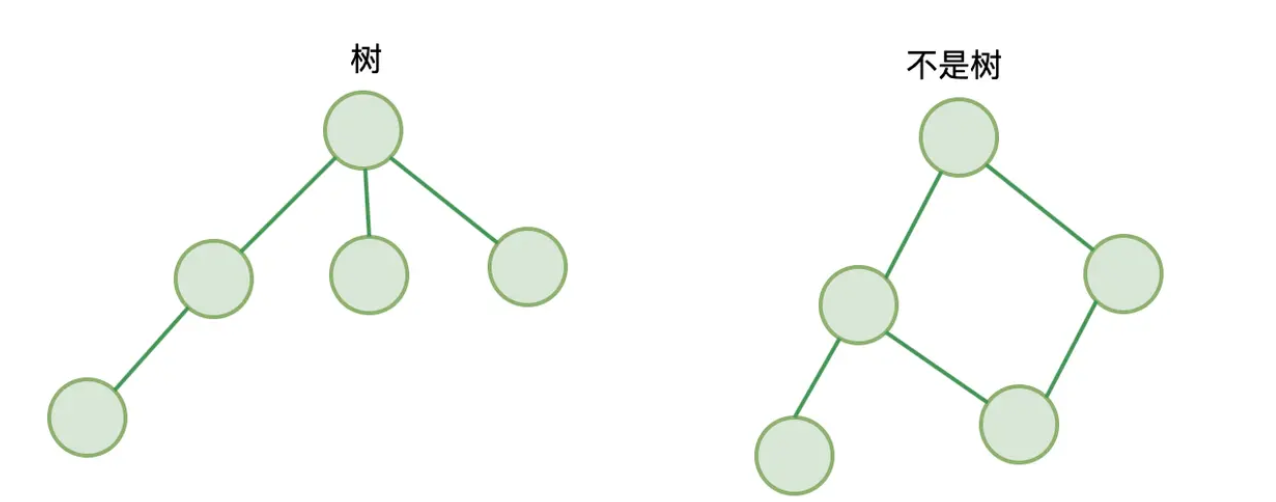
树
树的几个概念
- 拥有相同父节点的节点,互称为兄弟节点
- 节点的深度 :从根节点到该节点所经历的边的个数
- 节点的高度 :节点到叶节点的最长路径
-
树的特性
有且仅有一个根节点,没有节点则是空树
- 除根节点外,其他节点有且仅有一个父节点
- 节点之间不能形成闭环

B、C、D就互称为兄弟节点,其中,节点B的高度为2,节点B的深度为 1,树的高度为3
二叉树
二叉树的概念
- 最多只有两个子节点的树(最多能分两个叉的树)
- 树由节点组成

因此,我们定义树往往都是定义节点—>节点连接起来就成了树,而节点的定义就是:一个数据,两个指针(如果有节点就指向节点,没有节点就指向null)
二叉树性质
层节点
- 在二叉树的第i层上最多有2^{i-1}个结点(i>=1)
- 总节点
- 深度为k的二叉树最多有2^{k}-1个结点(k>=1)
节点数
抽象语法树(BST),Babel在编译的时候构建的BST就是一颗二叉树,vue的diff,虚拟DOM都离不开二叉树。另外,利用二叉树前序遍历显示目录结构,利用二叉树中序遍历实现表达式树,在编译器里非常有用。利用二叉树后序遍历实现计算目录内的文件以及信息。总之,二叉树无处不在,熟练运用二叉树,提升程序运行效率,提高程序可读性
满二叉树
满二叉树的特性
满二叉树就是满的,每一层都是最大的节点,不能有空,也就是除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树
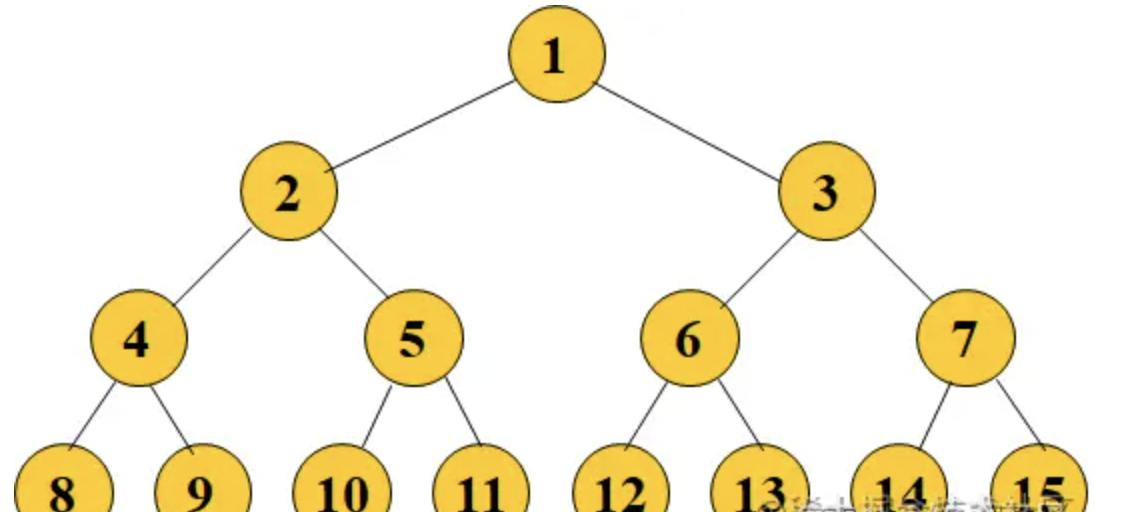
平衡二叉树
平衡二叉树的特性
- 二叉树中,每一个节点的左右子树的高度相差不能大于 1,称为平衡二叉树。

完全二叉树
完全二叉树的特性
- 结点按照编号从左到右依次构建二叉树,不存在无左孩子、却有右孩子的情况(有就不是)(深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边)
- 满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树
—————————————————————————-
二叉树的遍历
二叉树的遍历可分为:

遍历方式
迭代实现
- 建立一个栈
- 首先将根入栈
- 将根节点出栈,将根节点值放入结果数组中
- 然后依次遍历左子树、右子树,由于栈是先进后出,所以先右子树入栈,后左子树入栈
- 继续出栈。。直到栈空
var preorderTraversal = function(root) {const result=[]const stack=[] // 建立一个栈,注意栈是先进后出的数据结构if(root!==null) stack.push(root) // 当根节点不为null的时候,将根节点入栈while(stack.length>0){const currentNode=stack.pop() // 推出栈顶元素为当前访问的节点result.push(currentNode.val) // 访问当前节点,第一步的时候,访问的是根节点// 先序遍历的节点访问顺序是 根->左子树->右子树// 而先入栈的后访问,所以先入栈右子树,再入栈左子树,这样就左子树就会先被栈弹出来访问,再右子树// 所以先入栈 右子树 这样 右子树就会在后面被 pop() 也就是后访问到if(currentNode.right!==null) stack.push(currentNode.right)if(currentNode.left!==null) stack.push(currentNode.left)}return result};
递归实现 ```javascript function preorder(root, result = []) { // 边界情况 if(root === null) return result // 先输出根节点 ret.push(root.val) // 前序遍历左节点 preorder(root.left, result) // 前序遍历右节点 preorder(root.right, result) return ret }
var preorderTraversal = function(root,result=[]) { if(root===null) return result result.push(root.val)
};
<a name="LCZ9C"></a>#### 中序遍历- 对于二叉树中的任意一个节点,先打印它的左子树,然后是该节点,最后右子树(左-->根-->右)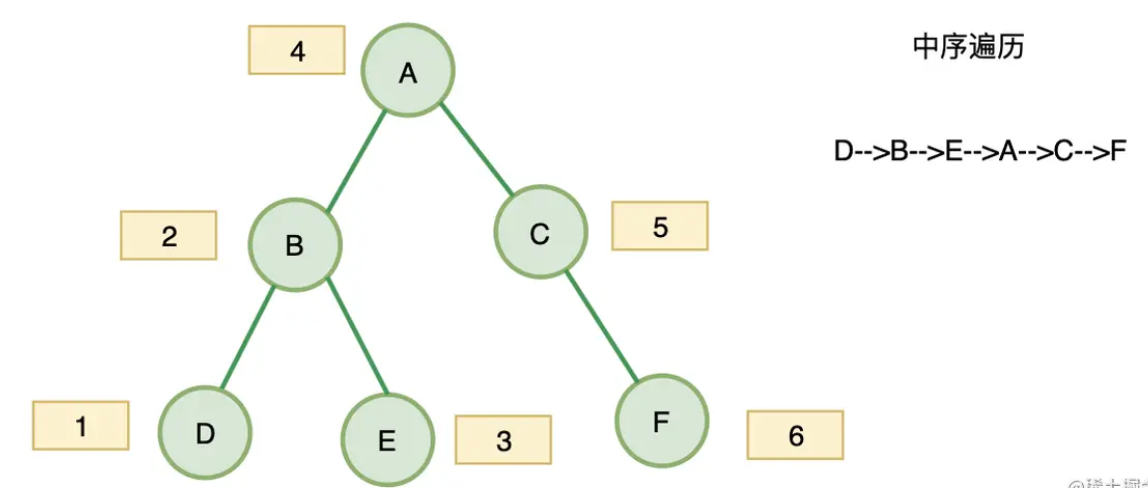- **遍历方式**[https://leetcode.cn/problems/binary-tree-inorder-traversal/](https://leetcode.cn/problems/binary-tree-inorder-traversal/)- **迭代实现**- 我们需要遍历的顺序是左-->根-->右,所以要先找到最左节点- 按照中序遍历的输出,我们需要记录遍历过程中的根节点- 输出完当前根节点,如果有右节点,再去把右节点放入栈中,依次输出```javascriptvar inorderTraversal = function(root) {const result=[]const stack=[]while(stack.length || root){// 先遍历到最左节点while(root){stack.push(root)root=root.left}root=stack.pop() // 输出当前左节点result.push(root.val)root=root.right // 再去指向右节点,遍历入栈,如果没有右节点会pop出上一层的节点}return result};
- 递归实现
const inorderTraversal = (root, arr = []) => {if(root) {inorderTraversal(root.left, arr)arr.push(root.val)inorderTraversal(root.right, arr)}return arr}// 或者var inorderTraversal = function(root) {let result=[]const inOrder=(root)=>{if(!root) returninOrder(root.left)result.push(root.val)inOrder(root.right)}inOrder(root)return result};
后序遍历
- 对于二叉树任意一个节点,先打印它的左子树,然后是右子树,最后是该节点 (左—>右—>根)

遍历方式
迭代实现
- 和中序遍历大致一样
- 不同点:如果当前节点存在右子树,先把当前节点的文本域入栈(不然会出现死循环),接着是当前节点指向右节点,进行后序遍历
var postorderTraversal = function(root) {const result=[]const stack=[]while(stack.length||root){while(root){stack.push(root)root=root.left}root=stack.pop()if(root.right){stack.push({val:root.val})}else{result.push(root.val)}root=root.right}return result};
递归实现 ```javascript function postorder(root, ret = []) { if (root === null) return ret // 后序遍历左节点 postorder(root.left, ret) // 后序遍历右节点 postorder(root.right, ret) // 输出根节点 ret.push(root.val) return ret }
const postorderTraversal = (root, arr = []) => { if(root) { postorderTraversal(root.left, arr) postorderTraversal(root.right, arr) arr.push(root.val) } return arr } // 或者 var postorderTraversal = function(root) { let result=[] const postorder=(root)=>{ if(!root) return postorder(root.left) postorder(root.right) result.push(root.val) } postorder(root) return result };
<a name="VQiLg"></a>## 二叉树的层序遍历- [https://leetcode.cn/problems/binary-tree-level-order-traversal/](https://leetcode.cn/problems/binary-tree-level-order-traversal/)- 层序就是逐层的,从左到右访问所有节点```javascript二叉树:[3,9,20,null,null,15,7] ,3/ \9 20/ \15 7返回其层次遍历结果:[[3],[9,20],[15,7]]
我们可以看到层序遍历的结果是个二维数组。 似乎我们可以把根作为起点来走,左右子树当成岔道,来进行BFS或DFS查找,查找其实过程就是遍历。某种策略(DFS/BFS),一个个找过去(遍历)。
DFS(Deep First Search) 深度优先搜索
- 深度优先搜索的步骤分为
- 递归下去
- 回溯上来
顾名思义,深度优先,先一条路走到底,直到达到目标,这里成为递归下去
否则既没有目标又无路可走了,那么则退回到上一步的状态,走其他路,这便是回溯上来
BFS(Breath First Search)广度优先搜索
- 广度优先搜索较之深度优先搜索之不同在于,深度优先搜索旨在不管有多少条岔路,先一条路走到底,不成功就返回上一个路口然后就选择下一条岔路。
而广度优先搜索旨在面临一个路口时,把所有的岔路口都记下来,然后选择其中一个进入,然后将它的分路情况记录下来,然后再返回来进入另外一个岔路,并重复这样的操作
DFS和BFS的不同
从数据结构来说:
- DFS用递归的形式,用到了栈的结构,先进后出
- BFS用队列的形式,先进先出
- 复杂度
DFS的复杂度与BFS的复杂度大体一致,不同之处在于遍历的方式与对于问题的解决出发点不同,
- DFS是沿着树的深度遍历树的节点,尽可能深的搜索分支
DFS不是按照层次遍历的,为了让递归的过程中同一层的节点放入同一个列表中,在递归时要记录每个节点的深度。递归到新节点时要把该节点推入对应深度的列表末尾。const levelOrderDFS = function(root) {const result=[]const deepthFirst=(node,level)=>{if(!node) returnresult[level]=result[level]||[] // 当遍历到一个新的深度, 新建一个列表数组result[level].push(node.val) // 把节点值推进当前它的深度对应的结果数组中deepthFirst(node.left,level+1) // 递归调用, 当前节点有左右子树,下级循环深度+1deepthFirst(node.right,level+1)}deepthFirst(root,0) // 0正好代表根节点深度,也是数组的开始 indexreturn result};
当遍历到一个新的深度时,而最终结果还没有创建深度对应的列表时,应该在结果数组中,新建一个列表用来保存该深度的所有节点。BFS的实现
BFS 需要用队列作为辅助结构,下面是简单说明步骤var levelOrder = function(root) {const result=[]const queue=[]if (root !== null) queue.push(root)while(queue.length>0){const currentLevelList=[]let levelSize=queue.lengthwhile(levelSize>0){const node=queue.shift()currentLevelList.push(node.val)levelSize--if(node.left!==null) queue.push(node.left)if(node.right!==null) queue.push(node.right)}result.push(currentLevelList)}return result};
- 我们先将根节点放到队列中,第一层有一个节点,队列长度为 1 ,这个长度也就表示该层有几个节点
- 取出队列头部node 第一次就是根 值放进该层list 并把它左右子树入队列,(其实就是记录这层有多少岔道)
- 把该层list 放进结果数组就行了,一层的遍历就完成了,下面第二层同样的操作就行了,继续重复
实现上来说2层循环,外层循环一次代表一层,得到一个列表,放进结果数组,内部循环循环该层队列中的每个节点,并把这层节点的左右子树推到下一层队列中。(因为循环次数为当前层节点个数,所以后面推进去的是下一层循环才会用到)

若有收获,就点个赞吧
0 人点赞
