- 一、Meta-SGD: Learning to Learn Quickly for Few-Shot Learning
- 二、Few-shot object detection with attention-rpn and multi-relation detector
- 三、One-shot object detection with co-attention and co-excitation
- 四、LSTD: A low-shot transfer detector for object detection
- 五、基于局部和全局特征表示的红外目标检测算法研究
- 六、图像识别中小样本学习方法与模型轻量化研究-李文静
- 七、Few-shot Classification via Adaptive Attention
一、Meta-SGD: Learning to Learn Quickly for Few-Shot Learning
1、核心思想
本文是在MAML的基础上进一步探索利用元学习实现无模型限制的小样本学习算法。思路与MAML和Meta-LSTM比较接近,首先MAML是利用元学习的方式获得一个较好的初始化参数,在此基础上只需要进行少量样本的微调训练就可以得到较好的结果,这种方式实现简单,但由于只对初始化参数进行学习,模型的容量有限。Meta-LSTM则是利用LSTM网络作为外层网络对内层网络的各项优化参数(学习率、衰减率等)进行学习,这一方法模型容量大,但由于LSTM训练过程复杂,且收敛速度较慢,实用性不高。因此作者受二者启发,提出一种折中的方案,沿用MAML只需要同一个网络结构,分别进行内层次训练和外层次训练。任务数据集分成两部分:训练子集D t r a i n D^{train}D train 和测试子集DtestD^{test}D test。首先在训练子集上进行内层次训练,其数学表达如下: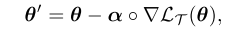
其中α \alphaα是一个与θ \thetaθ尺寸相同的向量,同时决定了参数更新的方向和学习率,∘ \circ∘表示逐元素相乘操作。则自适应项α ∘ ▽ L T ( θ ) \alpha\circ\triangledown L_T(\theta)α∘▽L
T(θ)是一个向量,其方向就是更新的方向,其长度就表示学习率,如下图所示。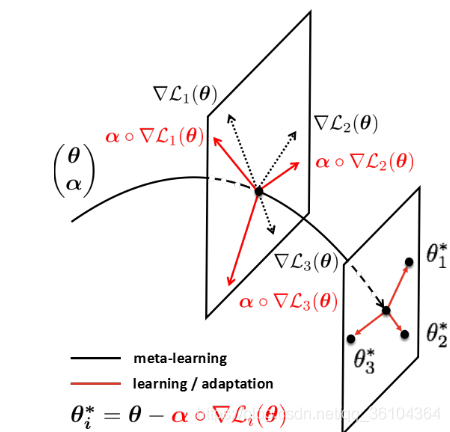
在测试子集Dtest D^{test}D test上进行外层次训练,也就是元学习的过程,同时对初始化参数θ \thetaθ,学习率α \alphaα和参数更新的方向进行学习。有趣的是,元学习过程还是采用了SGD的方式,学习率β \betaβ是由人工选定的值。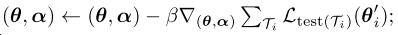
元学习的目标是希望找到最优的初始化参数θ \thetaθ和学习率向量α \alphaα使得训练得到的网络在所有任务上的经验损失最低。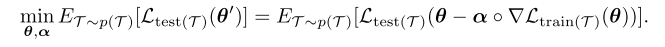
2、实现过程
与MAML相同该算法也是不对模型和任务进行限制,可用于分类、回归和强化学习等多种任务,网络结构和损失函数可以根据任务需求自行选定。
3、创新点
利用元学习的方法同时对初始化参数,学习率和更新方向进行学习,训练得到的模型可以很容易的经过微调以适应新的任务。
4、算法评价
相对于MAML,该算法的模型容量得到了提高;相对于Meta-LSTM,该算法的训练难度得到了明显的下降,根据实验结果来看,在多项任务中相对于MAML和Meta-LSTM都有一定的提高,但由于前两个算法珠玉在前,本文则显得比较平庸,创新性也略显不足。
二、Few-shot object detection with attention-rpn and multi-relation detector
1.Motivation
文章着力于解决小样本目标检测问题,即实现一个目标检测模型,可以无需在新类别上重新训练,就可以检测新的未见过的(unseen)类别。
左上角,右上角是给出的support图像
2.Contribution
文章的贡献主要在以下两个层面:
- 提出一种新的小样本目标检测模型,包括Attention RPN模块,Multi-Relation Detector。此外,在训练时,作者设计了一种新的训练策略,进一步提高性能
- 提供一个新的小样本目标检测模型FSOD(few-shot object detection dataset),共包含1000个类别(800类训练,200类测试)
3.FSOD数据集
虽然现在已经有多个目标检测的数据集,像MSCOCO,PASCAL VOC等,但这些数据集存在以下的问题:
- 各个数据集的标注体系不同,相同的目标在不同的数据集上可能不同。
- 现有数据集的标注包含噪声、漏标、重复标等问题
- 训练/测试的划分包含相同的类别,不适合小样本学习(感觉这条虽然正确,但不够充分,完全可以像之前的模型那样重新划分数据集)
新数据集的来源:
- ImageNet(531/1000类)
- Open Image V4(469/600类)
3.1 修正(统一)label
不同数据集的类标标签不同,比如同样是北极熊,对应label可能是polar bear或ice bear。为了统一标签名称,作者利用了open image数据集提供的semantic tree。就像下图所示,叶子节点是具体类标,非叶子节点是超类(super category)
3.2 补充标注
在确定了类别之后,需要对原先没有标注的部分进行补充标注。同时去除图像质量差的图片以及面积小于图像面积0.05%的标注框
3.3 划分数据集
按照训练集类别数:测试集类别数=800:200。测试集的类别选择在wordnet上与其他类别距离较远(差距较大)的类别(shortest path that connects the meaning of two phrases in the is-a taxonomy)。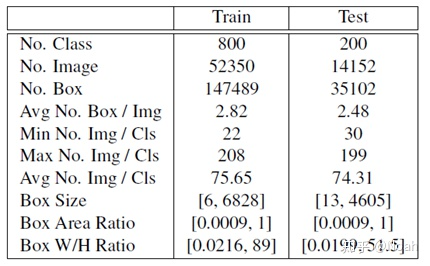
FSOD数据集的情况,不过那个Avg No. Img/Cls貌似不太对?
数据集各类别的数量
4.模型结果
模型的整体结构如下,很明显模型以Faster RCNN为基础构建,不熟悉的读者需要自行了解(很重要)。模型的输入包含2个分支,query图像是待检测图像,support图像定义了检测的类别,模型需要在query图像上框出对应的目标。
weight shared network是权值贡献的特征提取模块,一般是resnet50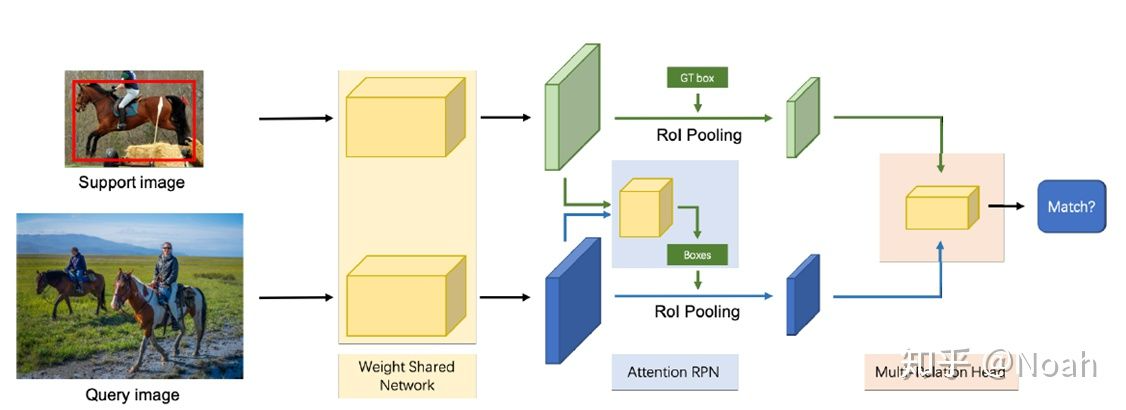
4.1 Attention-RPN 模块
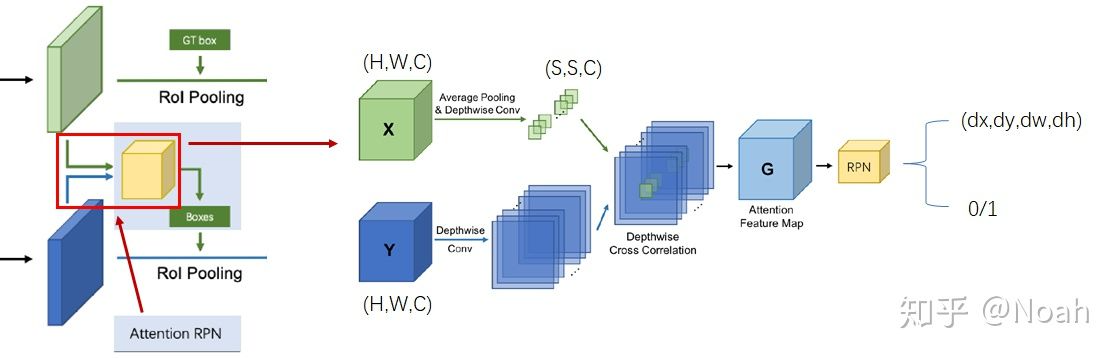
通过卷积的方式度量相似度
在分别提取图像的特征后,模型进行了第一次的相似性度量,目的是帮助RPN网络能产生包含目标的proposal。相似性度量的方式很直观,即以support图像的特征为卷积核,在query图像上滑动。这样的操作早在目标跟踪网络Siamese-FC中就有涉及。
该操作需要注意2点:
1)support特征需要经过池化,抽象出总体的特征,才能作为卷积核。在这里,作者尝试了不同大小后选择S=1,这与global average pooling对应。原始的support特征尺度太大,细节较多,不能反应目标的总体特性。如果用原始的support特征做卷积核,容易产生噪声
2)卷积操作选择的是depthwise conv,而不是传统的卷积。深度网络抽取的特征,不同的层级反应的内容不同。因此相同层级的特征应该具有相关性,所有depthwise的卷积跟符合问题场景。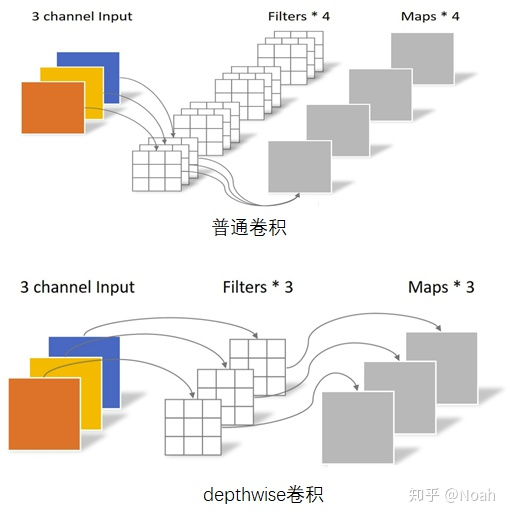
4.2 Multi-Resolution Decoder
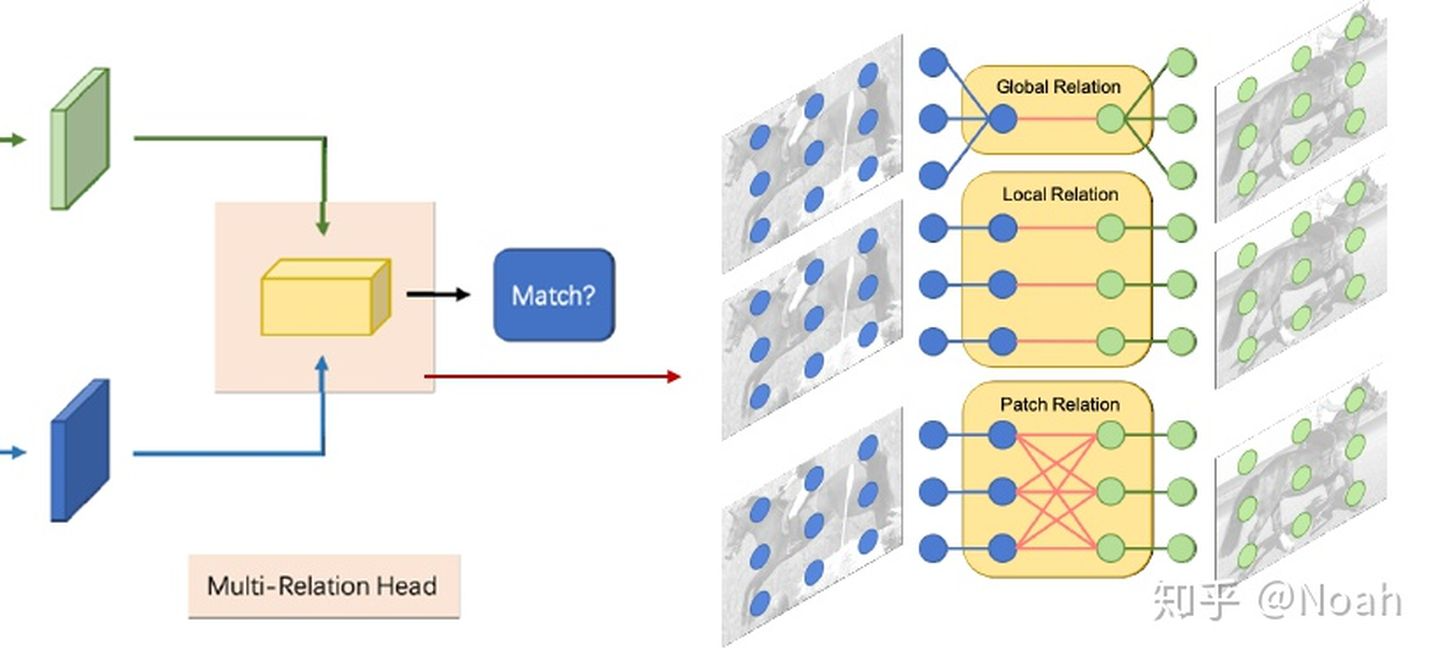
上一个步骤生成粗回归框,经过roi-pooling操作后,会得到固定大小的ROI特征(7x7xC)。Multi-Resolution Decoder将进一步proposal是否包含support图像给出的目标,并精修proposal的位置。这里作者采用3种不同的relation判断query图像的ROI是否与support图像的ROI匹配。最终的结果是将这个三个置信度结合起来判断,但文章并没有给出判断的方法…
Global Relation:将support图像以及query图像的ROI特征oncatenate,这时候就变成了7x7x2C,在经过一次全局平均池化,变成1x1x2C,获取了全局信息,再通过一系列全连接操作输出得到一个数值(从2C降维到1),此数值就是两ROI特征图的全局相似性。
Local Relation: 分别对support图像特征与query图像特征用权值贡献的1x1卷积进行channel-wise操作,然后再进行类似于Attention RPN的卷积操作,区别在于support图像的ROI特征图不需要全局池化到1x1,而是直接以7x7的大小作为一个卷积核在query image的ROI特征图上进行卷积(非depthwise卷积,而是普通卷积),变成1x1xC,最后同样使用全连接层得到局部相似度。
Patch Relation:首先将两个ROI特征图进行concatenate,变成7x7x2C,然后经过一系列结构如下图所示。每组卷积后面都会使用RELU函数激活,并且pooling和卷积结构都是stride=1以及padding=0。这样在经过这些操作之后,合并的ROI特征图的大小会变为1x1x2C,这时候后面接一个全连接层用来获得区域级的相似度。此外,该部分还并行接了一个全连接层,用于产生bounding box predictions(只有这个部分对回归框做了精修)。此部分应该是直接借鉴了Faster RCNN的detector head。
4.3 训练策略(Two-way Contrastive Training Strategy)
有些时候,我们会说一个小样本模型是个N-way k-shot模型,这个意思是指对于单张query图像,support图像有N个类别,每个类别有k张图像。上面介绍的是模型1-way 1-shot的情况。但是这个模型可以做到N-way k-shot情况。
1-way k-shot
此情况下,直接将同类的k张图像经过weight shared network提取的特征求平均,作为代表进行后续计算。
N-way k-shot
对于同类别的k张图像,依旧采用求平均的方法。对于N个不同的类别,则分别计算,即把N-way k-shot问题化解为N个1-way 1-shot问题。
训练策略
在训练时,作者将query图像缩放至(1000,600)的大小,support图像以标注的bbox为依据向外围扩展16个像素并裁剪,再进行0值填充,使图像变成正方形(为了防止图像缩放至正方形改变物体形状),最后缩放至(320,320)的大小。此外,作者为了提高网络的性能,采用了新的训练策略,主要包括:
- 为了增强网络的判别能力,一次训练采用三元组(
 ),
),  表示c类别的query图像,
表示c类别的query图像,  表示c类别的support图像,
表示c类别的support图像,  表示n类别(n与c不同)的support图像。也就是说每次训练是2-way k-shot的情况。网络在训练中学会尽可能区分类别。
表示n类别(n与c不同)的support图像。也就是说每次训练是2-way k-shot的情况。网络在训练中学会尽可能区分类别。
- 控制RPN网络的采样比例。RPN网络会产生很多回归框,如果不加以限定,那么很有可能产生大量的背景框。作者制定了采样策略,对以下三种类别按1:2:1保留topN(top 2N)的框送入multi-relation detector学习。
1)前景ROI和positive support image特征对(pairs)(如下图右侧第一行)
2)背景ROI和positive support image特征对(pairs)(如下图右侧第二行)
3)任意ROI和negative support image特征对(pairs)(如下图右侧第三行第四行)
5. 实验结果
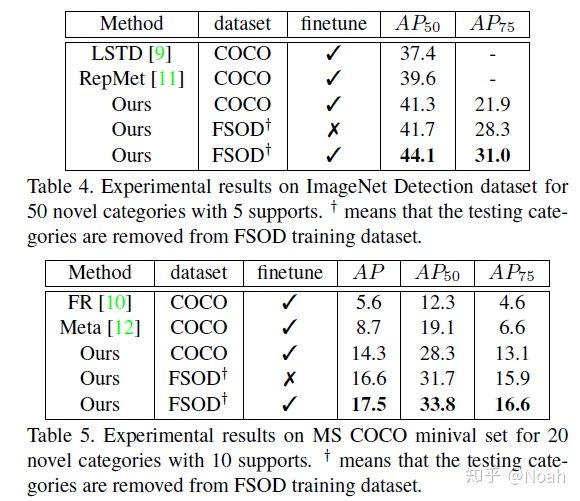
消融实验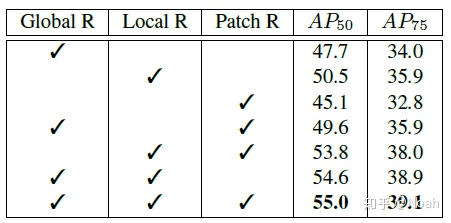
实验证明同时选择三个relation方法的结果最好。此外可以看出不同的relation方法差异很大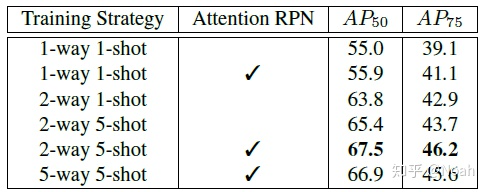
Two-way训练策略配合Attention RPN模块能带来明显的性能提升
检测结果
三、One-shot object detection with co-attention and co-excitation
论文连接:https://arxiv.org/abs/1911.12529
代码地址:https://github.com/timy90022/One-Shot-Object-Detection
1.摘要
这篇文章主要是在解决小样本目标检测的挑战性问题。给定一个查询图像,其类别标签未包含在训练数据中,任务的目标是检测目标图像中同一类别的所有实例。为此,我们开发了一种新颖的共同注意和共同激发(CoAE)框架,该框架在三个关键技术方面做出了贡献。首先,我们使用non-local操作来探索每个查询目标中的共同注意(采用non-local 操作对query-target匹配对探索co-attention, 并生成ROI用于目标检测框)。其次,我们制定了一种挤压和共激励方案,该方案可以自适应地强调相关的特征通道,以帮助发现相关建议以及最终目标对象(引入squeeze-and-co-excitation scheme可以适应性的调整feature的通道权重)。最后,我们设计了一个基于边距的排名损失,用于隐式学习一种度量来预测区域提议与基础查询的相似性,无论其类别标签在训练中是否可见(第三,设计一个margin-based ranking loss , 学习一种度量方式用来预测ROI和query patch的相似度)。
1. 提出任务
给定一个没有在训练集中出现过的类别的图像补丁,目的是检测出与该类别相同的所有的实例。
假设查询的图像作为未见过的测试集中的的类的原型,任务是在新的目标图像中定位查询对象最可能出现的位置(检测出新的目标的位置)
2. 解决方案
首先,采用non-local 操作对query-target匹配对探索co-attention, 并生成ROI用于目标检测框;
第二,引入squeeze-and-co-excitation scheme可以适应性的调整feature的通道权重;
第三,设计一个margin-based ranking loss , 学习一种度量方式用来预测ROI和query patch的相似度。
2.相关工作
1.Object detection:最新目标检测通常分为两类:第一:one-stage(proposal-free)代表有YOLO;第二:two-stage (proposal-based)代表有Faster R-CNN(RPN)
2.Few-shot classification via metric learning:小样本分类一般采用度量学习,Siamese networks (孪生网络)、matching networks。
3.Few-shot object detection:与小样本分类相似都是基于小样本的任务。但是小样本检测的任务比较新颖,这类的文章比较少。
对于看不见的新颖的类别,我们的做法与类别无关,并且无需培训。 训练过程完成后,我们的模型可以用于检测未见类别的对象,而无需事先知道类别或进行微调。
3.研究方法
3.1 Model
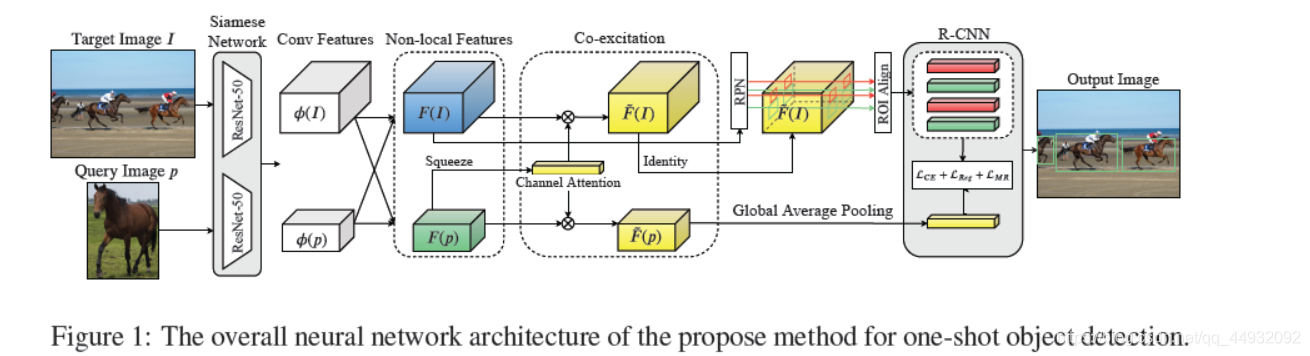
如上图所示,模型首先通过两个以Resnet-50为backbone的Siamese Network,分别学习得到Query的特征和Target Image 的特征;为了解决query image和target image差别过大造成检测框质量差的问题,引入了non-local操作,采用如下公式分别得到non-local后的特征: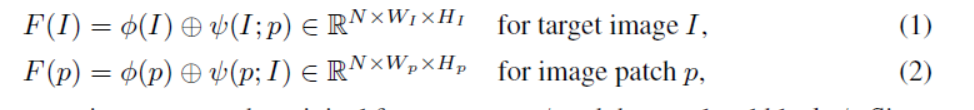
3.2 Non-local object proposals
将通道注意力机制应用到了所有通道的每张特征图对应位置上,本质就是输出的每个位置值都是其他所有位置的加权平均值,通过softmax操作可以进一步突出共性。最后经过一个1x1卷积恢复输出通道,保证输入输出尺度完全相同。采用non-local 操作对query-target匹配对探索co-attention, 并生成ROI用于目标检测框。
经过non-local操作得到的特征图不仅包括目标图像I的图像特征,还包括加权之后的目标图像I和查询图像之间的特征,基于扩展特征设计的RPN将学习查询图像p中探索更多信息,并生成更好的区域建议质量。 换句话说,最终non-local提案将更适合小样本目标检测。
3.3 Squeeze and co-excitation
在实验过程中,发现经过non-local得到的特征它们的通道数是相同的,所以可以考虑采用Squeeze-and-co-excitation方法探索两种features对应通道的关联。其中,Squeeze step对应图1右下角部分,采用GAP对特征进行全局总结;另外co-excitation部分作为两者的桥梁调整通道的权重。
个人认为这里的意思就是将一个通道特征图中的整个图中位置的信息相融合,避免对通道进行权值评估时由于卷积核尺寸问题造成的局部感受野提取信息范围太小参考信息量不足使得评估不准确。首先是 Squeeze 操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。最后是一个 Reweight 的操作,将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
3.4 Proposal ranking
最后,提出一个Proposal ranking loss; 由于proposal框的数量很多的时候,首先用前景背景缩减数量,抛弃背景框;然后采用 提出的 margin-based ranking loss作为度量方法获取与query patch最相关的proposal bounding boxes。
4. 实验结果

结果,所提出的方法可以产生非局部对象提议并使用共激励。强调查询和目标图像共享的重要功能的操作。 最终的小样本目标检测器在两个流行的数据集上实现了最先进的性能。
四、LSTD: A low-shot transfer detector for object detection
Abstract
1,为了解决训练样本不足的问题,提出了LSTD模型,并整合了SSD与faster rcnn模型的优点(即SSD部分模型与faster rcnn部分模型结合)<br /> 2,为了进一步提高检测的微调,提出了一种新的正则化方法:基于原域和目标域的转移指数(TK)和背景抑制(BD)的正则化方法.<br /> 3,Low-shot;少量注释图片的检测
1、Introduction
1,为了解决这个问题,之前的解决办法是引入额外的易于注释的标签图像,但这种缺乏训练集的充分监督. 还有一种解决办法是对深度学习进行转移(弱监督:有标签没有框框.半监督:有标签,部分有框.)
2,Low-shot存在的挑战:a,在不引入额外的图像下,深度学习转移对检测是不适用的,因为这是小目标,涉及到微调.b,深度检测在转移学习中比分类更容易出现过拟合.c,简单的微调会降低可转移性.
3,TK主要在目标提案中transfer标签知识.BD主要是用框来做特征图的额外监督,这样可以在transferring中抑制背景的干扰
3,Low-Shot Transfer Detector(LSTD)
Basic Deep Architecture of LSTD: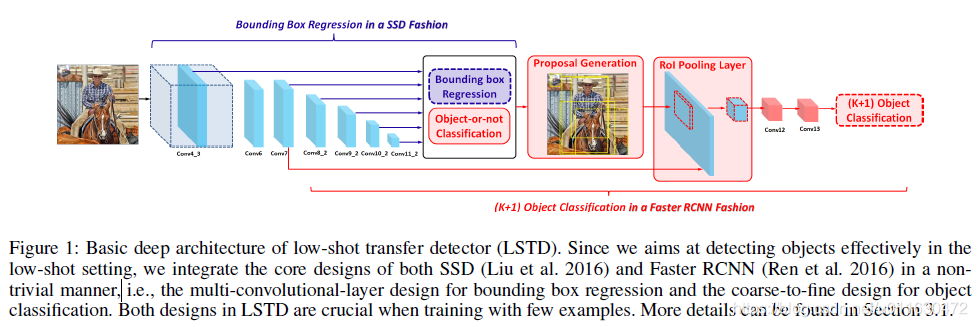
利用SSD设计边界盒回归,对于每一层都有默认的候选框.每一层都用smooth L1来对框的回归进行训练.(这对few-shot来说,很重要,因为缺少大小多样性的样本,也减少了后面的微调负担). 用faster rcnn设计目标分类,对于默认的框,根据每个框的分类得分,来选折RPN的目标提案.然后将ROI应用于卷积网络的中层,对每个proposals生成固定大小卷积特征.最后用两个卷积层代替faster rcnn原始的全连接层来进行分类.(注意:这里就是将原始faster rcnn的框的回归换成了SSD的多尺度框的回归,原始的RoI层中的特征层,用SSD的卷积的中层特征代替)
Regularized Transfer Learning for LSTD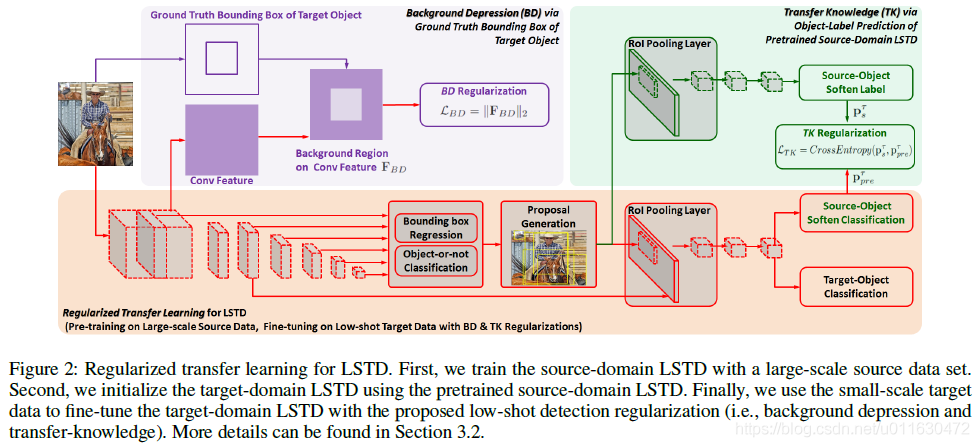
首先用大量的源数据训练图1中的模型(basic LSTD). 然后用本文提出的正则化方法在目标域中进行微调预训练的LSTD(图一的模型),微调的总的损失函数如下: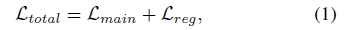
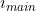 指在LSTD中的多个尺度层的回归损失和微调目标分类的损失(即后面的两个卷积),(源域与目标域相关但不同,因为low-shot检测在少量目标数据中之前没有出现过的类别).因此在目标域中需要重新初始化.即源域训练好的用来当做目标域的初始化,然后来进行微调.为了避免过拟合,加了正则化项.:
指在LSTD中的多个尺度层的回归损失和微调目标分类的损失(即后面的两个卷积),(源域与目标域相关但不同,因为low-shot检测在少量目标数据中之前没有出现过的类别).因此在目标域中需要重新初始化.即源域训练好的用来当做目标域的初始化,然后来进行微调.为了避免过拟合,加了正则化项.: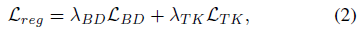
 分别表示的是,背景抑制和知识迁移项.
分别表示的是,背景抑制和知识迁移项.
Background-Depression (BD) Regularization
由于复杂的背景信息会影响localization性能,所以在目标域中用object knowledge 设计了BD正则化.从卷积的中间层生成特征立方(candidate boxes) 然后用groud truth bounding boxes取匹配框,找出与背景对应的特征区域即.然后使用L2正则化.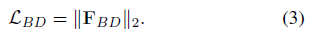
Transfer-Knowledge(TK) Regularization
由于源域与目标域的类别不同,所以在目标域中就要微调,如果只用目标域的数据进行微调,就不能充分利用源域的知识.所以提出了TK正则化,它将源域的目标标签预测作为源知识去正则化目标网络
算法如下:
(1) Source-Domain Knowledge:我们将training图片分别喂到源和目的LSTD里面,然后将目标域的提案应用于源域的LSTD的ROI池层.最终从源域对象分类器中生成知识向量.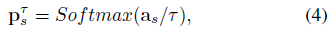
其中As是vector for each object proposal,τ参数,可以产生soften label和richer-relation information.
(2)Target-Domian Prediction of Source-Domain Categories.:将(1)中的目LSTD微调成多目标学习框架:添加a source-object soften classifier at end of target-domain lSTD: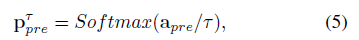
其中Apre是 each proposal.
(3) TK Regularization.
五、基于局部和全局特征表示的红外目标检测算法研究
摘要
红外小目标检测:旨在研究远距离红外成像时目标的快速检测技术,面临着目标尺寸小、纹理信息稀缺、图像背景复杂和信噪比较低等难点。
基于特征表示的红外小目标检测:优异的目标增强和背景抑制能力。难点:如何描述小目标的内在特性并构造有效的特征表示,如何设计具有杂波鲁棒性的检测算法。
本文:基于局部-全局特征表示的红外小目标检测算法
(1)基于多尺度局部亮度差异度量和局部能量因子的小目标检测算法:更高的目标增强能力和检测精度。
(2)基于改进随机游走的两阶段式小目标检测算法:剔除更多误检点,降低虚警率。
(3)基于带局部特征约束的图拉普拉斯的端到端式小目标检测算法:更高的检测精度。
(4)基于分布式最大熵随机游走的多小目标检测算法:目标增强、背景抑制和多目标检测精度上均有提升。
六、图像识别中小样本学习方法与模型轻量化研究-李文静
- 摘要
研究深度学习亟待解决的两个问题:
小样本(训练数据标注不充分)和模型轻量化(测试平台存储计算资源有限)的问题。
本文主要对小样本问题中的度量方式、特征提取方法以及如何利用无标签样本进行了研究。
从度量学习角度出发,提出了一种新的面向直推小样本学习的局部和全局的相似度度量方式。
从数据角度出发,提出了一种新的基于上下文相似度的二阶注意力模型用于解决半监督的小样本分类问题。
从应用角度,提出一种新的面向应用的基于单视角的小样本学习方法。
本文进一步研究了具体细粒度图像任务中的小样本问题,即行人重识别中的单视角问题。
为了研究模型轻量化方法,本文选取一个代表性的智能车载应用驾驶行为分析作为具体研究载体。
提出一种新的基于样本的多教师知识蒸馏的方法,学习准确率高,速度快的轻量卷积
七、Few-shot Classification via Adaptive Attention
Attention Module
Adaptive attention module的目标是准确获取空间信息:找到support image中的物体在query image中的位置。关键在于基于support image自适应地生成query image的attention map。本文提出meta-reweighting based attention generation。
总体流程如下:
1. support images和query image转化为相应的feature。
2. support feature进入meta-weight generator,产生一个对应类别的权重向量。
3. 产生的权重向量和query feature进行channel-wise multiplication,得到的结果进入spatial attention generator。
4. 得到attention map。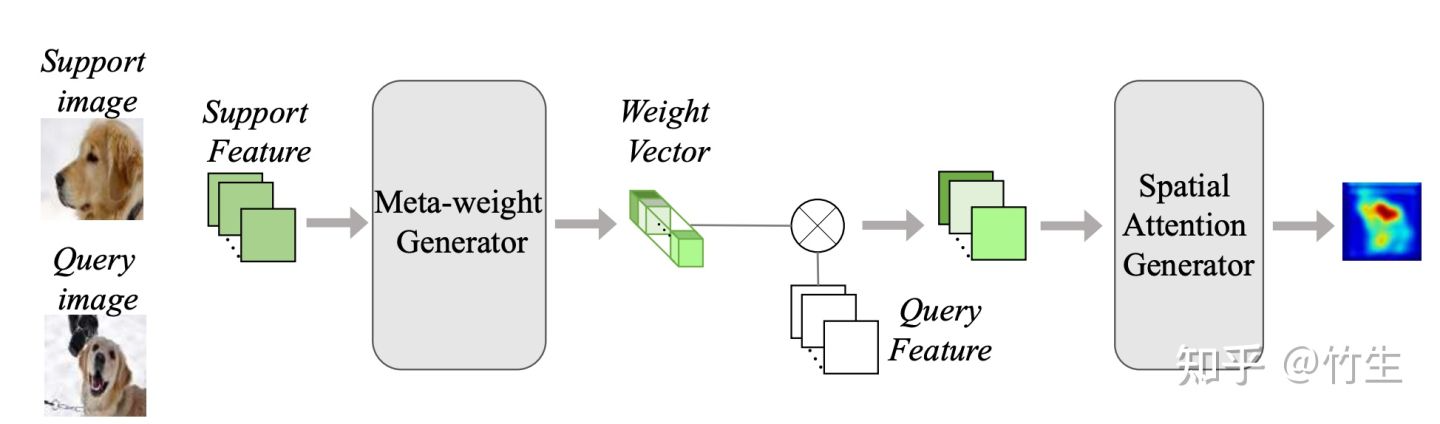
Meta-weight Generator
人类辨认物体往往都是通过有区别性的特征,比如要在一个房间里找猫,我们会找两只眼睛四只脚,全身毛儿,长尾巴等等特征的生物。Meta-weight generator利用这个原理,通过support feature计算产生class-dependent weight vector。
这里的乘法是channel-wise multiplication。  和
和  分别是support feature和query feature。
分别是support feature和query feature。  表示Meta-weight generator。得到的结果
表示Meta-weight generator。得到的结果  是对应class
是对应class  的feature。
的feature。
如果当前图片  不属于类别
不属于类别  ,那么这个feature map会产生很多无用信息,最终导致分类器会给这张图片一个比较低的分数。
,那么这个feature map会产生很多无用信息,最终导致分类器会给这张图片一个比较低的分数。
Spatial Attention Generator
该部分设计由两层Conv layer以及一个one-channel final output map组成。最后得到:
代表的就是出现在support里的物体在qurey里位置。
Classifier
经过上面的adaptive attention module,我们可以得到每一张query image的attention map。
其中,  代表point-wise multiplication,
代表point-wise multiplication,  是query feature,
是query feature,  是 class-dependent attention map。得出的feature将被用于最后的分类。
是 class-dependent attention map。得出的feature将被用于最后的分类。
分类器由一层pooling layer和多层linear layer组成。对于每一对  ,分类器会计算输出一个分数。
,分类器会计算输出一个分数。
然后为了结果的对称性,作者又加了一步通过query里的物体找support里对应位置(个人感觉非常类似于Prototypical Aligment Regularization的思想,详情请查阅PANet,关于小样本分割)。所以最后的分数变成了:
Training
首先我们的任务是K-ways n-shots小样本分类。也就是说我们有K个类别,每个类别有n个样本。经过Attention Module后每张query image会产生K个attention maps  。经过global average pooling layer,每一张query image会得到K个分数
。经过global average pooling layer,每一张query image会得到K个分数  ,表示query image
,表示query image  属于类别
属于类别  的可能性。注意这个分数是中间产物(avgpooling之后的output),不是最后得出的分数。
的可能性。注意这个分数是中间产物(avgpooling之后的output),不是最后得出的分数。
训练的loss分为两部分:attention module部分产生的loss和classifier部分产生的loss。
 是attention module的cross-entropy loss。
是attention module的cross-entropy loss。
Classifier最后的output是:
我们对每个类i计算平均分数:
这个分数代表着query image  和该类别下的图片
和该类别下的图片  属于同一类的可能性。
属于同一类的可能性。
Classifier产生的loss为:
最后的loss为: 

若有收获,就点个赞吧
0 人点赞
