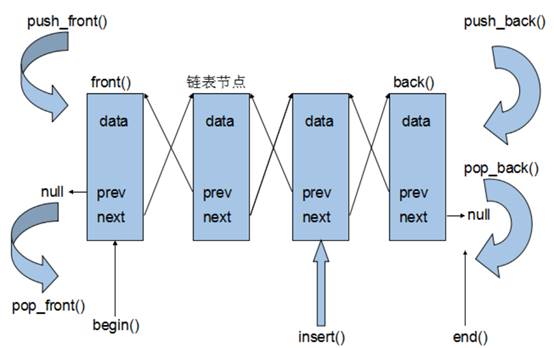
//操作符重载了 ++ ,* ,-> 等符号,和一大推typedefineself& operator++() {node = (link_type)((*node) .next);//取出(*node) .next,再进行强制类型转换link_type,赋值给nodereturn *this;}//T&reference operator*() const {return (*node) .data;}//T*pointer operator->() const {return &(operator*());}
1.4 deque
分段连续,双向进出,有个中控器维护每段缓冲区的地址,中控器可以理解为一个vector,也是成倍扩充的
这里有个有趣的事情是扩充后,会将原来的数据copy到新内存的中段,这样就保证了可前后进出了。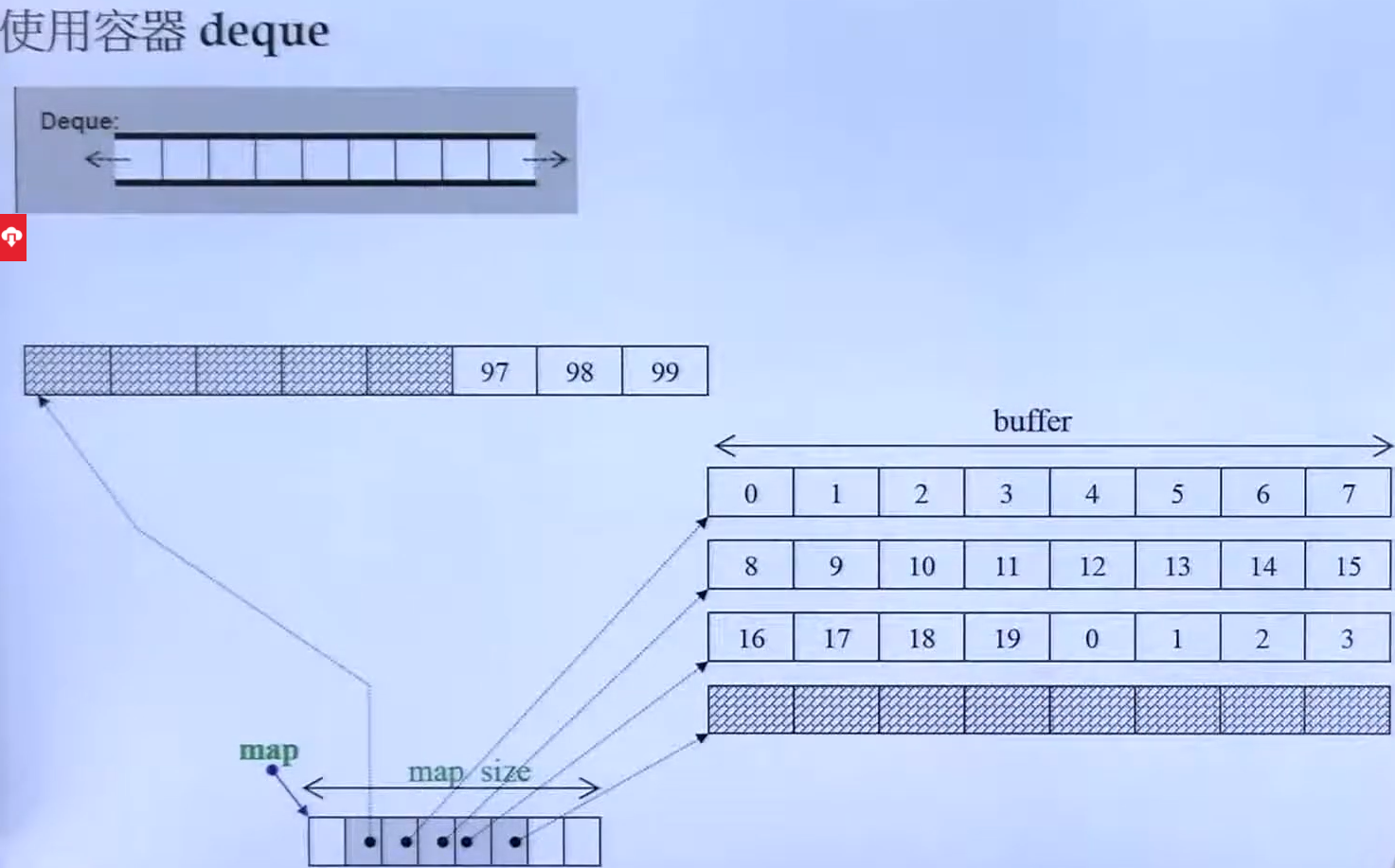
push_back() pop_back()
push_front() pop_front()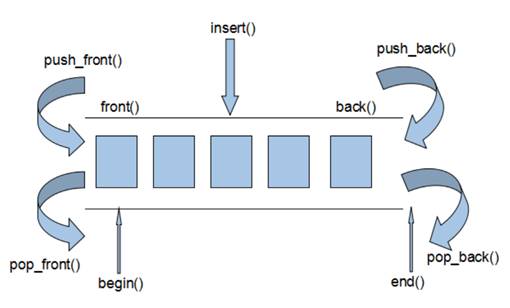
在32位的win系统下,每创建一个deque,占的内存为 40bit
//deque类//所谓 buffer_size是指每个buffer 容纳的元素个数template < class T, class Alloc=alloc,size_t BufSiz=0 >class deque {public:typedef T value_type;typedef _deque_iterator<T,T&,T*,BufSiz> iterator;protected:typedef pointer* map pointer; //T**protected:iterator start;iterator finish;map_pointer map;size_type map_size;public:iterator begin() { return start;}iterator end() {return finish; }size_type size() const { return finish - start; }}
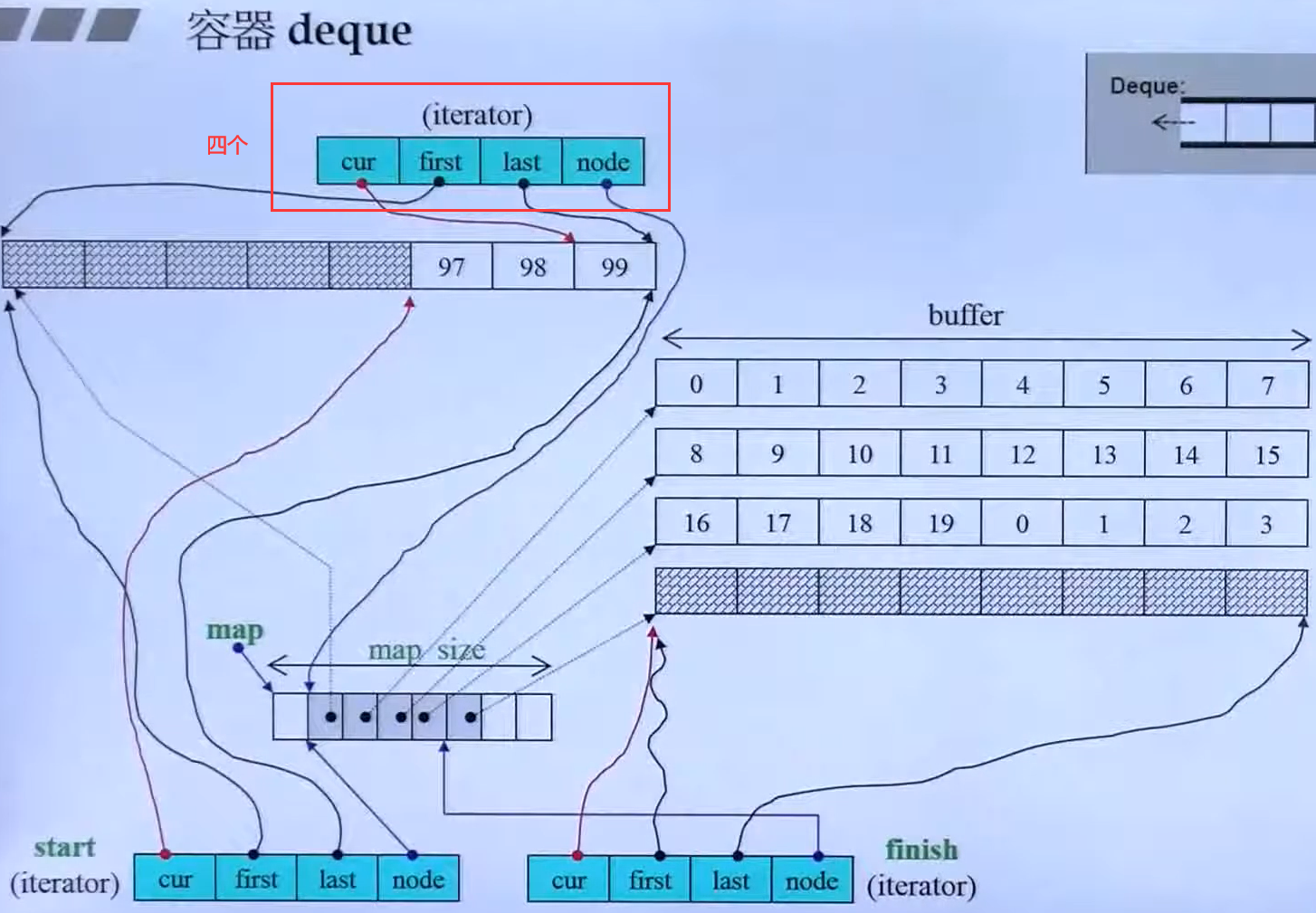
deque的迭代器是一个封装的class,内部含有四个元素cur,first,last,node
//deque的迭代器本身也封装成了类template <class T, class Ref,class Ptr,size_t BufSiz>struct _deque_iterator {typedef random_access_iterator_tag iterator_category;typedef T value_type;typedef Ptr pointer;typedef Ref reference;typedef size_t size_type;typedef ptrdiff_t difference_type;typedef _deque_iterator self;T* cur;T* first;T* last;T** node;}
stack和queue自己本身并没有实现什么数据结构,其内部其实就是一个deque,借用deque进行操作,所以有时候也不把这两个称为容器,可以理解为容器的适配器
其底层也可以用 list 做支撑,但是deque比较快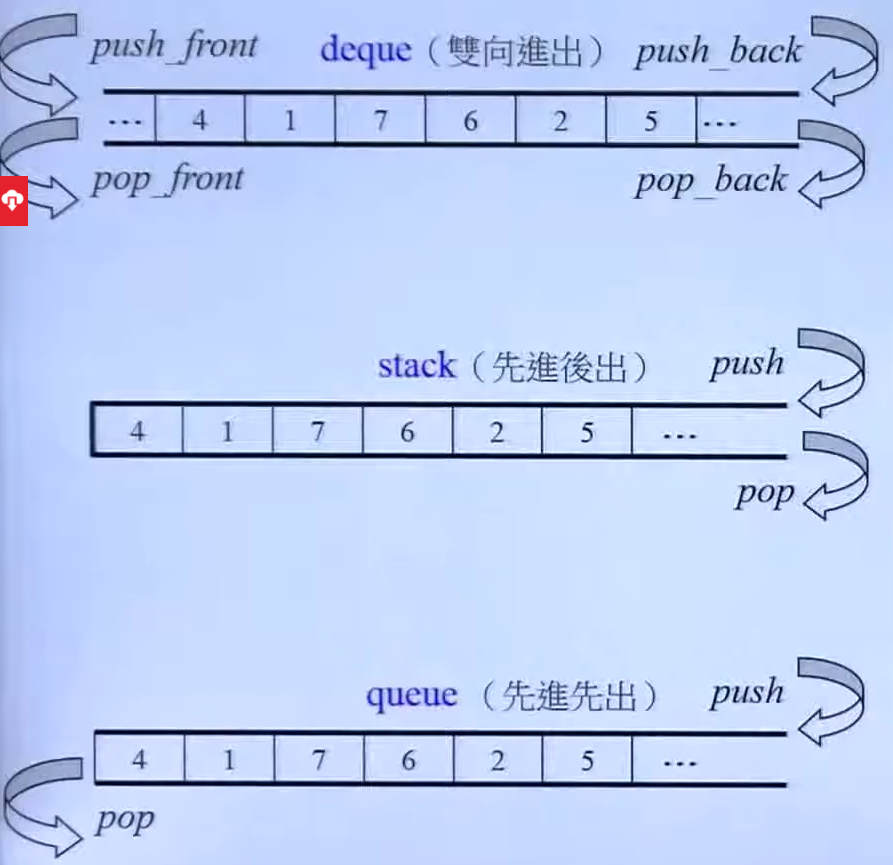
他们也没有迭代器这种东西,因为如果有这个的话意味着他们可以随意插入和删除其中的元素,这样会破坏他们原来的先进先出,先进后出的属性
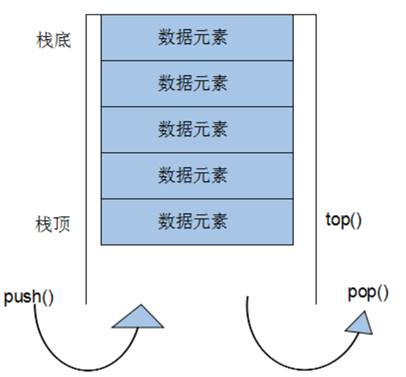
1.5 stack
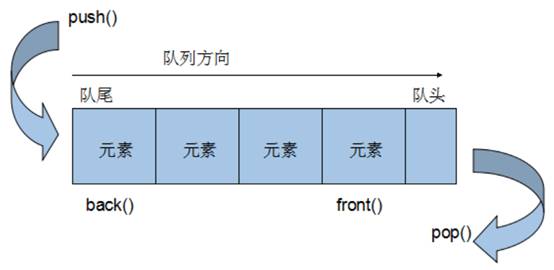
1.6 queue
2. 关联式容器
2.1 红黑树
2.2 set/multiset

set容器特点:
//所有元素插入时候自动被排序
//set容器不允许插入重复值
void test_multiset(long& value) //传引用{cout << endl << "test multiset.........." << endl;multiset<string> c;char buf[10];clock_t timeStart = clock();for (long i = 0; i < value; i++){try{snprintf(buf, 10, "%d", rand());c.insert(string(buf));//buf是一个char数组,需要转化为string类型,才能放入vector中}//如果系统无法再分配空间了,就会引发异常catch (exception& p)//捕获了异常,抓住了异常{cout << "i=" << i << " " << p.what() << endl;abort();//退出程序}}cout << "milli-seconds:" << clock() - timeStart << endl;cout << "c.size() = " << c.size() << endl;cout << "c.max_size() = " << c.max_size() << endl;string target = get_a_target_string();//调用标准库提供的全局::find()timeStart = clock();auto flag = ::find(c.begin(), c.end(), target);cout << "::find().milli-seconds:" << clock() - timeStart << endl; //12msif (flag != c.end())cout << "found," << *flag << endl;elsecout << "not found" << endl;//调用容器自己的find()timeStart = clock();flag = c.find(target);cout << "c.find(target),milli-seconds:" << clock() - timeStart << endl; //0msif (flag != c.end())cout << "found," << *flag << endl;elsecout << "not found" << endl;}
2.3 map/multimap

void test_multimap(long& value)//传引用{cout << endl << "test multimap.........." << endl;multimap <long, string> c;char buf[10];clock_t timeStart = clock();for (long i = 0; i < value; i++){try{snprintf(buf, 10, "%d", rand());c.insert(pair<long, string>(i, buf));//c[i] = srting(buf);//multimap不可用[]做insert,map可以用,但是直接c.insert()比c[i]速度要快一点}catch (exception& p)//捕获了异常,抓住了异常{cout << "i=" << i << " " << p.what() << endl;abort();//退出程序}}cout << "milli-seconds:" << clock() - timeStart << endl;cout << "c.size() = " << c.size() << endl;cout << "c.max_size() = " << c.max_size() << endl;long target = get_a_target_long();timeStart = clock();auto flag = c.find(target);cout << "c.find(target),milli-seconds:" << clock() - timeStart << endl;if (flag != c.end())cout << "found," << (*flag).second << endl;elsecout << "not found" << endl;}
2.6 哈希表
2.7 unordered_multiset
2.8 unordered_multimap
p9 面向对象编程(OOP)VS泛型编程(GP)
OOP:数据放在类里面,操作这些数据的函数也放在类里面,试图将data与methods直接关联在一起
GP:将data与methods分来,通过模板可以实现函数的复用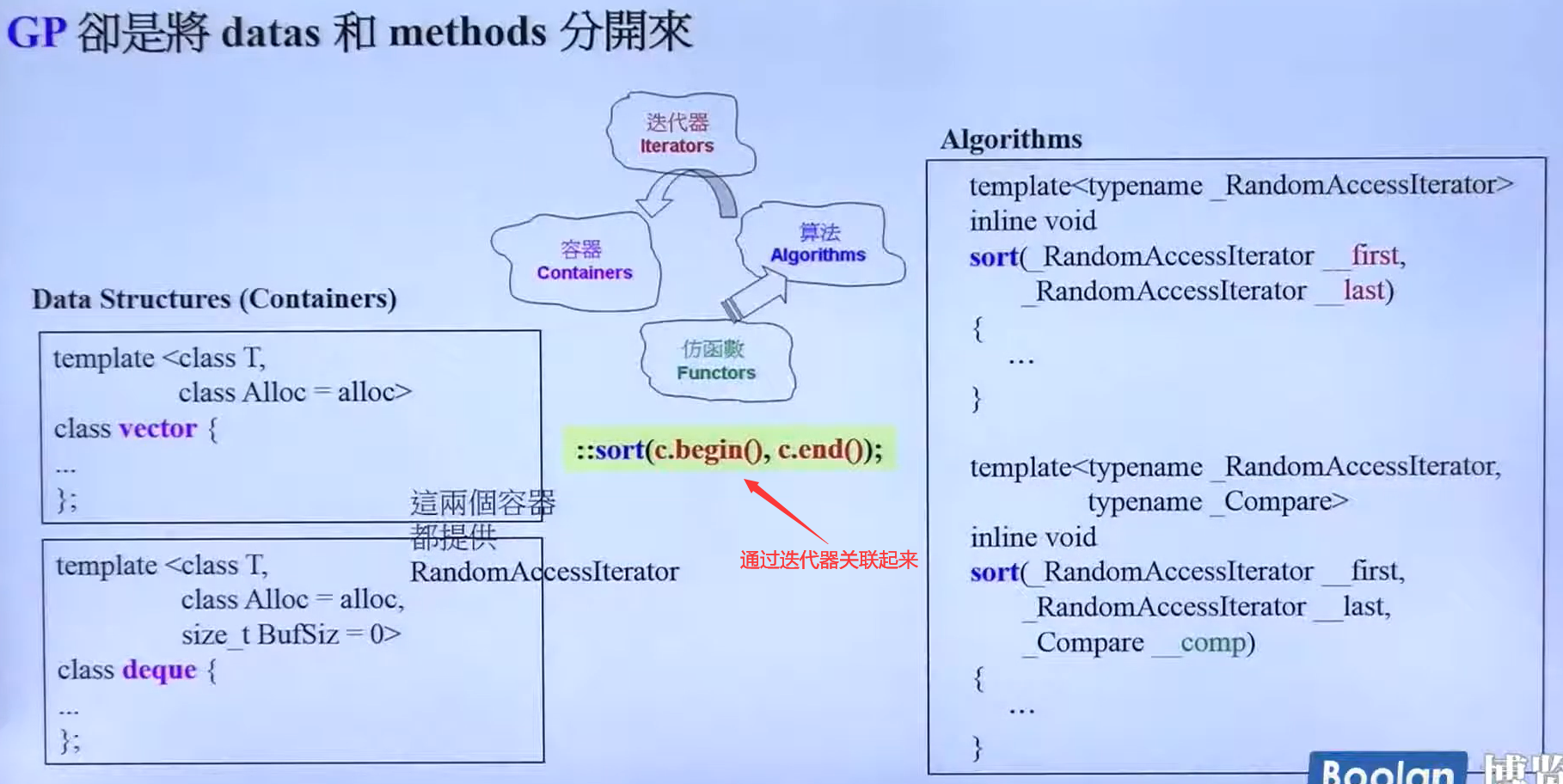
比如我们要实现比较大小的算法,我们完全可以下面这样实现
这个 T 你可以随意指定,可以是vector,list 甚至是 person,stone,只是你需要重载一下操作符 <
template <class T>
inline const T& min(const T& a, const T& b)
{
return b < a ? b : a;
}
template <class T>
inline const T& max(const T& a, const T& b)
{
return b > a ? b : a;
}
提问:为什么list容器不能使用全局的sort()函数? 因为list的迭代器有问题,链表的迭代器是单独设计的一个class。 在全局 sort() 源码里会出现迭代器的加减乘除运算,但list不支持随机存储,故不可做加减乘除运算,不能调用全局的 sort() 算法,所以需要在类内重写sort(),
随机访问迭代器的意思是可以在该迭代器指向的位置基础上向前或者向后移动n的位置,还能获取到容器的数据。 并且一个容器的迭代器如果不是随机访问迭代器的话,它往往也不支持使用 [ ] 和 at 来通过下标访问容器中的任意一个元素。
3. 算法
3.1 accumulate
template <class InputIterator,class T>
T accumulate(InputIterator first, InputIterator last,T init)
{
for( ;first != last; ++first)
//将元素累加至初值init身上
init = init +*first;return init;
}
template <class InputIterator, class T, class BinaryOperation>
T accumulate(InputIterator first, InputIterator last, T init, BinaryOperation binary_op)
{
for ( ; first != last; ++first)
//到元素「累计算」至初值init身上
init = binary_op(init, * first);
return init;
}
3.2 for_each
template <class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function f)
{
for( ; first != last; ++first)
f(*first);
return f;
}
3.3 replace
3.4 count
除了std::count() 形式,还有成员函数形式的 count(),有自己的就用自己的
3.5 find
除了std::find() 形式,还有成员函数形式的 find()
3.6 sort
除了std::sort() 形式,还有成员函数形式的 sort()

若有收获,就点个赞吧
0 人点赞
