已搭建好单机版的Solr服务器,最后启动Tomcat,在Google Chrome浏览器中访问http://localhost:8080/solr/index.html,你可以很清楚地看到Solr的后台管理界面,如下图所示。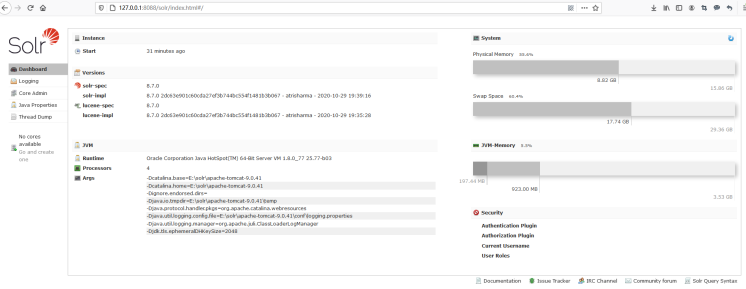
Dashboard
Dashboard即为仪表盘,它显示了Solr实例开始启动运行的时间、版本、系统资源以及JVM等信息,这可以从下图所示的Solr后台管理界面中看出。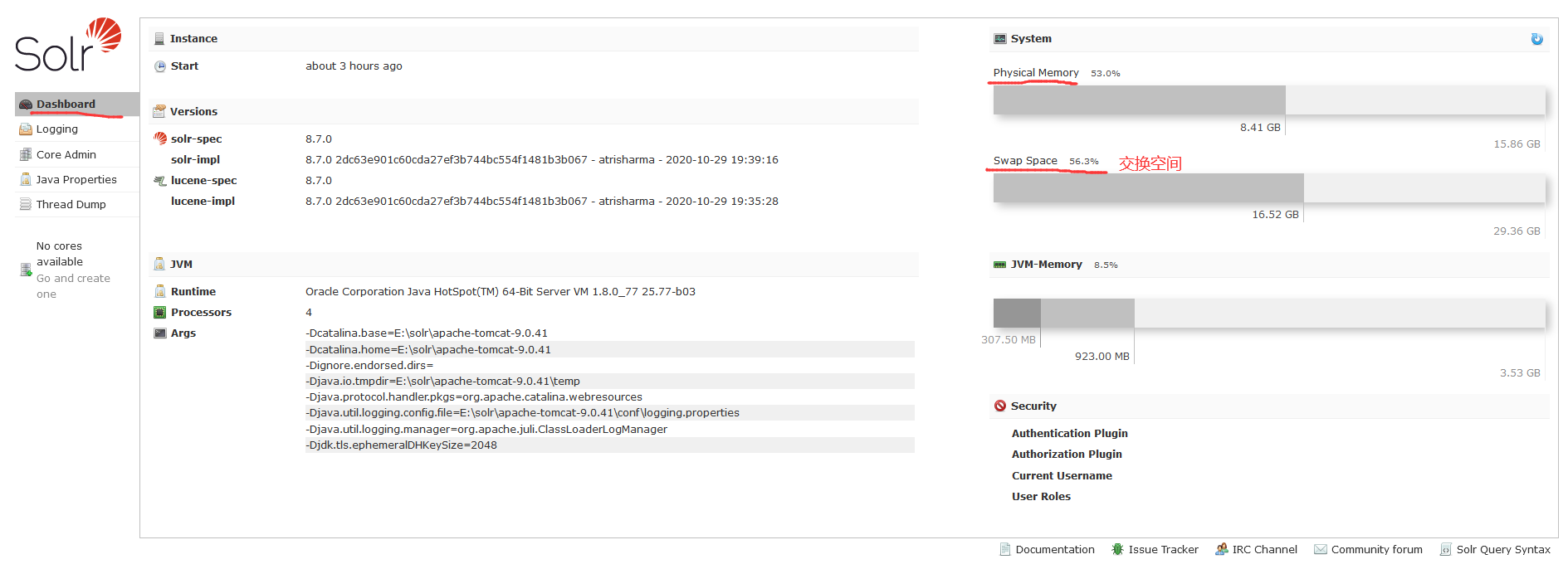
小朋友,你是不是有很多问号?上图中的Swap Space到底是啥意思啊?Swap Space即交换空间,也叫虚拟内存。它到底有什么用呢?给大家举个例子,假设你有一个4G的内存条,但是在你用着用着的时候,忽然间电脑发现这个内存条不够用了,要满,这个时候它会采用一个策略,即将这个4G大小的内存当中最近一段时间内用的不频繁的、使用率极低的一部分转存到磁盘上。假如说这4个G中有1个G转存到了磁盘上,内存是不是就可以剩余出1个G啦!然后再接着运行你当前的程序,而转存的这1个G就放到了你的硬盘上了(例如硬盘总共是500个G,其中用1个G占内存的这一块就叫做虚拟内存,也叫交换空间)。
虚拟内存越大,电脑速度会加快,这个说法是成立的,只是说快得没有那么明显。如果平时4个G大小的内存都用不了,那么这块虚拟内存用不用啊?不用,你想一想这4个G大小的内存都使不了,那这块虚拟内存就更加不会再使用了。
还有一个问题,如果你将这个虚拟内存设为64M,那么你的物理内存能不能说用65M呢?不能,一旦出现这种情况就会造成内存里面只会最大有64M的东西放到你的虚拟内存当中,也就是你的硬盘上。至于再往下存不下了,那就会造成机器卡顿。因为此时内存条已经满了(内存处于等待状态),满了之后,你再给它安排活,它就不干了,它会等它干完手上的活之后,再干你的活,这样就会造成在使用电脑的过程中,出现卡顿的现象。
Logging
它会显示Solr运行日志信息。要想成为一名合格的程序员,你就必须得学会看日志,试想一下如果在存储数据的过程中出现了问题,你怎么知道出现了什么问题呢?这时,你就得看日志了。
更早期版本的Solr后台管理界面的Logging是下图所示这样子的,这里我就以它来介绍了。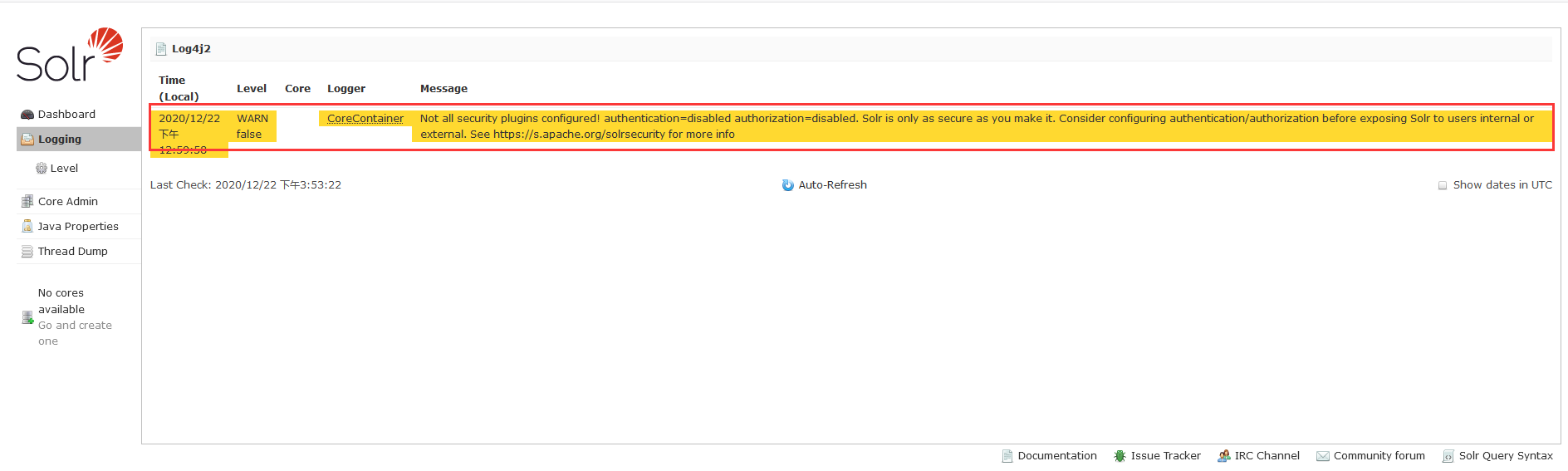
从上图中可以看到出现了好多的警告信息,你不仅就要问为什么会出现这些警告信息呢?别急,原因我会娓娓道来。咱们在启动Tomcat的时候,是并没有去配置Solr服务器的核心配置文件的。不信的话,你打开E:\solr\solrHome\collection1\conf文件夹,将会发现该文件夹下有一大堆的配置文件,而这一大堆配置文件当中最核心的配置文件就是solrconfig.xml。继续打开solrconfig.xml核心配置文件,你便会发现它里面配置了如下这些东西。
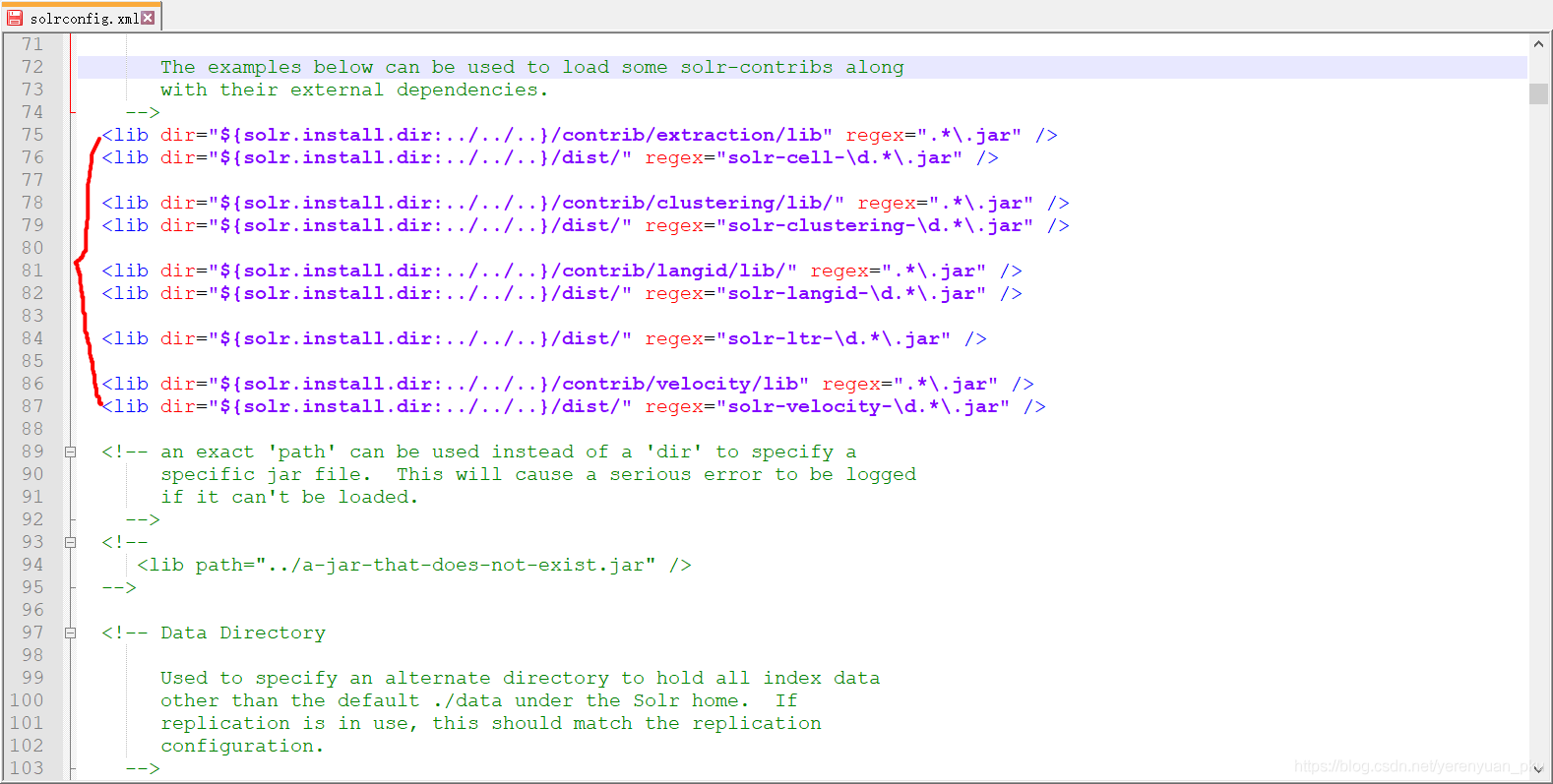
如上配置就是要求这个solrconfig.xml核心配置文件在走这一刹那的时候,去加载一些第三方支持包插件,也即第三方jar包。其中,${solr.install.dir}这个目录指(对应)的就是D:\solr\solrHome\collection1目录,很显然${solr.install.dir:../../..}就是在D:\solr\solrHome\collection1该目录基础上连退三层目录,最后就到了D盘了,而D盘下显然是没有contrib或者dist目录的,所以就会报上面出现的那些警告信息!
Core Admin
Solr Core的管理界面。Solr Core是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个Solr Core(Solr实例),一个Core对应一个索引目录。要是你理解起来难的话,可以将Solr核管理理解成数据库管理,即一个核就是一个数据库。
进入Solr后台管理界面,可以发现其左下角显示的是No cores available,所以我们可以点击Core Admin,在右侧出现的界面中点击Add Core按钮,来创建一个新的Core。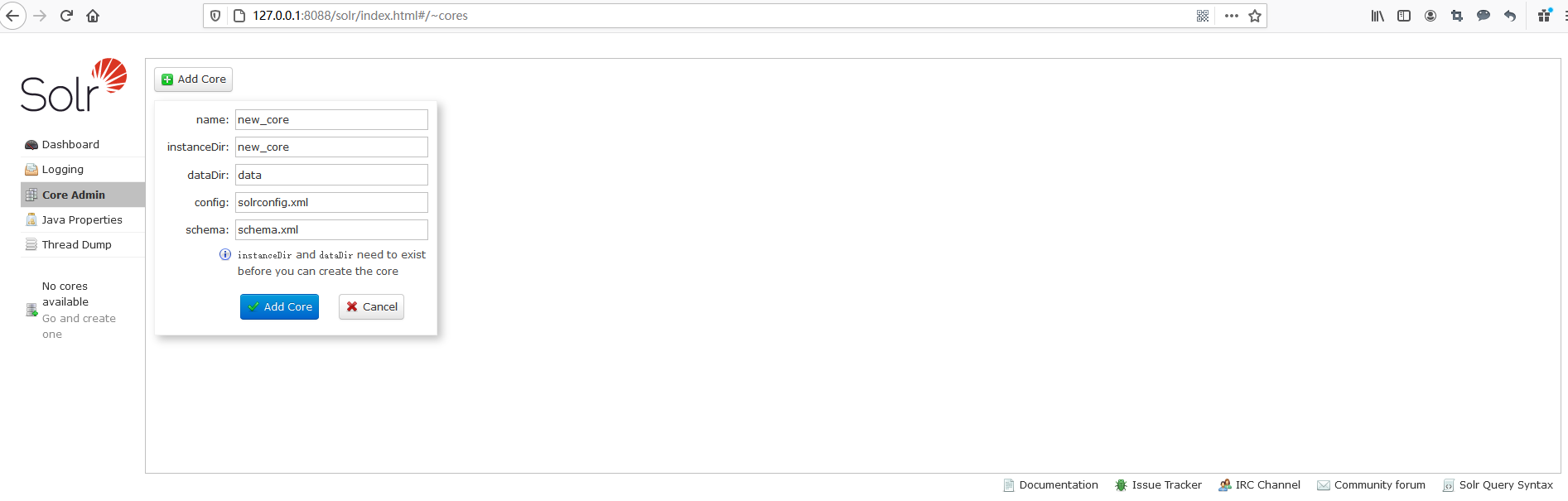
这时将会在我们指定的solrHome文件夹内产生一个new_core的空文件夹,并且页面会报错:Can't find resource 'solrconfig.xml' in classpath or 'E:\solr\solrHome\new_core',意思就是说在这个新Core下的conf文件夹中没有找到solrconfig.xml文件。这他妈的不是废话吗?新创建的new_core文件夹里面就是空的,啥都没有,哪来的conf文件夹啊!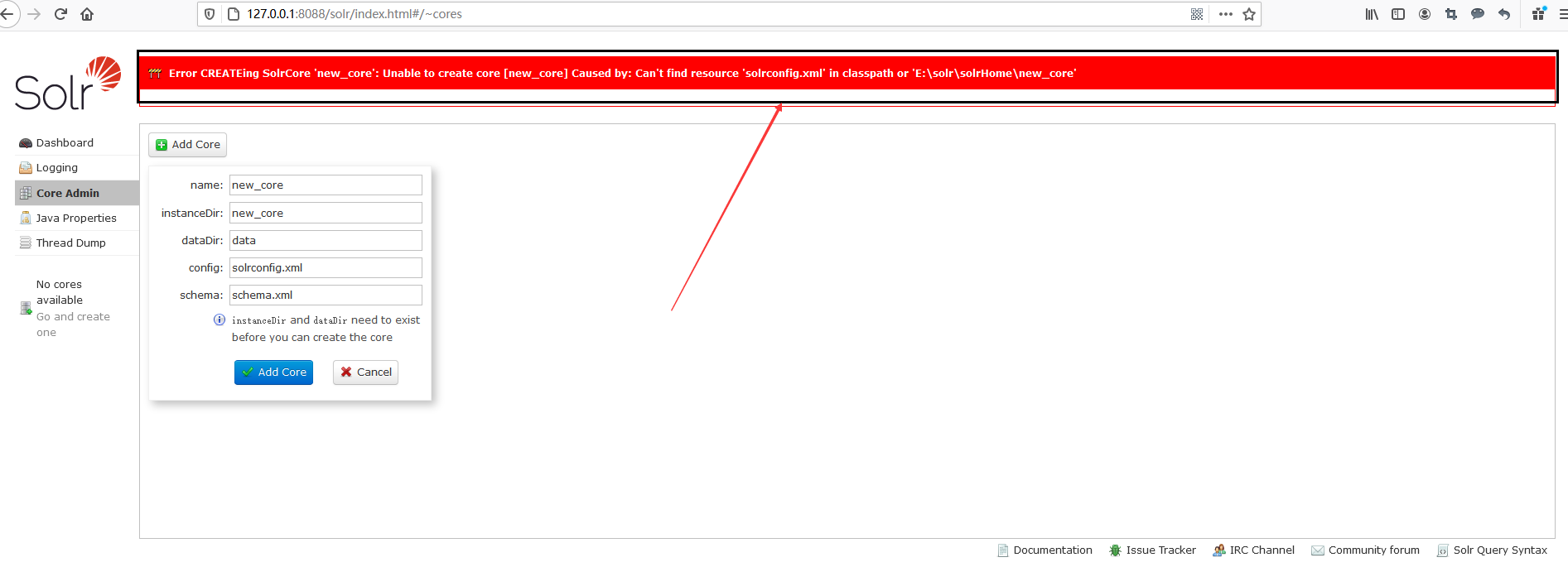
综上所述表明,像上面那样是添加不了核的(既然加核失败,那就把new_core空文件夹删除掉吧!),所以我们得自己手动添加Solr Core,步骤如下:
- 第一步:在solrHome文件夹下新建一个名为core001的文件夹(名字可以随意取,它将作为一个core核心);
- 第二步:将
E:\solr\solrHome\configsets\_default路径下的conf文件夹复制到此collection1文件夹中; - 第三步:在core001文件夹中新创建一个名为core.properties的文件,并在该文件中添加
name=core001配置,这里的name的值也就是在页面中要显示的Sole Core的名称; - 第四步:重启Tomcat服务器。
此时,进入Solr后台管理界面,点击Core Admin就可以看到刚刚我们自己添加的Core( core001)。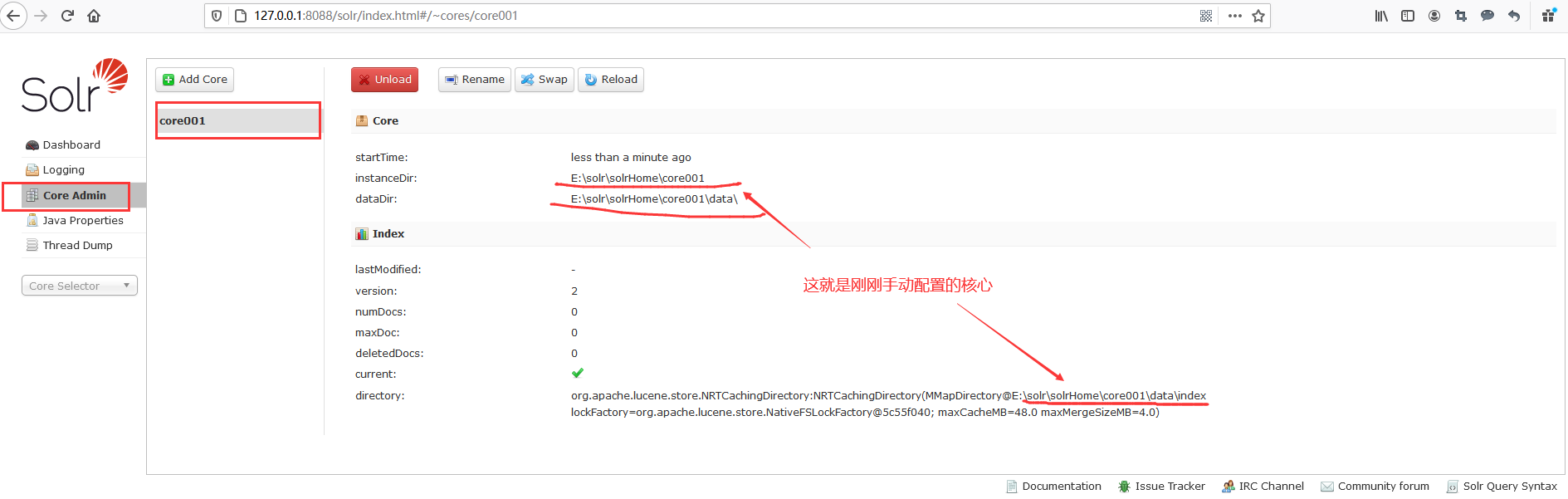
从上图可以看到我们自己添加的Core( core001)的相关信息。如果试着打开core001文件夹,那么你便会发现在它里面新创建了一个data文件夹,而它就是索引数据存放的地方。
至此,你该知道如何手动添加Solr Core了吧!趁热打铁,不如你试着手动添加一个名为core002的Core,就像下面这样。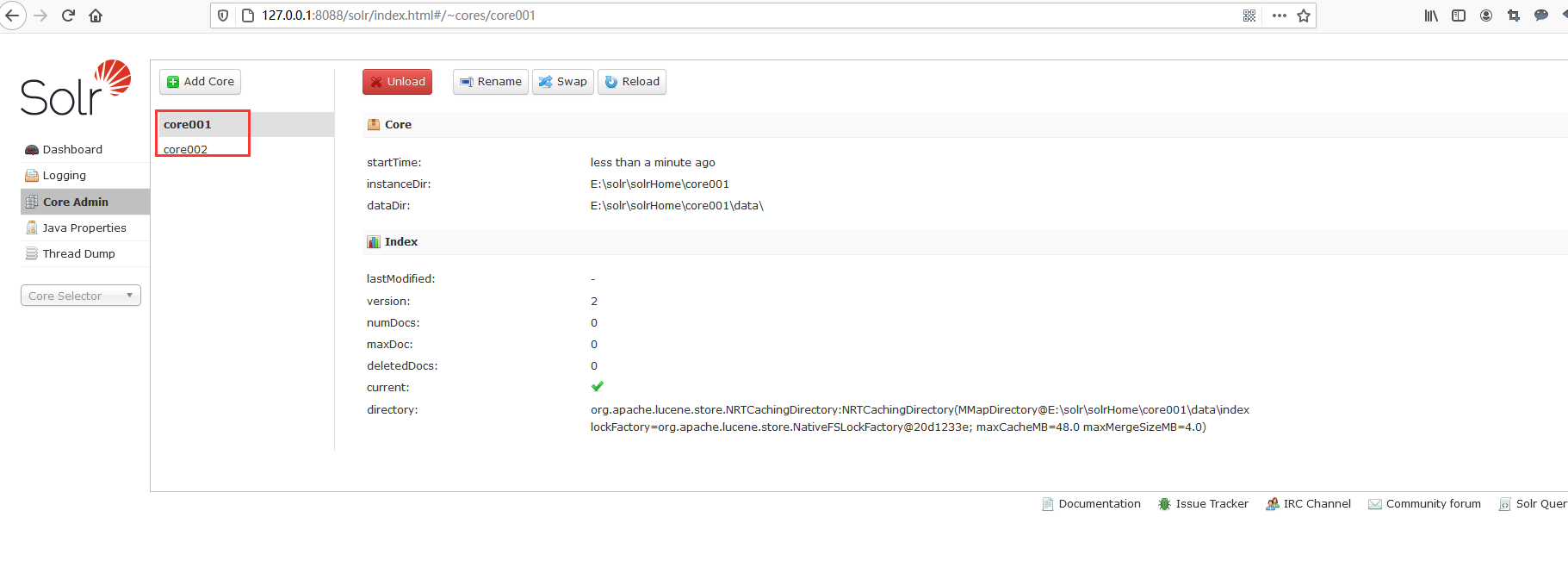
特别提示:在企业中,核一般都用核1,很少使用核2的,只有那么个别公司会用,因为太穷了,穷到啥程度呢?比如说商品和订单能不能分个层啊,那么这时公司就要用两台机器了,但现在没有两台机器,就一台,那怎么办呢?那就用核2。
Java Properties
Solr在JVM运行环境中的属性信息,包括类路径、文件编码以及JVM内存设置等信息。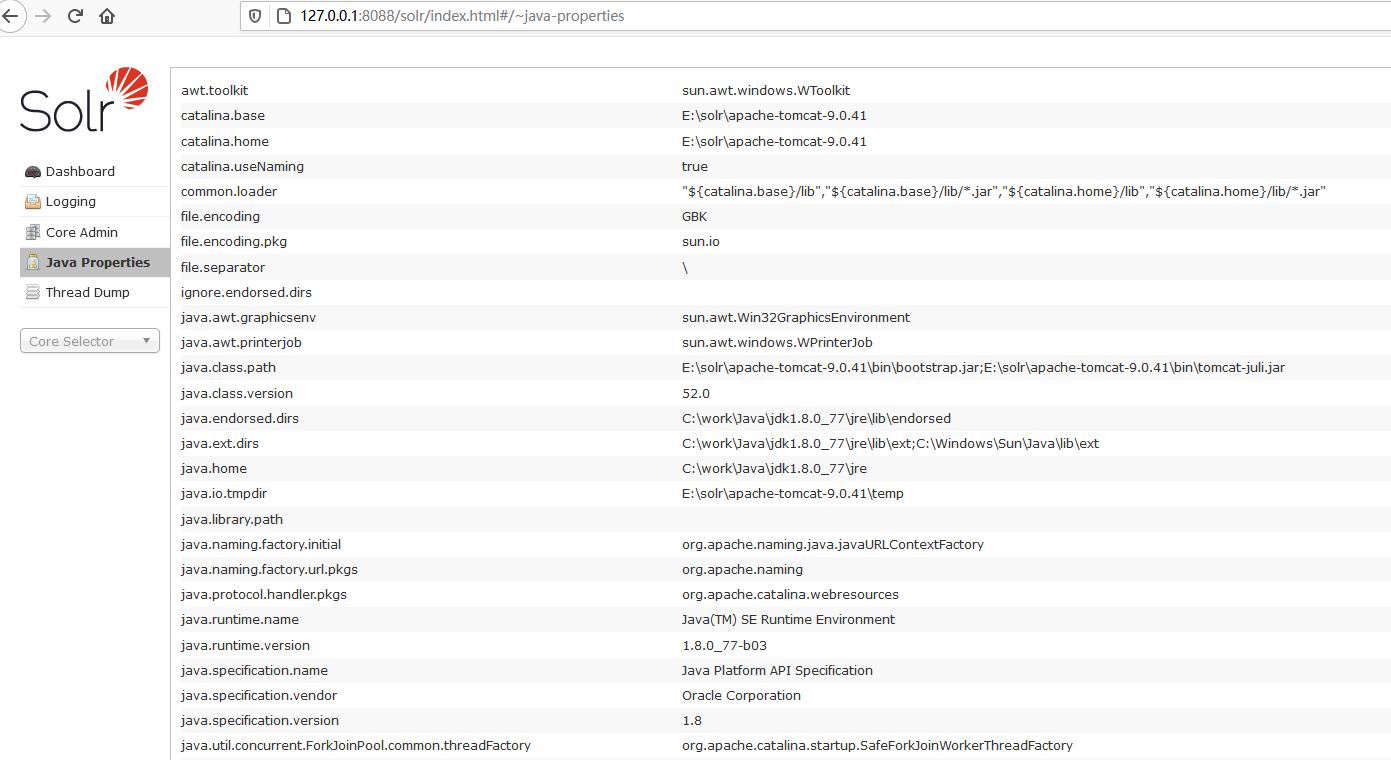
Tread Dump
显示Solr Server中当前活跃的线程信息(增删改查索引都会产生一些线程),同时也可以跟踪线程运行栈信息。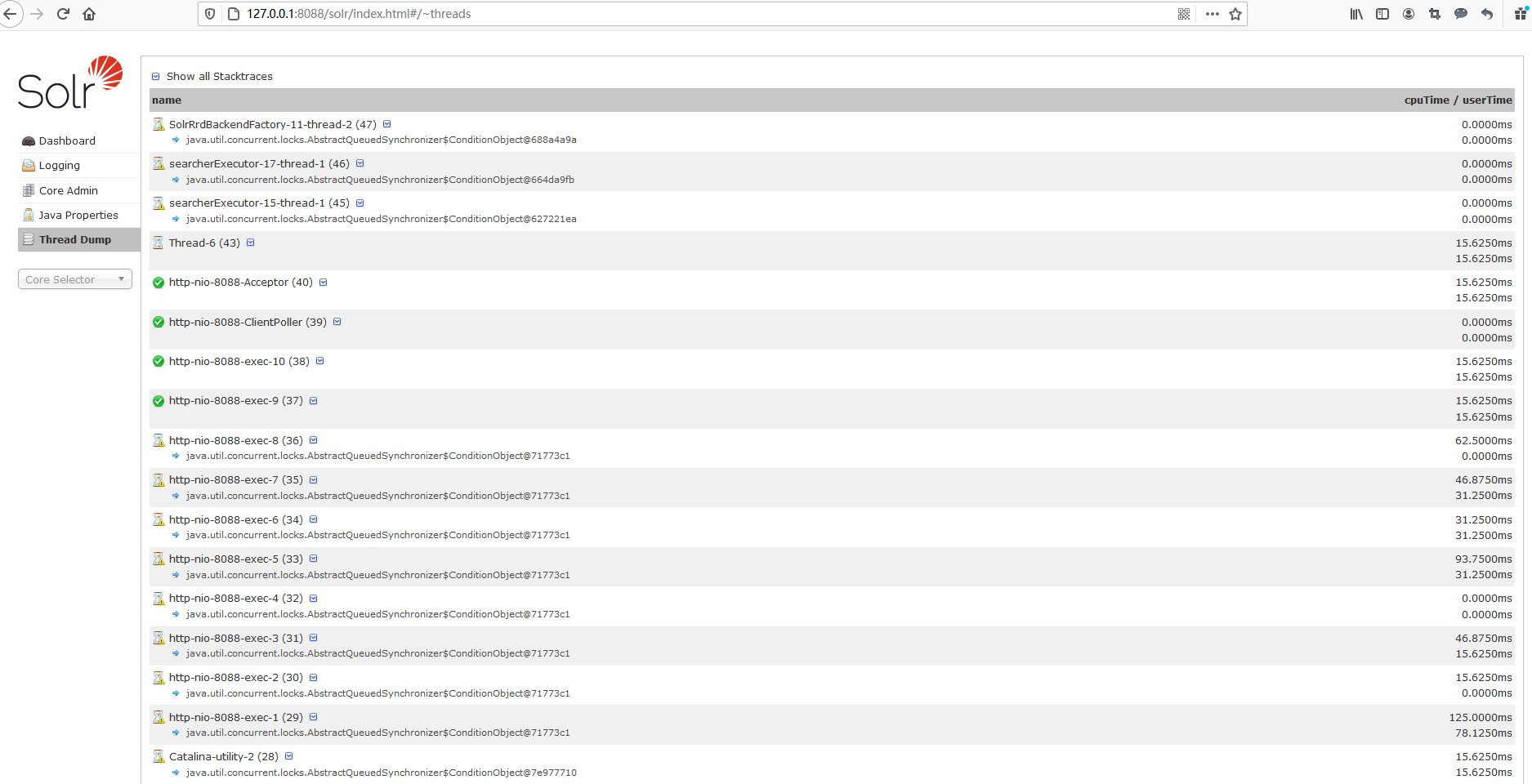
Core Selector
即操作具体核。选择核1并进入之后,你便会看到如下图所示的界面。
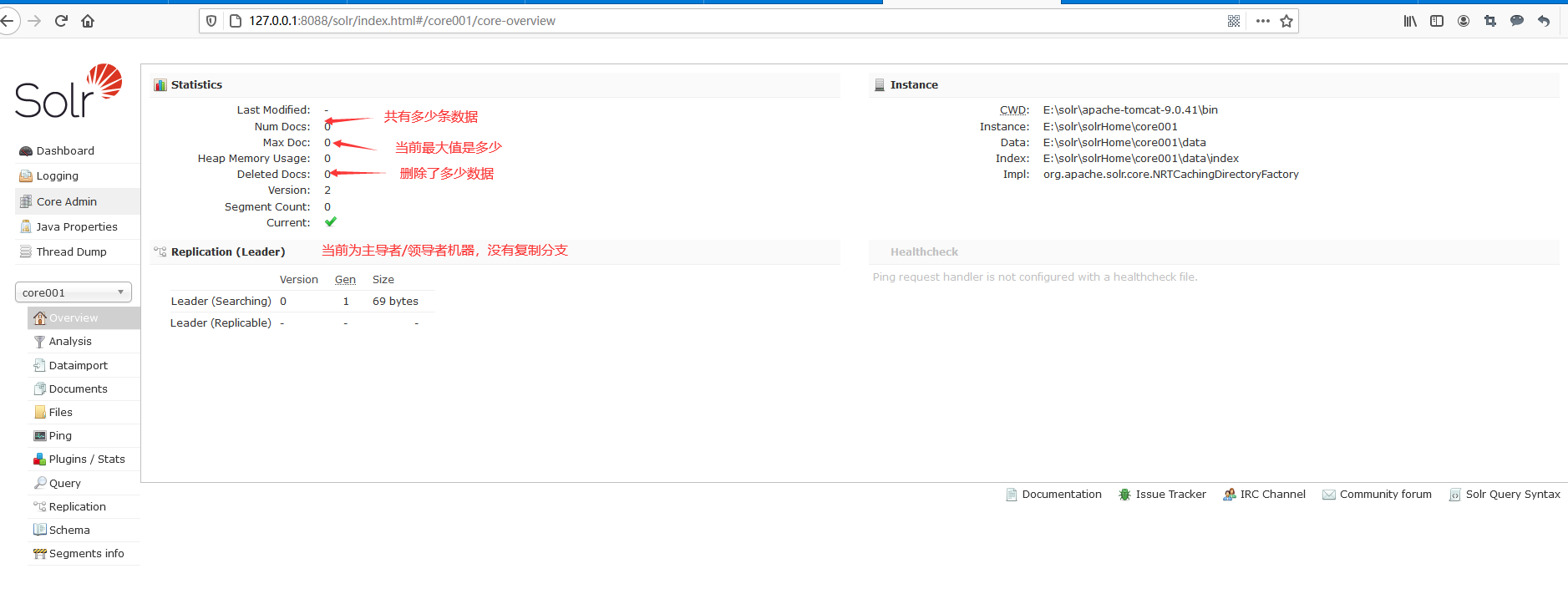
从上图可以清楚地看到,当前是Master机器,并没有副本。啥叫副本啊?搭建集群就得有副本,防止你一台Solr服务器有可能挂掉,因为一旦挂掉了,机器就不能再用了。这里我稍微提一下集群,集群有两大目的,第一个目的就是为了防止机器挂掉后不能再使用,第二个目的就是为了防止存储索引过多时存不下。 所以,一旦搭建完集群之后,你便会发现整个机器的稳定性就会非常好,一旦主机挂掉,备机就会工作,一旦索引存不下,就用多个组来存,每一组是一主一备。假设现在有组1和组2这两组,那么你就会发现现在共有四台机器,其中两台为主备关系,另外两台为主备关系,这四台之间,两台和两台之间是两组,每组存的数据都不一样。打个比方,现在有一百万条数据,那么可以一组存五十万条数据,另外一组再存五十万条数据,这就是所谓的扩容。
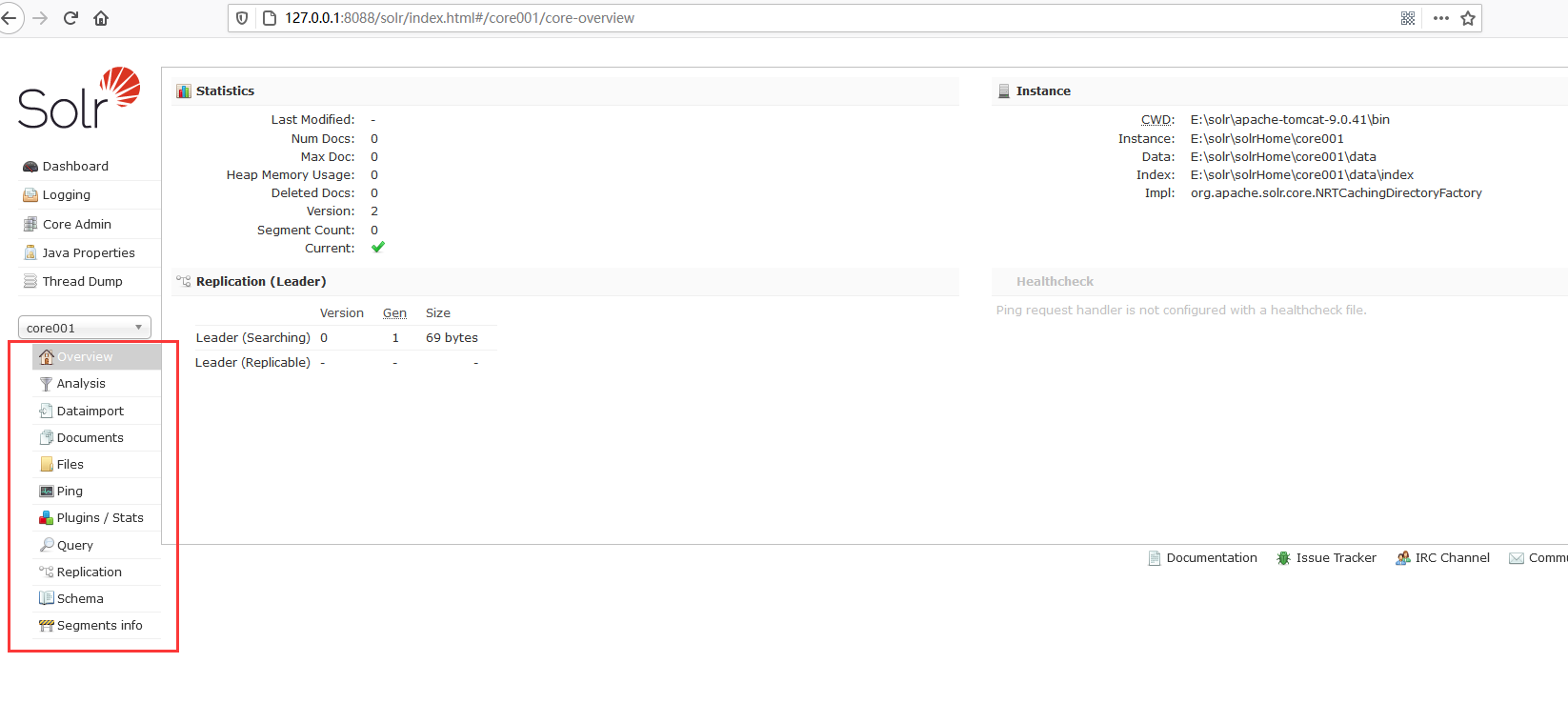
当咱们选择了一个Solr Core进行详细操作时,你便会发现有如下这些操作。
Analysis
分词,但默认使用的是标准分词器。点击Analysis之后,可以通过右侧的界面测试索引分析器和搜索分析器的执行情况。其默认中文分词,是按照单个字的分词,这明显达不到预期目的,后面会介绍IK分词的集成**。**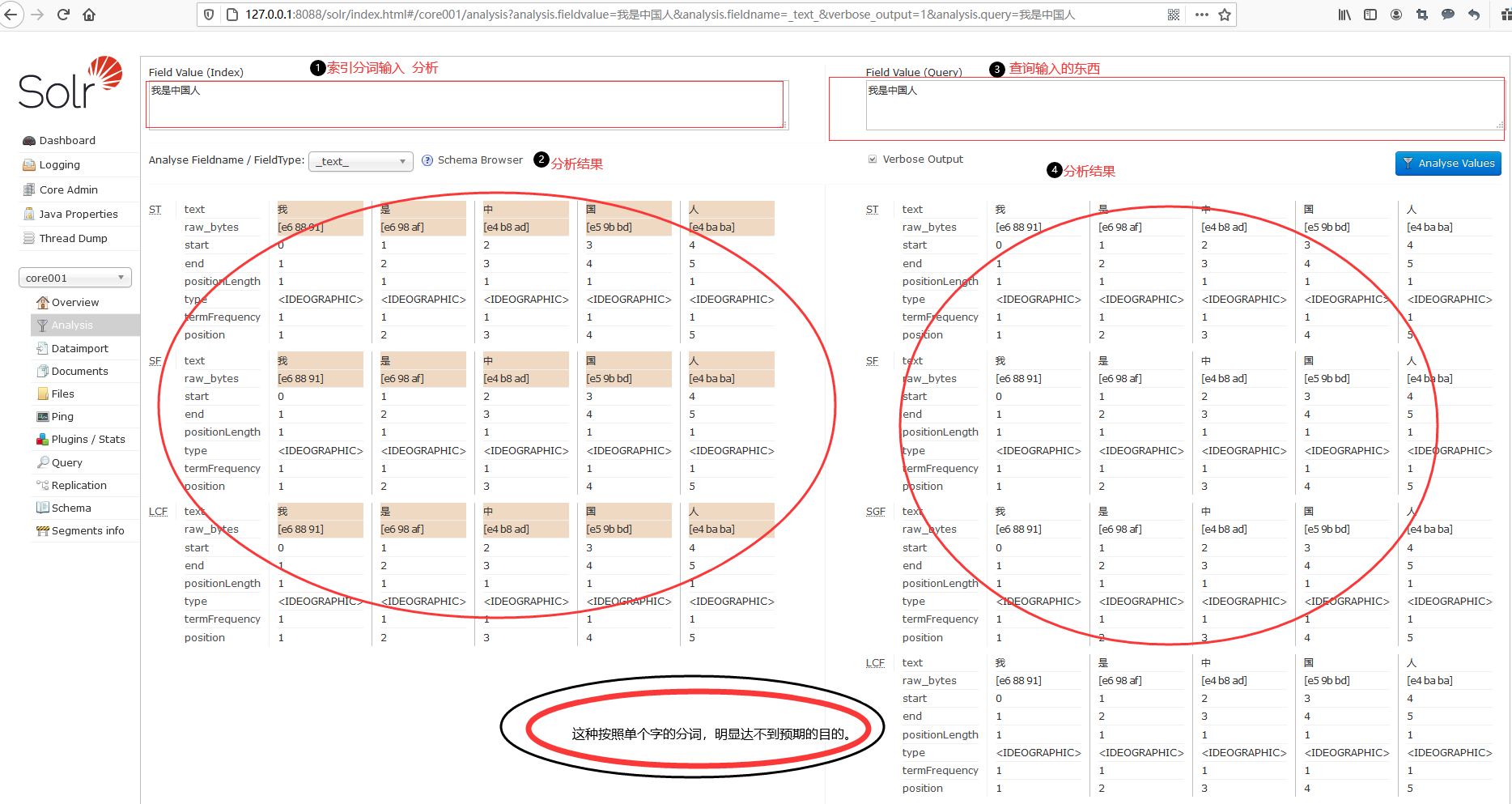
Dataimport
可以定义数据导入处理器,从而将关系型数据库中的数据导入到Solr索引库中。
Documents
通过此菜单可以执行创建索引、更新索引、删除索引等操作,即增删改索引等操作。点击Documents之后,你便会看到如下右侧界面。
这里,我会举个例子来演示创建索引是如何来进行操作的。大家可以按照下图所示的内容来填写。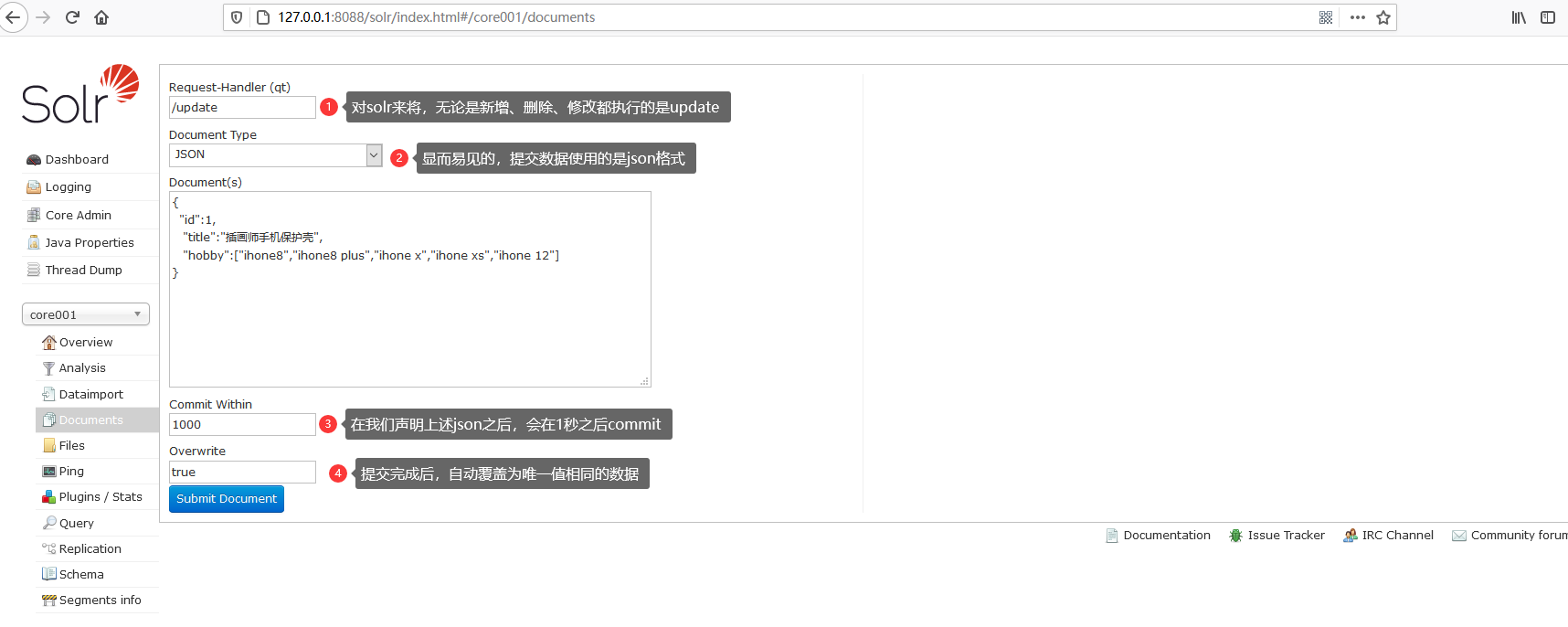
当点击Submit Document按钮之后,你便会看到如下图所示的效果,这代表已经成功创建了索引。
温馨提示:/update表示更新索引,Solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
Files
通过此菜单可以将Solr服务器的配置文件以浏览器的方式显示出来,就如下图所示的这样。
Ping
通过此菜单可以测试Solr服务器是否还活着。如果Solr服务器挂掉了,那么你便会看到如下图所示的效果。
Plugins/Stats
对于更早期版本的Solr而言,由于Solr的家就是E:\solr\solrHome目录,所以并不会去加载一些第三方支持包插件。
Query
通过此菜单可以执行搜索索引操作。点击Query之后,你便会看到如下右侧界面。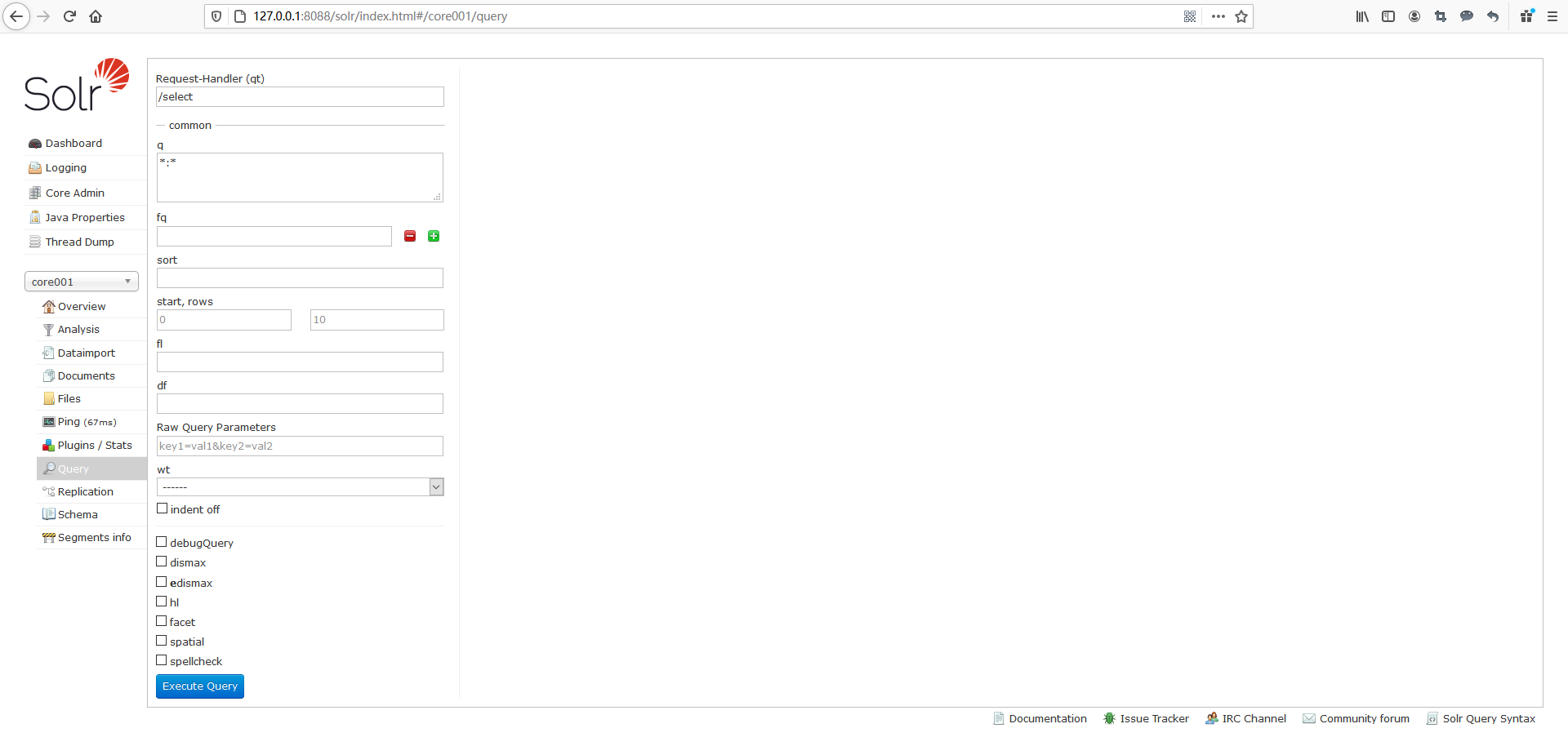
这里,我会举个例子来演示搜索索引是如何来进行操作的。大家可以按照下图所示的内容来填写。
温馨提示:通过/select执行搜索索引操作时,必须指定”q”查询条件方可进行搜索。
最后,点击Execute Query按钮,你便会看到如下图所示的搜索结果,可以看到我们上面添加的索引。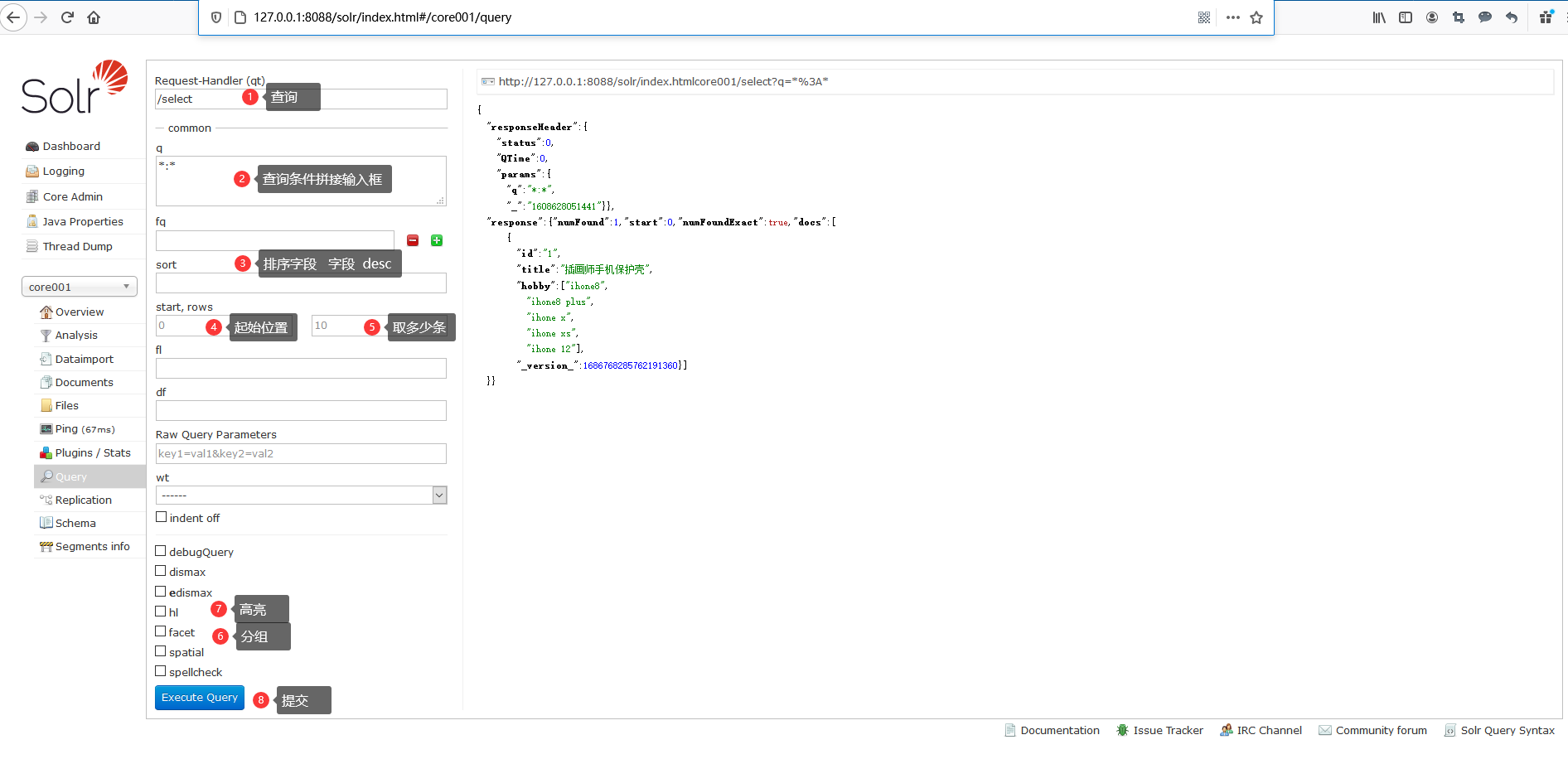
Replication
由于目前还没有副本,所以不作深入介绍。
Schema
这里,我稍微说一下,后面会详细介绍。其实它就是Schema里面的配置,里面会有大量的域,我之前讲解的时候是说一个文档会有四个域,即文件名称、文件大小、文件路径以及文件内容。但实际在Solr当中,一个文档不会只有四个域,Solr会写一大堆的域给你准备用。

若有收获,就点个赞吧
0 人点赞
