1. map 为什么是无序的?我要有序的map怎么办?
1.1 首先知道map的底层结构大概是个什么样的,如下图
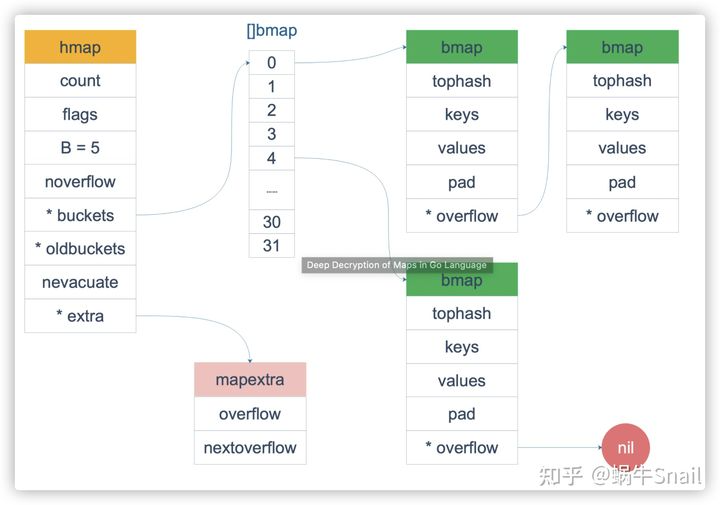
1.2 逻辑推论可以做到有序遍历吗?
如果只按照上面的图,逻辑上我只要遍历buckets这个链表,然后再跟着overflow这个指针继续遍历就可以做到“有序”
1.3 为什么实际遍历的时候不是有序的呢?
第一点:原生遍历map的函数中插入了随机数,导致无序,代码如下 ```go // 代码位置:runtime/map.go func mapiterinit(t maptype, h hmap, it *hiter) { // 省略一部分代码
// 1,这里会获取一个随机数,实现在下面 r := uintptr(fastrand()) if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
} // 2,这里会根据随机数决定一个bucket遍历的起点 it.startBucket = r & bucketMask(h.B) it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state it.bucket = it.startBucket
// Remember we have an iterator. // Can run concurrently with another mapiterinit(). if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {
atomic.Or8(&h.flags, iterator|oldIterator)
}
mapiternext(it) }
// 代码位置:runtime/stubs.go func fastrand() uint32 { mp := getg().m s1, s0 := mp.fastrand[0], mp.fastrand[1] s1 ^= s1 << 17 s1 = s1 ^ s0 ^ s1>>7 ^ s0>>16 mp.fastrand[0], mp.fastrand[1] = s0, s1 return s0 + s1 }
- **第二点:为什么明明逻辑上可以有序,却要加入随机数?**- 1,因为这只是从第一张图看上去可以做到有序,而实际遍历map中,要考虑[扩容](https://www.zhihu.com/search?q=%E6%89%A9%E5%AE%B9&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22article%22%2C%22sourceId%22%3A379441510%7D)的影响- 2,假设发生扩容情况下,两次遍历的情况- 第一次遍历,第一个bucket中的元素在前面- map发生扩容,导致第一个bucket中的元素被分配到了后面的bucket- 第二次遍历,遍历出来的结果就和第一次不一样了- 3,所以如果golang不加入随机数,那么**不排除不熟悉此原理的开发者**,在没有遇到扩容的情况下就会以为map是有序的。**从而依赖这个特性,引发bug**。所以golang就直接通过加随机数避免这种问题<a name="xkIVY"></a>### 1.4 我要有序的map怎么办?- 1,自己实现一个有序的map,这个比较复杂=-=,需要点东西,先不讲- 2,把无序的map做一个排序- 第一种办法:针对key排序,则可以把key取出来做一个list,然后针对list进行排序,然后再回原map进行取值即可- 第二种办法:针对key或者value排序,可以通过实现排序的接口实现<a name="PuG0y"></a>## 2 map 为什么并发读写会报Panic?怎么解决?<a name="YhHUz"></a>### 2.1 为什么并发读写会报Panic ?- **因为代码里面有做限制,代码如下**```go// 文件位置:runtime/map.go// 1,读取数据的时候会检查是否正在写入if h.flags&hashWriting != 0 {throw("concurrent map read and map write")}// 2,赋值的时候也会检查是否在写入if h.flags&hashWriting != 0 {throw("concurrent map writes")}
- 为什么代码要做出不允许同时读写这样的限制?
因为如果多个groutine对同一块内存地址进行操作,可能导致这块内存的数据错乱
2.2 怎么解决并发读写的问题?
- 1,通过 sync.Mutex 进行加锁
- 2,使用 sync.map 替换map
3,如果是读多写少的情况,则可以使用sync.RWMutex
2.3 为什么golang不原生支持map并发?
原因:因为如果原生就支持map并发的话,需要加锁,而如果加锁的话map的性能则会下降,但其实有很多场景map是不会多线程同时进行读写的
扩展:如果要使用锁来支持并发有没有什么性能优化方案?
- 1,可以参考java的ConcurrentHashmap的分段锁实现。简单的理解可以为数据库分库分表,提高读写性能
- 2,golang 本身的sync.map的实现也是一种,通过数据冗余来实现
3. map不常见但也值得思考的一些点
3.1 什么值可以做map的key?为什么?float可以吗?
key 可以是很多种类型,比如 bool, 数字,string, 指针, channel , 还有 只包含前面几个类型的 interface types, structs, arrays
float 可以做map的key吗?
可以,但建议慎用。因为float64会被转换成unit64类型后做map的key,所以可能出现偏差
3.3 map的key可以取地址吗?
不可以,代码如下
func TestMain1(t *testing.T) {testMap := make(map[int]bool)testMap[1] = truetestMap[2] = truefmt.Println(&testMap[1]) // 这里无法编译通过}
原因还是因为扩容,key的内存地址可能因为扩容而导致发生变化
4. 问题:map 嵌套结构体的问题
4.1 问题一:以下代码有什么问题?
```go type Student struct { name string }
func main() { m := map[string]Student{“people”: {“zhoujielun”}} m[“people”].name = “wuyanzu” // cannot assign to struct field m[“people”].name in map }
- 原因是 map 元素是无法取址的,也就说可以得到 m["people"], 但是无法对其进行修改。- 解决方案如下```gotype Student struct {name string}func main() {m := make(map[string]*Student)m["people"] = &Student{"ds"}m["people"].name = "d"}

若有收获,就点个赞吧
0 人点赞
