调度器
调度器为每一个未经调度的Pod资源、基于一系列的规则集(基于资源可用性将各Pod资源公平的分布于集群节点之上)从集群中挑选一个合适的节点来运行它。
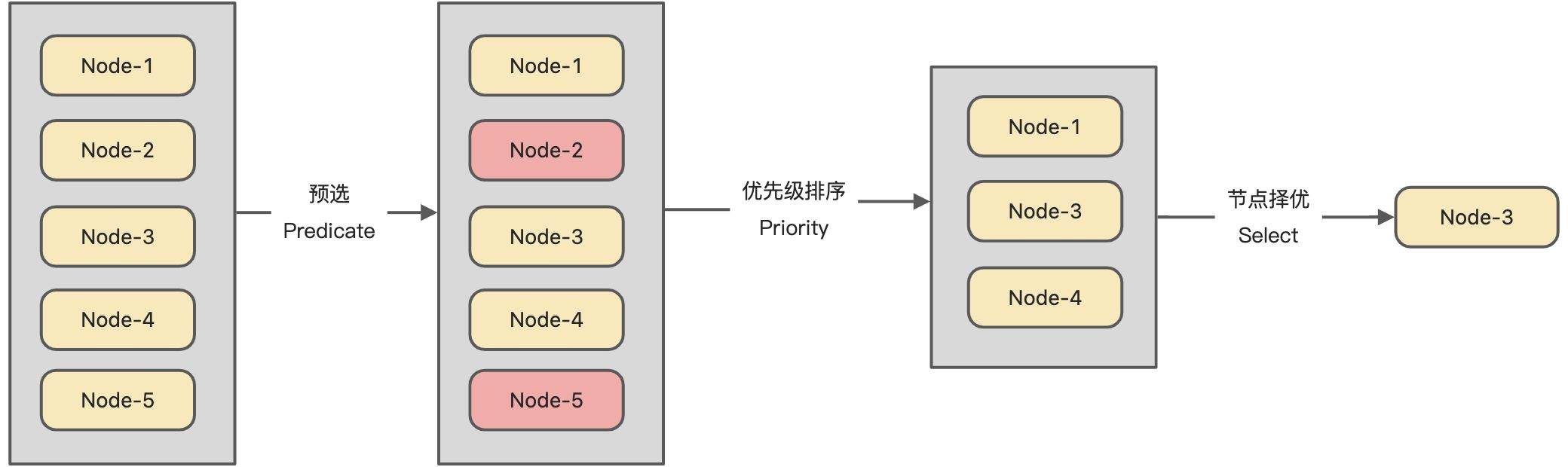
- 节点预选:基于一系列规则对每个节点进行检查,将那些不符合的节点过滤,如果Pod不存在任何一个满足条件的节点,则Pod被置于
**Pending**状态,直到有一个节点可用。- 节点优选:对预选出的节点进行有先级排序
- 节点择优:从优先级结果中挑选优先级最高的节点运行Pod
策略
- PodFitsHostPorts:检查Pod容器所需的HostPort是否已被节点上其它容器或服务占用。如果已被占用,则禁止Pod调度到该节点。
- PodFitsHost:检查Pod指定的NodeName是否匹配当前节点。
- PodFitsResources:检查节点是否有足够空闲资源(例如CPU和内存)来满足Pod的要求。
- PodMatchNodeSelector:检查Pod的节点选择器(nodeSelector)是否与节点(Node)的标签匹配
- NoVolumeZoneConflict:对于给定的某块区域,判断如果在此区域的节点上部署Pod是否存在卷冲突。
- NoDiskConflict:根据节点请求的卷和已经挂载的卷,评估Pod是否适合该节点。
- MaxCSIVolumeCount:决定应该附加多少CSI卷,以及该卷是否超过配置的限制。
- CheckNodeMemoryPressure:如果节点报告内存压力,并且没有配置异常,那么将不会往那里调度Pod。
- CheckNodePIDPressure:如果节点报告进程id稀缺,并且没有配置异常,那么将不会往那里调度Pod。
- CheckNodeDiskPressure:如果节点报告存储压力(文件系统已满或接近满),并且没有配置异常,那么将不会往那里调度Pod。
- CheckNodeCondition:节点可以报告它们有一个完全完整的文件系统,然而网络不可用,或者kubelet没有准备好运行Pods。如果为节点设置了这样的条件,并且没有配置异常,那么将不会往那里调度Pod。
- PodToleratesNodeTaints:检查Pod的容忍度是否能容忍节点的污点。
- CheckVolumeBinding:评估Pod是否适合它所请求的容量。这适用于约束和非约束PVC。
- NoVolumeZoneConflict: 给定的区域限之中检查存储卷冲突
- CheckNodeMemoryPressur: 检查内存节点是否存在压力(内存压力过大就不符合要求)
- CheckNodePIDPressure: 检查节点pid数量资源压力过大
- CheckNodeDiskPressure: 检查节点磁盘IO是否过高
- MatchInterPodAffinity: 检查节点是否满足POD是否满足亲和或者反亲和
函数
- LeastRequested: 由节点的空闲资源与节点的总容量来比较一个比值 根据空闲比例来评估 (cpu((capacity-sum(requested))10/capacity)+memory((capacity-sum(requested))10/capacity))/2
- BalancedResourceAllocation:CPU和内存资源被占用率相近的胜出
- NodePreferAvoidPodsPriority: 优先级较高,根据节点是否由注解信息来判定 节点注解信息“scheduler.alpha.kubernetes.io/preferAvoidPods”
- TaintToleration:将Pod对象的spec.tolerations列表项与节点的taints列表项进行匹配度检查,匹配条目越多,得分越低;
- NodeAffinityPriority:基于节点亲和性调度偏好进行优先级评估
- SeletorSpreading: 把同一个标签选择器的pod散开至多个节点
- InterPodAffinity: 匹配项越多得分越高 NodeAffinity: 节点亲和型
- MostRequested: 跟LeastRequested相反,空闲越小的分越高,尽可能把一个节点资源用完(默认关闭)
- NodeLabel: 根据节点是否有标签(默认关闭)
- ImageLocality:根据满足当前Pod对象需求的已有镜像的体积大小之和 (默认关闭)
节点亲和度与反亲和度
节点亲和度是调度程序来确定Pod对象调度位置的一组规则,这个规则基于节点上的自定义标签和Pod对象上指定的标签选择器进行定义。
- 硬亲和度(podAffinity);强制规则,它是在Pod调度时必须要满足的规则
- 软亲和度(nodeAffinity);柔性控制逻辑,被调度的Pod对象不再是“必须”而是“应该”放置在特定节点上
- 硬反亲和度(podAntiAffinity);强制规则,它是在Pod调度时不调度到指定节点
- 软反亲和度(nodeAntiAffinity);柔性控制逻辑,被反亲和调度的Pod对象不再是“必须”而是“尽量” 不放置在特定节点上
# 软亲和度spec:affinity:# 亲和度 nodeAffinity 反亲和度 nodeAntiAffinitynodeAffinity:preferredDuringSchedulingIgnoreDuringExecution:- weight: 60preference:matchExpreesion:- {key:zone, operator:In, values: ["foo"]}# 硬亲和度spec:affinity:# 亲和度 podAffinity 反亲和度 podAntiAffinitypodAffinity:preferredDuringSchedulingIgnoreDuringExecution:- weight: 60preference:matchExpreesion:- {key:zone, operator:In, values: ["foo"]}
污点和容忍度
污点是定义在节点之上的键值型属性数据,用于让节点拒绝将Pod调度运行。
- NoSchedule 不能容忍此污点的新Pod对象不可调度至当前节点,已存在的Pod不收影响
- PreferNoSchedule 是NoSchedule柔性约束版本,即不能容忍此节点的新Pod对象尽量不调度至当前节点
- NoExecute 不能容忍此污点的新Pod对象不可调度至当前节点,节点上现存的Pod对象因节点变动或Pod容忍度而不再满足匹配规则,Pod对象将本驱逐
Master 节点将自动添加污点信息以组织不能容忍此污点的Pod对象调度至此节点 DaemonSet(守护进程) 控制器能够无视此类节点
# 设置污点kubectl taint nodes node1 key1=value1:NoSchedule# 删除污点kubectl taint nodes node1 key1:NoSchedule-
Pod 对象的容忍度可以通过其
spec.toleration字段进行添加
# 判断机制的节点容忍度tolerations:- key: ""operator: "Equal"value: ""effect: "NoExecute"tolerationSeconds: 3600# 污点信息存在匹配tolerations:- key: ""operator: "Exists"value: ""effect: "NoExecute"tolerationSeconds: 3600
PDB 对象 / 非自愿中断
非自愿中断指的那些由不可控外界因素导致的Pod中断退出操作,例如:硬件、或者系统内核故障、网络异常以及节点资源不足导致的Pod对象被驱逐操作。
PDB 资源可以用来保护由控制器管理的应用,此时几乎必然意味着PDB等同于相关控制器对象的标签选择器以精确关联目标Pod对象。
- select:PDB 对象使用的标签选择器
- minAvailable:Pod自愿中断场景,如果不想发生中断则设置为100%
- maxUnavailable:Pod自愿中断的场景中,最多可转换位不可用状态的Pod对象数量或者比例,0标示不允许Pod对象进行自愿中断,与
minAvailable互斥
apiVersion: policy/v1beta1kind: PodDisruptionBudgetmetadata:name: ""spec:minAvailable: 2selector:matchLabels:app: myapp
流程图
Kubernetes 金丝雀
金丝雀发布,即灰度发布,是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
Kubernetes 使用暂停更新以及回滚指定Pod 实现金丝雀发布
PS:Kubernetes 在做金丝雀的时候存在部分请求失效问题,目前行业解决方案都是**Service Mesh**解决金丝雀发布,总体没有一个比较成熟
# 暂停更新kubectl rollout pause deployment [名称]# 回滚版本kubectl rollout undo [名称]

若有收获,就点个赞吧
0 人点赞
