1. AlexNet
卷积块:Conv2d—->ReLU—->MaxPool2d
全连接层Dense:Dropout—->Linear—->ReLU
源码中部分代码:model.py
def forward(self,x):x= self.features(x)x= torch.flatten(x, start_dim=1)x= self.classifier(x)return x
在train.py里面用到了net.train( ) 和net.eval( ),管理dropout方法,如果是训练模式就启用dropout,如果是评估模式就关闭dropout层
for epoch in range(10) :# trainnet.train() # 启用dropout方法running_loss = 0.0 # 统计训练过程的平均损失for step,data in enumerate(train_loader , start=0):images,labels = dataoptimizer.zero_grad() # 清空之前的梯度信息outputs = net(images.to(device))loss = loss_function(outputs,labels.to( device))loss.backward() # 反向传播optimizer.step() # 更新每个节点的参数running_loss += loss.item()# 打印训练进度rate = (step + 1) / len( train_loader)a = "*" * int(rate * 50)b = "." * int((1 - rate) * 50)print("\r train loss: {:^3.0f}%[{}->{}]{:.3f }".format(int(rate * 100),a,b,loss),end="")print()#validatenet.eval() # 关闭dropout方法acc = 0.0 # accumulate accurate number / epoch# 使用torch.no_grad()禁止框架对参数进行跟踪with torch.no_grad() :for data_test in validate_loader :test_images, test_labels = data_testoutputs = net(test_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += ( predict_y == test_labels.to(device)).sum( ).item()accurate_test = acc / val_numif accurate_test > best_acc:best_acc = accurate_testtorch.save(net.state_dict(), save_path)print( '[epoch %d] train_loss: %.3f test_accuracy: %.3f'% (epoch + 1, running_ loss / step, accurate_test))
2. GoogLeNet
源码中部分代码:model.py
# Inception层class Inception(nn.Module):self.branch1 = BasicConv2d(in_channels,ch1×1,kernel_size=1)self. branch2 = nn . Sequential(BasicConv2d(in_channels,ch3x3red,kernel_size=1),BasicConv2d(ch3x3red,ch3x3,kernel_size=3,padding=1))self. branch3 = nn. Sequential(BasicConv2d(in_channels,ch5x5red,kernel_size=1),BasicConv2d(ch5x5red,ch5x5,kernel_size=5,padding=2))self.branch4 = nn. Sequential(nn.MaxPool2d(kernel_size=3,stride=1 , padding=1),Basicconv2d(in_channels,pool_proj, kernel_size=1))def forward(self, ×):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(×)outputs = [branch1,branch2,branch3,branch4]return torch. cat(outputs,1)# 辅助分类器class InceptionAux(nn.Module):def __init_(self, in_channels, num_classes) :super (InceptionAux, self).__init_ )self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)self.conv= BasicConv2d( in_channels,128, kernel_size=1)self.fc1 = nn.Linear( 2048,1024)self.fc2 = nn.Linear(1024,num_classes)def forward(self,x):x = self.averagePool(x)x = self.conv(x)× = torch.flatten(x,1)x = F.dropout(x, 0.5,training=self.training)x = F.relu(self.fc1(x),inplace=True)x = F.dropout(x, 0.5,training=self.training)x = self.fc2(x)return x
在train.py里面用到了net.train( ) 和net.eval( ),管理dropout方法,以及是否使用辅助分类器
train( )方法使用了aux_logits2, aux_logits1,所以得到了三个输出
按照原论文说的,三个输出权重最终的损失函数loss = loss0 + loss1 0.3 + loss2 0.3
for epoch in range(2):#trainnet.train()running_loss = 0.0for step,data in enumerate( train_loader , start=0 ) :images,labels = dataoptimizer.zero_grad()logits, aux_logits2, aux_logits1 = net(images.to(device))loss0 = loss_function(logits, labels.to(device))loss1 = loss_function(aux_logits1, labels.to(device))loss2 = loss_function(aux_logits2, labels.to(device))loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward() # 反向传播optimizer .step() # 更新每个节点的参数# 更新平均损失函数running_loss += loss.item()#validatenet.eval()acc = 0.0 #accumulate accurate number / epochwith torch.no_grad():for data_test in validate_loader :test_images,test_labels = data_testoutputs = net(test_images.to(device)) # eval model only have last output layerpredict_y = torch.max(outputs, dim=1)[1]acc += (predict_y == test_labels.to(device)).sum().item()accurate_test = acc / val_numif accurate_test > best_acc:best_acc = accurate_testtorch.save(net.state_dict(), save_path)print( '[epoch %d] train_loss: %.3f test_accuracy: %.3f'% (epoch + 1, running_loss / step, accurate_test))
3. ResNet
- 使用Batch Normalization加速训练 (丢弃dropout)
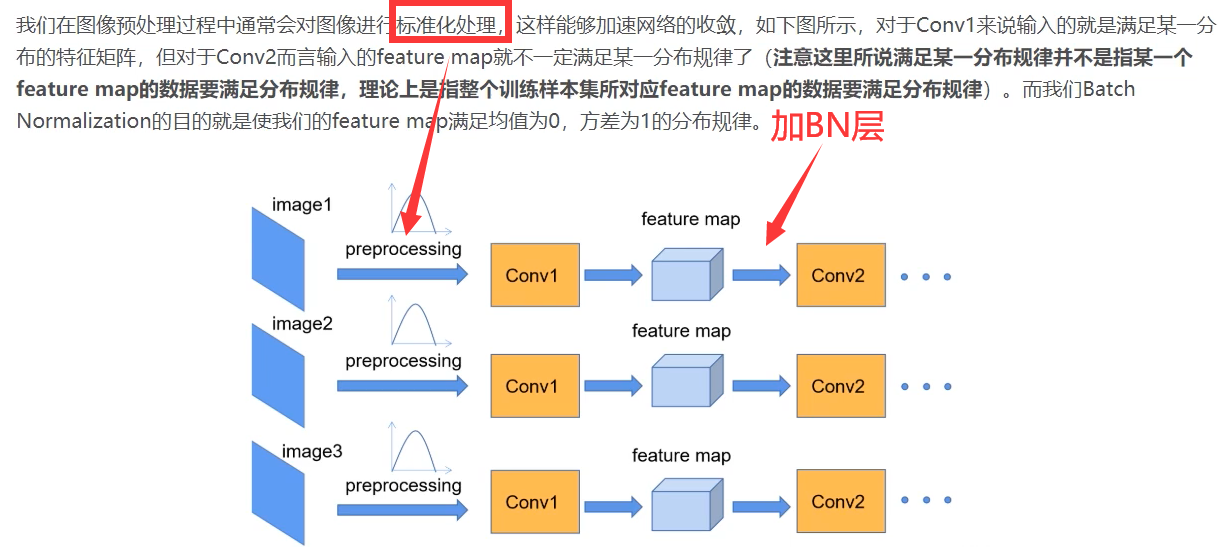
BN层目的是让feature map的每一个维度都满足均值为0,方差为1的分布规律。
- 提出residual模块
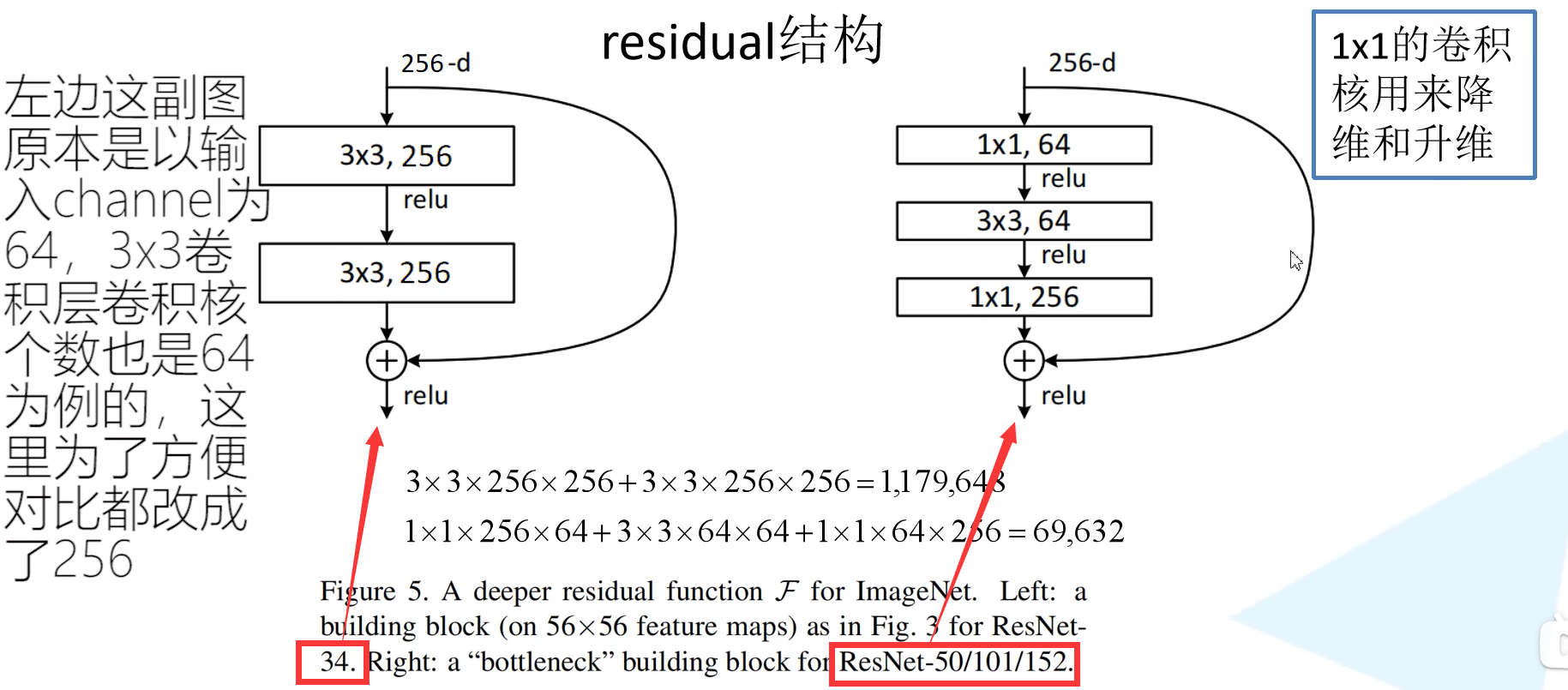
网络结构: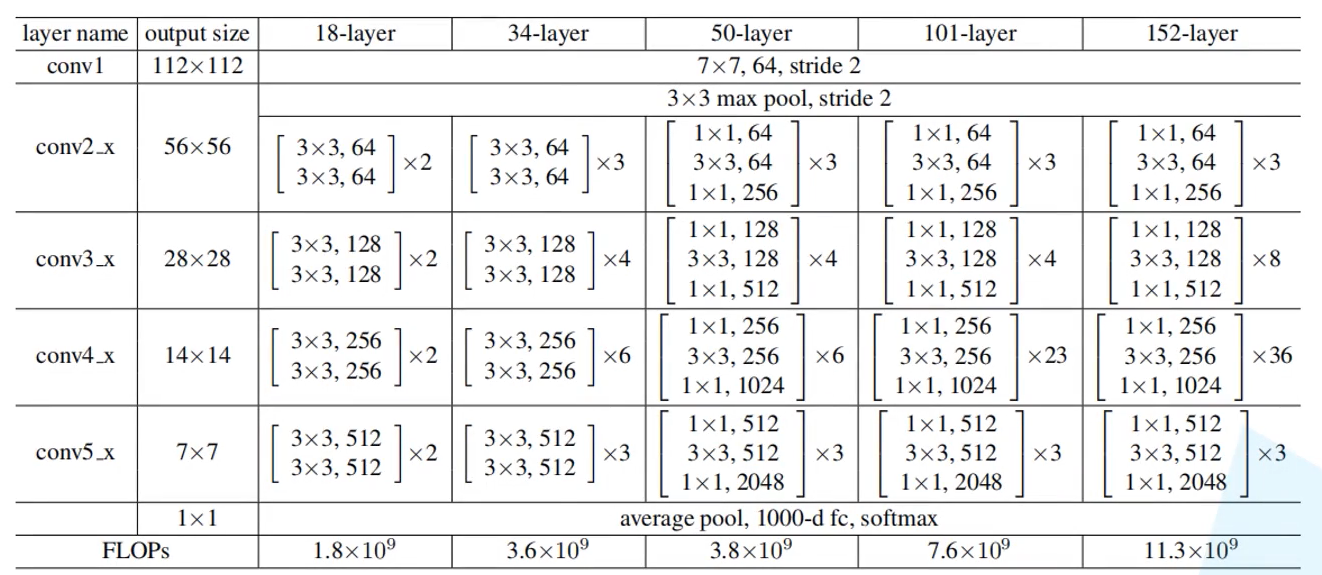

注意:在上述结构中的conv3_1, conv4_1, and conv5_1第一层做了修改
捷径分支如果是“实线”,则identity mapping和residual mapping通道数相同,“虚线”就是两者通道数不同,所以在捷径分支上需要使用1x1卷积下采样调整通道维度,使其可以相加。
另外重复部分的残差块第一块也做了部分修改,将stride设置为2,将上一层输出的高和宽调整为当前层的高和宽,不然输入和输出对不上。
原作者提出了好几个方法,最后经过验证发现option B的效果最好。
ResNet-18和34的改正部分,只改了conv3, conv4, and conv5三个块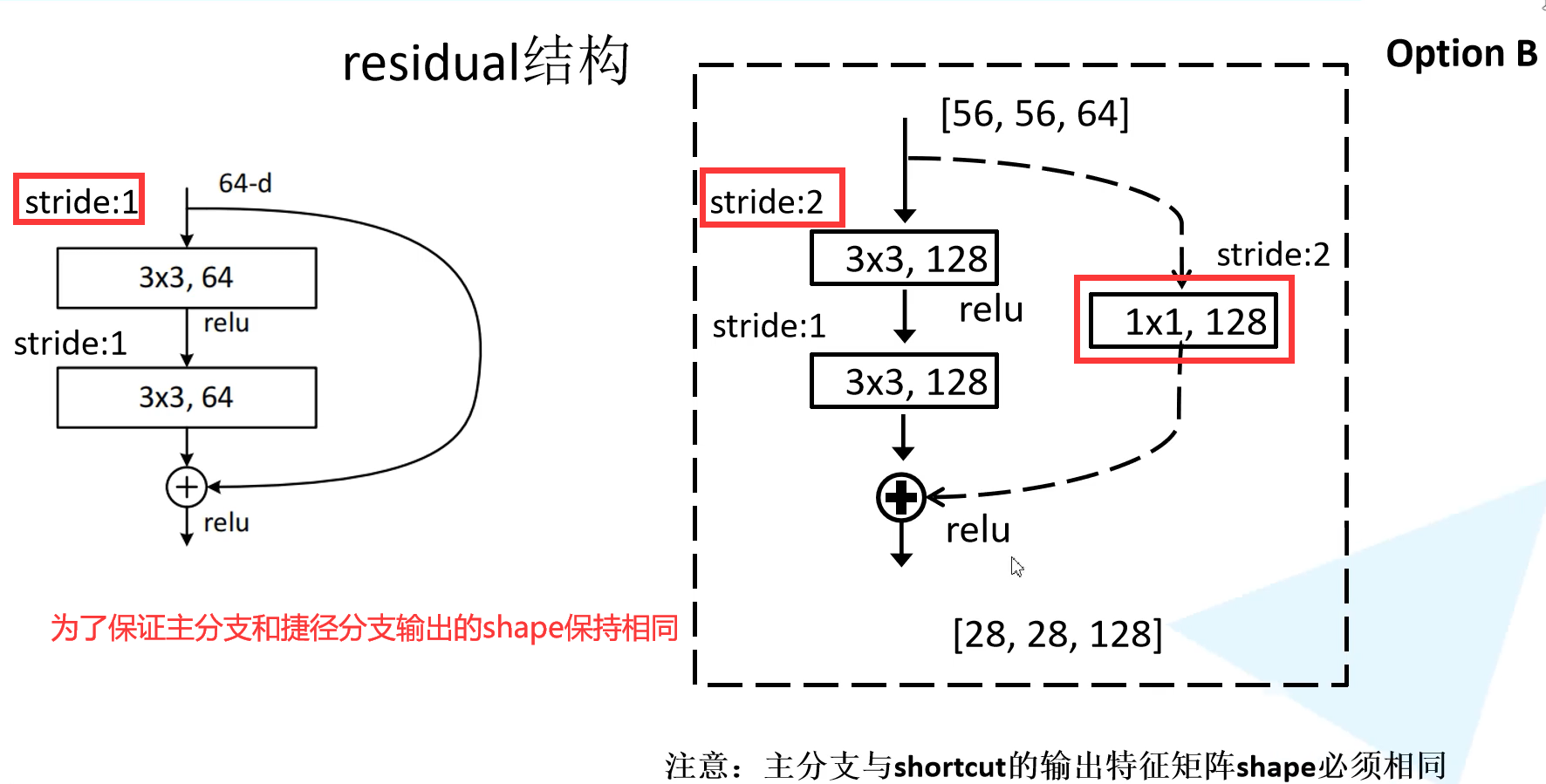
ResNet-50,101,152的改正部分,改了conv2,conv3, conv4, conv5四个块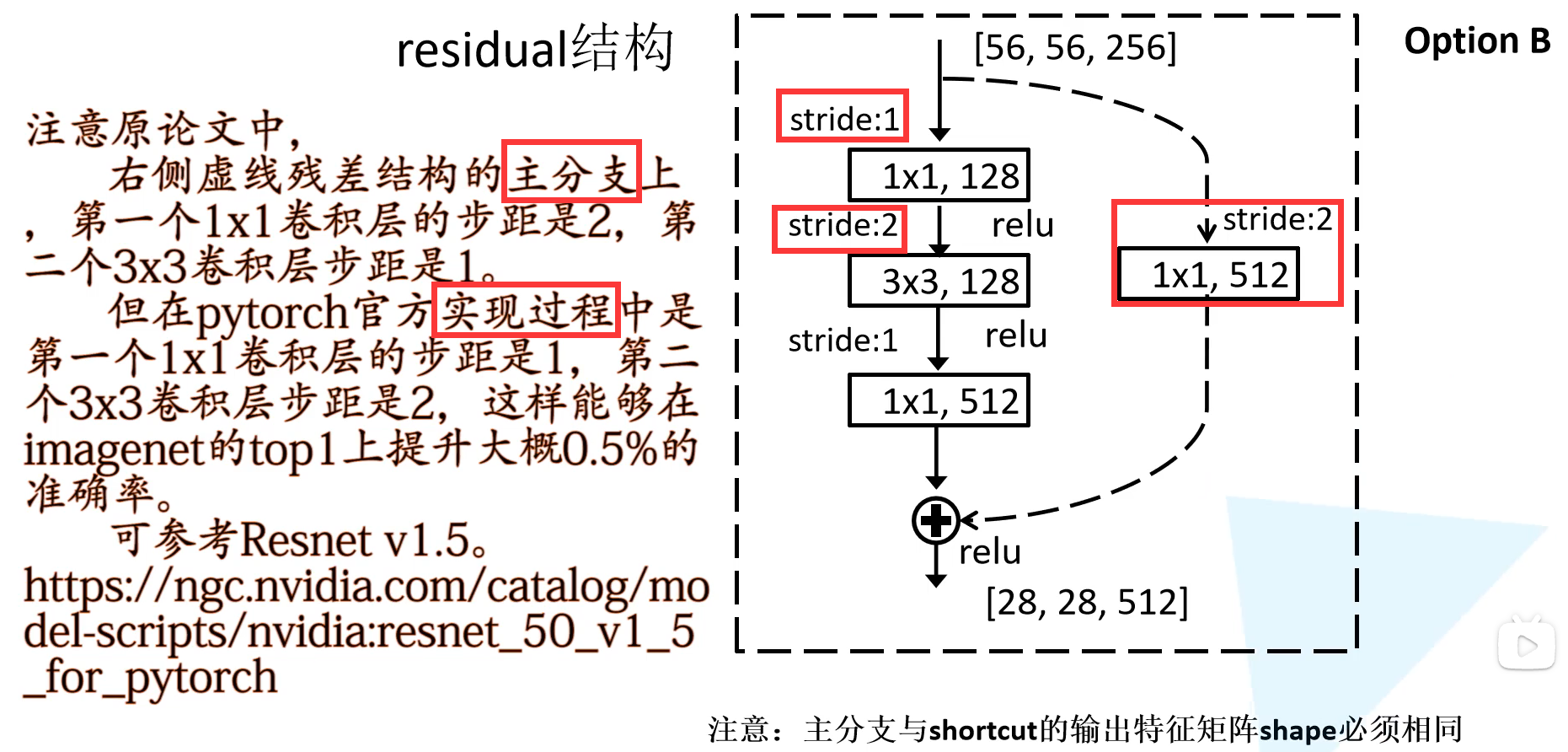
部分源码:model.py
关于BN笔记:1,使用BN的同时,卷积中的参数bias置为False;2,BN层放在conv层和relu层中间
def forward(self, x):identity = x # identity是捷径分支,如果没有下采样,就直接输出if self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out += identityout = self.relu(out)return out

若有收获,就点个赞吧
0 人点赞
