项目实例
https://github.com/Emily0511/LambdaStream
学习来源:
https://zhuanlan.zhihu.com/p/28112239
JDK8为我们提供了一些便捷的Stream相关 类库:
流操作
java.util.stream.Stream中定义了许多流操作的方法,为了更好的理解Stream API掌握它常用的操作非常重要。
流的操作其实可以分为两类:处理操作、聚合操作。
- 处理操作:诸如filter、map等处理操作将Stream一层一层的进行抽离,返回一个流给下一层使用。
- 聚合操作:从最后一次流中生成一个结果给调用方,foreach只做处理不做返回。
filter:
filter看名字也知道是过滤的意思,我们通常在筛选数据的时候用到,频率非常高。
filter方法的参数是Predicatepredicate 即一个从 T 到 boolean 的函数。 
map:
有时候我们需要将流中处理的数据类型进行转换,这时候就可以使用map方法来完成,将流中的值转换为一个新的流。
flatMap:
有时候我们会遇到提取子流的操作,这种情况用的不多但是遇到flatMap将变成更容易处理。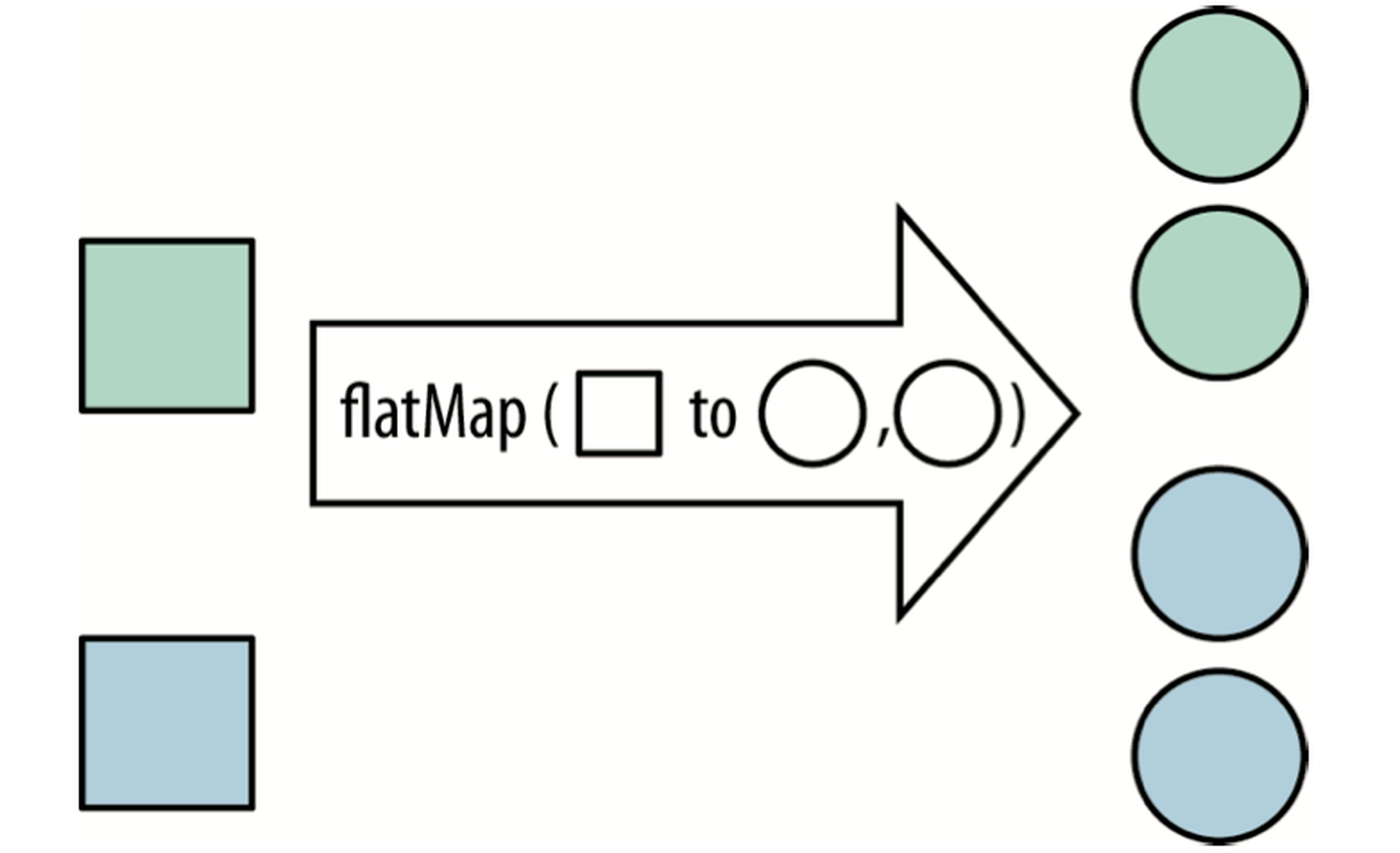
例如我们有一个List
要做的操作是获取这些数据中长度大于2的单词个数List<List<String>> lists = new ArrayList<>();lists.add(Arrays.asList("apple", "click"));lists.add(Arrays.asList("boss", "dig", "qq", "vivo"));lists.add(Arrays.asList("c#", "biezhi"));
在不使用flatMap前你可能需要做2次for循环。这里调用了List的stream方法将每个列表转换成Stream对象,lists.stream().flatMap(Collection::stream).filter(str -> str.length() > 2).count();
其他的就和之前的操作一样。并行数据处理
并行和并发
并发是两个任务共享时间段,并行则是两个任务在同一时间发生,比如运行在多核CPU上。
如果一个程序要运行两个任务,并且只有一个CPU给它们分配了不同的时间片,那么这就是并发,而不是并行。并行化是指为缩短任务执行时间,将一个任务分解成几部分,然后并行执行。
这和顺序执行的任务量是一样的,区别就像用更多的马来拉车,花费的时间自然减少了。
实际上,和顺序执行相比,并行化执行任务时,CPU承载的工作量更大。
数据并行化是指将数据分成块,为每块数据分配单独的处理单元。
还是拿马拉车那个例子打比方,就像从车里取出一些货物,放到另一辆车上,两辆马车都沿着同样的路径到达目的地。
当需要在大量数据上执行同样的操作时,数据并行化很管用。
它将问题分解为可在多块数据上求解的形式,然后对每块数据执行运算,最后将各数据块上得到的结果汇总,从而获得最终答案。
人们经常拿任务并行化和数据并行化做比较,在任务并行化中,线程不同,工作各异。
我们最常遇到的JavaEE应用容器便是任务并行化的例子之一,每个线程不光可以为不同用户服务,
还可以为同一个用户执行不同的任务,比如登录或往购物车添加商品。
Stream并行流
流使得计算变得容易,它的操作也非常简单,但你需要遵守一些约定。默认情况下我们使用集合的stream方法
创建的是一个串行流,你有两种办法让他变成并行流。
- 调用Stream对象的parallel方法
- 创建流的时候调用parallelStream而不是stream方法

若有收获,就点个赞吧
0 人点赞
