什么是Operator
Operator是由CoreOS开发的,用来扩展Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator基于Kubernetes的资源和控制器概念之上构建,但同时又包含了应用程序特定的领域知识。创建Operator的关键是CRD(自定义资源)的设计。Operator是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
- 资源:对象的状态定义
- 控制器:观测、分析和行动,以调节资源的分布
当前CoreOS提供的以下四种Operator:
- etcd:创建etcd集群
- Rook:云原生环境下的文件、块、对象存储服务
- Prometheus:创建Prometheus监控实例
- Tectonic:部署Kubernetes集群
安装
我们这里直接通过 Prometheus-Operator 的源码来进行安装,当然也可以用 Helm 来进行一键安装,我们采用源码安装可以去了解更多的实现细节。首页将源码下下来:
gitlab地址:https://github.com/prometheus-operator/kube-prometheus
下载时要注意版本,官方有推荐的版本对应下载
Kubernetes compatibility matrix
The following versions are supported and work as we test against these versions in their respective branches. But note that other versions might work!
| kube-prometheus stack | Kubernetes 1.14 | Kubernetes 1.15 | Kubernetes 1.16 | Kubernetes 1.17 | Kubernetes 1.18 | Kubernetes 1.19 |
|---|---|---|---|---|---|---|
release-0.3 |
✔ | ✔ | ✔ | ✔ | ✗ | ✗ |
release-0.4 |
✗ | ✗ | ✔ (v1.16.5+) | ✔ | ✗ | ✗ |
release-0.5 |
✗ | ✗ | ✗ | ✗ | ✔ | ✗ |
release-0.6 |
✗ | ✗ | ✗ | ✗ | ✔ | ✔ |
HEAD |
✗ | ✗ | ✗ | ✗ | x | ✔ |
Note: Due to two bugs in Kubernetes v1.16.1, and prior to Kubernetes v1.16.5 the kube-prometheus release-0.4 branch only supports v1.16.5 and higher. The extension-apiserver-authentication-reader role in the kube-system namespace can be manually edited to include list and watch permissions in order to workaround the second issue with Kubernetes v1.16.2 through v1.16.4.
我的kuberbetes的集群地址是 v1.15.9,所以我下载是版本是release-0.3
https://github.com/prometheus-operator/kube-prometheus/tagswget https://github.com/prometheus-operator/kube-prometheus/archive/v0.3.0.tar.gztar zxf v0.3.0.tar.gzcd kube-prometheus-0.3.0/manifests
进入到 manifests 目录下面,这个目录下面包含我们所有的资源清单文件,直接在该文件夹下面执行创建资源命令即可:
kubectl apply -f setup/kubectl apply -f .
部署完成后,会创建一个名为monitoring的 namespace,所以资源对象对将部署在改命名空间下面,此外 Operator 会自动创建4个 CRD 资源对象:
[admin@ch-k8s1 manifests]$ kubectl get crd |grep coreosalertmanagers.monitoring.coreos.com 2020-10-10T07:49:14Zpodmonitors.monitoring.coreos.com 2020-12-01T05:36:48Zprometheuses.monitoring.coreos.com 2020-10-10T07:49:14Zprometheusrules.monitoring.coreos.com 2020-10-10T07:49:14Zservicemonitors.monitoring.coreos.com 2020-10-10T07:49:14Z[admin@ch-k8s1 manifests]$
可以在 monitoring 命名空间下面查看所有的 Pod,其中 alertmanager 和 prometheus 是用 StatefulSet 控制器管理的,其中还有一个比较核心的 prometheus-operator 的 Pod,用来控制其他资源对象和监听对象变化的:
[admin@ch-k8s1 manifests]$ kubectl get pods -n monitoringNAME READY STATUS RESTARTS AGEalertmanager-main-0 2/2 Running 0 24halertmanager-main-1 2/2 Running 0 24halertmanager-main-2 2/2 Running 0 24hgrafana-65446cdfd4-z8vgh 1/1 Running 0 21hkube-state-metrics-7f6d7b46b4-dhg8q 3/3 Running 0 24hnode-exporter-9fhkt 2/2 Running 0 24hnode-exporter-b8gcm 2/2 Running 0 24hnode-exporter-fdfxg 2/2 Running 0 24hnode-exporter-pxz6f 2/2 Running 0 24hnode-exporter-rvrtq 2/2 Running 0 24hnode-exporter-s5pxn 2/2 Running 0 24hprometheus-adapter-68698bc948-5bz6c 1/1 Running 0 24hprometheus-k8s-0 3/3 Running 1 24hprometheus-k8s-1 3/3 Running 1 24hprometheus-operator-6685db5c6-b4s6l 1/1 Running 0 24h
查看创建的 Service:
[admin@ch-k8s1 manifests]$ kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager-main ClusterIP 10.43.160.126 <none> 9093/TCP 24halertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 24hgrafana NodePort 10.43.69.32 <none> 3000/TCP 24hkube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 24hnode-exporter ClusterIP None <none> 9100/TCP 24hprometheus-adapter ClusterIP 10.43.52.173 <none> 443/TCP 24hprometheus-k8s NodePort 10.43.79.240 <none> 9090/TCP 24hprometheus-operated ClusterIP None <none> 9090/TCP 24hprometheus-operator ClusterIP None <none> 8080/TCP 24h
可以看到上面针对 grafana 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果我们想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service,我们这里为了简单,直接使用 NodePort 类型的服务即可,编辑 grafana 和 prometheus-k8s 这两个 Service,将服务类型更改为 NodePort:
[admin@ch-k8s1 manifests]$ kubectl edit svc grafana -n monitoring
spec: clusterIP: 10.43.69.32 externalTrafficPolicy: Cluster ports:
- name: http
nodePort: 30001
port: 3000
protocol: TCP
targetPort: http
selector:
app: grafana
sessionAffinity: None
type: NodePort
spec: clusterIP: 10.43.79.240 externalTrafficPolicy: Cluster ports:[admin@ch-k8s1 manifests]$ kubectl edit svc prometheus-k8s -n monitoring
- name: web
nodePort: 30002
port: 9090
protocol: TCP
targetPort: web
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
type: NodePort
更改完成后,我们就可以通过去访问上面的两个服务了,比如查看 prometheus 的 targets 页面:[admin@ch-k8s1 manifests]$ kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager-main ClusterIP 10.43.160.126 <none> 9093/TCP 24halertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 24hgrafana NodePort 10.43.69.32 <none> 3000:30001/TCP 24hkube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 24hnode-exporter ClusterIP None <none> 9100/TCP 24hprometheus-adapter ClusterIP 10.43.52.173 <none> 443/TCP 24hprometheus-k8s NodePort 10.43.79.240 <none> 9090:30002/TCP 24hprometheus-operated ClusterIP None <none> 9090/TCP 24hprometheus-operator ClusterIP None <none> 8080/TCP 24h
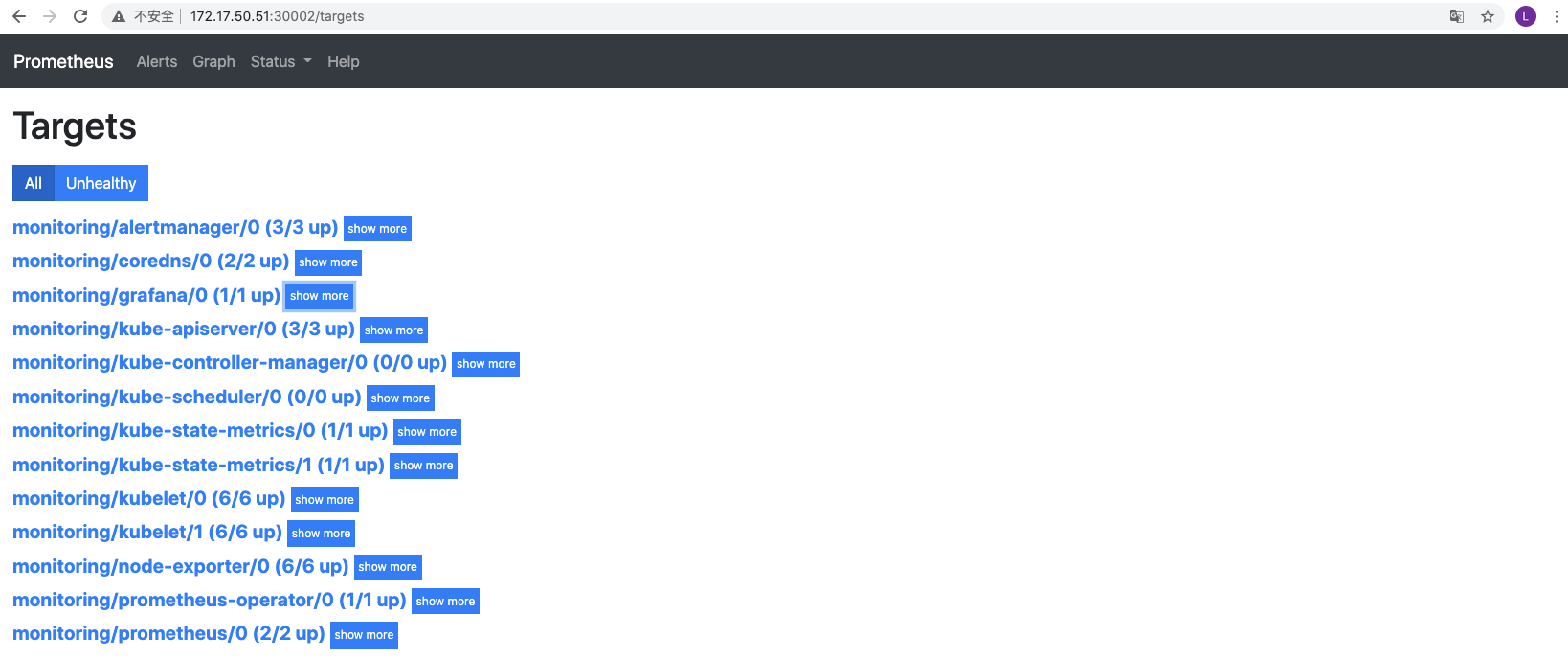
我们可以看到大部分的配置都是正常的,只有两三个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件,这就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义:(prometheus-serviceMonitorKubeScheduler.yaml)配置kube-scheduler
```yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: monitoring spec: endpoints: - interval: 30s #30s获取一次信息
port: http-metrics # 对应service的端口名
jobLabel: k8s-app
namespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any: true matchNames:- kube-system
selector: # 匹配的 Service 的labels,如果使用mathLabels,则下面的所有标签都匹配时才会匹配该service,如果使用matchExpressions,则至少匹配一个标签的service都会被选择
matchLabels:
k8s-app: kube-scheduler
上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过`selector.matchLabels`在 kube-system 这个命名空间下面匹配具有`k8s-app=kube-scheduler`这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service:(prometheus-kubeSchedulerService.yaml)yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: k8s-app: kube-scheduler spec: selector: component: kube-scheduler ports:
- kube-system
selector: # 匹配的 Service 的labels,如果使用mathLabels,则下面的所有标签都匹配时才会匹配该service,如果使用matchExpressions,则至少匹配一个标签的service都会被选择
matchLabels:
k8s-app: kube-scheduler
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
我们可以看到这个 Pod 具有其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,`selector`下面配置的是`component=kube-scheduler`,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduelr 这个 Pod:```yaml$ kubectl describe pod kube-scheduler-k8s-master -n kube-systemName: kube-scheduler-k8s-masterNamespace: kube-systemPriority: 2000000000PriorityClassName: system-cluster-criticalNode: k8s-master/172.16.138.40Start Time: Tue, 19 Feb 2019 21:15:05 -0500Labels: component=kube-schedulertier=control-plane......
component=kube-scheduler和tier=control-plane这两个标签,而前面这个标签具有更唯一的特性,所以使用前面这个标签较好,这样上面创建的 Service 就可以和我们的 Pod 进行关联了,直接创建即可:
创建完成后,隔一小会儿后去 prometheus 查看 targets 下面 kube-scheduler 的状态:$ kubectl create -f prometheus-kubeSchedulerService.yaml$ kubectl get svc -n kube-system -l k8s-app=kube-schedulerNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkube-scheduler ClusterIP 10.103.165.58 <none> 10251/TCP 4m
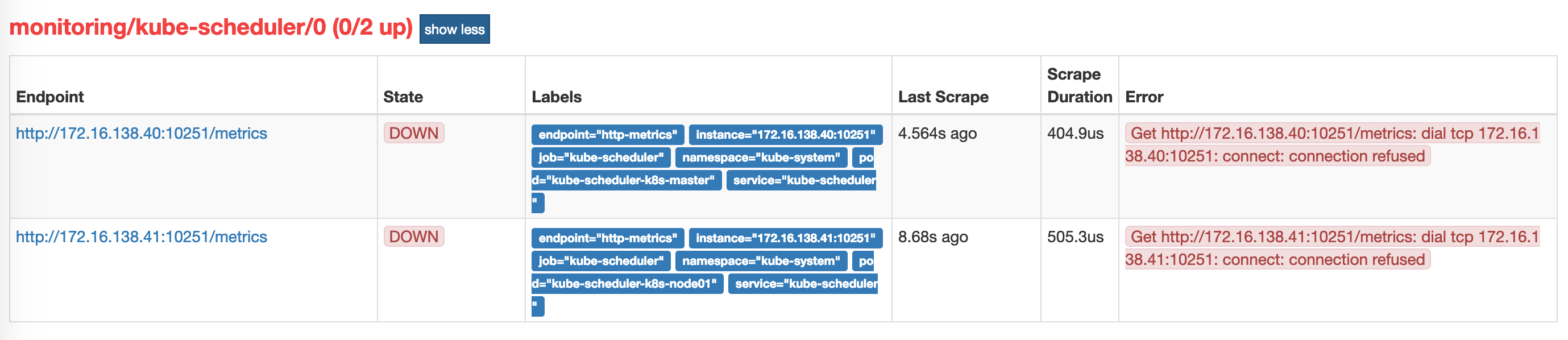 我们可以看到现在已经发现了 target,但是抓取数据结果出错了,这个错误是因为我们集群是使用 kubeadm 搭建的,其中 kube-scheduler 默认是绑定在
我们可以看到现在已经发现了 target,但是抓取数据结果出错了,这个错误是因为我们集群是使用 kubeadm 搭建的,其中 kube-scheduler 默认是绑定在127.0.0.1上面的,而上面我们这个地方是想通过节点的 IP 去访问,所以访问被拒绝了,我们只要把 kube-scheduler 绑定的地址更改成0.0.0.0即可满足要求,由于 kube-scheduler 是以静态 Pod 的形式运行在集群中的,所以我们只需要更改静态 Pod 目录下面对应的 YAML (kube-scheduler.yaml)文件即可: ```yaml $ cd /etc/kubernetes/manifests 将 kube-scheduler.yaml 文件中-command的—address地址更改成0.0.0.0 $ vim kube-scheduler.yaml apiVersion: v1 kind: Pod metadata: annotations: scheduler.alpha.kubernetes.io/critical-pod: “” creationTimestamp: null labels: component: kube-scheduler tier: control-plane name: kube-scheduler namespace: kube-system spec: containers: - command:
- kube-scheduler
- —address=0.0.0.0
- —kubeconfig=/etc/kubernetes/scheduler.conf
- —leader-elect=true
….
```
修改完成后我们将该文件从当前文件夹中移除,隔一会儿再移回该目录,就可以自动更新了,然后再去看 prometheus 中 kube-scheduler 这个 target 是否已经正常了:
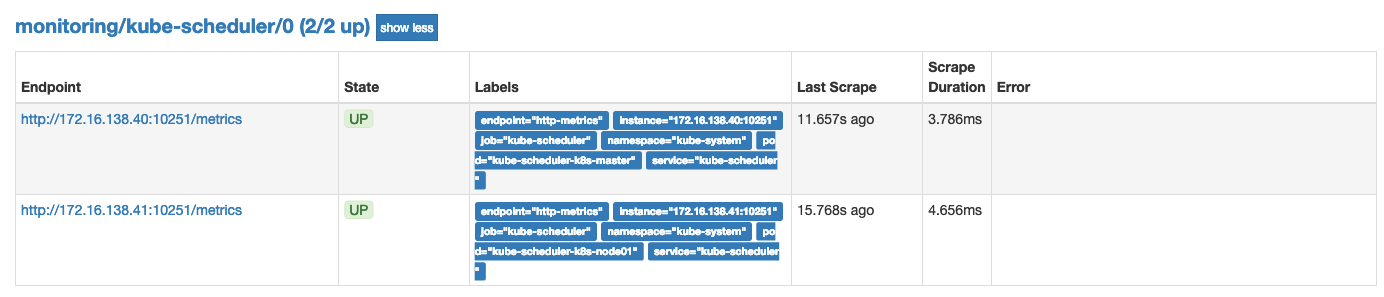
配置kube-controller-manager
我们来查看一下kube-controller-manager的ServiceMonitor资源的定义: ```yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: kube-controller-manager name: kube-controller-manager namespace: monitoring spec: endpoints:
- interval: 30s
metricRelabelings:
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- name port: http-metrics jobLabel: k8s-app namespaceSelector: matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
创建svc ```yaml apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: selector: component: kube-controller-manager ports:上面我们可以看到是通过k8s-app: kube-controller-manager这个标签选择的service,但系统中没有这个service。这里我们手动创建一个:<br />创建前我们需要看确定pod的标签:```yaml$ kubectl describe pod kube-controller-manager-k8s-master -n kube-systemName: kube-controller-manager-k8s-masterNamespace: kube-systemPriority: 2000000000PriorityClassName: system-cluster-criticalNode: k8s-master/172.16.138.40Start Time: Tue, 19 Feb 2019 21:15:16 -0500Labels: component=kube-controller-managertier=control-plane....
- action: drop
regex: etcd_(debugging|disk|request|server).*
sourceLabels:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
创建完后,我们查看targer<br />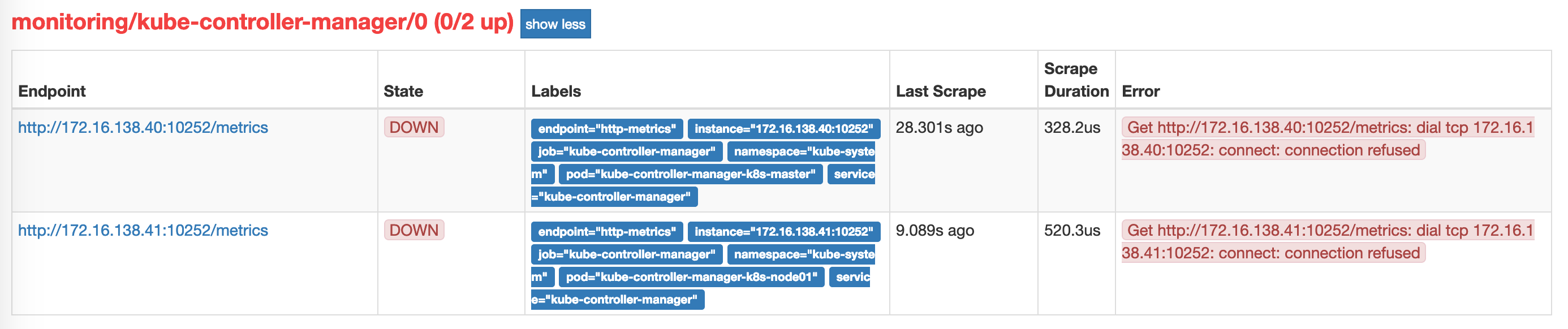<br />这里和上面是同一个问题。让我们使用上面的方法修改。让我们修改kube-controller-manager.yaml:yaml apiVersion: v1 kind: Pod metadata: annotations: scheduler.alpha.kubernetes.io/critical-pod: “” creationTimestamp: null labels: component: kube-controller-manager tier: control-plane name: kube-controller-manager namespace: kube-system spec: containers: - command:
- kube-controller-manager
- —node-monitor-grace-period=10s
- —pod-eviction-timeout=10s
- —address=0.0.0.0 #修改
……
```
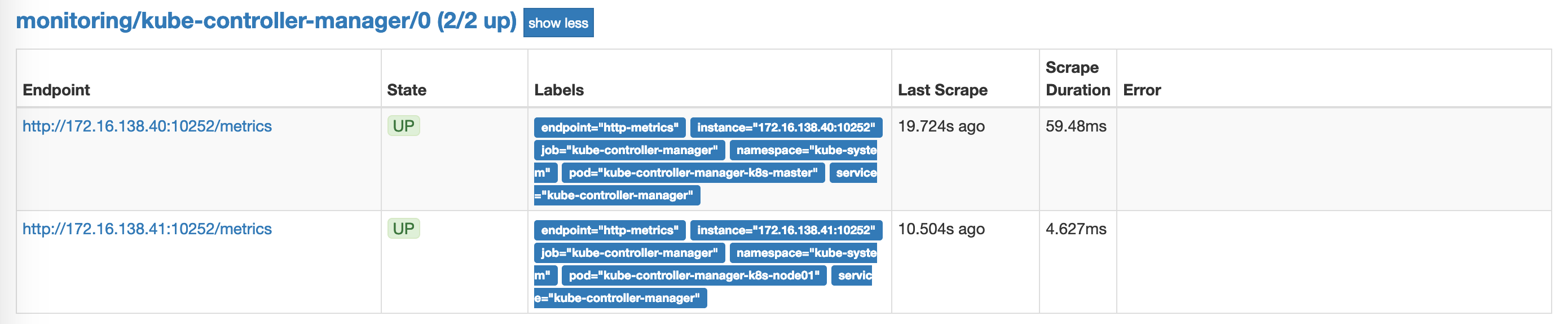
修改完成后我们将该文件从当前文件夹中移除,隔一会儿再移回该目录,就可以自动更新了,然后再去看 prometheus 中 kube-controller-manager 这个 target 是否已经正常了:
上面的监控数据配置完成后,现在我们可以去查看下 grafana 下面的 dashboard,同样使用上面的 NodePort 访问即可,第一次登录使用 admin:admin 登录即可,进入首页后,可以发现已经和我们的 Prometheus 数据源关联上了,正常来说可以看到一些监控图表了:
配置 PrometheusRule
现在我们知道怎么自定义一个 ServiceMonitor 对象了,但是如果需要自定义一个报警规则的话呢?比如现在我们去查看 Prometheus Dashboard 的 Alert 页面下面就已经有一些报警规则了,还有一些是已经触发规则的了:
但是这些报警信息是哪里来的呢?他们应该用怎样的方式通知我们呢?我们知道之前我们使用自定义的方式可以在 Prometheus 的配置文件之中指定 AlertManager 实例和 报警的 rules 文件,现在我们通过 Operator 部署的呢?我们可以在 Prometheus Dashboard 的 Config 页面下面查看关于 AlertManager 的配置: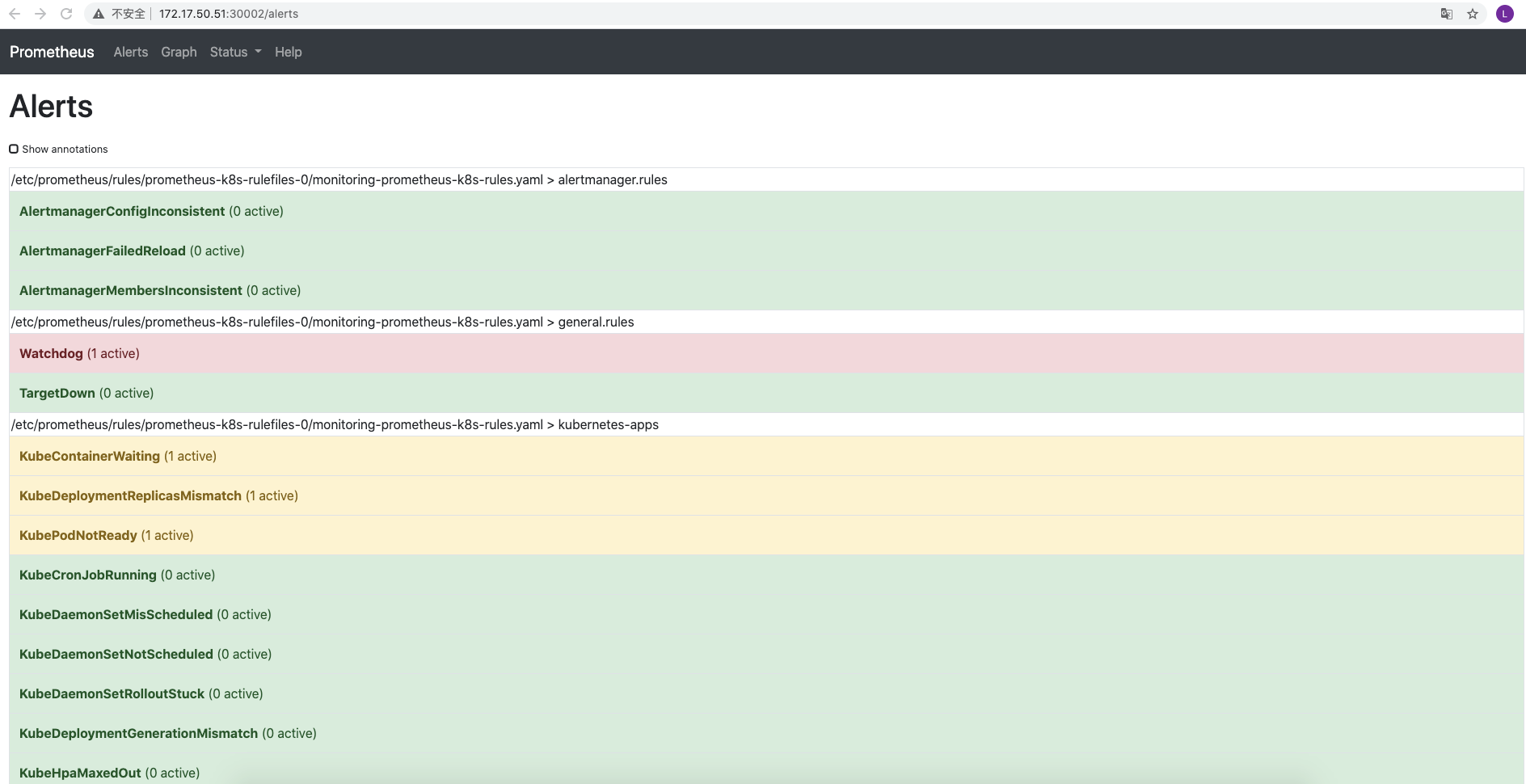
但是这些报警信息是哪里来的呢?他们应该用怎样的方式通知我们呢?我们知道之前我们使用自定义的方式可以在 Prometheus 的配置文件之中指定 AlertManager 实例和 报警的 rules 文件,现在我们通过 Operator 部署的呢?我们可以在 Prometheus Dashboard 的 Config 页面下面查看关于 AlertManager 的配置:
alerting:alert_relabel_configs:- separator: ;regex: prometheus_replicareplacement: $1action: labeldropalertmanagers:- kubernetes_sd_configs:- role: endpointsnamespaces:names:- monitoringscheme: httppath_prefix: /timeout: 10sapi_version: v1relabel_configs:- source_labels: [__meta_kubernetes_service_name]separator: ;regex: alertmanager-mainreplacement: $1action: keep- source_labels: [__meta_kubernetes_endpoint_port_name]separator: ;regex: webreplacement: $1action: keeprule_files:- /etc/prometheus/rules/prometheus-k8s-rulefiles-0/*.yaml
上面 alertmanagers 实例的配置我们可以看到是通过角色为 endpoints 的 kubernetes 的服务发现机制获取的,匹配的是服务名为 alertmanager-main,端口名未 web 的 Service 服务,我们查看下 alertmanager-main 这个 Service:
[admin@ch-k8s1 ~]$ kubectl get svc alertmanager-main -n monitoring -o yamlapiVersion: v1kind: Servicemetadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"alertmanager":"main"},"name":"alertmanager-main","namespace":"monitoring"},"spec":{"ports":[{"name":"web","port":9093,"targetPort":"web"}],"selector":{"alertmanager":"main","app":"alertmanager"},"sessionAffinity":"ClientIP"}}creationTimestamp: "2020-12-02T09:15:28Z"labels:alertmanager: mainname: alertmanager-mainnamespace: monitoringresourceVersion: "11875829"selfLink: /api/v1/namespaces/monitoring/services/alertmanager-mainuid: 7e191c6c-0add-4931-b0fc-b12645ad6bb7spec:clusterIP: 10.43.56.30ports:- name: webport: 9093protocol: TCPtargetPort: webselector:alertmanager: mainapp: alertmanagersessionAffinity: ClientIPsessionAffinityConfig:clientIP:timeoutSeconds: 10800type: ClusterIPstatus:loadBalancer: {}
可以看到服务名正是 alertmanager-main,Port 定义的名称也是 web,符合上面的规则,所以 Prometheus 和 AlertManager 组件就正确关联上了。而对应的报警规则文件位于:/etc/prometheus/rules/prometheus-k8s-rulefiles-0/目录下面所有的 YAML 文件。我们可以进入 Prometheus 的 Pod 中验证下该目录下面是否有 YAML 文件:
[admin@ch-k8s1 ~]$ kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoringkubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.Defaulting container name to prometheus.Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod./prometheus $ cat /etc/prometheus/rules/prometheus-k8s-rulefiles-0/monitoring-prometheus-k8s-rules.yamlgroups:- name: node-exporter.rulesrules:- expr: |count without (cpu) (count without (mode) (node_cpu_seconds_total{job="node-exporter"}))record: instance:node_num_cpu:sum- expr: |1 - avg without (cpu, mode) (rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m]))record: instance:node_cpu_utilisation:rate1m- expr: |(........
这个 YAML 文件实际上就是我们之前创建的一个 PrometheusRule 文件包含的:
[admin@ch-k8s1 manifests]$ cat prometheus-rules.yamlapiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata:labels:prometheus: k8srole: alert-rulesname: prometheus-k8s-rulesnamespace: monitoringspec:groups:- name: node-exporter.rulesrules:- expr: |count without (cpu) (count without (mode) (node_cpu_seconds_total{job="node-exporter"}))record: instance:node_num_cpu:sum- expr: |1 - avg without (cpu, mode) (rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m]))record: instance:node_cpu_utilisation:rate1m- expr: |(node_load1{job="node-exporter"}/instance:node_num_cpu:sum{job="node-exporter"})record: instance:node_load1_per_cpu:ratio.........
我们这里的 PrometheusRule 的 name 为 prometheus-k8s-rules,namespace 为 monitoring,我们可以猜想到我们创建一个 PrometheusRule 资源对象后,会自动在上面的 prometheus-k8s-rulefiles-0 目录下面生成一个对应的<namespace>-<name>.yaml文件,所以如果以后我们需要自定义一个报警选项的话,只需要定义一个 PrometheusRule 资源对象即可。至于为什么 Prometheus 能够识别这个 PrometheusRule 资源对象呢?这就需要查看我们创建的 prometheus 这个资源对象了,里面有非常重要的一个属性 ruleSelector,用来匹配 rule 规则的过滤器,要求匹配具有 prometheus=k8s 和 role=alert-rules 标签的 PrometheusRule 资源对象,现在明白了吧?
ruleSelector:matchLabels:prometheus: k8srole: alert-rules
所以我们要想自定义一个报警规则,只需要创建一个具有 prometheus=k8s 和 role=alert-rules 标签的 PrometheusRule 对象就行了,比如现在我们添加一个自定义的报警,创建文件 prometheus-blackboxRules.yaml:
apiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata:labels:prometheus: k8srole: alert-rulesname: blackbox-rulesnamespace: monitoringspec:groups:- name: blackbox_network_statsrules:- alert: blackbox_network_statsexpr: probe_success == 0for: 1mlabels:severity: criticalannotations:summary: "Instance {{ $labels.instance }} is down"description: "This requires immediate action!"- name: ssl_expiry.rulesrules:- alert: SSLCertExpiringSoonexpr: (probe_ssl_earliest_cert_expiry{job="blackbox_ssl_expiry"} - time())/86400 < 30for: 10mlabels:severity: warnannotations:summary: "ssl证书过期警告"description: '域名{{$labels.instance}}的证书还有{{ printf "%.1f" $value }}天就过期了,请尽快更新证书'- name: 主机状态-监控告警rules:- alert: 主机状态expr: up == 0for: 1mlabels:severity: criticalannotations:summary: "{{$labels.instance}}:服务器宕机"description: "{{$labels.instance}}:服务器延时超过5分钟"- alert: CPU使用情况expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60for: 1mlabels:severity: warnannotations:summary: "{{$labels.mountpoint}} CPU使用率过高!"description: "{{$labels.mountpoint }} CPU使用大于60%(目前使用:{{$value}}%)"- alert: 内存使用expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80for: 1mlabels:severity: warnannotations:summary: "{{$labels.mountpoint}} 内存使用率过高!"description: "{{$labels.mountpoint }} 内存使用大于80%(目前使用:{{$value}}%)"- alert: IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 1mlabels:severity: warnannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 网络expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 1mlabels:severity: warnannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 1mlabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 1mlabels:severity: warnannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
注意 label 标签一定至少要有 prometheus=k8s 和 role=alert-rules,创建完成后,隔一会儿再去容器中查看下 rules 文件夹:
[admin@ch-k8s1 new]$ kubectl exec -it prometheus-k8s-0 -n monitoring -- /bin/shDefaulting container name to prometheus.Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod./prometheus $ cd /etc/prometheus/rules/prometheus-k8s-rulefiles-0//etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ ls -ltotal 0lrwxrwxrwx 1 root 2000 37 Dec 2 09:52 monitoring-blackbox-rules.yaml -> ..data/monitoring-blackbox-rules.yamllrwxrwxrwx 1 root root 43 Dec 2 09:15 monitoring-prometheus-k8s-rules.yaml -> ..data/monitoring-prometheus-k8s-rules.yaml/etc/prometheus/rules/prometheus-k8s-rulefiles-0 $ lsmonitoring-blackbox-rules.yaml monitoring-prometheus-k8s-rules.yaml
可以看到我们创建的 rule 文件已经被注入到了对应的 rulefiles 文件夹下面了,证明我们上面的设想是正确的。然后再去 Prometheus Dashboard 的 Alert 页面下面就可以查看到上面我们新建的报警规则了: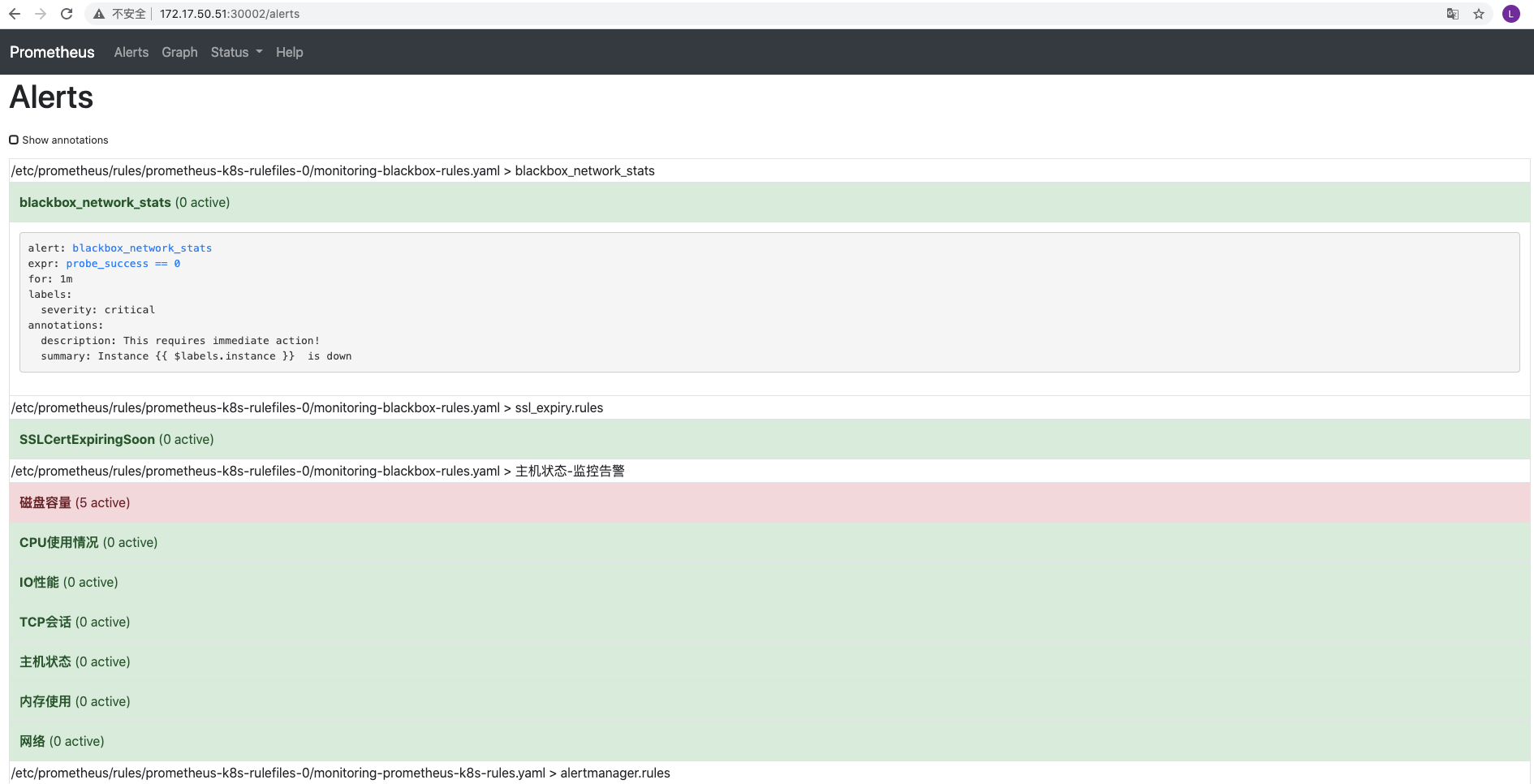
配置报警
我们知道了如何去添加一个报警规则配置项,但是这些报警信息用怎样的方式去发送呢?前面的课程中我们知道我们可以通过 AlertManager 的配置文件去配置各种报警接收器,现在我们是通过 Operator 提供的 alertmanager 资源对象创建的组件,应该怎样去修改配置呢?
首先我们将 alertmanager-main 这个 Service 改为 NodePort 类型的 Service,修改完成后我们可以在页面上的 status 路径下面查看 AlertManager 的配置信息:
.....selector:alertmanager: mainapp: alertmanagersessionAffinity: ClientIPsessionAffinityConfig:clientIP:timeoutSeconds: 10800.....

这些配置信息实际上是来自于我们之前在kube-prometheus-0.3.0/manifests/目录下面创建的 alertmanager-secret.yaml 文件:
[admin@ch-k8s1 manifests]$ cat alertmanager-secret.yamlapiVersion: v1data:alertmanager.yaml: Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAibnVsbCIKInJvdXRlIjoKICAiZ3JvdXBfYnkiOgogIC0gImpvYiIKICAiZ3JvdXBfaW50ZXJ2YWwiOiAiNW0iCiAgImdyb3VwX3dhaXQiOiAiMzBzIgogICJyZWNlaXZlciI6ICJudWxsIgogICJyZXBlYXRfaW50ZXJ2YWwiOiAiMTJoIgogICJyb3V0ZXMiOgogIC0gIm1hdGNoIjoKICAgICAgImFsZXJ0bmFtZSI6ICJXYXRjaGRvZyIKICAgICJyZWNlaXZlciI6ICJudWxsIg==kind: Secretmetadata:name: alertmanager-mainnamespace: monitoringtype: Opaque
可以将 alertmanager.yaml 对应的 value 值做一个 base64 解码:
[admin@ch-k8s1 manifests]$ echo Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAibnVsbCIKInJvdXRlIjoKICAiZ3JvdXBfYnkiOgogIC0gImpvYiIKICAiZ3JvdXBfaW50ZXJ2YWwiOiAiNW0iCiAgImdyb3VwX3dhaXQiOiAiMzBzIgogICJyZWNlaXZlciI6ICJudWxsIgogICJyZXBlYXRfaW50ZXJ2YWwiOiAiMTJoIgogICJyb3V0ZXMiOgogIC0gIm1hdGNoIjoKICAgICAgImFsZXJ0bmFtZSI6ICJXYXRjaGRvZyIKICAgICJyZWNlaXZlciI6ICJudWxsIg== | base64 -d
解码出来的结果:
"global":"resolve_timeout": "5m""receivers":- "name": "null""route":"group_by":- "job""group_interval": "5m""group_wait": "30s""receiver": "null""repeat_interval": "12h""routes":- "match":"alertname": "Watchdog""receiver": "null"
我们可以看到内容和上面查看的配置信息是一致的,所以如果我们想要添加自己的接收器,或者模板消息,我们就可以更改这个文件:
global:resolve_timeout: 5msmtp_smarthost: 'smtp.163.com:25' #使用163邮箱smtp_from: 'monitoring2020@163.com' #邮箱名称smtp_auth_username: 'monitoring2020@163.com' #登录邮箱名称smtp_auth_password: 'NHGJPAVAGO00000000' #授权码,不是登陆密码smtp_require_tls: false#wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 企业微信地址# 定义模板信心templates:- 'template/*.tmpl' #模板路径route: #默认路由group_by: ['instance','job'] #根据instance和job标签分组,同标签下的告警会在一个邮件中展现group_wait: 30s # 最初即第一次等待多久时间发送一组警报的通知group_interval: 5m # 在发送新警报前的等待时间repeat_interval: 10h #重复告警间隔receiver: email #默认接收者的名称,以下receivers name的名称routes: #子路由,不满足子路由的都走默认路由- receiver: leadermatch: #普通匹配severity: critical #报警规则中定义的报警级别- receiver: support_teammatch_re: #正则匹配severity: ^(warn|critical)$receivers: #定义三个接受者,和上面三个路由对应- name: 'email'email_configs:- to: 'jordan@163.com'- name: 'leader'email_configs:- to: 'jordan@wicre.com'- name: 'support_team'email_configs:- to: 'mlkdesti@163.com'html: '{{ template "test.html" . }}' # 设定邮箱的内容模板headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题send_resolved: true #恢复的时候发送告警消息webhook_configs: # webhook配置- url: 'http://127.0.0.1:5001'send_resolved: truewechat_configs: # 企业微信报警配置- send_resolved: trueto_party: '1' # 接收组的idagent_id: '1000002' # (企业微信-->自定应用-->AgentId)corp_id: '******' # 企业信息(我的企业-->CorpId[在底部])api_secret: '******' # 企业微信(企业微信-->自定应用-->Secret)message: '{{ template "test.html" . }}' # 发送消息模板的设定# 一个inhibition规则是在与另一组匹配器匹配的警报存在的条件下,使匹配一组匹配器的警报失效的规则。两个警报必须具有一组相同的标签。inhibit_rules:- source_match:severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'dev', 'instance']
将上面文件保存为 alertmanager.yaml,然后使用这个文件创建一个 Secret 对象:
#删除原secret对象kubectl delete secret alertmanager-main -n monitoringsecret "alertmanager-main" deleted#将自己的配置文件导入到新的secretkubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
我们添加了两个接收器,默认的通过邮箱进行发送,对于 CoreDNSDown 这个报警我们通过 wechat 来进行发送,上面的步骤创建完成后,收到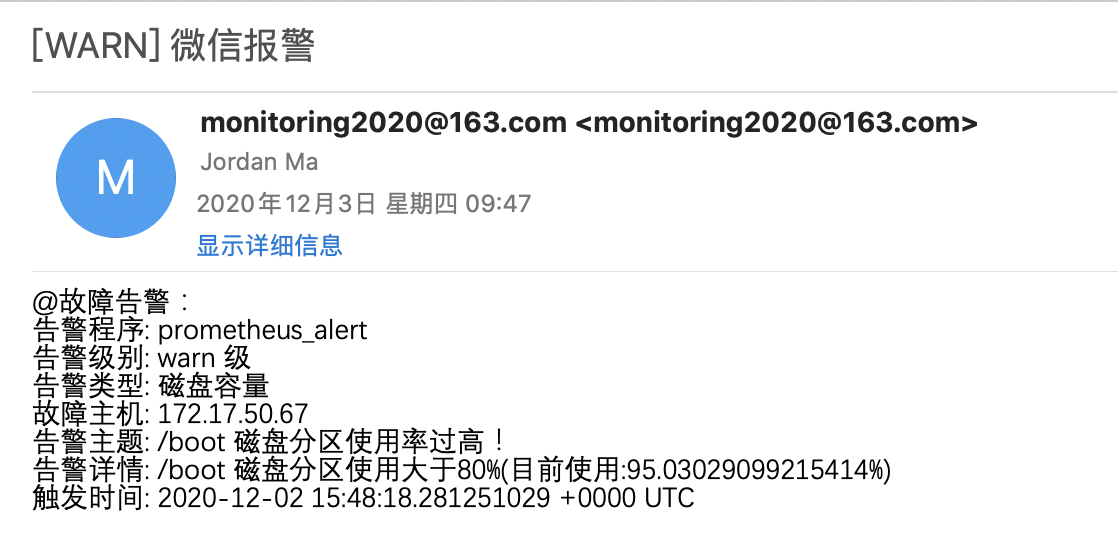
我们再次查看 AlertManager 页面的 status 页面的配置信息可以看到已经变成上面我们的配置信息了: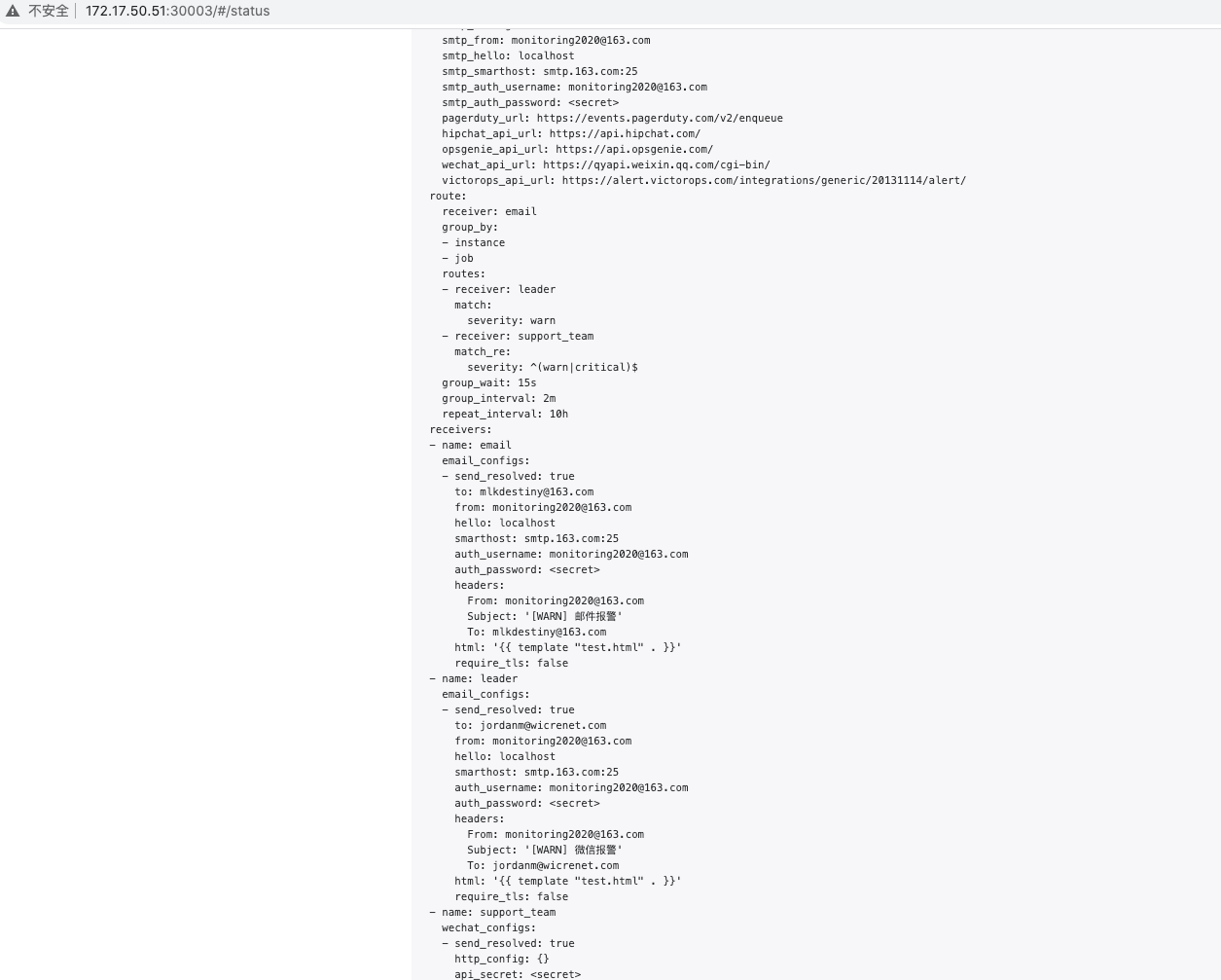
AlertManager 配置也可以使用模板(.tmpl文件),这些模板可以与 alertmanager.yaml 配置文件一起添加到 Secret 对象中,比如:
apiVersion:v1kind:secretmetadata:name:alertmanager-exampledata:alertmanager.yaml:{BASE64_CONFIG}template_1.tmpl:{BASE64_TEMPLATE_1}template_2.tmpl:{BASE64_TEMPLATE_2}...
模板会被放置到与配置文件相同的路径,当然要使用这些模板文件,还需要在 alertmanager.yaml 配置文件中指定:
templates:- '*.tmpl'
创建成功后,Secret 对象将会挂载到 AlertManager 对象创建的 AlertManager Pod 中去。
样例:我们创建一个test.tmpl文件,添加如下内容:
[admin@ch-k8s1 new]$ cat test.tmpl{{ define "test.html" }}{{ if gt (len .Alerts.Firing) 0 }}{{ range .Alerts }}@故障告警:<br>告警程序: prometheus_alert <br>告警级别: {{ .Labels.severity }} 级 <br>告警类型: {{ .Labels.alertname }} <br>故障主机: {{ .Labels.instance }} <br>告警主题: {{ .Annotations.summary }} <br>告警详情: {{ .Annotations.description }} <br>触发时间: {{ .StartsAt }} <br>{{ end }}{{ end }}{{ if gt (len .Alerts.Resolved) 0 }}{{ range .Alerts }}@故障恢复:<br>告警主机:{{ .Labels.instance }} <br>告警主题:{{ .Annotations.summary }} <br>恢复时间: {{ .EndsAt }} <br>{{ end }}{{ end }}{{ end }}
删除原secret对象
$ kubectl delete secret alertmanager-main -n monitoringsecret "alertmanager-main" deleted
创建新的secret对象
$ kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --from-file=test.tmpl -n monitoringsecret/alertmanager-main created
过一会我们的微信就会收到告警信息。当然这里标签定义的问题,获取的值不全,我们可以根据实际情况自定义。
自动发现配置
我们想一个问题,如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
为解决这个问题,Prometheus Operator 为我们提供了一个额外的抓取配置的来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。和前面自定义的方式一样,我们想要在 Prometheus Operator 当中去自动发现并监控具有prometheus.io/scrape=true这个 annotations 的 Service,之前我们定义的 Prometheus 的配置如下:
- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name
要想自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明,将上面文件直接保存为 prometheus-additional.yaml,然后通过这个文件创建一个对应的 Secret 对象:
[admin@ch-k8s1 new]$ kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoringsecret/additional-configs created
创建完成后,会将上面配置信息进行 base64 编码后作为 prometheus-additional.yaml 这个 key 对应的值存在:
[admin@ch-k8s1 new]$ kubectl get secret additional-configs -n monitoring -o yamlapiVersion: v1data:prometheus-additional.yaml: LSBqb2JfbmFtZTogJ2t1YmVybmV0ZXMtc2VydmljZS1lbmRwb2ludHMnCiAga3ViZXJuZXRlc19zZF9jb25maWdzOgogIC0gcm9sZTogZW5kcG9pbnRzCiAgcmVsYWJlbF9jb25maWdzOgogIC0gc291cmNlX2xhYmVsczogW19fbWV0YV9rdWJlcm5ldGVzX3NlcnZpY2VfYW5ub3RhdGlvbl9wcm9tZXRoZXVzX2lvX3NjcmFwZV0KICAgIGFjdGlvbjoga2VlcAogICAgcmVnZXg6IHRydWUKICAtIHNvdXJjZV9sYWJlbHM6IFtfX21ldGFfa3ViZXJuZXRlc19zZXJ2aWNlX2Fubm90YXRpb25fcHJvbWV0aGV1c19pb19zY2hlbWVdCiAgICBhY3Rpb246IHJlcGxhY2UKICAgIHRhcmdldF9sYWJlbDogX19zY2hlbWVfXwogICAgcmVnZXg6IChodHRwcz8pCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9hbm5vdGF0aW9uX3Byb21ldGhldXNfaW9fcGF0aF0KICAgIGFjdGlvbjogcmVwbGFjZQogICAgdGFyZ2V0X2xhYmVsOiBfX21ldHJpY3NfcGF0aF9fCiAgICByZWdleDogKC4rKQogIC0gc291cmNlX2xhYmVsczogW19fYWRkcmVzc19fLCBfX21ldGFfa3ViZXJuZXRlc19zZXJ2aWNlX2Fubm90YXRpb25fcHJvbWV0aGV1c19pb19wb3J0XQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IF9fYWRkcmVzc19fCiAgICByZWdleDogKFteOl0rKSg/OjpcZCspPzsoXGQrKQogICAgcmVwbGFjZW1lbnQ6ICQxOiQyCiAgLSBhY3Rpb246IGxhYmVsbWFwCiAgICByZWdleDogX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9sYWJlbF8oLispCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfbmFtZXNwYWNlXQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IGt1YmVybmV0ZXNfbmFtZXNwYWNlCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9uYW1lXQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IGt1YmVybmV0ZXNfbmFtZQo=kind: Secretmetadata:creationTimestamp: "2020-12-03T03:49:35Z"name: additional-configsnamespace: monitoringresourceVersion: "12056954"selfLink: /api/v1/namespaces/monitoring/secrets/additional-configsuid: b065947c-4117-4ccc-b32f-0b59f09b7ea4type: Opaque
然后我们只需要在声明 prometheus 的资源对象文件中添加上这个额外的配置:(prometheus-prometheus.yaml)
[admin@ch-k8s1 manifests]$ cat prometheus-prometheus.yamlapiVersion: monitoring.coreos.com/v1kind: Prometheusmetadata:labels:prometheus: k8sname: k8snamespace: monitoringspec:alerting:alertmanagers:- name: alertmanager-mainnamespace: monitoringport: webbaseImage: quay.io/prometheus/prometheusnodeSelector:kubernetes.io/os: linuxpodMonitorSelector: {}replicas: 2resources:requests:memory: 400MiruleSelector:matchLabels:prometheus: k8srole: alert-rulessecurityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000additionalScrapeConfigs:name: additional-configskey: prometheus-additional.yamlserviceAccountName: prometheus-k8sserviceMonitorNamespaceSelector: {}serviceMonitorSelector: {}version: v2.11.0
添加完成后,直接更新 prometheus 这个 CRD 资源对象:
[admin@ch-k8s1 manifests]$ kubectl apply -f prometheus-prometheus.yamlprometheus.monitoring.coreos.com/k8s configured
隔一小会儿,可以前往 Prometheus 的 Dashboard 中查看配置是否生效: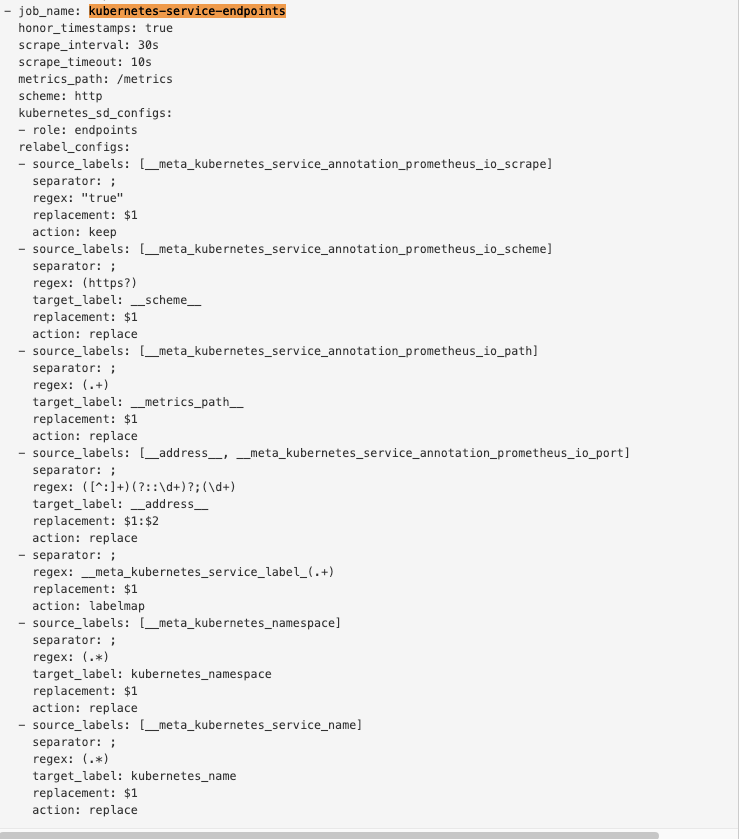
在 Prometheus Dashboard 的配置页面下面我们可以看到已经有了对应的的配置信息了,但是我们切换到 targets 页面下面却并没有发现对应的监控任务,查看 Prometheus 的 Pod 日志:
[admin@ch-k8s1 ~]$ kubectl logs -f prometheus-k8s-0 prometheus -n monitoring....e"level=error ts=2020-12-03T06:03:49.780Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:263: Failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"endpoints\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:49.781Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:265: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:50.775Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:264: Failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"services\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:50.783Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:263: Failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"endpoints\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:50.784Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:265: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:51.778Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:264: Failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"services\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:51.786Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:265: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"pods\" in API group \"\" at the cluster scope"level=error ts=2020-12-03T06:03:51.787Z caller=klog.go:94 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:263: Failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"endpoints\" in API group \"\" at the cluster scope"....
可以看到有很多错误日志出现,都是xxx is forbidden,这说明是 RBAC 权限的问题,通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:(prometheus-clusterRole.yaml)
[admin@ch-k8s1 manifests]$ cat prometheus-clusterRole.yamlapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: prometheus-k8srules:- apiGroups:- ""resources:- nodes/metricsverbs:- get- nonResourceURLs:- /metricsverbs:- get
上面的权限规则中我们可以看到明显没有对 Service 或者 Pod 的 list 权限,所以报错了,要解决这个问题,我们只需要添加上需要的权限即可:
apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: prometheus-k8srules:- apiGroups:- ""resources:- nodes- services- endpoints- pods- nodes/proxyverbs:- get- list- watch- apiGroups:- ""resources:- configmaps- nodes/metricsverbs:- get- nonResourceURLs:- /metricsverbs:- get

若有收获,就点个赞吧
0 人点赞
