1. anchor box和bounding_box
在传统的目标检测中,因为待检测的物体的scale是变化的,通过生成图像金字塔,用滑动窗口滚动生成很多候选区域。但yolo算法另辟蹊径,直接为每个像素分配不同尺度和比例的矩形窗口,它们的中心都是其所属的像素点。对于长度和比例的分配可以根据标注的图像信息通过k-means聚类得到,而每个像素块分配几个不同长度和比例的矩形窗口就是Anchor。因此anchor可以理解为早期的滑动窗口
当我们只对图片中一个对象(且图片中只有一个对象)进行box回归时,我们只需要一个box回归器,但是当我们对图片中多个对象进行回归时,这时使用多个box回归器预测多个对象位置时就会发生冲突,因为每个预测器都可能不受约束地预测图片中任何一个对象的位置和类别。这时,我们就可以使用anchor来对每个回归器进行约束,只让每个回归器负责一块独立区域内的对象box回归。
yolo使用k-means算法在训练集中所有样本的真实框(gt box)中聚类出具有代表性形状的宽和高,作者叫这种方法为维度聚类(dimension cluster)。但是具体几个anchor才是最合适的,作者采用实验的方式,分别用不同数量的anchor应用到模型,然后找出最优的在模型的复杂度和高召回率,9个anchor box为最佳。
对于yolov3来说,输入输入图像为416x416,输出为3个尺度的特征图,分别为13×13、26×26、52×52,那么9个anchor每个尺度均分3个anchor。
究竟是哪个anchor负责匹配gt box呢?
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的3个anchor box负责预测它,具体是哪个anchor box预测它,需要在训练中确定,即由那个与ground truth的IOU最大的anchor box预测它,而剩余的2个anchor box不与该ground truth匹配。YOLOv3需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况(理解为每个cell最多只会匹配上一个目标)。与ground truth匹配的anchor box计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的anchor box只计算置信度误差(此时target为0)。
回归边界框:有了平移(tx,ty)和尺度缩放(tw,th)才能让anchor box经过微调与grand truth重合,线性回归后的边界框就叫 bounding box
如图,红色框为anchor box,绿色框为Ground Truth,平移+尺度缩放将实线红色框先平移到虚线红色框,然后再缩放到绿色框。边框回归最简单的想法就是通过平移加尺度缩放进行微调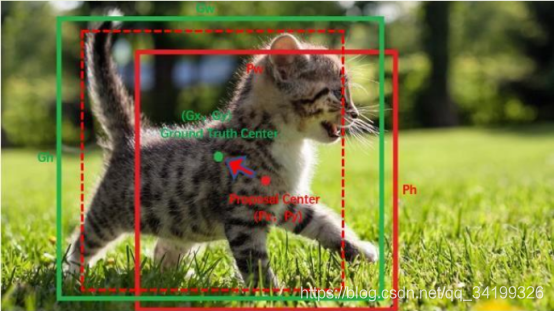
[
](https://blog.csdn.net/qq_43211132/article/details/102619661)还有一点:**yolov3需要的训练数据label是根据原图尺寸进行归一化了的**
2. YOLOv3
2.1 backbone
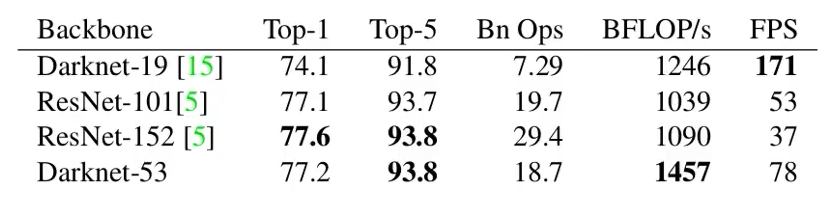
darknet53虽然在准确率上和resnet152差不多,但速率提升了两倍
从网络结构中可以看出,darknet53虽然和resnet152差不多,都是靠残差块的堆叠,但darknet53没有最大池化层,所有的下采样都是靠卷积实现,网络深度也就少一些。
3. YOLOv5
自己学习目标检测方向,看了一些github上的源码,yolov5的代码结构是我感觉最好理解的,很值得我们学习. 优秀的开源代码可以很好地提高我们写代码的规范。比如通过yaml文件来管理model的组成,我们可以自己添加模块,对模型的管理非常方便。
YOLOv5的1.0版本整体结构: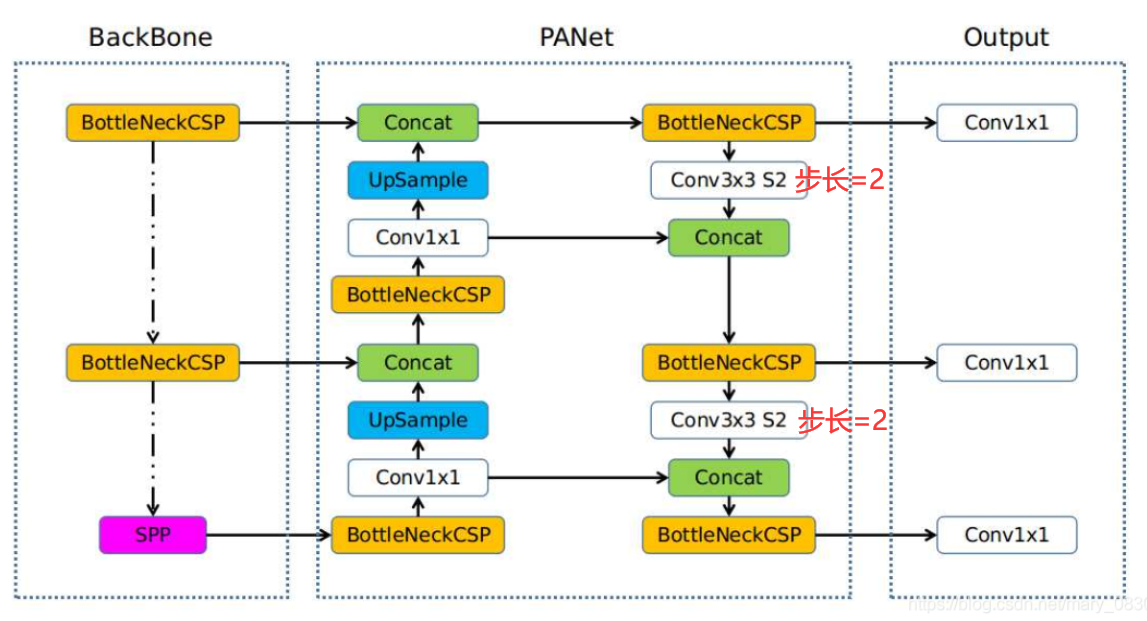
3.1 Bottleneck
class Bottleneck(nn.module):def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):super(Bottleneck,self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1) # conv(1*1) + BN + Lself.cv2 = Conv(c_, c2, 3, 1, g=g) # conv(3*3) + BN + L# 如果shortcut为True就会将输入和输出相加之后在输出self.add = shortcut and c1 == c2 # 相加操作def forward(self, x):# 根据self.add的值确定是不是有shortcut# 如果相加,则返回x+两次卷积的值, 若不想加,就相当于只做了两次卷积return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
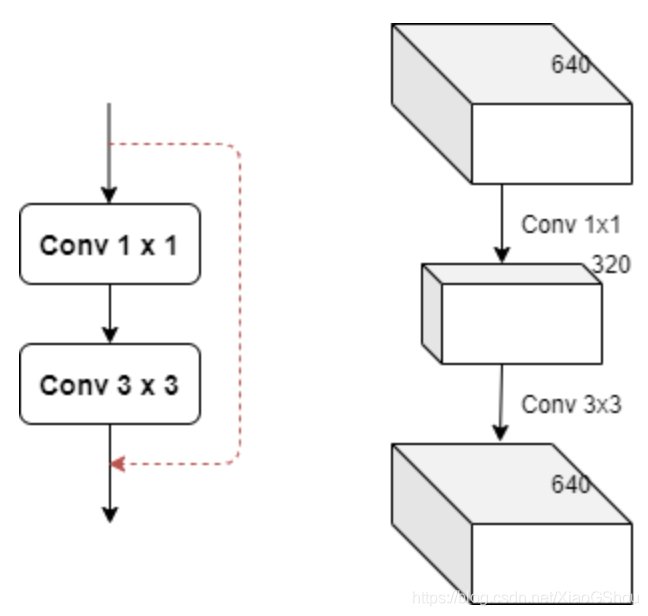
3.2 BottleneckCSP / C4
源码中有backbone中有三个BottleneckCSP,在yolov5s.ymal配置文件中,由于depth_multiple = 0.33 所以CSP中的Bottleneck个数为(1,3,3)而且Bottleneck有捷径分支
PANet中也是用的BottleneckCSP,但Bottleneck没有捷径分支,所以相当于做了三次卷积操作,再Cat
可以用CSP1,CSP2加以区分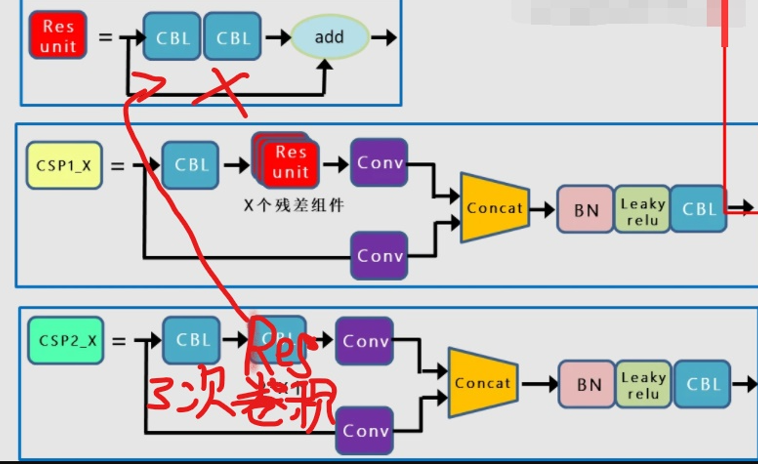
class BottleneckCSP(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super(BottleneckCSP, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1) # 第一个Conv模块self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.LeakyReLU(0.1, inplace=True)# 操作符*可以把一个list拆开成一个个独立的元素,self.m相当于n次的Bottleneck操作self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for_ in rang(n)])def forward(self, x):# 先做一次cv1操作(1X1)然后进行m操作也就是BCSP的n个Bottleneck,最后进行cv3操作# 输入x ->Conv模块 ->n个bottleneck模块 ->Conv模块 ->y1y1 = self.cv3(self.m(self.cv1(x)))# y2就是进行cv2操作,输入x -> Conv模块 -> 输出y2y2 = self.cv2(x)# 最后y1和y2做拼接, 然后做bn, 然后做act激活, 最后做cv4return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
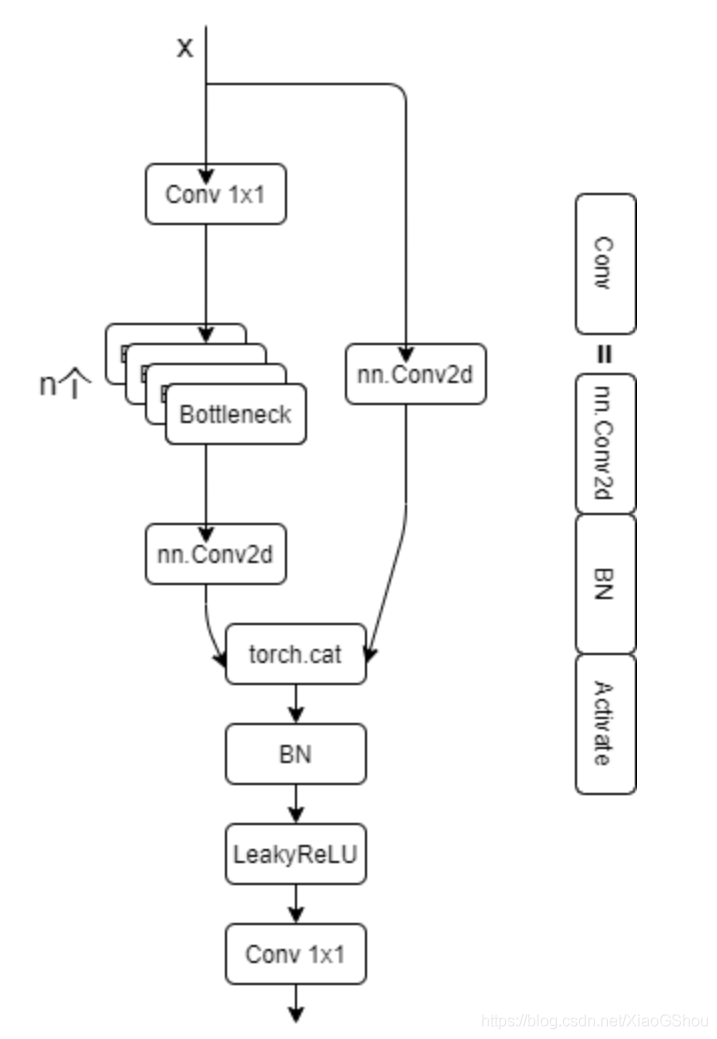
![)CA`%XOU37G4A42}~PIIWS.png
3.3 SPP
空间金字塔池化层,传统的卷积神经网络都是由卷积层+全连接层组成,其中卷积层对于输入数据的大小并没有要求,但是全连接层要求输入数据是固定大小的。SPP的提出就是为了解决CNN输入图像大小必须固定的问题,从而可以使得输入图像可以具有任意尺寸,有效避免了对图像区域的裁剪、缩放操作导致的图像失真问题,大大提高了产生候选框的速度,且节省了计算成本。
class SPP(nn.Module):# Spatial pyramid pooling layer used in yolov3-SPPdef __init__(self, c1, c2, k=(5, 9, 13)):super(SPP, self).__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1) # 1*1的卷积self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)# 先进行最大池化操作, 然后通过nn.ModuleList进行构造一个模块# 在构造时对每一个k都要进行最大池化,k=(5, 9, 13)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):x = self.cv1(x) # Conv2d + BN + LeakyRelu# 原输入x和对每一个m进行最大池化后的结果进行叠加拼接,最后做cv2操作return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))# torch.cat()是将两个tensor横着拼接在一起
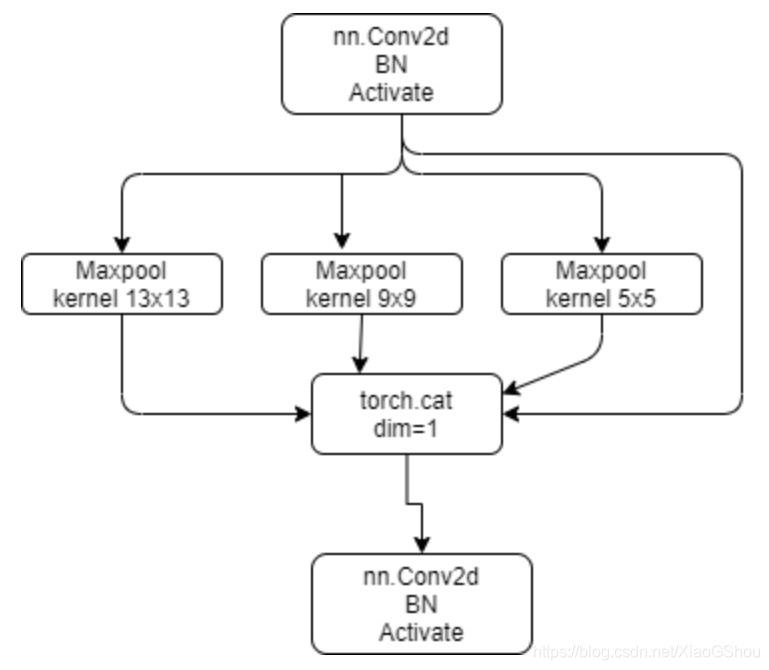
3.4 focus
将RGB三通道裁剪成 4*3 的12通道,步长为2。输入(b,c,w,h)的shape变成了输出(b, 4c, w/2, h/2)
class Focus(nn.Module):# Focus wh information into c-spacedef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):super(Focus, self).__init__()self.conv = Conv(c1 * 4, c2, k, s, p, g, act)def forward(self, x): # x(b,c,w,h) -> y(b, 4c, w/2, h/2) 有一个下采样的效果# 先进行切分, 然后进行拼接, 最后再做conv操作return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2],x[...,::2, 1::2], x[..., 1::2, 1::2]], 1))# return self.conv(self.contract(x))
3.5 yaml文件
通过./models/yolo.py解析文件加了一个输入构成的网络模块。
与config设置的网络不同,不需要进行叠加,只需要在配置文件中对number进行修改即可。

若有收获,就点个赞吧
0 人点赞

{kind=link}