tags: springbatch
1.引言
前面《数据批处理神器-Spring Batch(1)简介及使用场景》已经介绍了Spring Batch是一个轻量级,完善的批处理框架,它使用起来简单,方便,比较适合有点编程基础(特别是使用Spring及SpringBoot框架)的开发人员,针对业务编程,只需要关心具体的业务实现即可,把流程以及流程的控制交给Spring Batch就好。常言道”talk is cheap, show me the code“,下面我们就通过一个简单的hello world,进入Spring Batch的世界,通过这个示例,可以快速了解开发批处理的流程和Spring Batch开发用到的组件,为后续的操作打下基础。
2.开发环境
- JDK: jdk1.8
- Spring Boot: 2.1.4.RELEASE
- Spring Batch:4.1.2.RELEASE
- 开发IDE: IDEA
- 构建工具Maven: 3.3.9
- 日志组件logback:1.2.3
- lombok:1.18.6
3.helloworld开发
3.1 helloworld说明
本helloworld实现一个非常简单的功能,就是从数据组中读取字符串,把字符串转为大写,然后输出到控制台。如图:
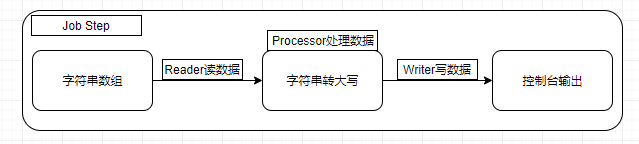
字符串读写整个过程就是一个批重任务(Job),它只有一个步骤(Job Step),步骤里分为三个阶段,读数据(ItemReader)、处理数据(ItemProcessor)、写数据(ItemWriter)。
3.2 开发流程
开发的主要代码如下:
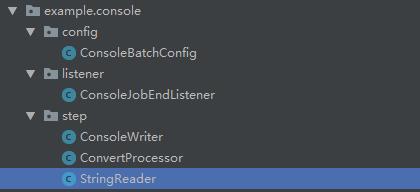
总体来说就是,通过Reader,Processor、Writer完成任务,结束后通过Listener进行监听,整个任务通过配置(BatchConfig)进行配置。
3.2.1 创建Spring Boot工程
直接使用Idea生成或在使用Spring Initializr生成即可,此处不详细说明。也可以直接使用我的代码示例。当前使用的Spring Boot版本是2.1.4.RELEASE
3.2.2 添加相关依赖
Spring Batch依赖 在使用spring-boot-starter-parent的情况下,直接添加以下依赖即可:<!-- 批处理框架--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-batch</artifactId></dependency>
引用后,会引用两个jar包,一个是
spring-batch-infrastructure,一个是spring-batch-core,版本是4.1.2.RELEASE。分别对应的是基础框架层和核心层。添加内存数据库H2
Spring Batch是需要数据库来存储任务的基本信息以及运行状态的,本例中不需要操作数据库逻辑,直接使用内存数据库H2即可。添加以下依赖:<dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId></dependency>
添加测试及工具类依赖 为了简化开发,使用
lombok进行处理。使用Spring Boot进行单元测试,添加依赖如下:<!-- 工具包:lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.6</version></dependency><!-- 测试框架 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
3.2.3 开发读数据组件ItemReader
添加完依赖后,就可以进入业务逻辑编程了。按
Spring Batch的批处理流程,读数据ItemReader是第一步,当前示例中,我们的任务是从数组中读取数据。ItemReader是一个接口,开发人员直接实现此接口即可。此接口定义了核心方法read(),负责从给定的资源中读取可用的数据。具体实现如下:@Slf4jpublic class StringReader implements ItemReader<String> {private String[] messages = {"aaa1","aaa2","aaa3","aaa4"};private int count = 0;@Overridepublic String read() throws UnexpectedInputException, ParseException, NonTransientResourceException {if(count < messages.length){String message = messages[count++];log.debug(LogConstants.LOG_TAG + "read data:"+message);return message;}else{log.debug(LogConstants.LOG_TAG + "read data end.");count = 0;}return null;}}
说明:
(1)StringReader实现ItemReader接口;
- (2)messages是数据源;
- (3)count表示读取数据的下标,每读一次,下标自增,读取完后返回null表示结束。同时把count置为0,以方便下次读取。
(4)日志输出使用的是logback,结合lombok的
@Slf4j注解,直接可使用log进行输出,简化操作。3.2.4 开发处理数据组件ItemProcessor
读取数据后,返回的数据会流到
ItemProcessor进行处理。同样,ItemProcessor是一个接口,要实现自己的处理逻辑,实现此接口即可。当然,如果没有ItemProcessor,读到的数据直接就到ItemWriter流程也是可以的。此处,Spring Batch有一个Chunk的概念,用于多次读,直到chunk指定的数量后,再统一给到processor和writer,以提高效率。本示例对于ItemProcessor的实现很简单,即把字符串转为大写。如下:@Slf4jpublic class ConvertProcessor implements ItemProcessor<String,String> {@Autowiredprivate ConsoleService consoleService;@Overridepublic String process(String data) {String dataProcessed = consoleService.convert2UpperCase(data);log.debug(LogConstants.LOG_TAG + data +" process data --> " + dataProcessed);return dataProcessed;}}
说明:
实现ItemProcessor接口,它有两个泛型,分别是I和O,I是读阶段获取的数据,O是提交给写阶段的数据。
- 使用ConsoleService服务,对数据进行大写转换,里面的实现直接使用字符串的
toUpperCase()方法3.2.5 开发写数据组件ItemWriter
数据处理完后,会统一交给写组件(ItemWriter)进行写入。ItemWriter也是一个接口,核心方法是write方法,参数是数组。要实现自己的逻辑,实现此接口即可。本示例中,直接把数据输出到日志中即可。如下:@Slf4jpublic class ConsoleWriter implements ItemWriter<String> {@Overridepublic void write(List<? extends String> list) {for (String msg :list) {log.debug(LogConstants.LOG_TAG + "write data: "+msg);}}}
3.2.6 开发任务完成后的监听器JobExecutionListener
数据写入到目标后,任务即结束,但有时候我们还需要在任务结束时去做一些其它工作,如清理数据,更新时间等,则需要在任务完成后进行逻辑处理。Spring Batch对于任务或步骤开始和结束都会提供监听,以便于开发人员实现监听逻辑。如通过继承JobExecutionListenerSupport,可以实现beforeJob和afterJob的监听,以实现开始任务前和结束任务后的处理。当前示例中,仅输出任务完成的日志。如下:@Slf4jpublic class ConsoleJobEndListener extends JobExecutionListenerSupport {@Overridepublic void afterJob(JobExecution jobExecution) {if(jobExecution.getStatus() == BatchStatus.COMPLETED){log.debug("console batch job complete!");}}}
3.2.7 配置完整任务
经过上面的读、处理、写、任务完成后监听的操作,现在需要把它们组装在一起,形成一个完成的任务,使用Spring Boot,简单的使用几个配置即可完成任务的组装。任务及其相关组件的关系如下: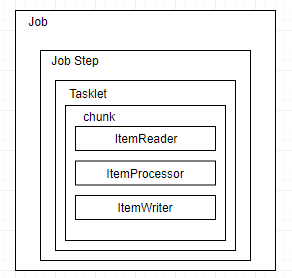
创建配置文件ConsoleBatchConfig.java,具体代码如下:
@Configuration@EnableBatchProcessingpublic class ConsoleBatchConfig {@Autowiredpublic JobBuilderFactory jobBuilderFactory;@Autowiredpublic StepBuilderFactory stepBuilderFactory;@Beanpublic Job consoleJob(Step consoleStep,JobExecutionListener consoleListener){String funcName = Thread.currentThread().getStackTrace()[1].getMethodName();return jobBuilderFactory.get(funcName).listener(consoleListener).flow(consoleStep).end().build();}@Beanpublic Step consoleStep(ItemReader stringReader,ItemProcessor convertProcessor,ItemWriter consoleWriter, CommonStepListener commonStepListener){String funcName = Thread.currentThread().getStackTrace()[1].getMethodName();return stepBuilderFactory.get(funcName).listener(commonStepListener).<String,String>chunk(3).reader(stringReader).processor(convertProcessor).writer(consoleWriter).build();}@Beanpublic ItemReader stringReader(){return new StringReader();}@Beanpublic ItemWriter consoleWriter(){return new ConsoleWriter();}@Beanpublic ItemProcessor convertProcessor(){return new ConvertProcessor();}@Beanpublic JobExecutionListener consoleListener(){return new ConsoleJobEndListener();}}
说明:
- 添加注解
@Configuration及和@EnableBatchProcessing,标识为配置及启用Spring Batch的配置(可以直接使用JobBuilderFactory及StepBuilderFactory分别用于创建Job和Step)。 - 创建
ItemReader、ItemWriter、ItemProcessor、Listener对应的Bean,以供Step及Job的注入。 - 使用
stepBuilderFactory创建作业Step,其中chunk进行面向块的处理,即多次读取后再写入,提高效率。当前配置是3个为一个chunk。 - 使用
jobBuilderFactory添加step,创建任务。 注意step和Job都需要有对应的名称(
get方法确定),此处直接使用方法名作为Job和Step的名称。3.2.8 测试批处理
经过上面的步骤,已经完成Job的开发,测试则可使用两种方式,一个是编写
Controller,以接口调用的方式运行job,一种编写单元测试。Job的运行 通过
JobLauncher的run方法来运行任务,run方法参数分别是Job和jobParameters,即已配置的Job及job运行的参数。每个任务的区分是通过任务名(jobName)和任务参数(jobParameters)作为区别的,即如果jobName和jobParameters相同,Spring Batch会认为是同一任务,若任务已运行成功,同一任务不会再运行。因此,一般来说,不同的任务,我们的jobParameters可以直接以时间作为参数,以便于区别。生成jobParameters。代码如下:JobParameters jobParameters = new JobParametersBuilder().addLong("time",System.currentTimeMillis()).toJobParameters();
编写单元测试 编写
ConsoleJobTest,加载job,运行测试,如下所示:@RunWith(SpringRunner.class)@SpringBootTest(classes = {MainBootApplication.class,ConsoleBatchConfig.class})@Slf4jpublic class ConsoleJobTest {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate Job consoleJob;public void testConsoleJob2() throws JobParametersInvalidException, JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException {//构建参数JobParameters jobParameters = new JobParametersBuilder().addLong("time",System.currentTimeMillis()).toJobParameters();//执行任务JobExecution run = jobLauncher.run(consoleJob, jobParameters);ExitStatus exitStatus = run.getExitStatus();log.debug(exitStatus.toString());}}
说明:引入
SpringBootTest注解时,需要把Spring Batch任务也引入进来。执行结果输出 执行结果如下图所示:
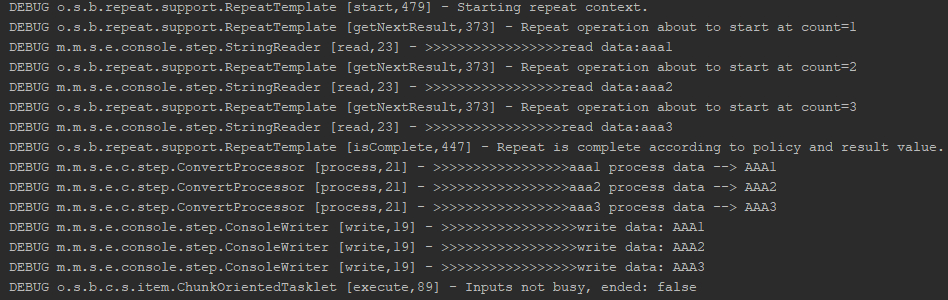
从输出可知,由于设置的chunk是3,读取3个数据后,就统一给ItemProcessor进行大写转换处理,然后统一交给ItemWriter进行写入。执行完成后,Job的exitCode表示任务执行的状态,如果正常则为COMPLETED,失败则为FAILED。
4.总结
经过以上的操作步骤,即可完成批处理操作。关于任务的状态,流程的步骤(读、处理、写)均交给Spring Batch来完成,开发人员所做的工作是根据自己的业务逻辑编写具体的读数据、处理数据和写数据即可。希望通过本文,大家可以对Spring Batch的组件有清晰的了解。

若有收获,就点个赞吧
0 人点赞
