elk 是什么 ?
Elastic Stack(旧称ELK Stack),是一种能够从任意数据源抽取数据,并实时对数据进行搜索、分析和可视化展现的数据分析框架。(hadoop同一个开发人员)
- java 开发的开源的全文搜索引擎工具
- 基于lucence搜索引擎的
- 采用 restful - api 标准的
- 高可用、高扩展的分布式框架
实时数据分析的
为什么要用elk?
服务器众多,组件众多,日志众多,发现问题困难,技能要求高
业务场景:《实时日志分析展现》
日志主要包括系统日志、应用程序日志和安全日志。
系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。
当务之急我们使用集中化的日志管理,例如:开源的 syslog ,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用 grep 、 awk和 wc 等 Linux 命令能实现检索和统计,
但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
开源实时日志分析 ELK 平台能够完美的解决我们上述的问题, ELK 由 ElasticSearch 、 Logstash 和 Kiabana 三个开源工具组成。
体系架构**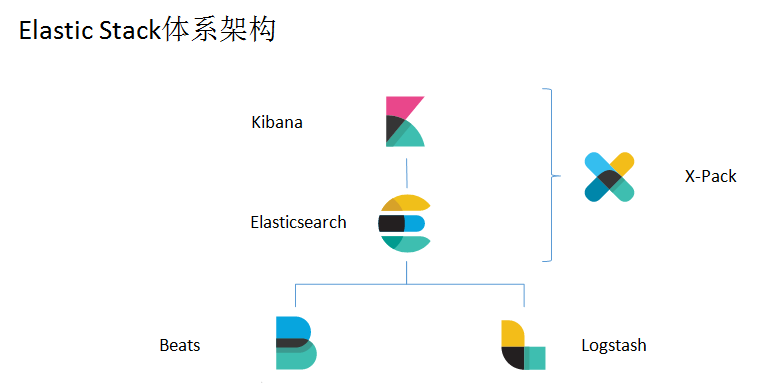

工作原理如下如所示:
在需要收集日志的所有服务上部署 logstash ,其中 logstash agent ( logstash shipper )用于监控并过滤收集日志,将过滤后的内容发送到 logstash indexer , logstash indexer 将日志收集在一起交给全文搜索服务 ElasticSearch ,
可以用 ElasticSearch 进行自定义搜索
通过 Kibana 来结合自定义搜索进行页面展示。
elk的技术架构
gateway:hdfs、Amazon S3、Local FileSystem、Shared FileSystem<br /> Index module、Search module、 Mapping、River(引入异构数据的插件机制:RabbitMQ-River、Twitter-River)<br /> zen和ec2---zk、scripting(mvel、python、js等)<br /> 第三方插件(Head、)<br /> Transport(Thrift、Memcached、Http)<br /> Java(Netty)<br /> restful 和 curl
elk的基本概念
node 和 cluster
index(数据库)->type(表)->document(行)->field (字段)
shards 分片
replicas 复制

若有收获,就点个赞吧
0 人点赞
