增量式网络爬虫是指对已下载网页采取增量式更新和只爬取新产生或者已经发生变化的网页的爬虫,它能够在一定程度上保证所爬取的页面尽可能是新的页面。
《实战Python网络爬虫》PDF+代码+黄永祥
《实战Python网络爬虫》PDF,483页;配套源代码。
下载: https://pan.baidu.com/s/1BbFejbRvbnbdu8YQum4Mqg
提取码: 3ww5
聚焦网络爬虫又称主题网络爬虫,是选择性地爬取根据需求的主题相关页面的网络爬虫。与通用网络爬虫相比,聚焦爬虫只需要爬取与主题相关的页面,不需要广泛地覆盖无关的网页,很好地满足一些特定人群对特定领域信息的需求。
只会在需要的时候爬取新产生或发生更新的页面, 并不重新下载没有发生变化的页面, 可有效减少数据下载量,及时更新己爬取的网页,减小时间和空间上的耗费,但是增加了爬取算法的复杂度和实现难度, 基本上这类爬虫
在实际开发中不太普及。
从原理到实践,循序渐进地讲述了使用Python 开发网络爬虫的核心技术。从逻辑上可分为基础篇、实战篇和爬虫框架篇三部分。基础篇主要介绍了编写网络爬虫所需的基础知识,包括网站分析、数据抓取、数据清洗和数据入库。网站分析讲述如何使用Chrome 和Fiddler 抓包工具对网站做全面分析;数据抓取介绍了Python爬虫模块Urllib 和Requests 的基础知识;数据清洗主要介绍字符串操作、正则和BeautifulSoup的使用;数据库讲述了MySQL 和MongoDB 的操作,通过ORM 框架SQLAlchemy 实现数据持久化,进行企业级开发。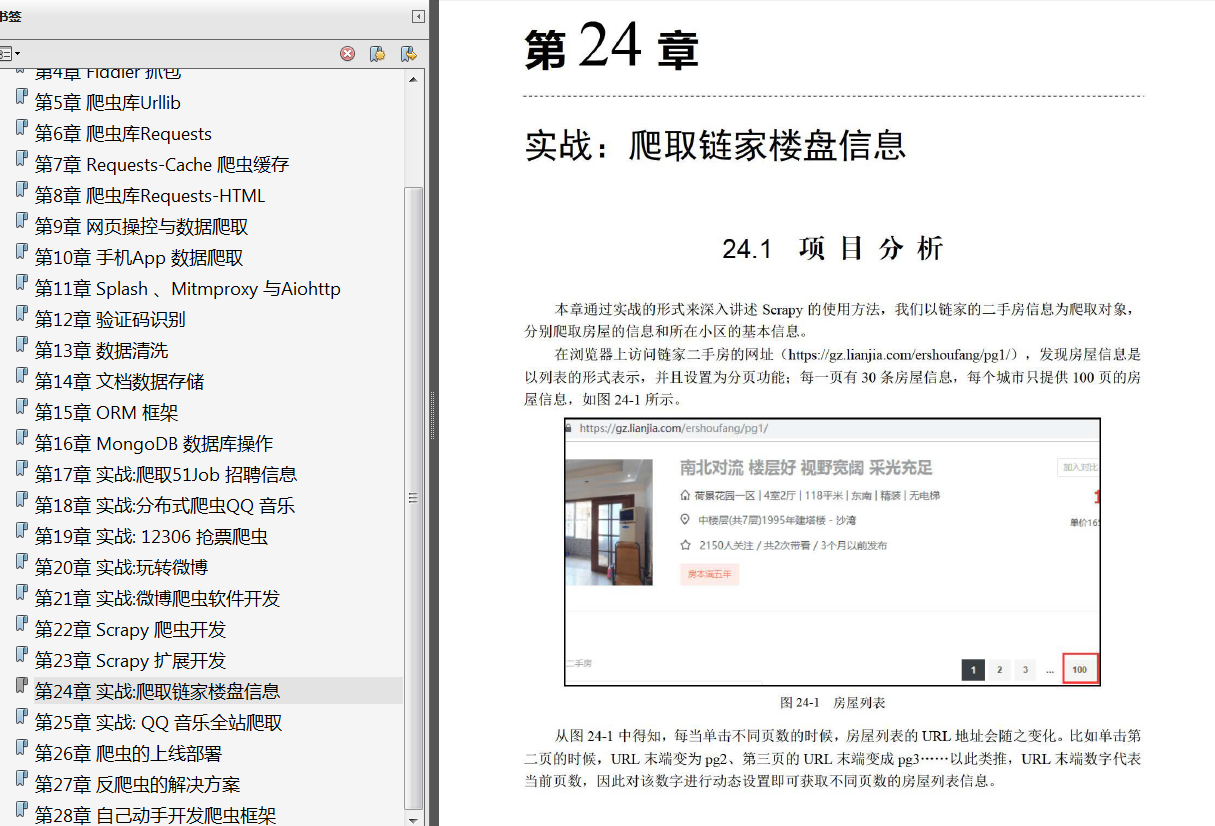
实战篇深入讲解, 了分布式爬虫、爬虫软件的开发、12306 抢票程序和微博爬取等。框架篇主要讲述流行的爬虫框架Scrapy ,并以Scrapy 与Selenium、Splash、Redi s 结合的项目案例,深层次了解Scrapy 的使用,还介绍了爬虫的上线部署、如何自己动手开发一款爬虫框架、反爬虫技术的解决方案等内容。

若有收获,就点个赞吧
0 人点赞
