Kubernetes 的核心功能之一在于确保各个资源对象的当前状态
status,以匹配用户希望的状态spec,使当前状态不断地向希望状态和解来完成容器应用管理这就是控制器。
PS:Kubernetes的控制器有十几种,这里仅说明常用的。
Pod 控制器的组成
Pod 控制器资源至少包含三个基本的组成部分:
- 标签选择器: 匹配并关联Pod资源对象,并据此完成受其管控的Pod资源计数
- 期望的副本数:期望在集群中精确运行着的Pod资源对象数量
- Pod模板:用于新建Pod资源对象的Pod模板资源
apiVersion: apps/v1kind: Deploymentmetadata:annotations:deployment.kubernetes.io/revision: '4'# 资源标签labels:app: admin-client-nginxmodule: nginxname: admin-client-nginxnamespace: interests# 期望的用户状态spec:progressDeadlineSeconds: 600# 期望的副本数replicas: 1revisionHistoryLimit: 10# 标签选择器selector:matchLabels:app: admin-client-nginxstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdate# Pod模板template:metadata:annotations:labels:app: admin-client-nginxspec:containers:- image: 'nginx:1.20'imagePullPolicy: IfNotPresentname: admin-client-nginxports:- containerPort: 80name: httpprotocol: TCP# 资源请求resources:requests:cpu: 250mmemory: 512MiterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /etc/localtimename: volume-1648780685822- mountPath: /etc/nginx/conf.dname: volume-1648791000841dnsPolicy: ClusterFirstrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- hostPath:path: /etc/localtimetype: ''name: volume-1648780685822- name: volume-1648791000841secret:defaultMode: 420secretName: admin-client-nginx# 当前用户状态status:availableReplicas: 1conditions:- lastTransitionTime: '2022-04-01T05:12:35Z'lastUpdateTime: '2022-04-01T05:30:27Z'message: ReplicaSet "admin-client-nginx-5888bfd5b6" has successfully progressed.reason: NewReplicaSetAvailablestatus: 'True'type: Progressing- lastTransitionTime: '2022-04-11T02:47:14Z'lastUpdateTime: '2022-04-11T02:47:14Z'message: Deployment has minimum availability.reason: MinimumReplicasAvailablestatus: 'True'type: AvailableobservedGeneration: 4readyReplicas: 1replicas: 1updatedReplicas: 1
Pod 控制器类型
Deployment 无状态
Deployment 构建与
ReplicaSet控制器之上,主要职责同样是为了保证Pod资源的健康运行,主要包括:
- 事件状态查看:查看对象升级详细进度状态
- 回滚:升级操作完成后可以回滚机制将应该返回到前一个
- 版本记录:对每一次操作都给予保存
- 暂停和启动:对于每一次升级,都能够随时暂停和启动
- 多种自动更新方案:
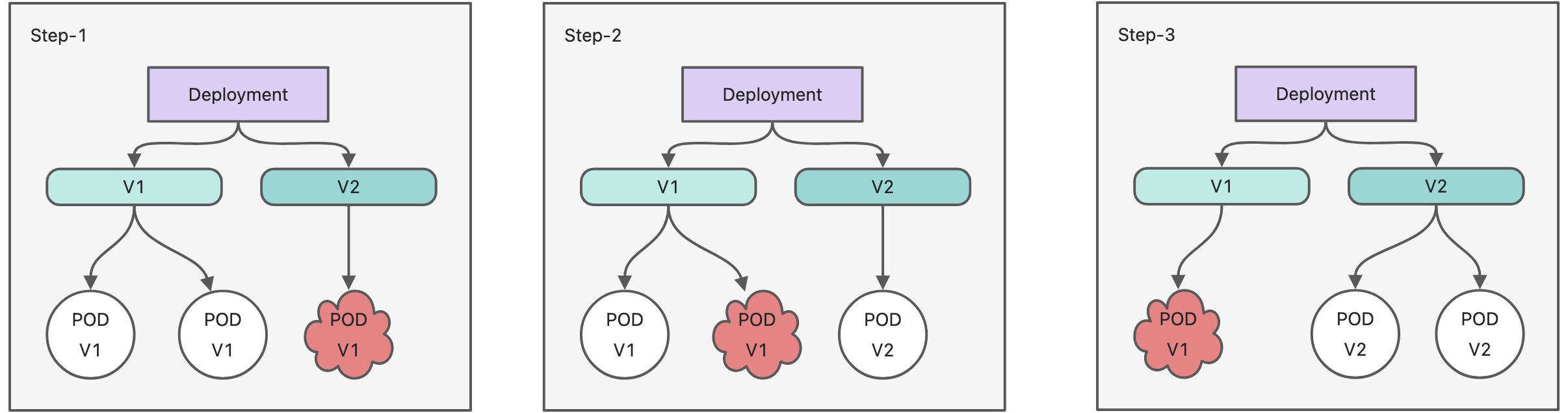
Recreate重建更新,全面停止、删除旧的Pod后启用新版本替代;另一个是RollingUpdate即滚动升级机制,逐步替换旧有的Pod至新的版本。
apiVersion: apps/v1# 无状态类型kind: Deploymentmetadata:annotations:generation: 1labels:app: billbear-hotel-clientmodule: apiname: billbear-hotel-clientnamespace: interests# 期望配置spec:progressDeadlineSeconds: 600replicas: 1revisionHistoryLimit: 10# 更新策略strategyType: RollingUpdateselector:matchLabels:app: billbear-hotel-client# 模板template:metadata:labels:app: billbear-hotel-clientspec:containers:image: ''imagePullPolicy: Alwaysname: billbear-hotel-clientports:- containerPort: 8080name: httpprotocol: TCPresources:requests:memory: 512MivolumeMounts:- mountPath: /etc/localtimename: volume-localtime- mountPath: /app/logs/name: volumn-sls-16468903003157dnsPolicy: ClusterFirstimagePullSecrets:- name: aliyun-shanghairestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- hostPath:path: /etc/localtimetype: ''name: volume-localtime- emptyDir: {}name: volumn-sls-16468903003157
更新升级说明
Deployment 控制器支持
Recreate重建更新,RollingUpdate滚动更新重建更新:首选删除现有的Pod对象,而后由控制器基于新模板重新创建出新版本资源对象。通常只有在新的不兼容旧版本时使用。
滚动更新:是默认的升级策略,创建一部分新版本Pod对象,进行应用升级,其优势是升级期间,容器中应用提供的服务不会中断。
spec.minReadySeconds控制升级时长spec.strategy.rollingUpdate.maxSurge升级期间存在的总Pod对象数量最多超出期望值的个数spec.strategy.rollingUpdate.maxUnavailable升级期间正常可用的Pod数量PS:使用升级命令时候,必须修改 spec 内内容否则不会触发更新
# 使用命令修改镜像并出发更新kubectl path deployment [名称] -p '{"spec": {"containers": ["image":"xxx:v2"]}}'
DaemonSet 守护进程集
DaemonSet 用于在集群的全部节点上同时运行一份指定的Pod资源,它是一个特殊的控制器,它有特定的应用场景,通常运行那些执行系统级操作任务的应用
- 保证每个节点都会运行一个Pod
- 事件状态查看:查看对象升级详细进度状态
- 回滚:升级操作完成后可以回滚机制将应该返回到前一个
- 版本记录:对每一次操作都给予保存
- 暂停和启动:对于每一次升级,都能够随时暂停和启动
- 多种自动更新方案:
Recreate重建更新,全面停止、删除旧的Pod后启用新版本替代;另一个是RollingUpdate即滚动升级机制,逐步替换旧有的Pod至新的版本。
apiVersion: apps/v1# 守护进程kind: DaemonSetmetadata:labels:app: flanneltier: nodename: kube-flannel-dsnamespace: kube-systemspec:revisionHistoryLimit: 10selector:matchLabels:app: flanneltier: nodetemplate:metadata:labels:app: flanneltier: nodespec:containers:image: >-registry-vpc.cn-shanghai.aliyuncs.com/acs/flannel:v0.15.1.5-11d1c700-aliyunimagePullPolicy: IfNotPresentname: kube-flannelresources:requests:cpu: 100mmemory: 100MisecurityContext:capabilities:add:- NET_ADMIN- SYS_ADMINprivileged: falsereadOnlyRootFilesystem: falseterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /runname: run- mountPath: /etc/kube-flannel/name: flannel-cfgdnsPolicy: ClusterFirst# 共享宿主机网络hostNetwork: truenodeSelector:kubernetes.io/os: linuxpriorityClassName: system-node-criticalrestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}serviceAccount: flannelserviceAccountName: flannelterminationGracePeriodSeconds: 30tolerations:- operator: Existsvolumes:- hostPath:path: /runtype: ''name: run- hostPath:path: /etc/cni/net.dtype: ''name: cni- configMap:defaultMode: 420name: kube-flannel-cfgname: flannel-cfg
更新升级说明
重建更新:首选删除现有的Pod对象,而后由控制器基于新模板重新创建出新版本资源对象。通常只有在新的不兼容旧版本时使用。
滚动更新:是默认的升级策略,先删除一个节点上的Pod资源,等待其新版本Pod资源重建完成后在开始操作另外一个节点上的Pod资源
StatefulSet 有状态
应用程序存在 “有状态” 和 “无状态”, 而无状态程序可以按需增加、减少、或者重构,而不会对服务有影响。 当程序与用户、设备、其他应用程序或外部组件进行通讯时,根据其是是否需要记录前一次或多次通信中的相关时间信息易作为下一次通讯分类标准,可以将那些需要记录系信息的应用程序称为有状态应用
StatefulSet 用于部署个扩展有状态应用的Pod,确保他们的运行顺序以及每个Pod资源的唯一性
- 稳定具有唯一的网络标识符
- 稳定且持久的存储
- 有序、优雅的部署和扩展
- 有序、优雅的删除和终止
- 有序而自动的滚动更新
apiVersion: apps/v1kind: StatefulSetmetadata:labels:app: rabbitmqname: rabbitmqnamespace: basespec:podManagementPolicy: OrderedReadyreplicas: 1revisionHistoryLimit: 10selector:matchLabels:app: rabbitmqserviceName: rabbitmq-svctemplate:metadata:labels:app: rabbitmqspec:affinity: {}containers:image: 'registry-vpc.cn-shanghai.aliyuncs.com/basis/rabbitmq:delayed'imagePullPolicy: Alwaysname: rabbitmqports:- containerPort: 15672name: adminprotocol: TCP- containerPort: 5672name: tcpprotocol: TCPresources:requests:memory: 1GiterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /etc/localtimename: volume-localtime- mountPath: /var/lib/rabbitmq/mnesia/rabbit@rabbitmq-0name: volume-rabbitmq-pvcdnsPolicy: ClusterFirstimagePullSecrets:- name: aliyun-shanghairestartPolicy: AlwaysschedulerName: default-schedulersecurityContext: {}terminationGracePeriodSeconds: 30volumes:- hostPath:path: /etc/localtimetype: ''name: volume-localtime- name: volume-rabbitmq-pvcpersistentVolumeClaim:claimName: rabbitmq-pvcupdateStrategy:type: RollingUpdate
更新升级说明
重建更新:首选删除现有的Pod对象,而后由控制器基于新模板重新创建出新版本资源对象。通常只有在新的不兼容旧版本时使用。
滚动更新:是默认的升级策略,Pod资源以逆向的形式从其最大索引编号的Pod资源逐一进行,它在终止一个Pod资源,更新资源并待其就绪后启动更新下一个资源,即索引号比当前号小1的Pod资源。
暂缓更新:
spec.update-Strategy.rollingUpdate.partition设置Pod资源的副本数量,比Pod资源最大索引号大1,则所有的Pod资源都不会处于可直接更新的分区之内
Job 控制器
Job 控制器用于调配Pod对象运行一次性任务,容器中的进程在正常运行结束后不会对其重启,而是将Pod对象置于
Completed(完成)状态
- Job 控制器常用于管理那些运行一段时间便可”完成”的任务,例如数据库备份等操作
- 单工作队列:多个一次性任务串行执行多次作业,直至满足期望的次数
- 多工作队列:这个方式可以设置工作队列数,即作业数,每个队列仅负责运行一个或多个任务
spec.completions总任务数量spec.parallelism并行度spec.actuveDeadlineSecinds最大活动时间长度,超出此时长的作业将被终止spec.backoffLimit将作业标记为失败状态之前的重试次数PS:
restartPolicy默认是_**Always**_始终重启,单对于Job 不是很合适,使用Never
apiVersion: apps/v1# Jobkind: Jobmetadata:name: job-testspec:# 运行多少次completions: 5# 并发队列parallelism: 1# 最大执行时间,超过则强制停止actuveDeadlineSecinds: 60# 重试次数backoffLimit: 3template:spec:containers:- name: testimage: xxx:v1command: ["/bin/sh", "-c", "sleep 20"]# 默认是Always 始终重启,单对于Job 建议禁用restartPolicy: Never
CronJob 控制器
CronJob 控制器用于管理Job 控制器资源的运行时间。CronJob 类似Linux操作系统的周期性任务作业计划(Cron)的方式控制其运行的时间点及重复运行的方式。
- 在未来某时间点运行作业一次
- 在指定的时间点重复运行作业
spec.jobTemplateJOB任务模板spec.scheduleCron格式的作业调度运行spec.concurrencyPolicy并发执行策略,Allow 允许,Fobid 禁用,Replace 替换,定义前一次任务没有执行完成时如何运行后一次的作业spec.failedJobHistoryLimit为失败任务执行保留的历史记录数spec.successfulJobsHistoryLimit为成功任务执行保留的历史记录数spec.startingDeadlineSeconds执行超时,记录历史记录spec.suspend是否挂起后续的任务执行,默认false
apiVersion: apps/v1# Jobkind: CronJobmetadata:name: job-testspec:# Cron 表达式schedule: "**/2 * * * *"# Job 模板jobTemplate:# 运行多少次completions: 5# 并发队列parallelism: 1# 最大执行时间,超过则强制停止actuveDeadlineSecinds: 60# 重试次数backoffLimit: 3template:spec:containers:- name: testimage: xxx:v1command: ["/bin/sh", "-c", "sleep 20"]# 默认是Always 始终重启,单对于Job 建议禁用restartPolicy: Never

若有收获,就点个赞吧
0 人点赞
