1 节点简介
假设这里有16台用于存储数据的服务器,很多人往这16个节点里面存数据,很久以后忘了自己存在哪里怎么办?? 一台一台遍历,显然有点傻。解决方法就是拿出来一台存储一些索引数据,记录其他节点的状态,这个就当做主节点(NameNode),其他的节点用来存储数据叫做(dataNode)。
hadoop有着很明显的主从结构
主节点:NameNode用来尾骨集群的目录树结构,同时对外提供服务。dataNode就是用来存储数据的
我们在02里面部署了三台linux服务器
他们的集群规划是
集群规划:+--------------+---------------------+| Node | Applications |+--------------+---------------------+| qianfeng01 | NameNode | qianfeng01 是主节点namenode , 也存储数据datanode| | DataNode | 然后就是ResourceManager,NodeManagere后面yarn学到| | ResourceManager || | NodeManagere |+--------------+---------------------+| qianfeng02 | SecondaryNameNode | qianfeng02 这台机子 数据节点,nodemanager ,| | DataNode | SecondaryNameNode 后面学到| | NodeManager |+--------------+---------------------+| qianfeng03 | DataNode |qianfeng03 就是一个普通的数据节点datanode,NodeManager| | NodeManager |+--------------+---------------------+
2 开始编辑hadoop的配置文件
这里我们主要进行编辑的文件有
我们需要通过配置若干配置文件,来实现Hadoop集群的配置信息。需要配置的文件有:hadoop-env.shyarn-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml在Hadoop安装完成后,会在$HADOOP_HOME/share路径下,有若干个*-default.xml文件,这些文件中记录了默认的配置信息。同时,在代码中,我们也可以设置Hadoop的配置信息。三个位置里面都可以对hadoop进行配置,三个地方的优先权是这些位置配置的Hadoop,优先级为: 代码设置 > *-site.xml > *-default.xml
首先我们进到qianfeng01里面的Hadoop的安装目录里面去/usr/local/hadoop。
可以看到hadoop里面有这么几个文件夹
所有的配置文件都是放在hadoop的etc里面的 进到etc里面你就会发现Hadoop的etc里面只有一个文件夹就是hadoop,在进到hadoop里面去,现在我们的位置就是 /usr/local/hadoop/etc/hadoop
里面有很多文件,我们可能要对下面这些进行编辑
2.1 编辑core-site.xml
[root@qianfeng01 ~]# cd $HADOOP_HOME/etc/hadoop/ 就是进到放置hadoop配置文件的文件夹[root@qianfeng01 hadoop]# vi core-site.xml 开始编辑配置文件<configuration><!-- hdfs的地址名称:schame,ip,port--><!-- 在Hadoop1.x的版本中,默认使用的端口是9000。在Hadoop2.x的版本中,默认使用端口是8020 --><property><name>fs.defaultFS</name><value>hdfs://qianfeng01:8020</value></property><!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property></configuration>
直接复制到文件里面就好了,但是我的linux里面中文乱码
2.2 配置hdfs-site.xml
在这个文件里面我们主要就是配置块的副本数,在hdfs里面是以块为单位进行数据的存储的,块是有副本的机制的,我可以在别的节点上面存储我的副本,(可能是为了避免单点故障防止数据的丢失),其他的配置都是hdfs这个文件的默认配置。
首先我们还是要先进到hadoop这个安装目录下面,在hadoop这个文件夹里面有个一etc我们进到etc里面以后有一个hadoop。再进到 hadoop里面,这里面就有很多hadoop的配置文件。
[root@qianfeng01 hadoop]# vi hdfs-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>qianfeng02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>qianfeng01:50070</value>
</property>
</configuration>
我们一开始查看hdfs-site.xml这个文件的时候,里面的配置是空的,我们要将上面文件里面的配置直接复制放进去。
使用vi 命令编辑这个hdfs-site.xml 文件,编辑之后再重新查看一下这个文件,可以看到已经配置好了,但是因为我们的虚拟机中文没有支持的太好,中文出现了乱码。
2.3 配置mapred-site.xml文件
首先还是到/usr/local/hadoop这个文件夹下面,然后进到里面的etc/hadoop/ 里面就存放着hadoop的配置文件。
[root@qianfeng01 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@qianfeng01 hadoop]# vi mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>qianfeng01:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>qianfeng01:19888</value>
</property>
</configuration>
我们先看一下配置之前的mapred-site.xml文件,但是进到文件夹以后我们发现并没有mapred-site.xml这个文件mapred-site.xml.template这个文件,这个mapred-site.xml.template文件是一个模板文件,我们吧这个模板复制一下并且命名为mapred-site.xml 命令:cp mapred-site.xml.template
执行命令之后,我们再查看一下文件
可以看到已经多了一个 mapred-site.xml文件了
开始输入vi mapred-site.xml对这个文件进行编辑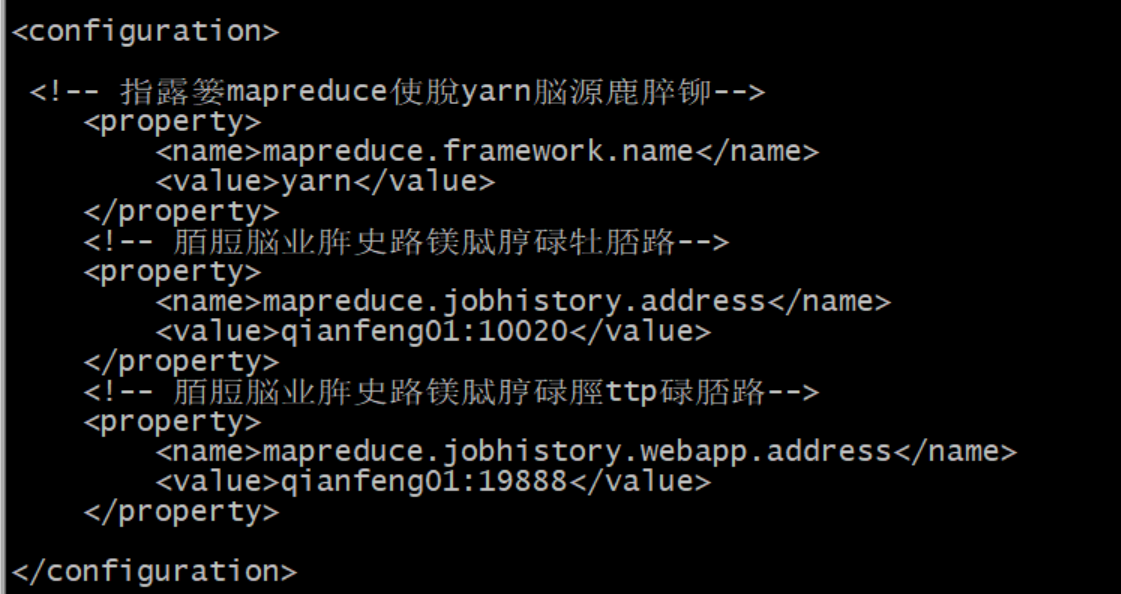
配置以后就可以了,这里的配置的解释我们会在后期学期yarn的时候详细介绍。
2.4 配置yarn-site.xml文件
[root@qianfeng01 hadoop]# vi yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qianfeng01</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>qianfeng01:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>qianfeng01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>qianfeng01:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>qianfeng01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>qianfeng01:8088</value>
</property>
</configuration>
我们先查看一下这个文件里面的数据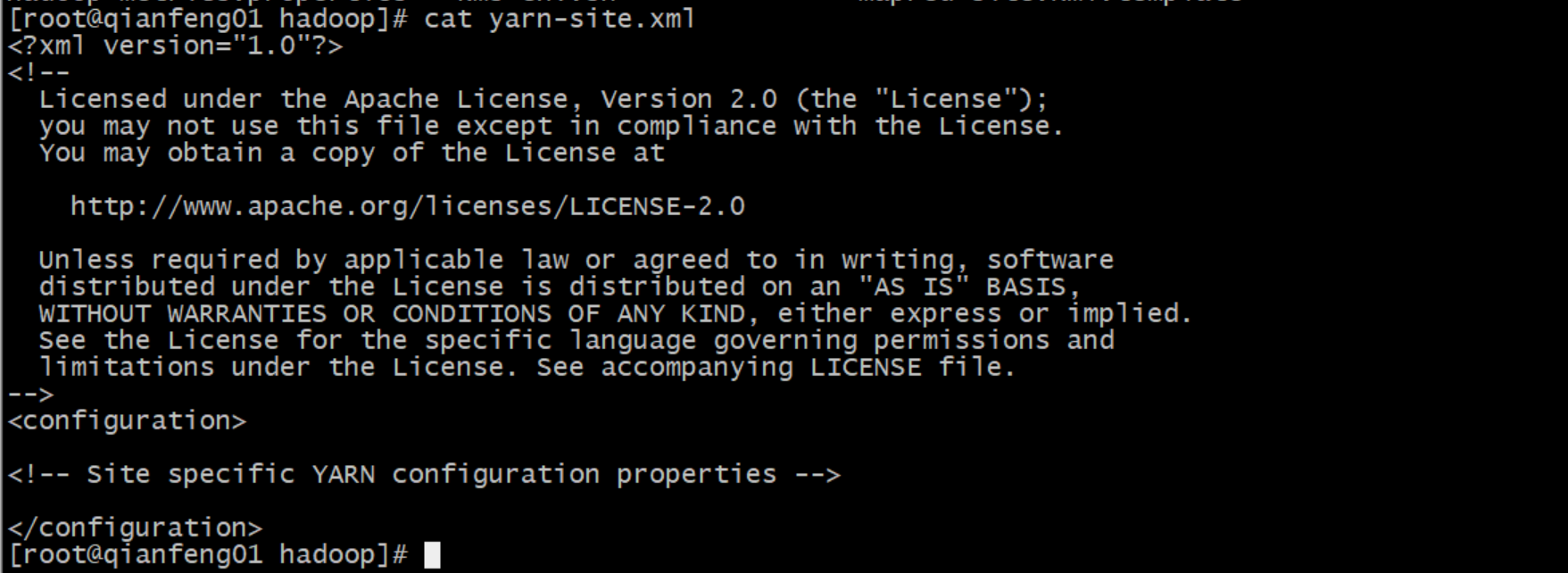
里面其实也是什么配置都没有,我们开始添加配置
及时上面的代码配置进去就可以了。
2.5 配置hadoop-env.sh文件
[root@qianfeng01 hadoop]# vi hadoop-env.sh
.........
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8
.........
还是进到/usr/local/hadoop/etc/hadoop里面看一下hadoop-env.sh文件这个文件里面的内容还是比较多的。
我们主要就是在这个文件夹里面配置一下我们jdk的环境变量
2.6 配置yarn-env.sh文件
[root@qianfeng01 hadoop]# vi yarn-env.sh
.........
# some Java parameters
export JAVA_HOME=/usr/local/jdk
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/local/jdk1.8
fi
.........
还是进到/usr/local/hadoop/etc/hadoop里面看一下hadoop-env.sh文件这个文件里面的内容还是比较多的。
一会我们要在这里设置上我们自己的jdk的位置
2.7 slaves文件
此文件用于指定datanode守护进程所在的机器节点主机名 ,我们三台机器都是datanode所以就在主节点里面指定一下这三台机器,其实就是配置从节点
[root@qianfeng01 hadoop]# vi slaves
qianfeng01
qianfeng02
qianfeng03
还是进到/usr/local/hadoop/etc/hadoop里面看一下hadoop-env.sh文件这个文件里面的内容还是比较多的。
先查看下slaves
cat slaves
这样我们就编辑好了
做好以后我们cd ..
回到上一级其实就是 /usr/local/hadoop/etc ,在etc下面就是hadoop文件夹,文件夹里面就是我们刚刚已近配置多的所有节点了。我们要将这个hadoop文件夹,分发给qianfeng02和qianfeng03,同步一下文件
同步的命令,发给qianfeng02 : scp -r hadoop/ qianfeng02:$PWD
里面的 qianfeng02:$PWD表示的就是qianfeng02的当前位置( /usr/local/hadoop/etc)
同步的命令,发给qianfeng03 : scp -r hadoop/ qianfeng03:$PWD
里面的 qianfeng03:$PWD表示的就是qianfeng02的当前位置( /usr/local/hadoop/etc)

这样就全都发过去了。

若有收获,就点个赞吧
0 人点赞
