JMM (Java memory model Java内存模型)
JMM 是一种抽象概念,属于一规范。通过这种方式定义了程序中各个变量(包括实例字段、静态字段和构成数组对象的元素)的访问方式。
JMM 同步规范:
线程加锁前,从主线程的主内存中复制出所需变量到本线程中的工作空间中,之后操作本线程内存数据。
线程解锁前,把修改的工作内存数据变量刷新到主线程主内存中。
所有线程加锁和解锁都是同一把锁。
JMM 特性:可见性、原子性和有序性。
项目中是否使用过volatile,场景是什么,为什么使用?
volatile 是java中一种轻量的同步机制。
有点类似订阅发布的意思,其保证了数据的可见性和有序性(禁止指令重排,编译为汇编指令,大学汇编学的太浅了),但是没有保证数据的原子性。
原子性解决方案:根据需求选择,我常用 atomic 保证原子性。
场景使用:双重检索单例模式和多线程处理Kafka数据。
双重检索单例模式:指令重排会导致分配对象内存、初始化对象和对象指向分配内存地址的指令出现引用对象尚未完成初始化完成(已经指向了分配内存地址,但是对象尚未初始化)导致可能多次实例化。
多线程使用的数据均加上volatile。

AtomicInteger为什么用CAS而不是synchronized?
CAS :compareAndSwap(比较并替换),是一条CPU原语指令。
源码: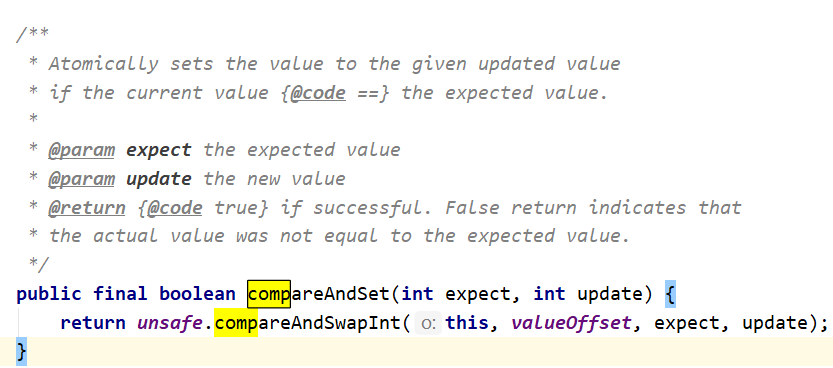
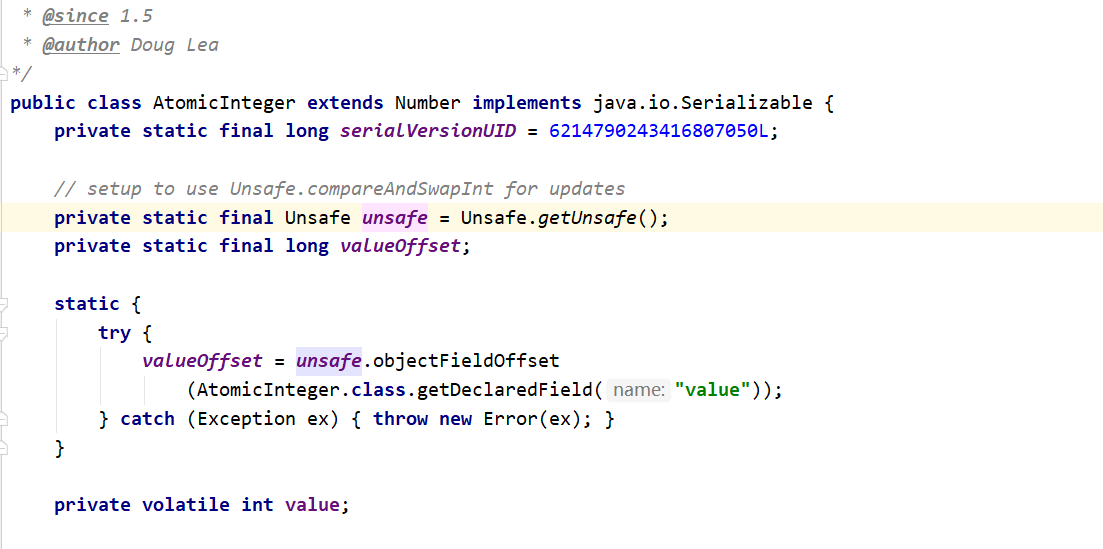
此处出现Unsafe类,其大多方法是本地方法,是保证原子操作的核心类。
而 AtomicInteger 的 getAndIncrement,调用的 Unsafe 的 getAndAddInt 方法。
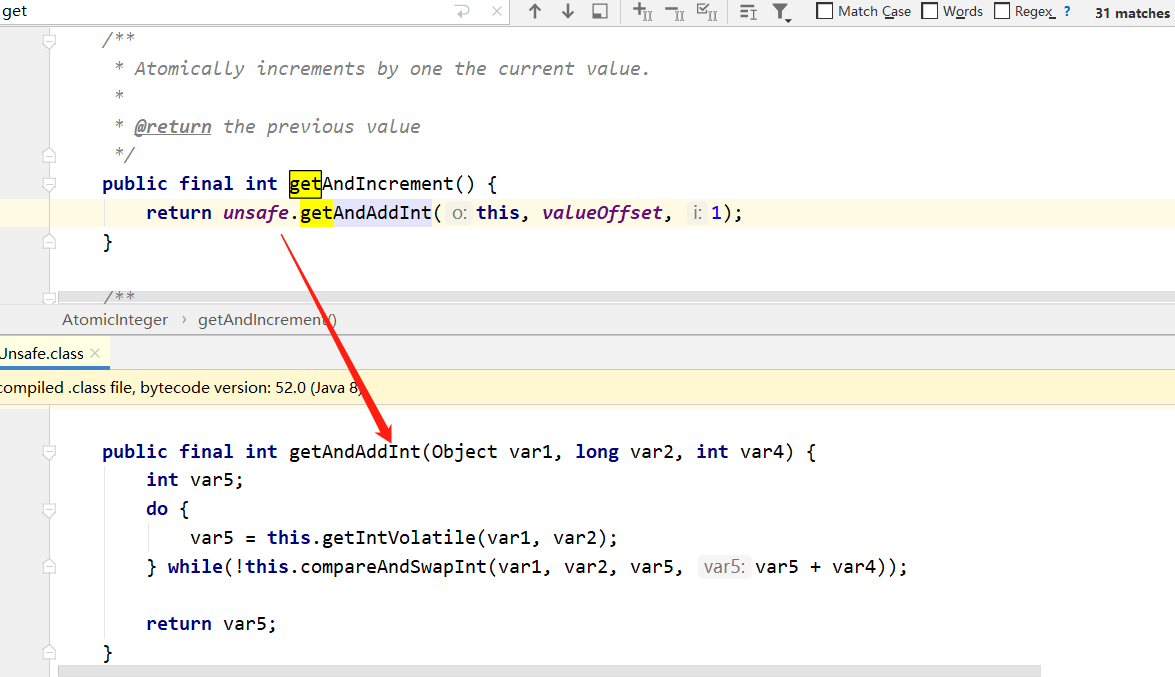
getAndAddInt () 通过自旋锁实现指定内存数据修改。
getAndAddInt 参数解析 var1 代表的是执行的类对象
var2 内存地址
var4 增加值
this.compareAndSwapInt 参数解析 var1 执行对象本身
var2 内存偏移量(内存地址)
var5 当前值
var4 更新值
getAndAddInt() 方法: 先获取指定对象的指定内存地址的值,执行CAS原语指令。执行原语指定时判断预期值和当前值是否一致,一致则更新、不一致则循环获取判断。
由此可知道,synchronized,在处理数据时只有一个线程可操作,降低了并发性。而CAS通过代码实现的自旋锁处理数据。保证了线程的并发性。
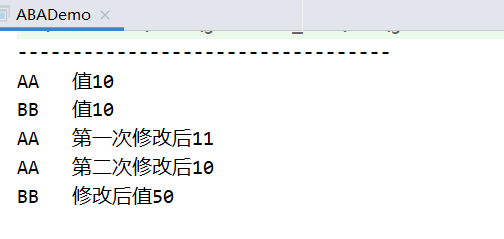
但是CAS同时也导致了一个ABA问题。即 线程1 获取 变量X 时值为A,但是因为是多线程,在执行 线程1要修改变量X前,另外一个线程2更新了 主内存 值为B,但是很快又将B值修改为了A值,线程1更新变量X时就会更新成功了。所以有可能导致最终程序执行出错。
CAS 也会导致 CPU 高速运行。
ABA问题解决思路
平常使用原子更新 AtomicReference,但是ABA问题会影响程序结果的情况下
使用原子更新引用 AtomicStampedReference(添加时间戳属性)。
ABA问题代码测试
import java.util.concurrent.atomic.AtomicInteger;import java.util.concurrent.atomic.AtomicReference;public class ABADemo {static AtomicReference<Integer> atomicReference = new AtomicReference<>(10);public static void main(String[] args) {new Thread(() -> {System.out.println(Thread.currentThread().getName() + "\t 值" + atomicReference.get());atomicReference.compareAndSet(10, 11);System.out.println(Thread.currentThread().getName() + "\t 第一次修改后" + atomicReference.get());atomicReference.compareAndSet(11, 10);System.out.println(Thread.currentThread().getName() + "\t 第二次修改后" + atomicReference.get());}, "AA").start();new Thread(() -> {System.out.println(Thread.currentThread().getName() + "\t 值" + atomicReference.get());try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}atomicReference.compareAndSet(10, 50);System.out.println(Thread.currentThread().getName() + "\t 修改后值" + atomicReference.get());}, "BB").start();System.out.println("----------------------------------");}}
ArrayList、HashMap、HashSet
都是线程不安全
ArrayList 初始值默认是10,每次增长为原数组的1.5倍
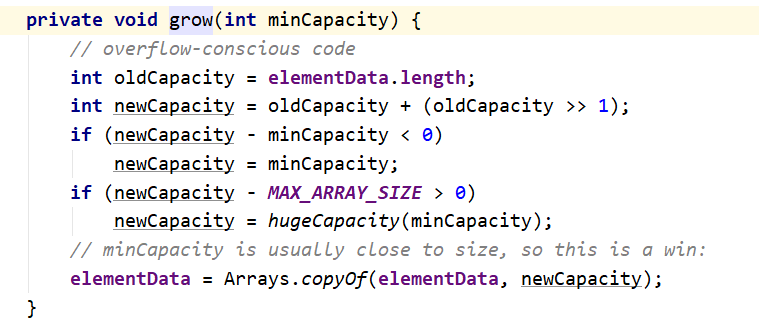
HashSet底层使用的HashMap。将值放到Map的key、value 为空对象
HashMap 初始值默认 16,最大值 2的30次方,每次增长0.75
HashMap 底层是数组加链表
那么使用的线程安全的集合?
ArrayList —-> CopyOnWriteArrayList (写实复制技术、读写分离思想参考数据库的读写分离)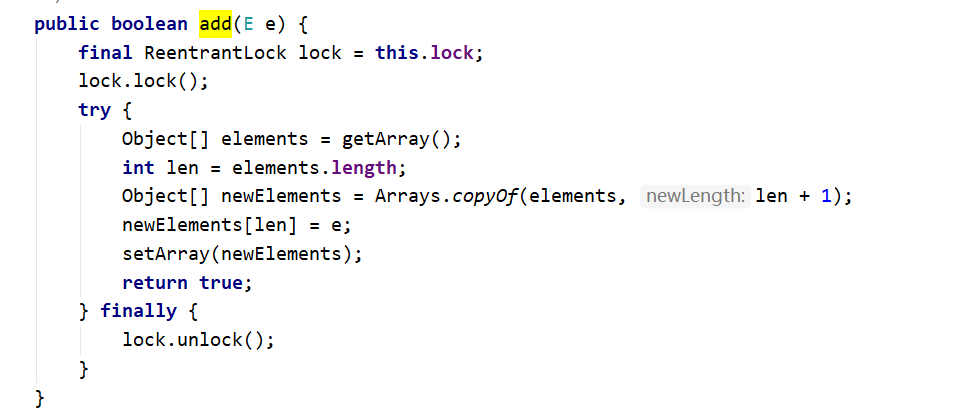
HashSet —-> CopyOnWriteArraySet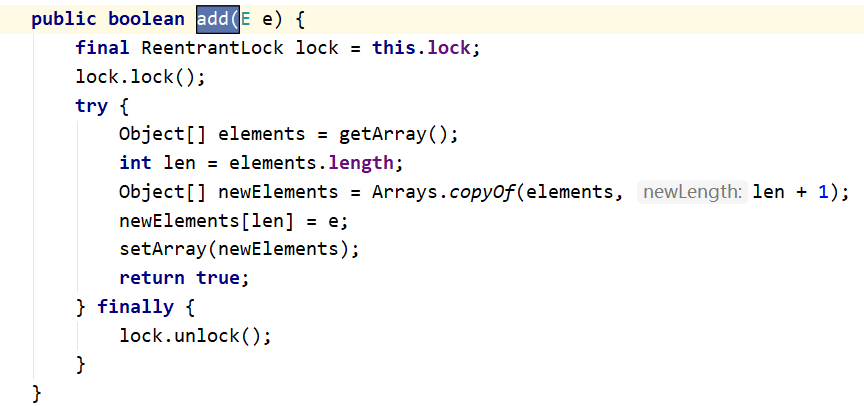
HashMap —-> ConcurrentHashMap 使用synchronized
公平锁、非公平锁、自旋锁、可重入锁(递归锁)、独占锁(写)/共享锁(读)
公平非公平:申请到锁顺序是否可变。
自旋锁: 循环获取锁。参考CAS
可重入锁(递归锁): 多个同步方法,若是相互调用,则在进入下一个同步方法时自动获取此方法需要的锁。
独享锁: synchronized 和 ReentrantLock,单独线程使用
读写锁: 写时单线程、读时多线程。参考ReentrantReadWriteLock
Synchronized与Lock的区别
| 类别 | synchronized | Lock |
|---|---|---|
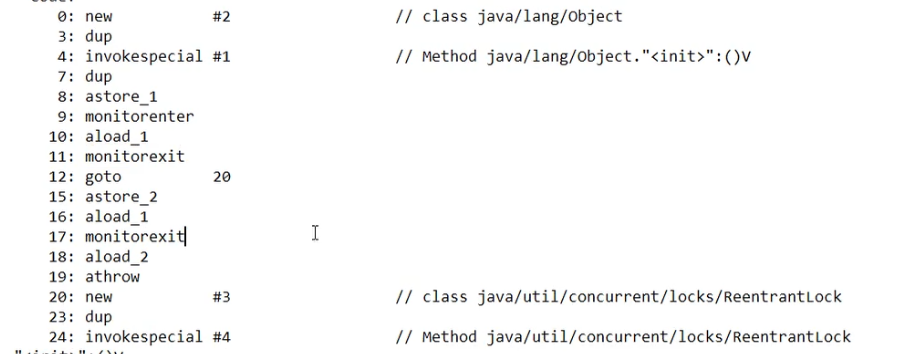
| 存在层次 | Java的关键字,在jvm层面上 底层使用 汇编的monitorenter、monitorexit实现 参考下图,两次monitorexit,一次代表正常退出,一次是finally的强制保证退出 |
是一个接口,使用具体类,是 api层面的锁 |
| 锁的释放 |
1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程自动释放锁 |
在finally中必须释放锁,不然容易造成线程死锁 lock()和unlock()方法成对使用配合try、finally保证程序运行 |
| 锁的获取 | 假设A线程获得锁,B线程等待。 如果A线程阻塞,B线程会一直等待 |
分情况而定,Lock有多个锁获取的方式,大致就是可以尝试获得锁,线程可以不用一直等待(可以通过tryLock判断有没有锁) |
| 锁状态 |
无法判断 | 可以判断 |
| 锁类型 | 可重入 不可中断 非公平 | 可重入 可中断 可公平(两者皆可) |
| 性能 |
少量同步 | 大量同步 - Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离) - 在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态; - ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。 |
| 多条件指定线程唤醒 | 无条件指定,只能随机唤醒一个或全部唤醒 | 可指定多条件,指定特定线程唤醒 |
CountDownLatch、CyclicBarrier、Semaphore
CountDownLatch : 在开始设置标记,每个线程结束后,CountDownLatch 值 countDown(减1),await后直到CountDownLatch的值为0,在执行后续线程。
CyclicBarrier: 在开始设置标记,每个线程结束后,CyclicBarrier值 countDown(加1),await后直到CountDownLatch的值为0,在执行后续线程。
Semaphore: 信号量主要两个目的,一个用于多个共享资源的互斥使用,一个用于并发线程数的控制。
/*** 情景:办公室五个老师都走了,值班人员才可以锁门。*/public class CountDownLatchDemo {public static void main(String[] args) {System.out.println("办公室五个老师");System.out.println("值班人员开始等待所有老师离开");CountDownLatch countDownLatch = new CountDownLatch(5);for (int i = 0; i <5 ; i++) {new Thread(() -> {System.out.println(Thread.currentThread().getName()+"号老师干完自己的事回家了");countDownLatch.countDown();},String.valueOf(i)).start();}try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("所有老师离开,值班人员上锁!");}}
import java.util.concurrent.BrokenBarrierException;import java.util.concurrent.CyclicBarrier;import java.util.concurrent.TimeUnit;import java.util.concurrent.TimeoutException;/*** 情景:五个人员都到会议室才可以开会*/public class CyclicBarrierDemo {public static void main(String[] args) {CyclicBarrier cyclicBarrier = new CyclicBarrier(5,()->{System.out.println("人到齐了,开始开会");});for (int i = 0; i < 5; i++) {new Thread(() -> {System.out.println(Thread.currentThread().getName()+" 号人员进入会议室等待开会");try {cyclicBarrier.await(3, TimeUnit.SECONDS);} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();} catch (TimeoutException e) {e.printStackTrace();}},String.valueOf(i)).start();}}}
import java.util.concurrent.Semaphore;/*** 情景:六个学生打水、只有三个水龙头。抢占打水*/public class SemaphoreDemo {public static void main(String[] args) {Semaphore semaphore = new Semaphore(3);for (int i = 0; i < 6; i++) {new Thread(() -> {try {semaphore.acquire(1);System.out.println(Thread.currentThread().getName()+"号同学抢占到一个水龙头");Thread.sleep(2000);System.out.println(Thread.currentThread().getName()+"号同学打水用时2秒离开");} catch (InterruptedException e) {e.printStackTrace();}finally {semaphore.release(1);}},String.valueOf(i)).start();}}}
队列常用方法和区别,有哪些队列?
| 方法类型 | 抛异常 | 特殊值 | 阻塞(等待插入或取值) | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) 返回boolean值 | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() 返回原值或 null | take() | poll(time,unit) |
| 检查 | element() | peek() 返回首元素 |
// ArrayBlockingQueue (数组组成的有界阻塞队列)// LinkedBlockingQueue 链表组成的有界阻塞队列(默认大小为Integer.MAX_VALUE)// PriorityBlockingQueue 优先级排序的无界阻塞队列// DelayQueue 使用优先级队列实现的延迟无界阻塞队列// SynchronousQueue 单元素阻塞队列// LinkedTransferQueue 链表无界阻塞队列// LinkedBlockingDeque 链表双向阻塞队列// ConcurrentLinkedQueue
对线程池的理解
创建线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor();
public ThreadPoolExecutor(int corePoolSize, //常驻核心线程数int maximumPoolSize, //最大创建执行线程数long keepAliveTime, //闲置线程存活时间,会销毁到只剩下常驻核心线程数TimeUnit unit, //闲置线程存活时间单位BlockingQueue<Runnable> workQueue, //超过执行线程数后的资源处理存放队列ThreadFactory threadFactory, //创建工作线程的创建工厂RejectedExecutionHandler handler) { //超过承载的最大处理资源数的处理方式(最大处理资源数= maximumPoolSize + workQueue )}

若有收获,就点个赞吧
0 人点赞
