- 剑指 Offer 07. 重建二叉树">剑指 Offer 07. 重建二叉树
- 剑指 Offer 08. 二叉树的下一个节点">剑指 Offer 08. 二叉树的下一个节点
- 剑指 Offer 26. 树的子结构">剑指 Offer 26. 树的子结构
- 剑指 Offer 27. 二叉树的镜像">剑指 Offer 27. 二叉树的镜像
- 剑指 Offer 28. 对称的二叉树">剑指 Offer 28. 对称的二叉树
- 剑指 Offer 32 - I. 从上到下打印二叉树">剑指 Offer 32 - I. 从上到下打印二叉树
- 剑指 Offer 32 - II. 从上到下打印二叉树 II">剑指 Offer 32 - II. 从上到下打印二叉树 II
- 剑指 Offer 32 - III. 从上到下打印二叉树 III">剑指 Offer 32 - III. 从上到下打印二叉树 III
- 剑指 Offer 33. 二叉搜索树的后序遍历序列">剑指 Offer 33. 二叉搜索树的后序遍历序列
- 剑指 Offer 34. 二叉树中和为某一值的路径">剑指 Offer 34. 二叉树中和为某一值的路径
- 剑指 Offer 36. 二叉搜索树与双向链表">剑指 Offer 36. 二叉搜索树与双向链表
- 剑指 Offer 37. 序列化二叉树">剑指 Offer 37. 序列化二叉树
- 剑指 Offer 54. 二叉搜索树的第k大节点">剑指 Offer 54. 二叉搜索树的第k大节点
- 剑指 Offer 55 - I. 二叉树的深度">剑指 Offer 55 - I. 二叉树的深度
- 剑指 Offer 55 - II. 平衡二叉树">剑指 Offer 55 - II. 平衡二叉树
- 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先">剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
- 剑指 Offer 68 - II. 二叉树的最近公共祖先">剑指 Offer 68 - II. 二叉树的最近公共祖先
剑指 Offer 07. 重建二叉树
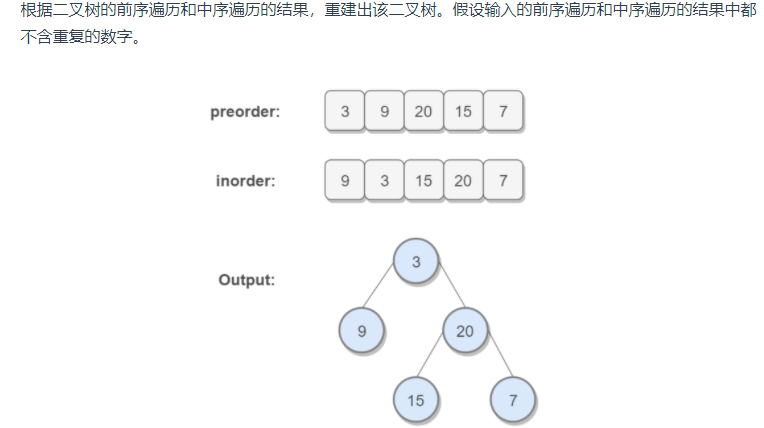
题解思路1:递归
对于任意一颗树而言,前序遍历的形式是:根—左—右。中序遍历的形式是:左—根—右
只要我们在中序遍历中定位到根节点, 就可以分别知道左子树和右子树中的节点数目,获取左子树的前序遍历和中序遍历,然后递归地构造出左子树和右子树。
细节 在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。可以考虑使用哈希表来快速地定位根节点。对于哈希映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。在构造二叉树的过程之前,可以对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射。
算法解析
- 递推参数:根节点在前序遍历的索引root、子树在中序遍历的左边界left、子树在中序遍历的右边界right
- 终止条件:当left>right,表示已经越过叶节点,此时返回null
递推工作:
- 建立根节点node:节点值为preorder 【root】
划分左右子树:查找根节点在中序遍历inorder中的索引 i 。
class Solution {Map<Integer, Integer> map = new HashMap<>();int[] preorder = null;public TreeNode buildTree(int[] preorder, int[] inorder) {this.preorder = preorder;for (int i = 0; i < inorder.length; i++) {map.put(inorder[i], i);}return recur(0, 0, inorder.length - 1);}TreeNode recur(int root, int left, int right) {if (left > right)return null;TreeNode node = new TreeNode(preorder[root]);int i = map.get(preorder[root]);node.left = recur(root + 1,left, i - 1);node.right = recur(root - left + i+1 , i + 1, right);//此处因为是索引计算说root处要多加1return node;}}
剑指 Offer 08. 二叉树的下一个节点
| 给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回 。注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。 |
|---|
public class TreeLinkNode {int val;TreeLinkNode left = null;TreeLinkNode right = null;TreeLinkNode next = null; // 指向父结点的指针TreeLinkNode(int val) {this.val = val;}}
题解思路:中序遍历的过程:先遍历树的左子树,再遍历根节点,最后在遍历右子树。所以最左节点是中序遍历的第一个节点
剑指 Offer 26. 树的子结构
| 输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)B是A的子结构, 即 A中有出现和B相同的结构和节点值。 例如: 给定的树 A: 3<br /> / \\<br /> 4 5<br /> / \\<br /> 1 2给定的树 B: 4 <br /> /<br /> 1返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。 |
|---|
题解思路:若树B是树A的子结构,则子结构的根节点可能为树A的任意一个节点。因此,判断树B是否是树A的子结构需要完成以下两步:
1、先序遍历树A中的每一个节点nA;(对应函数isSubStructure(A,B))
2、判断树A中以nA为根节点的子树是否包含树B。(对应函数recur(A,B))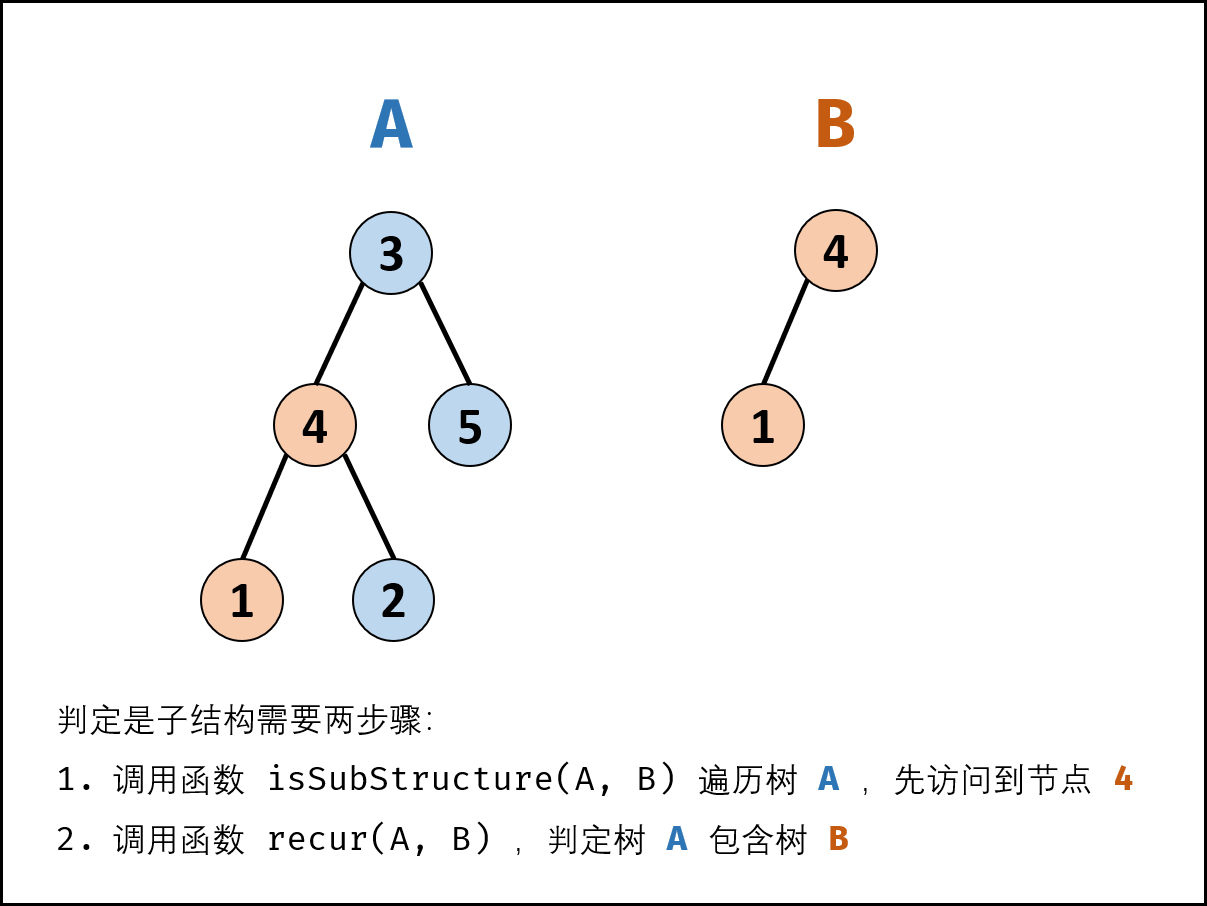
| 算法流程:> 名词规定:树A的根节点记作节点A,树B的根节点记作节点B。
recur(A,B)函数:
1、终止条件:
1、当节点B为空:说明树B已匹配完成(越过叶子节点),因此返回true
2、当节点A为空:说明已经越过树A叶子节点,即匹配失败,返回false;
3、当节点A和B的值不同,说明匹配失败,返回false;
2、返回值
1、判断A和B的左子节点是否相等,即recur(A.left,B.left);
2、判断A和B的右子节点是否相等,即recur(A.right,B.right);
isSubstructure(A,B)函数:
1、特例处理:当树A为空或者树B为空时,直接返回false;
2、返回值
1、以 节点 A为根节点的子树 包含树 B ,对应 recur(A, B);
2、树 B 是 树 A 左子树 的子结构,对应 isSubStructure(A.left, B);
3、树 B 是 树 A 右子树 的子结构,对应 isSubStructure(A.right, B); |
| —- |
public boolean isSubStructure(TreeNode A, TreeNode B) {return (A != null && B != null) && (recur(A, B) || isSubStructure(A.left, B) || isSubStructure(A.right, B));}//注意这里条件之间的括号public boolean recur(TreeNode A, TreeNode B) {if (B == null) return true; //遍历到B结束if (A == null || A.val != B.val) return false;return (recur(A.left,B.left)&&recur(A.right,B.right));}
剑指 Offer 27. 二叉树的镜像
| 请完成一个函数,输入一个二叉树,该函数输出它的镜像。 例如输入: 4<br /> / \\<br /> 2 7<br /> / \\ / \\<br />1 3 6 9镜像输出: 4<br /> / \\<br /> 7 2<br /> / \\ / \\<br />9 6 3 1示例 1: 输入:root = [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1] |
|---|
二叉树镜像定义:对于二叉树中任意节点root,设其左/右子节点分别为left,right,则二叉树的镜像中的对应root节点,其左/右子节点分别为right、left。
方法1:递归法
- 根据二叉树镜像的定义,考虑递归遍历(dfs)二叉树,交换每一个节点的左/右子节点,即可生成二叉树的镜像。
递归解析:
1、终止条件:当节点root为空时(即越过叶节点),则返回null
2、递推工作:
1、初始化节点tmp,用于暂存root的左子节点。
2、开启递归右子节点mirrorTree(root.right),并将返回值作为root的左子节点
3、开启递归左子节点mirrorTree(root.left),并将返回值作为root的右子节点
3、返回值:返回当前节点root
public TreeNode mirrorTree(TreeNode root) {
if (root == null) return null;
TreeNode tmp = root.left;
root.left = mirrorTree(root.right);
root.right = mirrorTree(tmp);
return root;
}
总结:整个过程的思想类似于不断的向下拆分。将左右两边的空指针走完了才返回
题解方法2:
public TreeNode mirrorTree(TreeNode root) {
if (root == null)
return null;
swap(root);
mirrorTree(root.left);
mirrorTree(root.right);
return root;
}
public void swap(TreeNode root) {
TreeNode tmp = root.left;
root.left = root.right;
root.right = tmp;
}
总结:每一个节点进行迭代交换
题解方法3:辅助栈(或队列)
- 利用栈(或队列)遍历树的所有节点node,并交换每个node 的左/右子节点
算法流程
1、特例处理: 当 root 为空时,直接返回 null ;
2、初始化: 栈(或队列),本文用栈,并加入根节点 root 。
3、循环交换: 当栈 stack 为空时跳出;
1、出栈: 记为 node ;
2、添加子节点: 将 node左和右子节点入栈;
3、交换: 交换 node的左 / 右子节点。
4、返回值: 返回根节点 root。
public TreeNode mirrorTree(TreeNode root) {
if (root == null) return null;
Stack<TreeNode> stack = new Stack<>();
stack.add(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
if (node.left != null) stack.add(node.left);
if (node.right != null) stack.add(node.right);
TreeNode tmp = node.left;
node.left = node.right;
node.right = tmp;
}
return root;
}
剑指 Offer 28. 对称的二叉树
| 请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。 例如,二叉树 [1,2,2,3,4,4,3] 是对称的。 1<br /> / \\<br /> 2 2<br /> / \\ / \\<br />3 4 4 3但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的: 1<br /> / \\<br /> 2 2<br /> \\ \\<br /> 3 3示例 1: 输入:root = [1,2,2,3,4,4,3] 输出:true |
|---|
public boolean isSymmetric(TreeNode root) {
if (root == null)
return true;
return isSymmetrical(root.left, root.right);
}
public boolean isSymmetrical(TreeNode t1, TreeNode t2) {
if (t1 == null && t2 == null) return true;
if (t1 == null || t2 == null) return false;
if (t1.val != t2.val) return false;
return isSymmetrical(t1.left, t2.right) && isSymmetrical(t1.right, t2.left);
}
总结:递归的做法,注意递归函数的出口条件!!!
通过队列实现,每次入队两个,取出两个。入队的顺序就按题目的要求就好了。
class Solution {
public boolean isSymmetric(TreeNode root) {
if (root == null)
return true;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
queue.add(root);
while (!queue.isEmpty()) {
TreeNode t1 = queue.poll();
TreeNode t2 = queue.poll();
if (t1 == null && t2 == null)
continue;
if ((t1 == null || t2 == null) || (t1.val != t2.val))
return false;
queue.offer(t1.left);
queue.offer(t2.right);
queue.offer(t1.right);
queue.offer(t2.left);
}
return true;
}
}
将root进队列两次
剑指 Offer 32 - I. 从上到下打印二叉树
| 从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。 例如: 给定二叉树: [3,9,20,null,null,15,7],3 / \ 9 20 / \ 15 7 返回: [3,9,20,15,7] |
|---|
题解思路:层序遍历(BFS:广度优先搜索)
使用队列来进行层序遍历,不需要使用两个队列分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
public int[] levelOrder(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
List<Integer> list = new ArrayList<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (node == null)
continue;
list.add(node.val);
queue.add(node.left);
queue.add(node.right);
}
}
int count = list.size();
int[] res = new int[count];
for (int i = 0; i < count; i++) {
res[i] = list.get(i);
}
return res;
}
总结 1、使用队列,保证先进先出。左边的元素先进队列,右元素后进入 2、每一次for循环内部的次数都是一层中元素的个数,保证层序遍历
剑指 Offer 32 - II. 从上到下打印二叉树 II
| 从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。 例如: 给定二叉树: [3,9,20,null,null,15,7],3 / \ 9 20 / \ 15 7 返回其层次遍历结果: [ [3], [9,20], [15,7] ] |
|---|
题解思路:仍然是层序遍历的思想,只是输出的格式不一样。
public List<List<Integer>> levelOrder(TreeNode root) {
if (root == null) return new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> lists = new ArrayList<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
List<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (node == null)
continue;
list.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
lists.add(list);
}
return lists;
}
剑指 Offer 32 - III. 从上到下打印二叉树 III
| 请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。 例如: 给定二叉树: [3,9,20,null,null,15,7],3 / \ 9 20 / \ 15 7 返回其层次遍历结果: [ [3], [20,9], [15,7] ] |
|---|
题解思路:翻转结果集
public List<List<Integer>> levelOrder(TreeNode root) {
if (root == null) return new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> lists = new ArrayList<>();
queue.add(root);
int count = 0;
while (!queue.isEmpty()) {
int size = queue.size();
List<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (node == null)
continue;
list.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
if (count % 2 != 0)
Collections.reverse(list);
lists.add(list);
count++;
}
return lists;
}
题解思路:双端队列
public List<List<Integer>> levelOrder(TreeNode root) {
if (root == null) return new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> lists = new ArrayList<>();
queue.add(root);
int count = 0;
boolean flag=true;
while(!queue.isEmpty()){
count=queue.size();
LinkedList<Integer> list=new LinkedList<>();
for(int i=0;i<count;i++){
TreeNode node=queue.poll();
if(flag) list.addLast(node.val);
else list.addFirst(node.val);
if(node.left!=null) queue.add(node.left);
if(node.right!=null) queue.add(node.right);
}
flag=!flag;
lists.add(list);
}
return lists;
}
剑指 Offer 33. 二叉搜索树的后序遍历序列
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。参考以下这颗二叉搜索树: 5 / \ 2 6 / \ 1 3 示例 1: 输入: [1,6,3,2,5] 输出: false |
|---|
题解思路:后序遍历的定义:[左子树 | 右子树 | 根节点]
- 二叉搜索树定义:左子树中所有节点的值<根节点的值;右子树中所有节点的值>根节点的值,其左、右子树也分别为二叉搜索树
方法1:递归分治
- 根据二叉搜索树的定义,可以通过递归,判断所有子树的正确性(即其后序遍历是否满足二叉搜索树的定义),若所有子树都正确,则此序列为二叉搜索树的后序遍历。
递归解析
- 终止条件:当i>=j,说明此子树节点数量<=1,无需判别正确性,因此直接返回true。
- 递推工作:
1、划分左右子树:遍历后序遍历的[ i,j ]区间元素,寻找第一个大于根节点的节点,索引记为m。此时,可划分出左子树区间[ i,m-1]、右子树区间[m,j-1]、根节点索引 j 。
2、判断是否为二叉搜索树:
- 左子树区间 [i, m - 1]内的所有节点都应 < postorder[j]。而第 1.划分左右子树 步骤已经保证左子树区间的正确性,因此只需要判断右子树区间即可。
- 右子树区间 [m, j-1]内的所有节点都应 >postorder[j]。实现方式为遍历,当遇到 ≤postorder[j] 的节点则跳出;则可通过 p = j判断是否为二叉搜索树。
- 返回值
- p = j : 判断 此树 是否正确。
- recur(i, m - 1): 判断 此树的左子树 是否正确。
- recur(m, j - 1): 判断 此树的右子树 是否正确。
| 在这里需要把握的一个关键点因素就是不管你怎么划分子树,最后一个元素都是根节点。 |
|---|
public boolean verifyPostorder(int[] postorder) {
return recur(postorder, 0, postorder.length - 1);
}
public boolean recur(int[] postorder, int i, int j) {
if (i >= j) return true;
int p = i;
while (postorder[p] < postorder[j]) p++;
int m = p;
while (postorder[p] > postorder[j]) p++;
return (p == j) && recur(postorder, i, m - 1) && recur(postorder, m, j - 1);
}
总结: 1、左右子树的划分,通过值来判断 2、主要判断三个部分: 1、当前树是否满足条件 2、当前树的左子树是否满足条件 3、当前树的右子树是否满足条件 3、关键在于怎么判断每个子树的满足条件呢? 就是找到右子树的起点后,遍历后面的所有元素,这些元素都要大于根节点就可以。
剑指 Offer 34. 二叉树中和为某一值的路径
| 输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。 示例: 给定如下二叉树,以及目标和 sum = 22,5 / \ 4 8 / / \ 11 13 4 / \ / \ 7 2 5 1 返回: [ [5,4,11,2], [5,8,4,5] ] |
|---|
题解思路:二叉树方案搜索问题,使用回溯法解决,其包含先序遍历+路径记录两部分。
- 先序遍历:按照“根,左,右”的顺序,遍历树的所有节点
路径记录:在先序遍历中,记录从根节点到当前节点的路径,当路径为根节点到叶节点形成的路径且各节点值的和为目标值时,将此路径加入到结果列表中
LinkedList<List<Integer>> res = new LinkedList<>(); LinkedList<Integer> path = new LinkedList<>(); public List<List<Integer>> pathSum(TreeNode root, int sum) { recur(root, sum); return res; } public void recur(TreeNode root, int tar) { if (root == null) return; path.add(root.val); tar -= root.val; if (tar == 0 && root.left == null && root.right == null) res.add(new LinkedList<>(path)); recur(root.left, tar); recur(root.right, tar); path.removeLast(); //走到这一步的时候说明上一步失败了,需要回退。 }总结: 1、递归调用每一个元素,目标值不断的减少。注意回退,其实每次都是走完叶子节点的左右null值才开始回退的。 2、注意每一条结果集生效的条件
res.add(new ArrayList<>(path))和res.add(path)的区别
| 共同点:都是向res这个ArrayList中添加了一个名为path的链表 不同点: res.add(new ArrayList(path)):开辟一个独立地址,地址中存放的内容为path链表,后续path的变化不会影响到resres.add(path):将res尾部指向了path地址,后续path内容的变化会导致res的变化。如果不开辟新的内存空间的话,引用里存的引用也会随着实例对象的改变而改变。 |
|---|
使用ArrayList实现
List<List<Integer>> res = new ArrayList<>();
List<Integer> list = new ArrayList<>();
public List<List<Integer>> pathSum(TreeNode root, int sum) {
recur(root, sum);
return res;
}
public void recur(TreeNode root, int tar) {
if (root == null)
return;
list.add(root.val);
tar -= root.val;
if (tar == 0 && root.left == null && root.right == null) {
res.add(new ArrayList<>(list));
}
recur(root.left, tar);
recur(root.right, tar);
list.remove(list.size() - 1);//删除最后一个元素
}
剑指 Offer 36. 二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。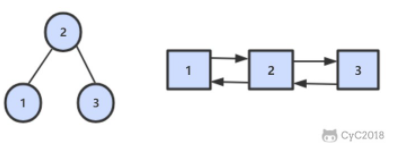 |
|---|
题解思路:二叉搜索树的中序遍历为递增序列。
将二叉搜索树转换成一个“排序的循环双向链表”,其中包含三个要素:
1、排序链表:节点应从小到大排序,因此应使用中序遍历“从小到大”访问树的节点;
2、双向链表:在构建相邻节点(设前驱节点pre,当前节点cur)关系时,不仅应pre.right=cur,也应该cur.left=pre
3、循环链表:设链表头节点head和尾节点tail,则应构建head.left=tail和tail.right=head。
中序遍历为“左,根,右”,递归实现代码如下
//打印中序遍历
void dfs(TreeNode root){
if(root==null) return;
dfs(root.left);//左
System.out.println(root.val);//根
dfs(root.right);//右
根据以上的分析,考虑使用中序遍历访问树的各节点cur,并在访问每个节点时构建cur和前驱节点pre的引用指向;中序遍历完成后,最后构建头节点和尾节点的引用指向即可。(上一节点的右指针为当前,当前指针的左指针为上一节点)
算法流程
dfs(cur):递归法中序遍历:
1、终止条件:当节点cur为空,代表越过叶节点,直接返回;
2、递归左子树,即dfs(cur.left);
3、构建链表:
1、当pre为空时:代表正在访问链表头节点,记为head。
2、当pre不为空时:修改双向节点引用,即pre.right=cur,cur.left=pre;
3、保存cur:更新pre=cur,即节点cur是后继节点的pre;
4、递归右子树,即dfs(cur.left);
treeToDoublyList(root):
1、特例处理:若节点root为空,则直接返回
2、初始化:空节点pre;
3、转化为双向链表:调用dfs(root);
4、构建循环链表:中序遍历完成后,head指向头节点,pre指向尾节点,因此修改head和pre的双向节点引用即可。
5、返回值:返回链表的头节head即可:
class Solution {
Node pre, head;
public Node treeToDoublyList(Node root) {
if (root == null) return null;
dfs(root);
head.left = pre;
pre.right = head;
return head;
}
public void dfs(Node cur) {
if (cur == null)
return;
dfs(cur.left);
if (pre != null)
pre.right = cur;
else
head = cur;
cur.left = pre;
pre = cur;
dfs(cur.right);
}
}
总结: 1、根据题意,大致的方向可以知道是通过中序遍历来实现 2、如何构建双向链表? 使用pre和cur两个节点指针,上一次遍历的即为pre,当前正在遍历的就是cur 3、如何判断到达头节点? 不断dfs(root.left)递归下去就可以到达头节点 4、如何判断尾节点? 当跳出递归函数dfs时,此时pre节点所指向的目标就是尾节点
剑指 Offer 37. 序列化二叉树
| 请实现两个函数,分别用来序列化和反序列化二叉树。 示例: 你可以将以下二叉树: 1 / \ 2 3 / \ 4 5 序列化为 "[1,2,3,null,null,4,5]" |
|---|
题解思路:观察题意可得,序列化的字符串实际上是二叉树的“层序遍历”(BFS)结果
算法流程
1、特例处理:若root为空,则直接返回空列表“[ ]”;
2、初始化:队列queue(包含根节点root);序列化列表res;
3、层序遍历:当queue为空时跳出:
1、节点出队,记为 node ;
2、若 node 不为空:① 打印字符串 node.val ,② 将左、右子节点加入 queue ;否则(若 node 为空):打印字符串 “null”
3、返回值: 拼接列表,用 ‘,’ 隔开,首尾添加中括号;
public class Codec {
public String serialize(TreeNode root) {
if(root == null) return "[]";
StringBuilder res = new StringBuilder("[");
Queue<TreeNode> queue = new LinkedList<>() {{ add(root); }};
while(!queue.isEmpty()) {
TreeNode node = queue.poll();
if(node != null) {
res.append(node.val + ",");
queue.add(node.left);
queue.add(node.right);
}
else res.append("null,");
}
res.deleteCharAt(res.length() - 1);
res.append("]");
return res.toString();
}
public TreeNode deserialize(String data) {
if(data.equals("[]")) return null;
String[] vals = data.substring(1, data.length() - 1).split(",");
TreeNode root = new TreeNode(Integer.parseInt(vals[0]));
Queue<TreeNode> queue = new LinkedList<>() {{ add(root); }};
int i = 1;
while(!queue.isEmpty()) {
TreeNode node = queue.poll();
if(!vals[i].equals("null")) {
node.left = new TreeNode(Integer.parseInt(vals[i]));
queue.add(node.left);
}
i++;
if(!vals[i].equals("null")) {
node.right = new TreeNode(Integer.parseInt(vals[i]));
queue.add(node.right);
}
i++;
}
return root;
}
}
总结: 1、使用ArrayList形式是无法通过编译的 2、序列化的过程就是层序遍历的过程 3、反序列的过程,通过队列的形式实现间隔获取左右节点
剑指 Offer 54. 二叉搜索树的第k大节点
| 给定一棵二叉搜索树,请找出其中第k大的节点。 示例 : 输入: root = [3,1,4,null,2], k = 1 3 / \ 1 4 \ 2 输出: 4 |
|---|
class Solution {
private TreeNode ret;
private int cnts;
public int kthLargest(TreeNode root, int k) {
dfs(root, k);
return ret.val;
}
public void dfs(TreeNode root, int k) {
if (root == null || cnts >= k)
return;
dfs(root.right, k );
cnts++;
if (cnts == k)
ret = root;
dfs(root.left, k);
}
}
总结: 通过中序遍历,不过是先遍历右节点再根最后左。在处理根的时候做文章
剑指 Offer 55 - I. 二叉树的深度
| 输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。 例如: 给定二叉树 [3,9,20,null,null,15,7],3 / \ 9 20 / \ 15 7 |
|---|
题解思路:不断的递归下去,直到为null
public int TreeDepth(TreeNode root){
return root==null?0:1+Math.max(TreeDepth(root.left),TreeDepth(root.right));
}
官方
树的遍历方式总体分为两种:深度优先搜索(DFS)、广度优先搜索(BFS);
- 常见的DFS:先序遍历、中序遍历、后序遍历
- 常见的BFS:层序遍历(即按层遍历)
方法一:后序遍历(DFS)
- 树的后序遍历/深度优先搜索往往利用递归或栈实现,本文使用递归实现
- 关键点:此树的深度和其左(右)子树的深度之间的关系。显然,此树的深度等于左子树的深度与右子树的深度中的最大值+1
算法流程
1、终止条件:当root为空,说明已越过叶节点,因此返回深度0;
2、递推工作:本质上是对树做后序遍历。
1、计算节点root的左子树的深度
2、计算节点root的右子树的深度
3、返回值:返回此树的深度,即max(maxDepth(root.left),maxdepth(root.right))+1;
方法二:层序遍历
每遍历一层就+1
public int maxDepth(TreeNode root) {
if (root == null)
return 0;
LinkedList<TreeNode> queue = new LinkedList<>();
int res = 0;
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
res++;
}
return res;
}
剑指 Offer 55 - II. 平衡二叉树
| 输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。 示例 1: 给定二叉树 [3,9,20,null,null,15,7]3 / \ 9 20 / \ 15 7 返回:true。 |
|---|
方法一:后序遍历+减枝
此方法为本题的最优解法,但剪枝的方法第一时间不易想到
思路是对二叉树做后序遍历,从底部至顶返回子树深度,若判定某子树不是平衡树则“剪枝”,直接向上返回
算法流程
recur(root)函数:
- 返回值:
1、当节点root左/右子树的深度差<=1;则返回当前子树的深度,即节点root的左/右子树的深度最大值+1;
2、当节点root 左 / 右子树的深度差 > 2 :则返回 -1 ,代表 此子树不是平衡树 。
- 终止条件:
1、当root为空:说明越多叶节点,因此返回高度0;
2、当左(右)子树深度为-1;代表此树的左(右)子树不是平衡树,因此减枝,直接返回-1.
返回值: 若
recur(root) != -1,则说明此树平衡,返回 truetrue ; 否则返回 falsefalse 。public boolean isBalanced(TreeNode root) { return recur(root) != -1; } private int recur(TreeNode root) { if (root == null) return 0; int left = recur(root.left); if (left == -1) return -1; int right = recur(root.right); if (right == -1) return -1; return Math.abs(right-left)>1?-1:Math.max(left,right)+1; }
方法二:先序遍历+判断深度(自顶到底)
思路:构造一个获取当前子树的深度的函数depth(root),通过比较某子树的左右子树的深度差abs(depth(root.left)-depth(root.right))<=1是否成立,来判断某子树是否是二叉平衡树
算法流程:
isBalanced(root) 函数: 判断树 root 是否平衡
- 特例处理: 若树根节点 root 为空,则直接返回 true ;
- 返回值: 所有子树都需要满足平衡树性质,因此以下三者使用与逻辑 \&\&&& 连接;
1、abs(self.depth(root.left) - self.depth(root.right)) <= 1 :判断当前子树是否是平衡树;
2、self.isBalanced(root.left) : 先序遍历递归,判断当前子树的左子树是否是平衡树;
3、self.isBalanced(root.right) : 先序遍历递归,判断 当前子树的右子树 是否是平衡树;
depth(root) 函数: 计算树 root 的深度
- 终止条件: 当 root 为空,即越过叶子节点,则返回高度 0 ;
返回值: 返回左 / 右子树的深度的最大值 +1。
public boolean isBalanced(TreeNode root) { if (root == null) return true; return Math.abs(depth(root.left) - depth(root.right)) <= 1 && isBalanced(root.left) && isBalanced(root.right); } private int depth(TreeNode root) { if (root == null) return 0; return Math.max(depth(root.left), depth(root.right)) + 1; }总结: 1、判断三种情况:当前子树、左子树、右子树
剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
| 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。” 例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5] 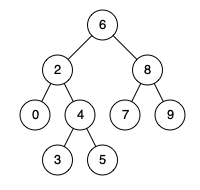 |
|---|
最近公共祖先的定义: 设节点 root为节点 p,q的某公共祖先,若其左子节点 root.left 和右子节点 root.right 都不是 p,q的公共祖先,则称 root 是 “最近的公共祖先” 。
根据以上定义,若 root 是 p,q的 最近公共祖先 ,则只可能为以下情况之一:
1、p 和 q 在 root 的子树中,且分列 root 的 异侧(即分别在左、右子树中);
2、p = root,且 q 在 root 的左或右子树中;
3、q = root,且 p 在 root的左或右子树中;
方法一:迭代
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (root != null) {
if (root.val > p.val && root.val > q.val)
root = root.left;
else if (root.val < p.val && root.val < q.val)
root = root.right;
else break;
}
return root;
}
方法二:递归
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root.val > p.val && root.val > q.val)
return lowestCommonAncestor(root.left, p, q);
if (root.val < p.val && root.val < q.val)
return lowestCommonAncestor(root.right, p, q);
return root;
}
剑指 Offer 68 - II. 二叉树的最近公共祖先
| 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。” 例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4] 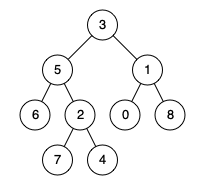 |
|---|
题解思路:根据题意可知:若root是p,q的最近公共祖先,则只有可能为以下情况之一:
1、p和q在root的子树中,且分列root的异侧(即分别在左、右子树中);
2、p=root,且q在root的左或右子树中
3、q=root,且p在root的左或右子树中
考虑通过递归对二叉树进行后序遍历,当遇到节点p或q时返回。从底至顶回溯,当节点p,q在节点root的异侧时,节点root即为最近的公共祖先,则向上返回root。
递归解析
1、终止条件:
1、当越过叶节点,则直接返回null
2、当root等于p、q,则直接返回root
2、递推工作
1、开启递归左子节点,返回值为left
2、开启递归右子节点,返回值为right
3、返回值: 根据 left 和 right ,可展开为四种情况;
1、当 left 和 right 同时为空 :说明 root 的左 / 右子树中都不包含 p,q,返回 null;
2、当 left 和 right 同时不为空 :说明 p, q 分列在 root 的异侧 (分别在 左 / 右子树),因此 root为最近公共祖先,返回 root;
3、当 left为空 ,right 不为空 :p,q 都不在 root 的左子树中,直接返回 right 。具体可分为两种情况:
p,q 其中一个在 root 的 右子树 中,此时 right 指向 p(假设为 p );
p,q 两节点都在 root的 右子树 中,此时的 right指向 最近公共祖先节点 ;
4、当 left 不为空 , right 为空 :与情况 3. 同理;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//只有找到目标节点或者是到达叶子节点才会跳出
if (root == null || root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if (left == null) return right;
if (right == null) return left;
return root;
}
总结: 1、只有找到目标节点或者是到达叶子节点才会跳出。

若有收获,就点个赞吧
0 人点赞
