我们抓取数据可以使用java语言和工具,但是java语言工业性比较强,可以学习简洁强大的Python语言,实现网页抓取技术,解答诸多常见问题,掌握从数据爬取到数据清洗全流程的系统实践指南。
瑞安《Python网络爬虫权威指南第2版》中文PDF+英文PDF+源代码
《Python网络爬虫权威指南第2版》中文PDF,266页,带目录,文字可复制;英文PDF,306页,带书签,文字可复制;配套源代码。
下载: https://pan.baidu.com/s/1LPFT-Uho-1LbwjbjcyBe9g
提取码: 7bmx
对那些没有学过编程的人来说,计算机编程看着就像变魔术。如果编程是魔术(magic),那么网页抓取(Web scraping)就是巫术(wizardry),也就是运用“魔术”来实现精彩实用却又不费吹灰之力的“壮举”。 
在我的软件工程师职业生涯中,我几乎没有发现像网页抓取这样的编程实践,可以同时吸引程序员和门外汉的注意。虽然写一个简单的网络爬虫并不难,就是先收集数据,再显示到命令行或.. (更多)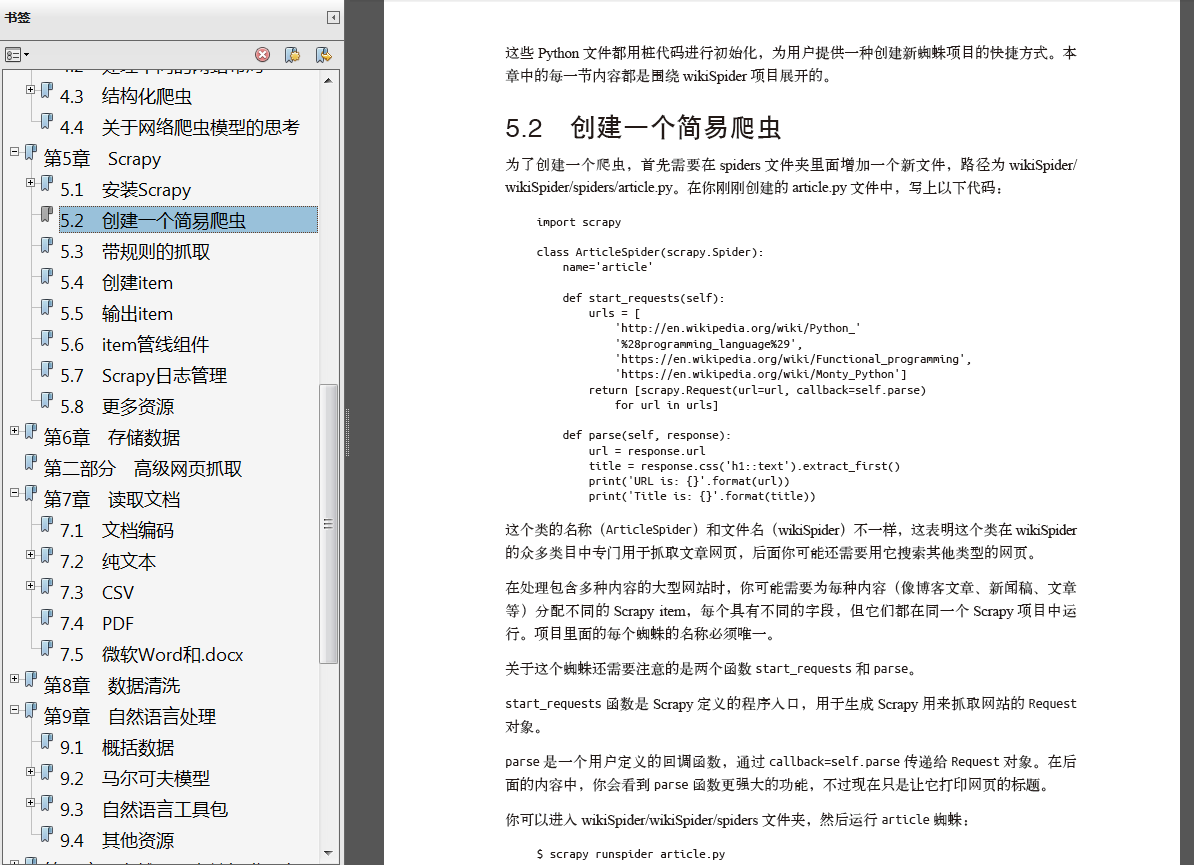
《Python网络爬虫权威指南第2版》中内容分为两部分。第一部分深入讲解网页抓取的基础知识,重点介绍BeautifulSoup、Scrapy等Python库的应用。第二部分介绍网络爬虫编写相关的主题,以及各种数据抓取工具和应用程序,帮你深入互联网的每个角落,分析原始数据,获取数据背后的故事,轻松解决遇到的各类网页抓取问题。新增网络爬虫模型、Scrapy和并行网页抓取相关章节。
一旦你开始抓取网页,就会感受到浏览器为我们做的所有细节。网页上如果没有 HTML 文本格式层、CSS 样式层、JavaScript 执行层和图像渲染层,乍看起来会有点儿吓人,学习如何在不借助浏览器帮助的情况下格式化和理解数据。 首先向网络服务器发送 GET 请求(获取网页内容的请求)以获取具体网页,再从网页中读取 HTML 内容,最后做一些简单的信息提取。
学习网络爬虫,解决一些问题,主要涉及以下几个方面:
- 解析复杂的HTML页面
- 使用Scrapy框架开发爬虫
- 学习存储数据的方法
- 从文档中读取和提取数据
- 清洗格式糟糕的数据
- 自然语言处理
- 通过表单和登录窗口抓取数据
- 抓取JavaScript及利用API抓取数据
- 图像识别与文字处理
- 避免抓取陷阱和反爬虫策略
- 使用爬虫测试网站

若有收获,就点个赞吧
0 人点赞
