节点隔离
cordon 停止调度
影响最小,只会将node调为SchedulingDisabled
之后再发创建pod,不会被调度到该节点
旧有的pod不会受到影响,仍正常对外提供服务
#将node节点设置为不可调度kubectl cordon node-name#恢复节点调度kubectl uncordon node_name
POD驱逐
drain 驱逐节点
首先,驱逐node上的pod,其他节点重新创建
接着,将节点调为 SchedulingDisabled
#排空node上的pod
kubectl drain node-name
#恢复节点调度
kubectl uncordon node_name
对节点执行维护操作之前(例如:内核升级,硬件维护等),您可以使用 kubectl drain 安全驱逐节点上面所有的 pod。
安全驱逐的方式将会允许 pod 里面的容器遵循指定的 PodDisruptionBudgets 执行优雅的中止。
注: 默认情况下,kubectl drain 不会删除不用API Server管理的pod
kubectl drain 返回成功表明所有的 pod (除了前面排除的那些)已经被安全驱逐(遵循期望优雅的中止期,并且没有违反任何应用程序级别的中断预算)。
然后,通过对物理机断电或者在云平台上删除节点所在的虚拟机,都能安全的将节点移除。
# 确定要排空的节点的名称
kubectl get nodes
# 查看获取pod名字
kubectl get po
# 命令node节点开始释放所有pod,并且不接收新的pod进程
kubectl drain [node-name] --force --ignore-daemonsets --delete-local-data
# 这时候把需要做的事情做一下。比如上面说的更改docker文件daemon.json或者说node节点故障需要进行的处理操作
# 然后恢复node,恢复接收新的pod进程
drain的参数
—force
当一些pod不是经 ReplicationController, ReplicaSet, Job, DaemonSet 或者 StatefulSet 管理的时候
就需要用—force来强制执行 (例如:kube-proxy)
—ignore-daemonsets
无视DaemonSet管理下的Pod
—delete-local-data(清除数据,谨慎操作)
如果有mount local volumn的pod,会强制杀掉该pod并把料清除掉
另外如果跟本身的配置讯息有冲突时,drain就不会执行
kubelet驱逐机制
在kubernetes里,pod的驱逐机制分为kubelet驱逐(被动驱逐)和主动驱逐两种。
在node节点的资源紧缺的条件下,kubelet为了保证node节点的稳定性,会触发主动驱逐pod的机制,流程如下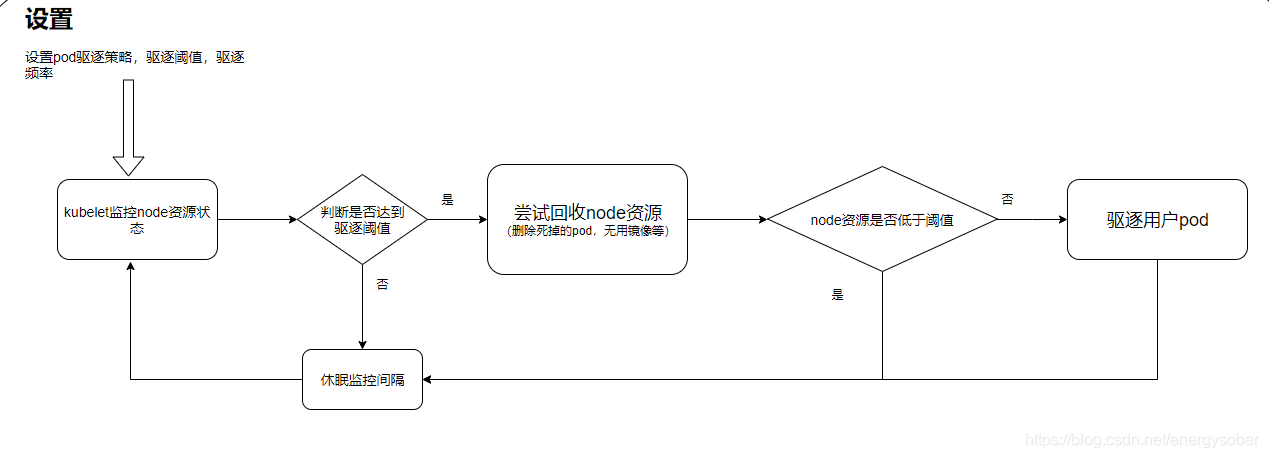
**
如果kubelet无法通过节点级别的资源回收获取足够的资源,就会开始驱逐用户的Pod,kubelet会按照下面的标准对Pod的驱逐行为进行判断
- Pod要求的服务质量(BestEffor,Bustable,Guaranteed)
- 根据Pod调度请求的被耗尽资源的消耗量
驱逐的逻辑如下:
BestEffort:对紧缺资源消耗最多的Pod最先被驱逐
Burstbale:根据相对请求(request)来判断,对紧缺资源消耗最多的Pod最先被驱逐,如果没有Pod超出它们的请求,则策略回瞄准紧缺资源消耗量最大的Pod
Guaranteed:根据相对请求(request)来判断,对紧缺资源消耗最多的Pod最先被驱逐,如果没有Pod超出它们的要求,策略回瞄准紧缺资源消耗量最大的Pod
所以
重要的Pod以及Daemonset尽量不要设置成BestEffort (BestEffor级别的Pod会被优先驱逐,而Damontset的特殊机制,被kill掉之后还是会被拉起,会出现不断重启,不断被kill)
主动驱逐
场景:
- 节点的维护或者升级(kubectl drain)
- 对应用的自动缩容操作(autoscaling down)
kubectl drain
当我们需要对一个节点进行维护,或者删除这个节点的时候,需要手动将布置在上面的Pod主动驱逐出来,以便不影响业务的连续性。
驱动node节点上的Pod(先设置node为cordon不可调度状态,然后驱逐Pod)kubectl drain <node name>
维护完后需要将节点设置为可调度kubectl uncordon <node name>
Pod Disruption Budget(PDB)
对于主动驱逐的场景来说,应用如果能够保持存活的Pod的数量,则将会非常的有用。通过使用PodDisruptionBudget。应用可以保证哪些会主动迁移Pod的集群操作永远不会同一时间停掉太多Pod,从而导致服务中观或者服务降级等后果。例如一个Node要进行维护时,系统应该保证应用以不低于一定数量的Pod保障服务的正常运行。kubectl drain操作将遵循PodDisrupitonBudget的设定。如果在该节点运行属于同一服务的多个Pod,则为了保证最少存活数量,系统将确保每终止一个Pod后,一定会在另一台健康的Node上启动新的Pod后,再继续终下一个Pod。
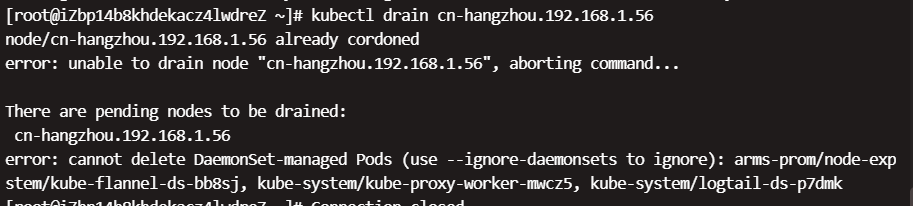
演示操作
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.54 Ready <none> 47d v1.18.8-aliyun.1
cn-hangzhou.192.168.1.55 Ready <none> 47d v1.18.8-aliyun.1
cn-hangzhou.192.168.1.56 Ready <none> 47d v1.18.8-aliyun.1
#排空节点pod,提示存在非APIserver管理的pod和挂在的存储
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl drain cn-hangzhou.192.168.1.54
node/cn-hangzhou.192.168.1.54 cordoned
error: unable to drain node "cn-hangzhou.192.168.1.54", aborting command...
There are pending nodes to be drained:
cn-hangzhou.192.168.1.54
cannot delete Pods with local storage (use --delete-local-data to override): arms-prom/arms-prometheus-ack-arms-prometheus-54c78f5b5f-dmtrw, kube-system/csi-provisioner-5cbb9458b6-7jd7j
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): arms-prom/node-exporter-wcr8n, kube-system/ack-node-problem-detector-daemonset-tctpx, kube-system/csi-plugin-n4j2m, kube-system/kube-flannel-ds-4x9cb, kube-system/kube-proxy-worker-dhrw4, kube-system/logtail-ds-sz8p7
#先恢复节点调度状态
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl uncordon cn-hangzhou.192.168.1.54
node/cn-hangzhou.192.168.1.54 uncordoned
#根据提示添加参数,并执行
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl drain cn-hangzhou.192.168.1.54 --ignore-daemonsets --delete-local-data
node/cn-hangzhou.192.168.1.54 cordoned
WARNING: ignoring DaemonSet-managed Pods: arms-prom/node-exporter-wcr8n, kube-system/ack-node-problem-detector-daemonset-tctpx, kube-system/csi-plugin-n4j2m, kube-system/kube-flannel-ds-4x9cb, kube-system/kube-proxy-worker-dhrw4, kube-system/logtail-ds-sz8p7
evicting pod arms-prom/arms-prometheus-ack-arms-prometheus-54c78f5b5f-dmtrw
evicting pod arms-prom/kube-state-metrics-ccb59dbff-wxhc6
evicting pod default/global-marketing-center-6bf9bbb998-d5dwq
evicting pod default/global-settlement-center-7545f66f5c-mfnqx
evicting pod kube-system/aliyun-acr-credential-helper-5744954b54-ksb7r
evicting pod kube-system/ack-node-problem-detector-eventer-7c44864479-rpmqq
evicting pod kube-system/csi-provisioner-5cbb9458b6-7jd7j
evicting pod kube-system/coredns-6cc7845c8c-cmc69
evicting pod kube-system/kube-eventer-init-4kzrr
evicting pod default/global-financial-payment-center-6849c985f9-snmxv
evicting pod default/global-financial-common-service-6798dc7759-x2k7r
evicting pod default/global-financial-product-75fc675ff7-mqwg7
evicting pod kube-system/alicloud-application-controller-798784bf49-q78zm
evicting pod default/global-financial-user-center-545df76cd4-shd9v
evicting pod kube-system/metrics-server-bf758d964-rkgvq
evicting pod kube-system/alicloud-monitor-controller-6b77595dbf-7nths
evicting pod kube-system/alibaba-log-controller-75b8fdc95c-tkdd6
evicting pod kube-system/nginx-ingress-controller-548755f5d4-cpx7d
pod/kube-eventer-init-4kzrr evicted
I0204 14:01:23.894055 703063 request.go:621] Throttling request took 1.199804679s, request: POST:https://192.168.1.51:6443/api/v1/namespaces/arms-prom/pods/arms-prometheus-ack-arms-prometheus-54c78f5b5f-dmtrw/eviction
pod/alicloud-application-controller-798784bf49-q78zm evicted
pod/kube-state-metrics-ccb59dbff-wxhc6 evicted
pod/global-marketing-center-6bf9bbb998-d5dwq evicted
pod/global-financial-payment-center-6849c985f9-snmxv evicted
pod/aliyun-acr-credential-helper-5744954b54-ksb7r evicted
pod/alicloud-monitor-controller-6b77595dbf-7nths evicted
pod/global-settlement-center-7545f66f5c-mfnqx evicted
pod/global-financial-user-center-545df76cd4-shd9v evicted
pod/ack-node-problem-detector-eventer-7c44864479-rpmqq evicted
pod/global-financial-common-service-6798dc7759-x2k7r evicted
I0204 14:01:33.995450 703063 request.go:621] Throttling request took 1.192885916s, request: GET:https://192.168.1.51:6443/api/v1/namespaces/kube-system/pods/csi-provisioner-5cbb9458b6-7jd7j
pod/metrics-server-bf758d964-rkgvq evicted
pod/coredns-6cc7845c8c-cmc69 evicted
pod/global-financial-product-75fc675ff7-mqwg7 evicted
pod/nginx-ingress-controller-548755f5d4-cpx7d evicted
pod/alibaba-log-controller-75b8fdc95c-tkdd6 evicted
pod/csi-provisioner-5cbb9458b6-7jd7j evicted
pod/arms-prometheus-ack-arms-prometheus-54c78f5b5f-dmtrw evicted
node/cn-hangzhou.192.168.1.54 evicted
#查看pod排空情况
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.54 Ready,SchedulingDisabled <none> 47d v1.18.8-aliyun.1
cn-hangzhou.192.168.1.55 Ready <none> 47d v1.18.8-aliyun.1
cn-hangzhou.192.168.1.56 Ready <none> 47d v1.18.8-aliyun.1
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl get pod -o wide |grep 1.54
#pod排空成功,恢复节点调度
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl get pod -o wide |grep 1.54
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl uncordon cn-hangzhou.192.168.1.54
node/cn-hangzhou.192.168.1.54 uncordoned
[root@iZbp14b8khdekacz4lwdreZ ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
cn-hangzhou.192.168.1.54 Ready <none> 47d v1.18.8-aliyun.1
cn-hangzhou.192.168.1.55 Ready <none> 47d v1.18.8-aliyun.1
cn-hangzhou.192.168.1.56 Ready <none> 47d v1.18.8-aliyun.1

若有收获,就点个赞吧
0 人点赞
