逻辑结构
Elasticsearch 的逻辑结构分为索引、类型和文档。
文档(Document)
Elasticsearch 是面向文档的,通常使用 JSON 表示数据。
文档的地位有些类似于关系型数据库的行(Row),但是有很大不同:
- 文档的结构是独立的,每个文档都包含字段名和与其对应的值
- 文档是有层级的,字段的值依旧可以是一个文档
- 文档是弹性的,每个文档的字段不需要完全相同(但是相同字段的类型必须相同)
类型(Type)
类型是文档的容器,对应着关系型数据库中的表(Table)。
每个类型都会有一个映射(Mapping),用于记录文档字段的类型和配置信息。
在默认情况下,Elasticsearch 会自动推断插入文档的字段类型,例如通过7得出类型为long。但是这样会有局限性,例如无法将40,116识别为一个地理坐标点,所以最好在插入文档前显式的建立映射。索引(Index)
索引是类型的容器,也是一个独立的文档集合,类似于数据库(Database)。每个索引都会存放在磁盘的一组文件中,包含它所有的类型映射和一些配置,例如分片数量、刷新间隔时间等。 

上图中的 Elasticsearch 实例包含了两个索引:get-together 和 get-together-blog,前者含有两个类型:event 和 group,后者只有一个类型 posts,这些类型中又包含着一些文档。物理结构
Elasticsearch 的物理结构分为节点和分片。分片(Shard)
分片是 Elasticsearch 中的最小单元,它实际就是 Lucene 中的索引:一个包含倒排索引文件的文件夹。
上图就是一个分片,这个倒排索引文件包含着文档的元数据,例如词元字典、词频等信息。词元字典包含了每个词元都出现在哪些文档中,这样在搜索时就可以直接找到对应的文档,而不用全部遍历一遍。词频记录了每个文档出现了多少次该词元,可以用于计算相关度。
分片包含主分片和复制分片,复制分片就是主分片的复制品。它可以用于处理搜索请求,或是在主分片发生故障时自动晋升为新的主分片。
一个索引可以有一到多个主分片,每个主分片可以有零到多个复制分片。复制分片的数量可以随时修改,但是主分片的数量必须在创建索引时确定,并且不能修改。
分片对应用程序是透明的,应用程序不需要了解分片到底是如何运作的。它只需要连接集群中的任意一个节点并发送请求即可。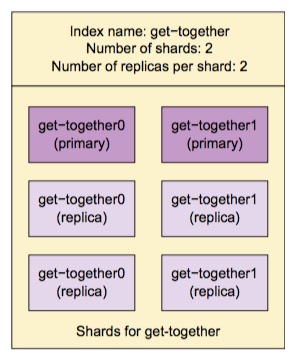
上图中的索引有 2 个主分片,每个主分片有 2 个复制分片,所以一共是 6 个分片。节点(Node)
每个 Elasticsearch 实例都是一个节点,多个节点可以加入同一个集群,这样集群中的数据就会平均分散在多台机器中,从而提高性能和可用性。如果每个主分片都有至少一个复制分片,即使主分片所在的节点出现故障,集群依旧可以正常提供服务。
一个节点上存在相同的多个分片(无论是主分片还是复制分片)是没有任何意义的,所以集群在节点数量不够时,不会分配出全部分片。
很重要的一点:必须要保证集群中节点间的通信速度足够快,否则会出现脑裂(split brain)现象,也就是集群中的两部分无法相互通信,并都认为对方已经退出了集群。
最简单的 Elasticsearch 集群只有一个节点:一台机器运行一个 Elasticsearch 实例。
提升集群处理能力的方法有两种:通过增加节点的方式称为水平扩展(horizontal scaling),通过增加机器硬件配置的方式称为垂直拓展(vertical scaling)。在大部分情况下水平拓展的性价比都要好过垂直拓展。
如上图,默认情况下 Elasticsearch 会对每个索引创建 5 个主分片,而每个主分片又会有 1 个复制分片,这些分片将会平均散布在集群的各个节点中。索引和搜索文档
索引
当索引一个文档时,Elasticsearch 会通过固定的 Hash 算法将它发送到指定的主分片。默认的 Hash 算法很简单,只是将文档 id 的 hash 值对主分片的个数取模,这也是主分片数量无法改变的原因:一旦分片的数量改变的,Hash 的结果也会改变,之前的文档就找不到了。
之后文档会被该主分片的所有复制分片索引,保证复制分片和主分片是同步的,所以复制分片可以处理搜索请求,或是在主分片故障时自动提升为主分片。
创建文档的方式:PUT 请求索引名 / 类型名 / 文档 id,内容为 JSON 格式的文档,例如:
返回结果中curl -XPUT 'http://localhost:9200/get-together/group/1?pretty' -d '{"name": "Elasticsearch Denver","organizer": "Lee"}'{"_index" : "get-together","_type" : "group","_id" : "1","_version" : 1,"created" : true}
created表示创建的结果,_id为文档的主键,这个请求指定了主键,也可以选择由 Elasticsearch 自动生成主键。_version为文档的版本号,从1开始,文档每次更新都会自增。
在索引文档时会自动创建不存在的索引和类型。也可以通过 PUT 请求索引名手动创建,例如:
手动创建索引的好处是可以自定义一些配置,例如指定分片数量。curl -XPUT 'http://localhost:9200/new-index?pretty' { "acknowledged" : true }
在索引文档时,如果字段的映射不存在,Elasticsearch 会自动推断出映射并创建,可以通过 GET 请求索引名 /_mapping/ 类型名查看:
返回结果中的curl 'http://localhost:9200/get-together/_mapping/group?pretty' { "get-together" : { "mappings" : { "group" : { "properties" : { "name" : { "type" : "string" }, "organizer" : { "type" : "string" } } } } } }properties为字段的映射信息,包含字段名、字段类型和配置。获取
直接通过 GET 请求索引名 / 类型名 / 文档 id就可以获取具体某个文档,例如获取刚才插入的文档:
返回内容包含了文档所在的索引、类型以及文档的主键、版本和数据。如果 id 不存在,返回的curl 'http://localhost:9200/get-together/group/1?pretty' { "_index" : "get-together", "_type" : "group", "_id" : "1", "_version" : 1, "found" : true, "_source": { "name": "Elasticsearch Denver", "organizer": "Lee" } }found字段将为false。
通过 id 获取文档的速度非常快,并且是实时的。而搜索是接近实时的,因为搜索需要等待刷新索引。搜索
当搜索文档时,Elasticsearch 首先会找到所有包含数据的分片,然后通过轮训调度算法对分片进行负载均衡。
轮训调度算法的前提是所有节点的处理速度都同样快,否则会出现处理速度慢的节点成为整个集群的性能瓶颈,这时候需要自己决定负载均衡方式。
搜索可以通过 GET 请求索引名 / 类型名 /_search,使用参数q指定关键词,例如:
在指定类型中搜索:
在指定索引的多个类型中搜索:curl 'http://localhost:9200/get-together/group/_search?q=elasticsearch&pretty'
在指定索引的全部类型中搜索:curl 'http://localhost:9200/get-together/group,event/_search?q=elasticsearch&pretty'
在多个索引中搜索:curl 'http://localhost:9200/get-together/_search?q=elasticsearch&pretty'
在全部索引中搜索:curl 'http://localhost:9200/get-together,other-index/_search?q=elasticsearch&pretty'
在全部索引的指定类型中搜索:curl 'http://localhost:9200/_all/_search?q=elasticsearch&pretty'
为了便于搜索,应该根据应用场景分配索引和类型,例如一般日志数据都会基于时间分配索引。curl 'http://localhost:9200/_all/group/_search?q=elasticsearch&pretty'
搜索的返回结果结构如下:{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 0.15342641, "hits" : [ { "_index" : "get-together", "_type" : "group", "_id" : "1", "_score" : 0.15342641, "_source": { "name": "Elasticsearch Denver", "organizer": "Lee" } } ] } }took记录了该次请求花费的时间,单位为毫秒。timed_out记录了该次请求是否超时,默认情况下没有超时时间,可以通过timeout参数指定,例如timeout=3s。_shards记录了搜索的分片信息,包含总共查询了多少个分片、成功的数量和失败的数量。如果一个主分片和它所有复制分片所在的节点都发生了故障,这部分的数据的查询就失败了。hits包含了搜索结果的总数、最高的相关度分数和搜索结果列表。列表中包含了每个文档的索引、类型、主键、分数和数据。默认情况下 Elasticsearch 只会返回前 10 条数据,可以通过size参数指定返回数量,同时还可以使用fields参数指定返回哪些字段,例如size=100&fields=name,age。
使用 URL 参数无法满足表达复杂的搜索,所以 Elasticsearch 还提供了通过 JSON 构造 DSL 搜索语句的方式。
使用 JSON 方式的搜索请求:
这种方式提供了更多的选项,例如上面的例子可以通过curl 'http://localhost:9200/get-together/group/_search?pretty' -d ' { "query": { "query_string": { "query": "elasticsearch" } } } 'default_field指定搜索的字段,或是通过"default_operator": "AND"要求文档必须包含所有词元(默认是OR:只需要包含任意词元):curl 'http://localhost:9200/get-together/group/_search?pretty' -d ' { "query": { "query_string": { "query": "elasticsearch san francisco", "default_field" :"name", "default_operator": "AND" } } } '过滤
过滤和搜索最大的区别是,搜索会计算每个结果的相关度,而过滤不会,所以过滤的速度要更快,而且可以被缓存。
一个过滤请求:
这个请求的结果会跟上面的搜索相同,只是所有文档的分数都会是 1.0。curl 'http://localhost:9200/get-together/group/_search?pretty' -d ' { "query": { "filtered": { "filter": { "term": { "name": "elasticsearch" } } } } } '聚合
聚合可以配合搜索和过滤得到一些统计数据,有些类似于 SQL 中的group by。
一个聚合请求:
这个请求会对搜索结果的curl 'http://localhost:9200/get-together/group/_search?pretty' -d ' { "query": { "query_string": { "query": "elasticsearch" } }, "aggregations" : { "organizers" : { "terms" : { "field" : "organizer" } } } } 'organizer字段进行聚合,额外返回这部分数据:
它表示有 2 个文档的 organizers 是"aggregations" : { "organizers" : { "buckets" : [ { "key" : "lee", "doc_count" : 2 }, { "key" : "andy", "doc_count" : 1 }] } }lee,1 个文档的 organizer 是andy。
一个很好的应用场景就是为搜索结果动态的提供筛选条件,它可以保证每个筛选条件都是有结果的,就像淘宝和京东的商品条件筛选。修改配置
Elasticsearch 的配置文件主要有三个:
- elasticsearch.yml:主配置文件
- logging.yml:日志的配置文件
elasticsearch.in.sh:JAVA 虚拟机(JVM)相关的配置
elasticsearch.yml
elasticsearch.yml 存放着最主要的配置,例如集群名、监听端口、文件存储路径等。每次修改后重启生效。
有一点需要注意:修改集群名后,之前创建的索引都会消失,因为存储数据的文件夹绑定着集群名。logging.yml
Elasticsearch 使用 Log4j 记录日志,日志文件主要有以下三种:
主日志(集群名.log):记录 Elasticsearch 运行状态的日志文件,例如新节点加入集群、搜索操作失败等
- 慢搜索日志(集群名_index_search_slowlog.log):记录搜索过慢的日志,默认时间为半秒
慢索引日志(集群名_index_indexing_slowlog.log):记录索引过慢的日志,默认时间为半秒
在大部分情况下,这种日志配置已经足够使用了。
elasticsearch.in.sh
作为一个 Java 应用,Elasticsearch 运行于 Java 虚拟机之上,所以许多配置与 JVM 配置息息相关。
最常用的配置就是修改内存,Elasticsearch 主要消耗堆内存,默认配置为初始化分配 256mb,最大分配 1gb。如果超过了 1gb 操作就会失败,并且日志中会记录内存溢出(OutOfMemory)异常。
通过修改环境变量ES_HEAP_SIZE可以设置堆内存大小,例如:export ES_HEAP_SIZE=500m另一种方式是修改 elasticsearch.in.sh,在文件的最前面添加
ES_HEAD_SIZE = 500m。
在生产环境中,如果一台机器只用于运行 Elasticsearch,建议分配该机器物理内存的一半给 Elasticsearch,剩下一半用于操作系统的缓存,它可以使 Elasticsearch 更快的访问本地文件。集群状态
通过访问
_cat/health?v可以查看集群健康,一般会返回如下数据(cat 下的命令多为运维使用,所以不会返回 JSON 格式,默认添加参数v可以显示每一列的名称):epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks 1462513392 13:43:12 elasticsearch red 1 1 142 142 0 0 154 0集群的健康度分为三种状态:
red:危险,集群中有主分片未分配,搜索时会有数据丢失
- yellow:警告,集群中所有主分片都已经分配了,但是有复制分片没有分配
green:安全,所有主分片和复制分片都已经分配了
通过_cat/shards?v可以查看集群分片的状态,包括具体是哪些分片没有分配出去。由于之前提到一个节点存在多个相同的分片是没有任何意义的,所以改变这些分片状态的唯一方法就是通过添加节点。
通过启动新的 Elasticsearch 实例创建一个新节点,如果该节点能发现集群的组播地址,并且集群的名称与它配置文件所定义的集群名称相同,它就会加入该集群。
集群中的第一个节点是集群的主节点,它负责维护集群的状态,包括集群中都有哪些节点,每个节点都有哪些分片。集群状态会复制给每个节点,这样当主节点故障后,另一个节点能提升为主节点并继续工作。
总结
Elasticsearch 是基于文档的,可伸缩的、模式自由的
- 尽管通过默认配置就可以建立一个集群,但是也应该修改一些配置,例如集群名和 JVM 堆大小。
- 索引请求会将文档通过 Hash 算法分配到某个主分片,接着同步到该分片的所有复制分片。
- 搜索请求会通过轮训调度算法分配到数据分片上(无论是主分片还是复制分片),接着聚合多个分片的结果最终返回给应用程序
- 应用程序通过 REST API 索引、搜索文档和修改配置,它不需要知道集群、节点和分片的含义

若有收获,就点个赞吧
0 人点赞
