- MapReduce概述
- 定义:MapReduce是一个分布式运算程序的编程框架。核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
- 优点:
- 易于编程:简单的实现一些接口,就可以完成一个分布式程序。
- 良好的扩展性:可以动态的增加服务器,解决计算资源不过的问题。
- 高容错性:任何一台服务器的中途挂掉之前,可以把正在执行的任务分配给其他服务器来完成。
- 适合海量数据的计算(TB/PB):几千台服务器共同计算。
- 缺点:
- 不擅长实时计算,一般是处理分钟/小时/天级别的任务。(Mysql)
- 不擅长流式计算,通常是处理静态数据,当数据来一条处理一条,这种实时流式计算MapReduce就不适合。(Sparkstreaming, flink)
- 不擅长DAG有向无环图的计算,即任务1结束之后的结果作为任务2的输入,任务2的输出作为任务3的输入。(Spark)
- 序列化
- 核心框架原理
- 输入数据InputFormat
- Shuffle
- 输出数据OutputFormat
- Join
- ETL
- 总结
- 压缩
- 有哪些压缩算法
- 压缩算法的特点
- 生产环境下如何使用
MapReduce的小结—-以WordCount为例:
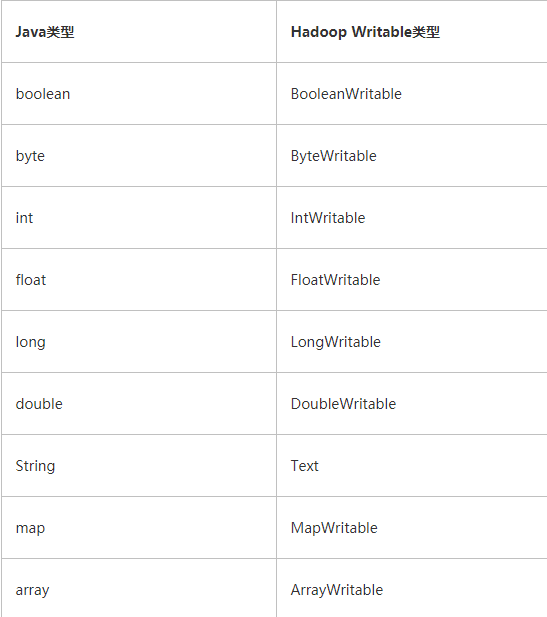
MapReduce从总体上来说,可以分为三个模块:Mapper,Reducer和Driver。在自定义Mapper/Reducer中,继承ortg.apache.hadoop.mapreduce.Mapper/Redeucer(注意这是hadoop2.x和3.x的类,千万别继承1.x对应的Mapper类),需要通过泛型限制Mapper的输入输出kv类型,该类型与Java中的类型有所区别,但是还是比较好理解的,主要区别还是在与String与Text的区别,Text中的方法并没有String丰富,对应的数据类型如下表:
下面以WordCount代码为例对三个模块进行逐一分析:
- Mapper
- 话不多说,先上代码: ```java package com.hishark.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
- @Author: lzh
- @data: 2021-06-02-21:25
- @Description: KEYIN: map阶段输入key的类型:偏移量—>LongWritable
- VALUEIN:map阶段输入value类型:Text(String)
- KEYOUT:map阶段输出的key类型:Text
- VALUEOUT:map阶段输出的value类型:IntWritable
@Version: 1.0 */ public class WordCountMapper extends Mapper
@Override protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word : words) {k.set(word);context.write(k, one);}
} } ```

若有收获,就点个赞吧
0 人点赞
