1、线程的生命周期


2、线程的创建方式
方式1:继承 Thread 类
步骤:
1、创建一个继承于Thread类的子类;
2、重写Thread类的run(),将此线程执行的操作声明在run()中;
3、创建Thread类的子类的对象;
4、通过此对象调用start()。
注意点:
- 我们不能通过直接调用
run()的方式启动线程。 - 如果再启动一个线程,必须重新创建一个
Thread子类的对象,调用此对象的start(),不可以还让已经start()的线程去执行,会报IllegalThreadStateException。
【示例代码】
// 1. 创建一个继承于Thread类的子类class MyThread1 extends Thread {// 2. 重写Thread类的run()@Overridepublic void run() {for (int i = 0; i <= 100; i++) {if (i % 2 == 0) {System.out.println(Thread.currentThread().getName() + ": " + i);}}}}public class ThreadTest1 {public static void main(String[] args) {// 3. 创建Thread类的子类的对象MyThread1 t1 = new MyThread1();t1.setName("线程1");// 4.通过此对象调用start():// ①启动当前线程 ② 调用当前线程的run()t1.start();// 再启动一个线程MyThread1 t2 = new MyThread1();t2.setName("线程2");t2.start();}}
方式2:实现 Runnable 接口
创建步骤
1、创建一个实现了 Runnable 接口的类;
2、实现类去实现 Runnable 中的抽象方法:run();
3、创建实现类的对象;
4、将此对象作为参数传递到 Thread 类的构造器中,创建 Thread 类的对象;
5、通过 Thread 类的对象调用 start()。
【示例代码】
// 1. 创建一个实现了Runnable接口的类class MyThread implements Runnable {// 2. 实现类去实现Runnable中的抽象方法:run()@Overridepublic void run() {for (int i = 0; i < 100; i++) {if (i % 2 == 0) {System.out.println(Thread.currentThread().getName() + ": " +i);}}}}public class ThreadTest {public static void main(String[] args) {// 3. 创建实现类的对象MyThread myThread = new MyThread();// 4. 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象Thread t1 = new Thread(myThread);t1.setName("线程1");// 5. 通过Thread类的对象调用start():// ① 启动线程 ②调用当前线程的run()-->调用了Runnable类型的target的run()t1.start();// 再启动一个线程:Thread t2 = new Thread(myThread);t2.setName("线程2");t2.start();}}
继承方式与实现方式的比较:
- 开发中优先选择实现
Runnable接口的方式。原因:- 实现的方式没有类的单继承性的局限性。
- 实现的方式更适合来处理多个线程有共享数据的情况。
- 联系:
public class Thread implements Runnable - 相同点:两种方式都需要重写
run(),将线程要执行的逻辑声明在run()中。
方式3:实现 Callable 接口
创建步骤
1、创建一个实现Callable接口的实现类;
2、实现call()方法,将此线程需要执行的操作声明在call()中;
3、创建Callable接口实现类的对象,并将此Calllable接口实现类的对象作为参数传递到FutureTask构造器中,创建FutureTask对象;
4、将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()方法;
5、获取Callable中call()方法的返回值,get()方法的返回值即为FutureTask构造器参数Callable实现类重写的call()方法的返回值。
如何理解实现**Callable**接口的方式创建多线程比实现**Runnable**接口创建多线程方式强大?
1、call()可以有返回值的。
2、call()可以抛出异常,被外面的操作捕获,获取异常的信息。
3、Callable是支持泛型的。
【示例代码】
// 1.创建一个实现Callable的实现类class NumThread implements Callable<Integer> {// 2.实现call方法,将此线程需要执行的操作声明在call()中@Overridepublic Integer call() throws Exception {int sum = 0;for (int i = 0; i <=100; i++) {if (i % 2 == 0) {System.out.println(i);sum += i;}}return sum;}}public class ThreadNew {public static void main(String[] args) {// 3.创建Callable接口实现类的对象NumThread numThread = new NumThread();// 4.将此Callable接口实现类的对象作为传递到FutureTask构造器中,创建FutureTask的对象FutureTask<Integer> futureTask = new FutureTask<Integer>(numThread);// 5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()new Thread(futureTask).start();try {// 6.获取Callable中call方法的返回值// get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值。Integer sum = futureTask.get();System.out.println("总和为:" + sum);} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}}}
方式4:使用线程池
1、创建线程池的四种方法
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程 就会大大降低 系统的效率,因为频繁创建线程和销毁线程需要时间. 线程池就是一个容纳多个线程的容 器,池中的线程可以反复使用,省去了频繁创建线程对象的操作,节省了大量的时间和资源。
使用线程池的好处:降低资源消耗,提高响应速度,提高线程的可管理性。
Java通过Executors提供四种线程池,分别为:
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
2、创建步骤
1、提供指定线程数量的线程池;
2、设置线程池的属性;
3、执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象;
4、关闭连接池。
3、【示例代码】
class NumberThread1 implements Runnable {@Overridepublic void run() {for (int i = 0; i <= 100; i++) {if (i % 2 == 0) {System.out.println(Thread.currentThread().getName() + ": " + i);}}}}class NumberThread2 implements Runnable {@Overridepublic void run() {for (int i = 0; i <= 100; i++) {if (i % 2 != 0) {System.out.println(Thread.currentThread().getName() + ": " + i);}}}}public class ThreadPoolTest {public static void main(String[] args) {//1.提供指定线程数量的线程池ExecutorService service = Executors.newFixedThreadPool(10);ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;//设置线程池的属性// System.out.println(service.getClass());// service1.setCorePoolSize(15);// service1.setKeepAliveTime();//2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象service.execute(new NumberThread1());service.execute(new NumberThread2());//3.关闭连接池service.shutdown();
3、线程池的作用
线程池是一种基于池化思想管理线程的工具
- 降低资源消耗,提高线程利用率,降低创建和销毁线程的消耗
- 提高响应速度,任务来了,直接有线程可用可执行,而不是先创建线程,在执行
提高线程的可管理性,线程是稀缺资源,使用线程池可统一分配调度监控。
线程池解决的问题
线程池解决的核心问题就是资源管理问题,在并发环境下,系统不能确定在任意时刻中,有多少任务需要执行,就有多少资源投入。为解决资源分配问题,线程池采用了“池化思想”,是为了最大化收益,最小风险,而将资源统一在一起管理的一种思想。常见的有:
内存池:预先申请内存,提升申请内存速度,减少内存碎片。
- 连接池:预先申请数据库连接,提升申请连接的速度,降低系统的开销
- 实例池:循环使用对象,减少资源在初始化和释放时的昂贵损坏。
4、线程池参数解释
```java public ThreadPoolExecutor(int corePoolSize,
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {
}Executors.defaultThreadFactory(), defaultHandler);
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue
- **corePoolSize** - 核心线程数,正常情况下创建工作的线程数,这些线程创建后并不会消除,而是一种常驻线程- **maximumPoolSize** - 最大线程数,与核心线程数对应,表示最大允许被创建的线程数,当任务很多,核心线程数不够用,队列已满,此时就会创建新的线程。为什么是先添加队列,在创建最大线程?<br />在创建线程的时候是需要获取全局锁的,这个时候其他就是阻塞,影响整体效率- **keepAliveTime** - 表示超出核心线程数之外的线程的空闲存活时间,核心线程不会消除,但是超出核心线程数的部分线程如果空闲一定时间则会被消除。- **workQueue** - 用来存放待执行任务的队列,默认为BlockingQueue(阻塞队列)。为什么使用阻塞队列:<br />一般队列只是一个长度有限的缓冲区,若超出长度,就无法保留当前任务,阻塞队列通过阻塞可保留当前想要继续入队的任务<br />阻塞队列可以保证队列中没有任务的时候,阻塞获取任务的线程进入wait状态,释放cpu资源。<br />阻塞队列自带阻塞和唤醒功能,不需要额外处理,无任务时,线程池利用阻塞队列的take方法挂起,从而维持核心线程存 货,不至于一直占用cpu资源- **ThreadFactory** - 线程工厂,用来生产线程,我们可以选择默认工厂,产生的线程都在同一个组内,拥有相同优先级,且都不是守护线程。- **RejectedExecutionHandler **- 任务拒绝策略,第一种:当我们调用shutdown等方法关闭线程池后,这时候再向线程池提交任务就会遭到拒绝;另一种情况,当达到最大线程数,线程池已经没有能力继续处理新提交的任务时,也拒绝。<a name="aFzLi"></a>### 拒绝策略| 拒绝策略 | 说明 || --- | --- || AbortPolicy | 默认策略,不执行此任务,直接抛出异常 || DiscardOldestPolicy | 丢弃队列最前面的任务,然后重新执行此任务 || DiscardPolicy | 丢弃任务但不抛出异常 || CallerRunsPolicy | 由调度线程处理该任务 || 自定义策略 | 自定义策略 |<a name="RoxJn"></a>## 5、线程池流程处理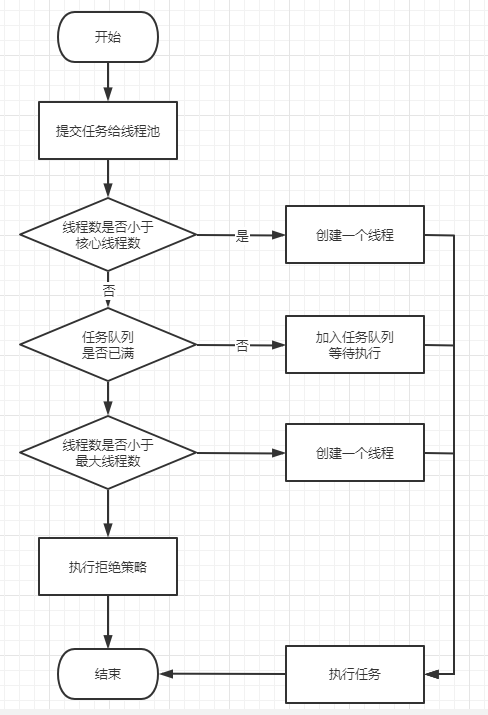- 将任务提交给线程池- 如果线程池中线程数小于核心线程数,则创建一个新的线程来执行该任务- 提交任务时,线程池中的空闲的线程数为0并且线程数等于核心线程数,则观察线程池中的任务队列是否已满,如果未满则将任务添加到任务队列- 如果最大线程数大于核心线程数,并且总线程数小于最大线程数,则创建一个新的线程来执行该任务。- 当任务队列已满时,就执行拒绝策略<a name="dMM6N"></a>## 6、线程池的核心设计与实现<a name="KyFu0"></a>### 设计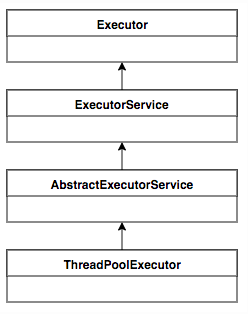<br />线程池的核心实现类是ThreadPoolExecutor,顶层接口是Executor, 顶层接口的设计思想是:**将任务提交和任务执行进行解耦**,用户无需关注如何创建线程,如何调度线程来执行任务。```javapublic interface Executor {void execute(Runnable command);}
ExecutorService接口增加了一些能力:
- 扩充执行任务的能力,补充可以为一个或一批任务生成Future方法
提供了管理线程池的方法,比如停止线程池的运行
public interface ExecutorService extends Executor {void shutdown();List<Runnable> shutdownNow();boolean isShutdown();boolean isTerminated();boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;<T> Future<T> submit(Callable<T> task);<T> Future<T> submit(Runnable task, T result);Future<?> submit(Runnable task);<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)throws InterruptedException;}
AbstractExecutorService则是上层的抽象类,将执行任务的流程串联起来,保证下层的实现只需关注一个执行任务的方法即可,最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。

生命周期管理
线程池内部使用一个变量维护两个值:运行状态runState和线程数量workerCount
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ThreadPoolExecutor的运行有5种状态
| 运行状态 | 状态描述 |
|---|---|
| RUNNING | 能接受新提交的任务,并且也能处理阻塞队列中的任务 |
| SHUTDOWN | 关闭状态,不再接受新提交的任务,却可以继续处理阻塞队列中已保存的任务 |
| STOP | 不能接受任务,也不处理队列中的任务,会中断正在处理任务的线程 |
| TIDYING | 所有的任务都已终止了,workerCount(有效线程数)为0 |
| TERMINATED | 在terminated()方法执行完成后进入该状态 |

Worker
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{final Thread thread;//Worker持有的线程Runnable firstTask;//初始化的任务,可以为null}

线程池中线程复用的原理
线程池将线程和任务进行解耦,线程是线程,任务是任务,通过Worker实现,摆脱了之前通过thread创建线程时的一个线程必须对应一个任务的限制
在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对 Thread 进行了封装,并不是每次执行任务都会调用 Thread.start() 来创建新线程,而是让每个线程去 执行一个“循环任务”,在这个“循环任务”中不停检查是否有任务需要被执行,如果有则直接执行,也就 是调用任务中的 run 方法,将 run 方法当成一个普通的方法执行,通过这种方式只使用固定的线程就 将所有任务的 run 方法串联起来。

若有收获,就点个赞吧
0 人点赞
