- Hadoop是什么?用来做什么?
- Hadoop是一个由Apache基金会所开发的分布式系统基础框架,主要解决海量数据的存储和分析计算问题。
- Hadoop的发展历史
- 创始人:Doug Cutting,一开始是基于Lucence框架来实现与Google类似的全文搜索功能的框架
- 2001年Luence成为Apache的一个子项目—->面对海量数据存储,遇到了瓶颈。模仿Google—>Nutch。
- Goolge的三大论文: GFS—->HDFS Map-Reduce——>MR BigTable——>HBase
Hadoop的三大发行版本:
- Apache版本—->最初始版本——>2006
- Cloudera版本—->对应产品CDH—->2008
- Hortonworks——>对应产品HDP—->2011
- 现在Hortonworks已经被Cloudera公司收购—->对应产品CDP
Hadoop的优势:4高
- 1.高可靠性(每台服务器维护多个副本)

2.高扩展性:

3.高效性,在MapReduce的思想下,Hadoop是并行工作的。
- 1.高可靠性(每台服务器维护多个副本)

- 4.高容错性:能够自动的将失败的任务重新分配。
- Hadoop的1.x, 2.x, 3.x的区别(面试题):

- NameNode:记录数据存储的位置,存储数据的元数据,如文件名、文件目录结构、文件属性以及每个文件的块列表和块所在的DataNode等。
- DataNode: 记录具体的数据,在本地文件系统存储文件块数据,以及快数据的校验和。
- 2NN(Secondary NameNode):每隔一段时间对NameNode做一个备份,防止NameNode的丢失
- Yarn的架构概述:
- ResourceManager(RM):整个集群资源(内存、CPU等)的老大
- NodeManager(NM):单个服务器资源的老大
- ApplicationMaster(AM):单个任务的老大
- Container:容器,相当于一台独立的服务器,里面封装了内存,CPU,磁盘,网络的

- 重点来了:Hadoop的集群配置!!!
思路:首先创建一台hadoop100,其中包含硬件(硬盘,cpu等),软件(系统,jdk,hadoop), 设置好用户名以及静态ip地址。

①在VMware中新建一个虚拟机,选择自定义,稍后安装操作系统,选择操作系统类型(我选择最小系统版),接下来的步骤都是默认选项就可以。
②安装位置:选择自定义—>完成—->’+’添加分区,/boot(启动电脑需要的资源,一般给1g),文件系统要改成ext4—->’+’添加分区,swap(内存不够了可以将硬盘当作内存,我配置了4g,用硬盘冒充内存)—->’+’添加分区,/ 剩下的所有空间分配给用户
③KDUMP:用来系统崩溃时数据的备份,学习阶段,为了节省资源,所有就把这里关闭了
④网络和主机名,把网络打开就行,然后安装就行。
最小系统版需要先安装一些必要的工具
yum install -y net-tools //包含了ifconfig等网络工具yum install -y vim //vim编辑器yum install -install -y epel-release //软件仓库
关闭防火墙
systemctl stop firewalldsystemctl disable firewalld.servise
创新/删除新的用户(Hishark 000000)
userad 用户名passwd 用户名//配置新添加用户的权限vim /etc/sudoers//在%wheel这一行进行添加用户名 ALL=(ALL) NOPASSWD:ALL //每次切换用户不需要输入密码
删除虚拟机自带的JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
配置主机名和ip地址 ```shell vim /etc/sysconfig/network-scripts/ifcfg-ens33 //找到BOOTPROTO,默认是动态获取IP地址,将其改为static,并且在后面加上静态IP地址,网关以及域名解析器 BOOTPROTO=static IPADDR=192.168.xx.xxx //(我用的是192.168.10.100) GATEWAY=192.168.xx.x //(我用的是192.168.10.2) DNS1=192.168.xx.x //(我用的是192.168.10.2)
//主机名称 vim /etc/hostname //把内容改成自己想要的主机名称
//设置主机名称映射 //为什么要做这个操作?考虑如下情况:假设服务器到处都是用IP地址192.168.10.100,如果某天IP地址发生变化,所有的地址都需要进行修改,为了避免这种情况,用一个映射来表示ip地址,每次只需要修改映射值就可以。 //如何进行这个操作? vim /etc/hosts
//在最后面添加映射关系 比如: //192.168.10.100 hadoop100 //192.168.10.101 hadoop101 //192.168.10.102 hadoop102
reboot //重启生效
//重启后ping一下百度,看是否配好了 ping www.baidu.com //查看新的主机名称 hostname
- **下一步就进行虚拟机的克隆操作(需要先关闭虚拟机!)**右键虚拟机--->管理---->克隆--->**创建完整克隆!!**- **修改克隆服务器的IP和主机名**```shellvim /etc/sysconfig/network-scripts/ifcfg-ens33 //修改ip地址vim /etc/hostname //配置主机名reboot
配置W10的主机映射
打开控制面板-->网络和Internet--->网络和共享中心--->更改适配器设置--->右键VMnet8--->属性--->双击TCP/IPv4--->填好IP地址(192.168.10.1),网关(192.168.10.2),DNS(192.168.10.2),备用DNS选择8.8.8.8找到C:\Windows\System32\drivers\etc,里面有个hosts文件,赋值到桌面,按照服务器的格式在最后加上IP映射,然后再替换掉原文件中的hosts,这样做的原因是因为W10的管理权限问题,不会让你直接修改成功。
网络和主机名都配置好了之后通过XShell进行连接,由于W10进行了IP映射,所以可以直接使用hadoop100这样的映射关系来创建连接。
- 接下来就是JDK和Hadoop的安装
- 先将JDK和Hadoop通过Xftp的Xftp传到hadoop102上,配置环境变量
```shell
//解压JDK和Hadoop
tar -zxvf JDK路径
tar -zxvf Hadoop路径
//环境变量的配置在 /etc/profile.d路径下
cd /etc/prorfile.d
//添加新的sh脚本
sudo vim my_env.sh
//添加环境变量
JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_281 export PATH=$PATH:$JAVA_HOME/binHADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.4 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
- 先将JDK和Hadoop通过Xftp的Xftp传到hadoop102上,配置环境变量
```shell
//解压JDK和Hadoop
tar -zxvf JDK路径
tar -zxvf Hadoop路径
//环境变量的配置在 /etc/profile.d路径下
cd /etc/prorfile.d
//添加新的sh脚本
sudo vim my_env.sh
//添加环境变量
//配置好之后要更新一下!!! source /etc/profile
- 测试是否安装成功```shelljavahadoop//出现很多提示就表示安装成功了
编写集成分发脚本(服务器与服务器之间的拷贝)—->安全拷贝
scp(secure copy) 安全拷贝//基本语法scp -r $pdir/$fname $user@$host:$pdir/$fanem命令 递归 要拷贝的文件路径/名称 目的用户名@主机:目的地路径名/名称//下面将hadoop102的jkd以及hadoop拷贝到hadoop103,hadoop104上去(前提是目的地用户的文件已经创建好)scp -r jdk1.8.0_281/ Hishark@hadoop103:/opt/module/ //在hadopp102上操作//scp可以在hadoop102上,从hadopp103传文件到hadoop104上。
rsync远程同步工具——>可以避免复制相同的内容,最对差异文件做更新
//rsync主要用于备份和镜像,速度快,避免复制相同内容和支持符号链接的优点//基本语法 -a 归档拷贝 v 现实复制过程rsync -av $pdir/$fname $user@$host:/$pdir/$fname
xsync集成分发脚本—->循环复制文件到所有结点的相同目录下 ```shell //先把脚本放在hadoop102上,完成之后把脚本分发到每个服务器,这样每台服务器就都可已使用了 echo $PATH //可以看到环境变量中有一个 /home/Hishark/bin的路径,我们把脚本放在该路径下 // /home/Hishark下没有bin目标,先创建 mkdir /home/Hishark/bin sudo vim /home/Hishark/bin/xsync
//把脚本复制进去
!/bin/bash
获取控制台指令
cmd=$*
判断指令是否为空
if [ ! -n “$cmd” ] then echo “command can not be null !” exit fi
获取当前登录用户
user=whoami
在从机执行指令,这里需要根据你具体的集群情况配置,host与具体主机名一致,同上
for (( host=102;host<=104;host++ )) do echo “================current host is hadoop$host=================” echo “—> excute command \”$cmd\”” ssh $user@hadoop$host $cmd done echo “excute successfully !”
//更改xsync的权限 cd /home/Hishark/bin chmod 777 xsync //这样就完成了一台服务器的xsync配置,接下来使用xsync把hadoop102下的xsync分发到其他服务器上 xsync bin/
//这样每台服务器就都可使用xsync脚本了 //同样还以使用这个脚本来同步环境变量 xsync /etc/profile.d/my_env.sh //更新往之后source一下 source /etc/profile
- 使用xsync时注意要切换到相同的用户! 不同用户的话可以使用绝对路径来同步```shellxsync /home/Hishark/bin/xsync
- ssh免密登录 ```shell //把公钥分发给其他服务器,这样该服务器就可以无密访问其他服务器 //每个用户都需要单独配置! //切换到~/.ssh下 cd ~ cd .ssh ssh-keygen -t rsa //生成密钥对(公钥+私钥)
//把公钥发给其他服务器(包括自己) ssh-copy-id hadoop102 ssh-copy-id hadoop103 ssh-copy-id hadoop104
ssh hadoop103 //再次在hadoop102上访问hadoop103就不需要密码了 exit //退出登录
//在其他服务器上重复相同的操作
//切换用户再重复操作 su root cd~ cd .ssh ssh-keygen -t rsa ssh-copy-id hadoop10X …..重复操作
- 集群配置- 注意事项- NameNode和SecondNameNode不要安装在同一台服务器,两个都很消耗内存- ResourceManager也很消耗内存,不要和NameNode、SecondNameNode配置在同一台服务器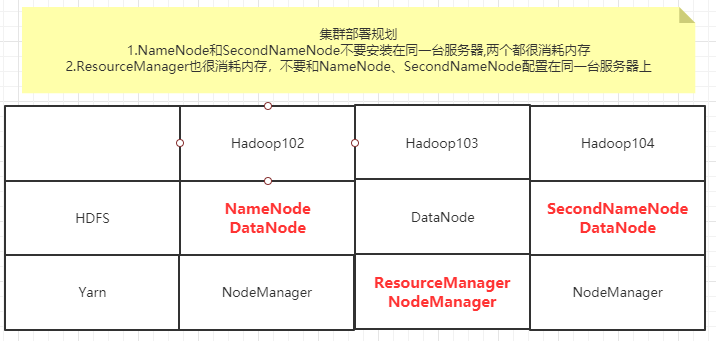- 配置文件说明:Hadoop配置文件分为两类- 默认配置文件- 要获取的默认文件 文件存放在Hadoop的jar包中的位置- [core-default.xml] hadoop-common-3.1.3.jar/core-default.xml- [hdfs-default.xml] hadoop-common-3.1.3.jar/hfds-default.xml- [yarn-default.xml] hadoop-common-3.1.3.jar/yarn-default.xml- [mapred-default.xml] hadoop-common-3.1.3.jar/mapred-default.xml- 自定义配置文件- core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml,这四个配置文件在$Hadoop_HOME/etc/hadoop这个路径上,用户可以根据自己的需求进行重新配置(NN,2NN, RM等的部署)。- 部署核心配置文件--core-site.xml- 这里可以①**设置NameNode的地址;②指定Hadoop数据的存储目录;③HDFS网页登录时的静态用户**- **这里要注意修改路径,hadoop版本号可能不一样,在这里踩过坑,要注意!!**```shell<!-- 指定 hadoop 数据的存储目录,内部通信端口8020 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.4/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 Hishark --><property><name>hadoop.http.staticuser.user</name><value>Hishark</value></property>
- 部署HDFS配置文件—hdfs-site.xml
- 这里可以①设置SecondaryNameNode的地址②web端访问地址
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web 端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web 端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property></configuration>
- 部署Yarn配置文件—yarn-site.xml
- 这是可以①设置MapReduce走什么协议;②ResourceManager的地址③环境变量的继承
- 配置日志聚集功能(默认是false),需要设置聚集地址,保留时间
<configuration><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定 ResourceManager 的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
部署mapred配置文件—mapred-site.xml
- 设置MapRed程序在哪里运行—默认值是在本地运行,需要修改为Yarn
- 设置历史服务器
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
这样就在hadoop102上把所有的集群配置文件设置好了,需要分发到所有的服务器上
cd $HADOOP_HOME/etcxsync hadoop/
在Hadoop103, 104上查看是否分发成功
cd $HADOOP_HOME/etc/hadoopcat core-site.xml//其他3个配置文件也可以查看一下
设置集群的workers——有哪些服务器运行
cd $HADOOP_HOME/etc/hadoop//路径里面有个workers文件vim workers//默认时Localhost//注意事项!!!!//不能有空格,不能空行//改成如下形式:hadoop102hadoop103hadoop104
Client服务器配置(windows10):
- 在本地下载好Java
- 下载并安装Hadoop
- hadoop的下载地址:https://hadoop.apache.org/releases.html
- windows工具包:winutils-master.zip
- 下载好winutils之后,将hadoop.dll和winutils.exe文件复制到hadoop的bin目录下,双击winutils.exe黑色窗口快速闪烁即为安装成功
- 配置Hadoop的环境变量

- 同时Path下添加:

- cmd窗口输入: hadoop version 查看安装的hadoop版本,至此hadoop的安装完成。
配置Hadoop的配置文件
- 分别配置hadoop/etc/hadoop下的core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml文件。
- 这四个文件的作用在集群的配置中有提到过:yarn-site.xmlmapred-site.xmlhdfs-site.xmlcore-site.xml
接下来就是要通过IDEA来对Hadoop集群进行操作了,首先安装好mavenapache-maven-3.8.1-bin.zip,修改conf目录下的settings.xml文件,包括设置本地仓库地址以及添加镜像,这里我添加镜像好像没用,不知道为什么,但是能正常下载,后面出现问题在进行补充,settings.xml。这样Maven就配置好了。接下通过IDEA创建一个Maven工程,在File->setting中找到Mavrn,修改Maven版本,使用自己安装的版本,同时修改好settings.xml文件的路径和本地仓库的路径。
 配置好Maven之后,安装所需要用到的依赖,包括Hadoop的依赖,junit, log4j日志等,然后其下载完成即可。
```java
<?xml version=”1.0” encoding=”UTF-8”?>
<project xmlns=”http://maven.apache.org/POM/4.0.0“
配置好Maven之后,安装所需要用到的依赖,包括Hadoop的依赖,junit, log4j日志等,然后其下载完成即可。
```java
<?xml version=”1.0” encoding=”UTF-8”?>
<project xmlns=”http://maven.apache.org/POM/4.0.0“xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0 com.hishark HDFSClient 1.0-SNAPSHOT 8 8 org.apache.hadoop hadoop-client 3.1.4 com.google.guava guava 30.1.1-jre junit junit 3.8.2 test org.apache.cassandra cassandra-all 3.11.10 org.slf4j slf4j-log4j12 log4j log4j junit junit RELEASE compile junit junit RELEASE compile
```
- 接下来就可以在客户端对hadoop集群进行操作了(主要要先把集群给启动起来!!!)
- 在IDEA中对hadoop集群操作的过程中还遇到了一下环境配置问题,下面汇总和解决:
- FileSystem.get()方法不存在
- 这个问题是因为一开始在本地计算机上没有安装Hadoop导致的,其相关的jar包都没有,所以找不到该方法,在安装后Hadoop并配置好环境变量之后得到解决。
- 报错:Exception in thread “main”java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V….
- 出现这个错误的原因是因为hadoop的版本和guava的版本不一致导致的,可以先将com.google.guava下的旧版本删除,然后在pom.xml文件中补充新版依赖,见上面代码中的guava依赖,问题解决。另外,这个提供一个网址https://mvnrepository.com/,可以搜索各种依赖的Maven配置格式,例如这里的guava包:
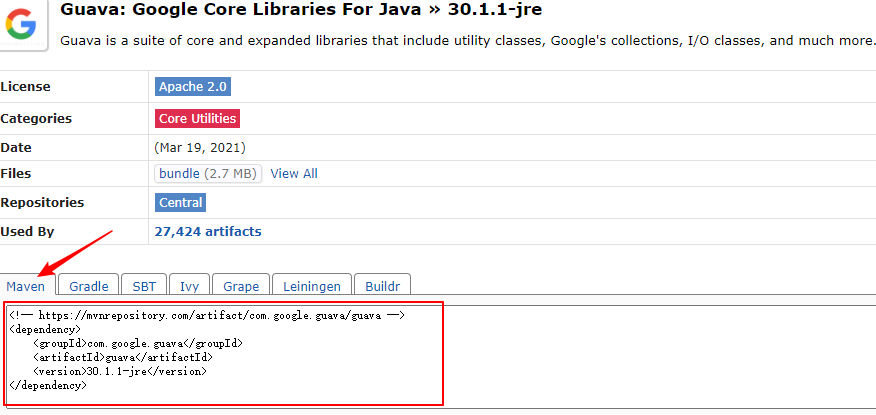
- 出现这个错误的原因是因为hadoop的版本和guava的版本不一致导致的,可以先将com.google.guava下的旧版本删除,然后在pom.xml文件中补充新版依赖,见上面代码中的guava依赖,问题解决。另外,这个提供一个网址https://mvnrepository.com/,可以搜索各种依赖的Maven配置格式,例如这里的guava包:
- 报错:AccessControlExeception:Permission denied: user=A
- FileSystem.get()方法不存在

若有收获,就点个赞吧
0 人点赞
