3.1 连接查询
在现实世界中,信息之间的关系不一定是一对一的,通常都是一对多或者是多对多,所以一行数据肯定无法记录现实中的信息。例如:部门信息就包含有部门本身的信息,还有员工信息。所以在表中记录的时候,我们记录这些信息的时候,记录每个员工信息的同时需要记录部门信息。
| 员工姓名 | 员工年龄 | 部门名 | 部门编号 | 部门负责人 |
|---|---|---|---|---|
| 张三 | 3 | 研发部 | 001 | 张三 |
| 李四 | 4 | 产品部 | 002 | 李四 |
| 王五 | 5 | 研发部 | 001 | 张三 |
如果信息出现变更,研发部的负责人改为王五,则需要修改所有的研发部的员工信息,这样就会出现大量冗余的数据,因此将信息存在多张表中是十分必要的。但是信息在多张表中就会存在一个问题,怎样用单条 SELECT 语句检索出数据?答案是使用连接。
3.1.1 笛卡尔积
由没有连接条件的表关系返回的结果为笛卡尔积。检索出的行的数据将是第一个表中的行数乘以第二个表中的行数。
select 查询列表from 表1,表2;
这种查询方式得到的结果是表 1 中每一条数据都会连接表 2 中的每一条数据。需要加上连接的条件,不然结果即使查询出来了也没有任何意义。

如 beauty 表中有 n 条数据,boys 表中有 m 条数据,如果没有连接条件,那么最后的结果就会有 m*n 条数据,这样的结果显然是没有意义的(连接都是依靠关系去联的)。
SELECT `name`,boyName FROM boys,beautyWHERE boys.id = beauty.boyfriend_id;
WHERE 的作用就是过滤掉逻辑上没有意义的数据
3.1.2 内部连接(内连接)
上一节的连接称为等值连接,它基于两个表之间的相等条件。这种基于两个表相等条件(交集)的连接方式称为内连接。
等值连接
等值连接属于内连接的一种,在 MySQL 中存在两种标准的写法,效果是一样的,只是写法不同,这两种标准写法分别为 sql92 和 sql99 ,sql92 作为了解,推荐使用 sql 99。
sql92 语法
sql92 语法仅支持 内连接,外连接部分则要用到 sql99。
实例1:查出 beauty 表中的 name 和其对应的 boyName
SELECT `name`,boyName FROM boys,beautywhere boys.id = beauty.boyFriendId;
实例2:为表起别名,查询员工名,工种号
SELECT last_name,e.job_id,job_titleFROM employees AS e,jobs AS jWHERE e.job_id=j.job_id;
当两张表的字段重复时,查询该字段时就会产生歧义,需要加上表名去限定,但是有些表的表名太长了,所以可以采用取别名的方式去限定。 注意:如果为表取了别名,则查询的字段就不能使用原来的表名去限定!
实例3:调换两个表的顺序
SELECT last_name,e.job_id,job_titleFROM employees AS e,jobs AS jWHERE j.job_id=e.job_id;
在连接时,表的顺序是不重要的
实例4:在连表的同时,对数据进行筛选
SELECT last_name,department_name,e.commission_pctFROM employees e,departments dWHERE e.department_id=d.department_idAND e.commission_pct IS NOT NULL;
实例5:先筛选后连接
SELECT last_name,department_name,e.commission_pctFROM employees e,departments dWHERE e.commission_pct IS NOT NULLAND e.department_id=d.department_id;
实例6:在等值连接的基础上添加分组
SELECT count(*) 个数 ,cityFROM departments d,locations lWHERE d.location_id=l.location_idGROUP BY city;
实例7:实现多表连接:查询员工名、部门名和所在的城市
SELECT last_name,department_name,cityFROM employees e,departments d,locations lWHERE e.department_id=d.department_idAND d.location_id = l.location_id;
总结:
- 多表等值连接的结果为多表的交集部分
- n 表连接,至少需要 n-1 个连接条件
- 多表的顺寻没有要求
- 一般需要为表起别名
-
sql99 语法
sql99 语法在 1999 年提出的标准,支持内连接,外连接(左外,右外,全外),交叉。
实例1:查询员工名、部门名SELECT last_name,department_nameFROM employees eINNER JOIN departments dON e.department_id=d.department_id;
实例2:查询名字中包含 e 的员工名和工种名(添加筛选条件)
SELECT last_name,job_titleFROM employees eINNER JOIN jobs jON e.job_id=j.job_idWHERE last_name LIKE "%e%";
实例3:查询部门数大于 3 的城市名和部门个数
SELECT COUNT(*),cityFROM departments dINNER JOIN locations lON d.location_id = l.location_idGROUP BY l.cityHAVING COUNT(*)>3;
实例4:查询部门员工个数大于 3 的部门和员工数,并按照个数降序排列
SELECT department_name,COUNT(*)FROM employees eINNER JOIN departments dON e.department_id=d.department_idGROUP BY e.department_idHAVING COUNT(*)>3ORDER BY COUNT(*) DESC;
实例5:查询员工名、部门名、工种名、并按照部门名降序(多表连接)
SELECT last_name,department_name,job_titleFROM employees eINNER JOIN departments dON e.department_id=d.department_idINNER JOIN jobs jON e.job_id = j.job_idORDER BY department_name DESC;
特点:
inner 可以省略
- 筛选条件放在 where后面,连接条件放在 on 后面,提高分离性,便于阅读
非等值连接
实例:查询员工名及其工资级别 ```sql案例:查询给员工的工资级别
SELECT salary,grade_level,last_name FROM employees e INNER JOIN job_grades jg ON e.salary>=jg.lowest_sal AND e.salary<=jg.highest_sal;
SELECT salary,grade_level,last_name FROM employees e INNER JOIN job_grades jg ON e.salary BETWEEN jg.lowest_sal AND jg.highest_sal;
<a name="DqArV"></a>### 自连接自连接得到的结果就是笛卡尔积<br />**实例:查询员工名和上级的领导名**```sqlSELECT e.employee_id,e.last_name,m.employee_id,m.last_nameFROM employees eINNER JOIN employees mON e.manager_id = m.employee_id;
总结
- sql92 和 sql99 只是写法上不一样,将多个表用 inner join 关键字去表示连接。
- sql92 的连接条件写在 where 语句后面,而 sql99 的连接条件写在 on 关键字后面。
- on 后面是 判等 表达式就是等值连接, on 后面如果不是判等表达式就是非等值连接
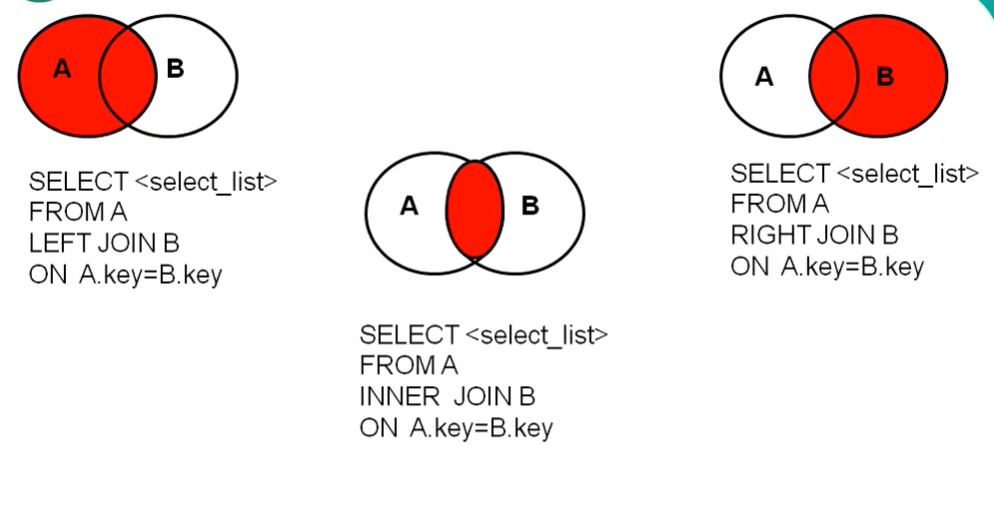
3.1.3 外连接
- 内连接和外连接本质上都是一张表中的数据去匹配另一张表或者是另外多张表中的每一条数据。
- 如果没有条件,则无论是内连接还是外连接,都显示多张表的笛卡尔积。
- 如果有条件,内连接只会显示两张表的交集部分,如果对应不上则不会显示。
- 左外连接会显示主表所有的记录和被连接的表的连接部分的记录。
- 右外连接相反,会显示次表所有的记录
-
左外连接
外连接的查询结果为主表的所有记录,和从表的匹配部分的数据
- 如果匹配到了,则显示匹配的值
- 如果没匹配到,则显示 null 值
主表就是 from 后面跟着的表,从表就是 join 后面跟着的表
实例:
SELECT b.`name`,bo.boyName
FROM beauty b
LEFT JOIN boys bo
ON b.id=bo.id
右外连接
右外连接和左外连接相反,它显示从表(join 后面跟着的表)中的所有的数据,以及主表中与从表匹配的数据。
实例:
SELECT b.`name`,bo.boyName
FROM beauty b
RIGHT JOIN boys bo
ON b.id=bo.id
全外连接
MySQL中不支持全外连接,别的数据库支持。全外连接能查询到 内连接+左外+右外 的所有记录。
实例:
SELECT b.*,bo.*
FROM beauty b
FULL JOIN boys bo
ON b.id = bo.id;
交叉连接
交叉连接的结果就是一个笛卡尔乘积,不过是用 sql99 语法来实现的
select b.*,bo.*
FROM beauty b
CROSS JOIN boys bo
3.1.4 总结

3.2 子查询
出现在其他语句中的 SELECT 语句,称子查询或内查询。外部的查询语句称为主查询或外查询。
分类:
- 按照及结果集的行数
- 标量子查询(结果集是一个值,也就是一行一列)
- 列子查询(结果集只有一行多列)
- 行子查询(结果集一般为多行多列)
- 按照子查询出现的位置
- 出现在 SELECT 后面:仅仅支持标量子查询
- 出现在 FROM 后面:支持表子查询
- WHERE 或 HAVING 后面(重点):标量子查询、列子查询、行子查询(用的比较少)
- exists后面:表子查询
3.2.1 放在 WHERE 或者是 HAVING 后面的子查询
特点:
- 子查询放在小括号内
- 子查询一般放在条件的右侧
- 标量子查询,一般搭配着单行操作符使用(> < <= >= <>)
- 列子查询一般搭配着多行操作符使用(in、any/some、all)
- 子查询的执行一般优于主查询,主查询的条件用到了子查询的结果
标量子查询
实例1:查询工资比 Abel 高的员工的名字和工资
SELECT last_name,salary
FROM employees e
WHERE salary>(
SELECT salary
FROM employees em
WHERE em.last_name='Abel'# 子查询语句不能加分号
);
实例2:查询 job_id 与 141 号员工相比 salary 比 143 号员工多的员工的姓名,job_id 和工资
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE employee_id=141
)
AND salary > (
SELECT salary
FROM employees
WHERE employee_id = 143
);
实例3:返回公司工资最少的员工 last_name,job_id 和 salary
SELECT last_name,job_id,salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);
实例4:查询最低工资大于 50 号部门最低最低工资的部门 id 和最低工资
SELECT department_id,MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary)>(
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
)
列子查询
子查询的列国是多行单列的,列子查询的结果需要和多行比较操作符使用
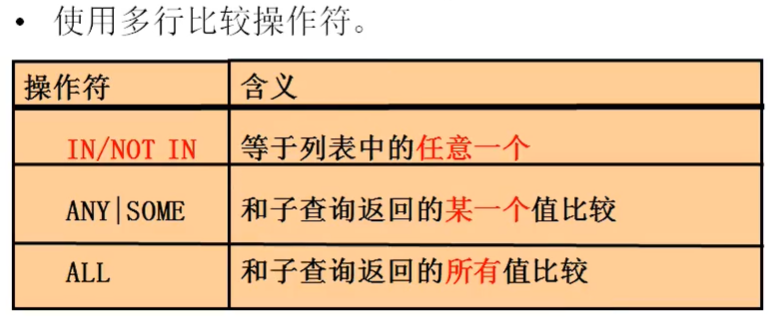
- in 和 ont in 是判定当前值是不是在查询的结果集当中
- 而 any 和 some 不太常用,是因为 any 是指任意一个,比如 salary > any (a1,a2,……,an)只要大于其中一个就可以,这种情况下,使用 min 关键字可读性更高
- all 也不常用,all 是表示所有,还是上面那个例子,大于的时候用 max 函数的可读性比 all 要更高。
- min 和 max 都在子查询里面,不能用在子查询外面
实例1:返回 location_id 是 1400 或者是 1700 的部门中的所有员工的姓名
SELECT last_name
FROM employees
WHERE department_id IN ( # 有重复的话最好去重
SELECT department_id
FROM departments
WHERE location_id in (1400,1700)
)
实例2:返回其他部门中比 job_id 为 IT_PROG 部门任意工资都低的员工的:工号、姓名、job_id 以及 salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
# 或者
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < (
SELECT MAX(salary)
FROM employees
WHERE job_id = 'IT_PROG'
);
实例3:返回其他部门中比 job_id 为 IT_PROG 部门所有工资都低员工的:工号、姓名、job_id 以及 salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ALL(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
# 或者
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < (
SELECT MIN(salary)
FROM employees
WHERE job_id = 'IT_PROG'
);
注意:
实例1:查询员工编号最小并且工资最高的员工信息
SELECT *
FROM employees
WHERE (employee_id,salary) = (
SELECT MIN(employee_id),MAX(salary)
FROM employees
);
要从一张表中查出一行,除了使用逐渐就是使用聚合函数,使用场景不多。
3.2.2 放在 from 后面的子查询
将子查询的结果当作一张表进行二次查询
实例:查询每个部门的平均工资的等级
SELECT avg.平均工资,department_id,g.grade_level
FROM (SELECT AVG(salary) 平均工资,department_id
FROM employees
GROUP BY department_id
) avg
LEFT JOIN job_grades g
ON avg.平均工资 BETWEEN g.lowest_sal AND g.highest_sal;
3.2.3 放在 exist 后面的子查询
exist 子查询,如果结果集不为空,则返回1,如果为空则返回 0.
实例1:查询有部门的员工名
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.department_id = e.department_id
)
实例2:查询没有女朋友的男生信息
SELECT *
FROM boys b
WHERE NOT EXISTS(
SELECT *
FROM beauty bu
WHERE b.id=bu.id
)
3.3 分页查询
语法:
SELECT 查询列表
FROM 表
【type JOIN 表2 ON 连接条件】
【WHERE 筛选条件】
【GROUP BY分组字段】
【HAVING 分组后的筛选】
【ORDER BY 排序的字段】
LIMIT 第n 条数据,显示的数据的数量
n 从 0 开始
语句的执行顺序
- form表
- join
- on
- where
- group by
- having
- select
- order by
- limit
上述每一步都会在内部生成一个虚拟的结果集
实例1:查询前 5 条员工的信息
SELECT *
FROM employees
LIMIT 0,5;
# 如果是从 0 开始,可以省略 0
SELECT *
FROM employees
LIMIT 5;
实例2:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT *
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10;
实例3:分页的另一种写法
SELECT *
FROM s1_user
LIMIT 4 OFFSET 3;
总结:
多数 SQL 查询都只包含从一个或多个表中返回数据的单条 SELECT 语句。MySQL 也允许执行多个查询(多条 SELECT 语句),并将结果作为单个查询结果集返回。
有两种基本情况,其中需要使用组合查询:
- 在单个查询中从不同的表返回类似结构的数据
- 对单个表执行多个查询,按单个查询返回数据
使用场景:
- 要查询的结果来自于多个表,且多个表没有类似于 id 之间的联系,所以不能用连接查询,这时候如果想要将这多个表的结果合并在一起,就可以使用联合查询
语法:
查询语句1
union
查询语句2
union
……
查询语句n;
实例1:查询部门编号大于 90 或邮箱包含 a 的员工信息
# 不使用联查询的方式
SELECT *
FROM employees
WHERE department_id>90
OR email LIKE '%a%';
# 联合查询的方式
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
注意:
- 联合查询就是将多个查询语句的结果合并在一起,并且会主动去重,不同的表中,数据相同的也会去重,如果不想去重,可以在 union 后面追加一个关键字 ALL。
- 并且可以查询多张表,而且多张表没有相同的字段也可以合并在一起,但是要保证查询出来的表的列数相同。

若有收获,就点个赞吧
0 人点赞
