上一篇文章讲解了PDF.js编译环境的搭建以及解决了各个版本中编译遇到的问题后,这篇文章就对编译好的js代码进行初步解析以及基于本身的demo进行初步的修改与集成。备注:由于2.5.207版本跟后面的PDF.js版本在接口上有很大的差异,这里的集成主要是基于2.10.377版本进行操作。
编译好的PDF.js目录树形结构(备注:其他几个目录例如 cmaps、images、locale、standard_fonts没有完全展示)如下图所示: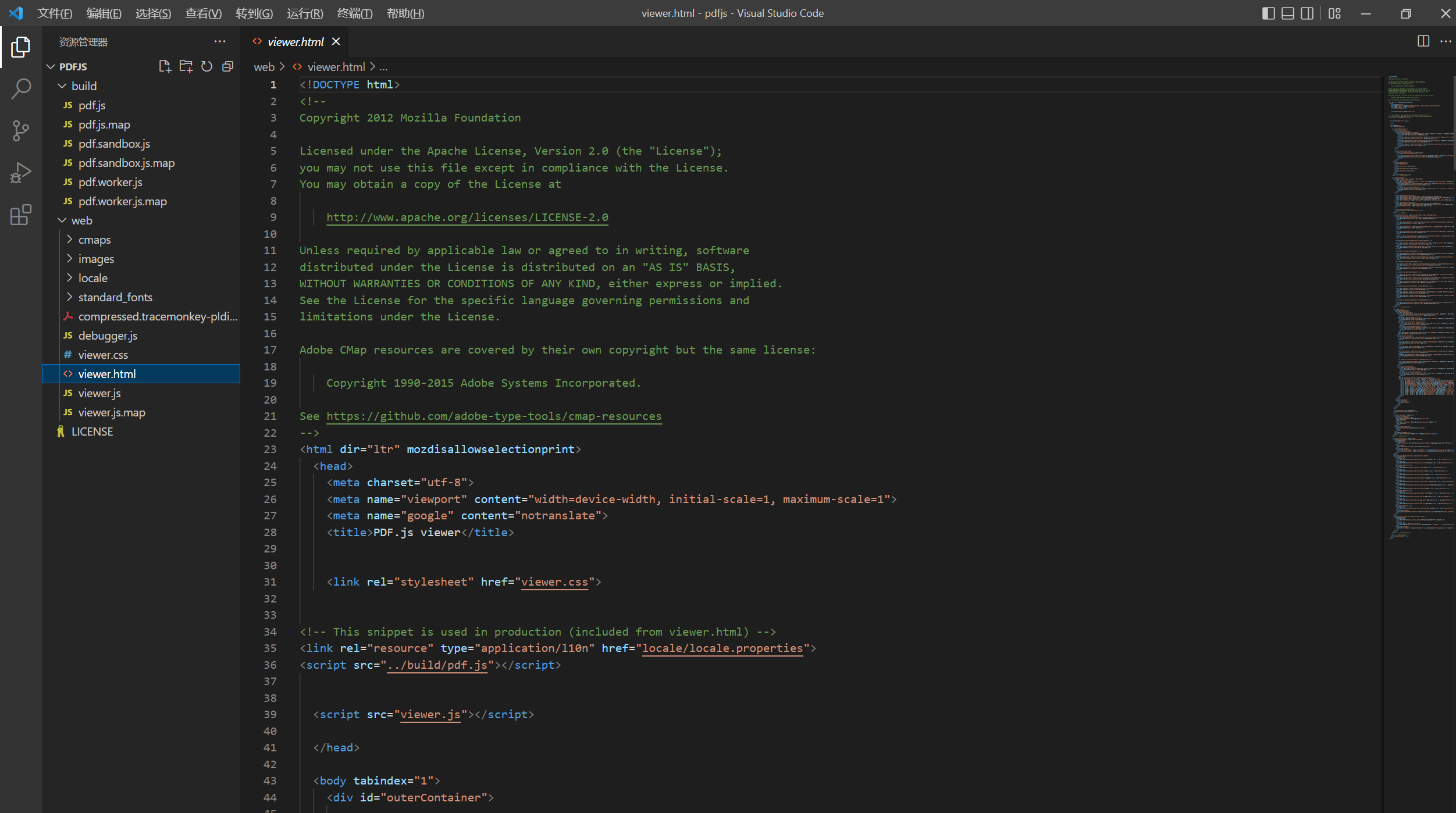
说实话,我拿到编译后的js代码后,没有去关注build目录下的.js以及.map的文件,直接查看了web目录下的viewer.html以及view.js代码,毕竟这个js才是我们要进行集成的PDF.js的UI层。
一、viewer.html
viewer.html这个页面主要用于展示PDF文档,它主要调用的是UI层的代码,显示效果图如下:<br /><br /> viewer.html主要分为三层:outerContainer层、printContainer层(该层目前为空)、xl-chrome-ext-bar层、fileInput域。截图若下图所示:<br />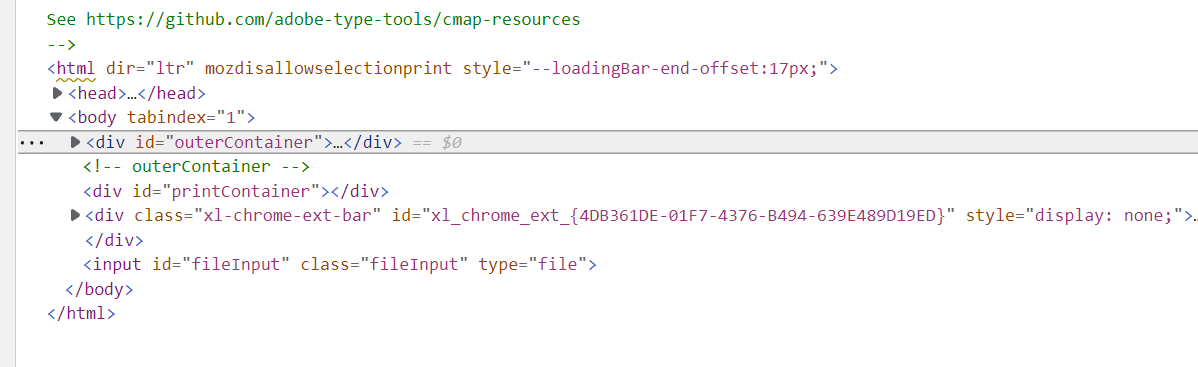
1、outerContainer层
outerContainer层主要用于控制整个页面的展示。该层次也包含了三层,分别是:sidebarContainer层、mainContainer层、overlayContainer层。截图如下图所示:
(1)、sidebarContainer层
该层用于控制是否显示PDF文档的侧边栏。如果在集成过程中不需要该层,直接删除html中的该div的整个元素即可。该层次也包含了三层,分别是:toolbarSidebar层、sidebarContent层、sidebarResizer层。截图如下图所示: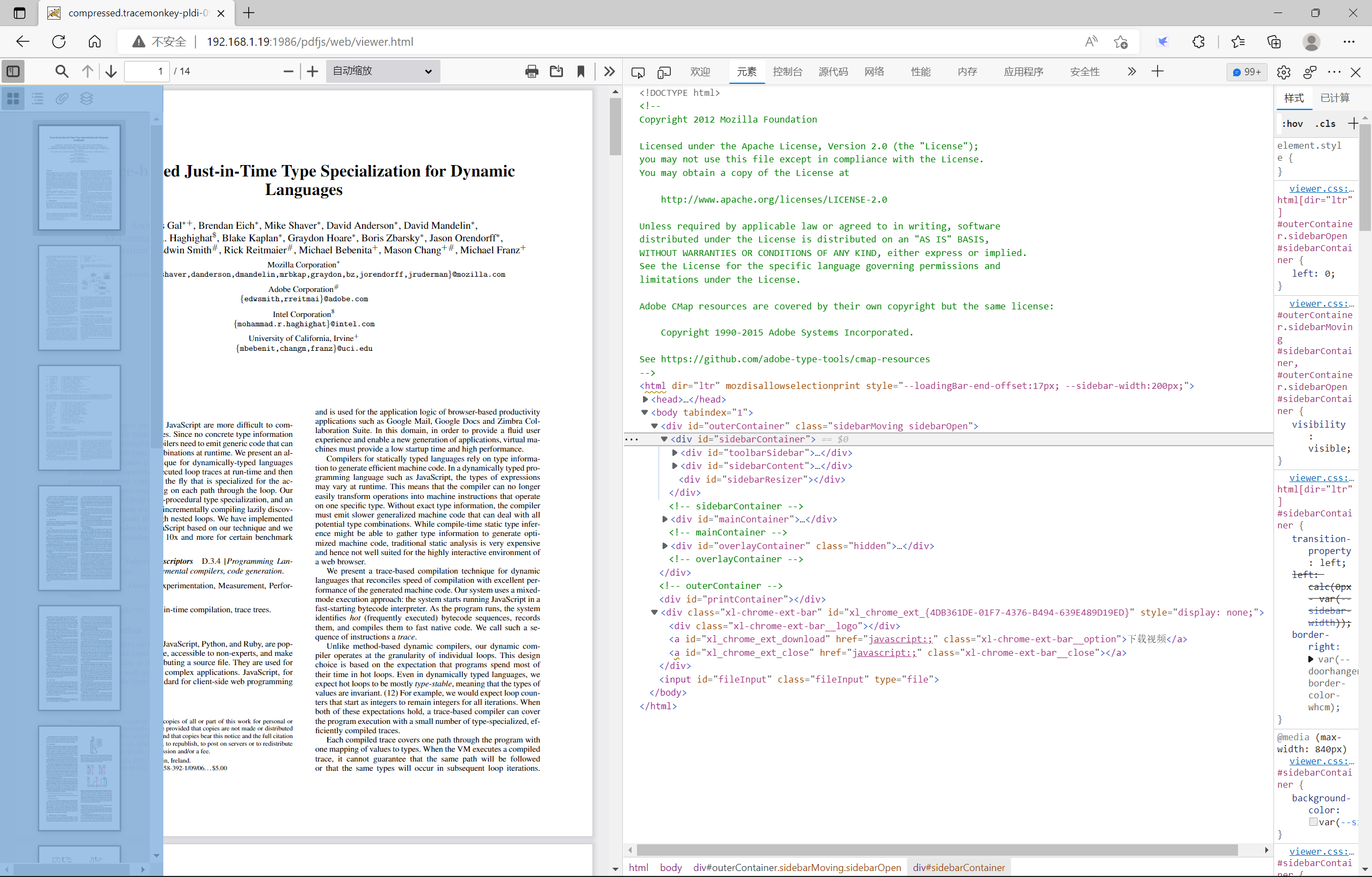
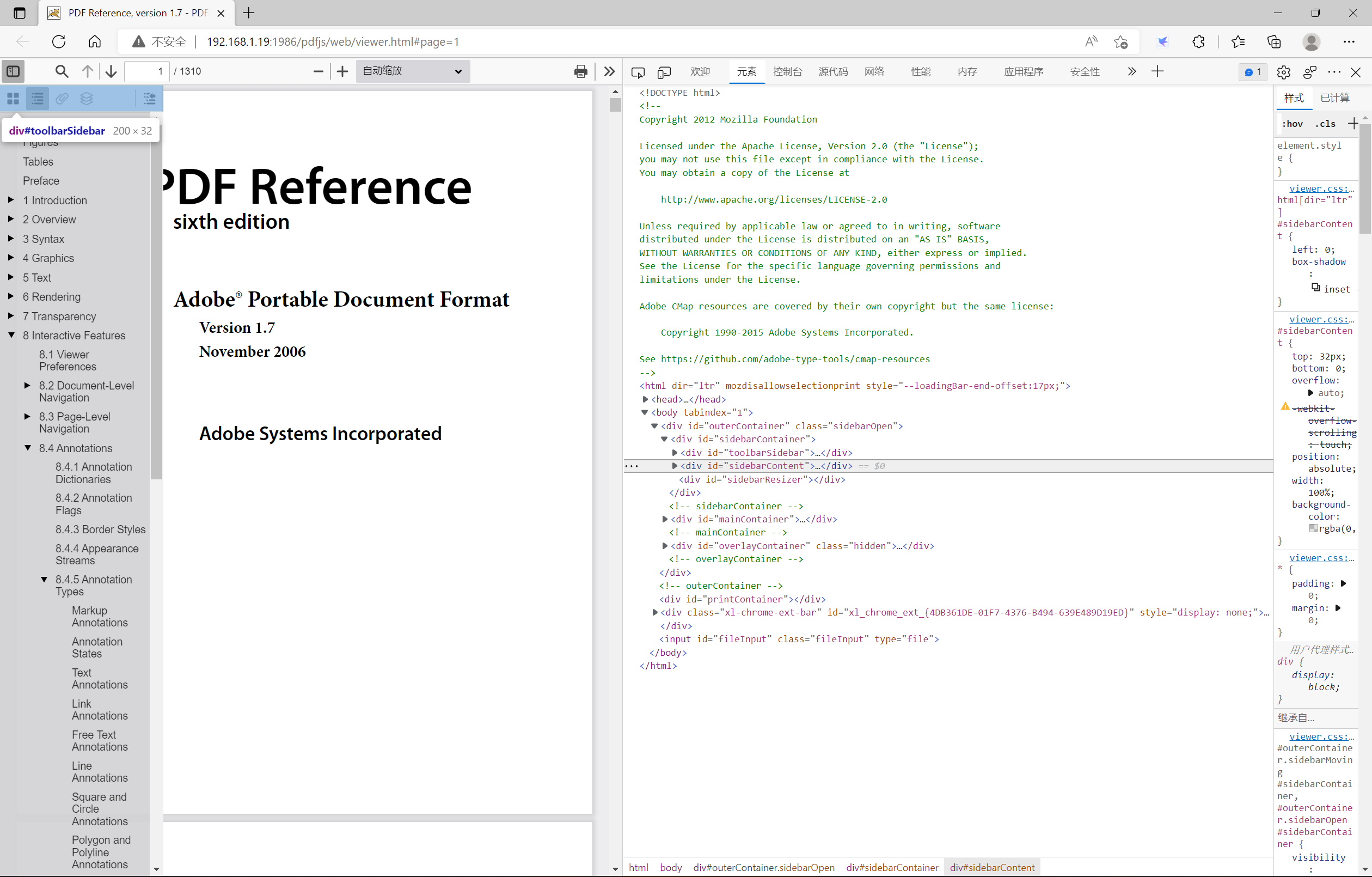
toolbarSidebar层
该层主要定义了5个按钮,用于展示PDF文档的不同形态。分别是显示缩略图、显示文档大纲、显示附件、显示图层、查找当前大纲项目(默认该按钮隐藏)。截的图片中,查找当前大纲项目这个按钮我开启了显示。截图如下: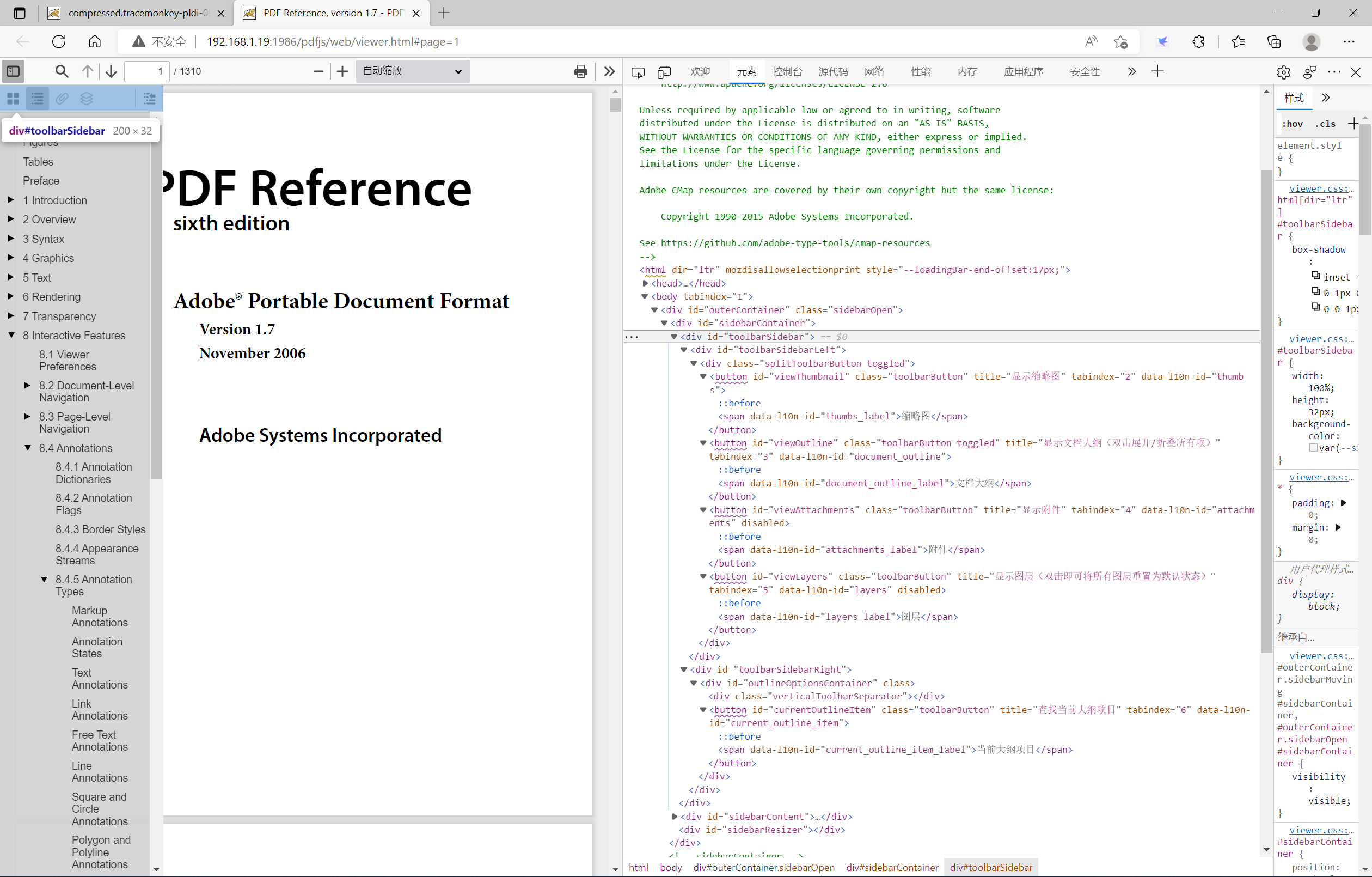
分别点击前4个按钮,则sidebarContent层则会替换成对应的文档数据。
sidebarContent层
该层用于显示toolbarSidebar层中按钮的点击所要展示的内容值。里面具体的内容值就不再详细的讲述了。如下面两张图片所示(备注:第一张图片展现的是显示缩略图按钮、第二张图片展现的是显示文档大纲按钮):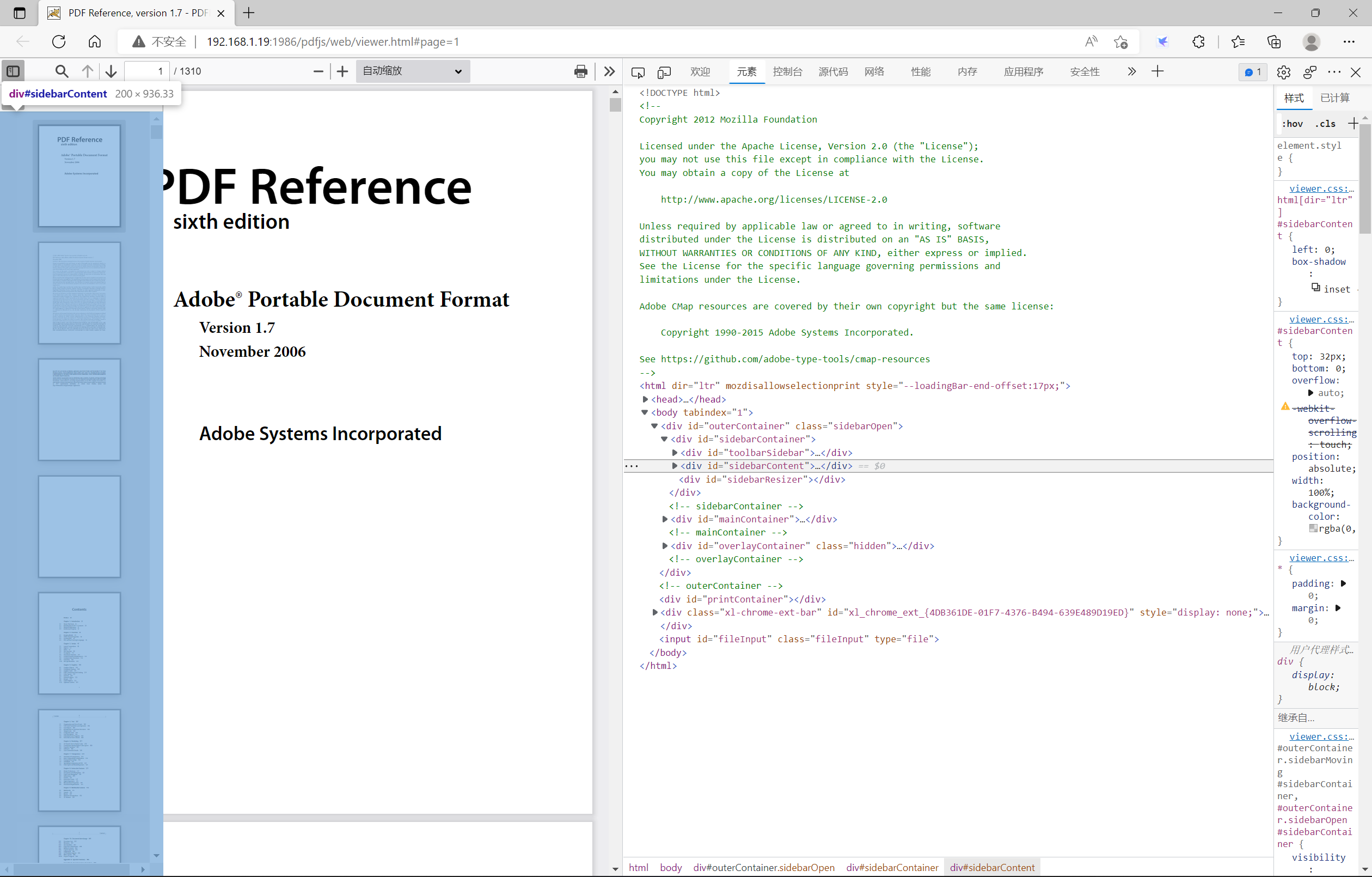
sidebarResizer层
该层主要用于控制sidebarContent层的拖放操作。如果删除该层,sidebarContent层则不会改变高度和宽度。
(2)、mainContainer层
mainContainer层主要分为用于展示需要打开的PDF文档内容以及一些功能接口的测试。该层次包含了五层,分别是:toolbar层、findbar doorHanger层、secondaryToolbar层、viewerContainer层、errorWrapper层。截图如下图所示:
toolbar层
该层主要就是定义了一些操作按钮:切换侧栏按钮、在文档中查找按钮(搜寻图标)、上一页按钮(上箭头图标)、下一页按钮钮(下箭头图标)、页面缩放相关的按钮(减号图标、加号图标以及下拉框)、切换到演示模式按钮、打开文件按钮、打印按钮、下载按钮、当前在看的内容按钮、工具按钮。每个按钮里面具体的内容值就不再详细的讲述了。这里额外提一句,如果要禁用对应的功能按钮,则在对应的button列表中添加style="display:none"即可隐藏按钮。或者直接删除对应的button即可。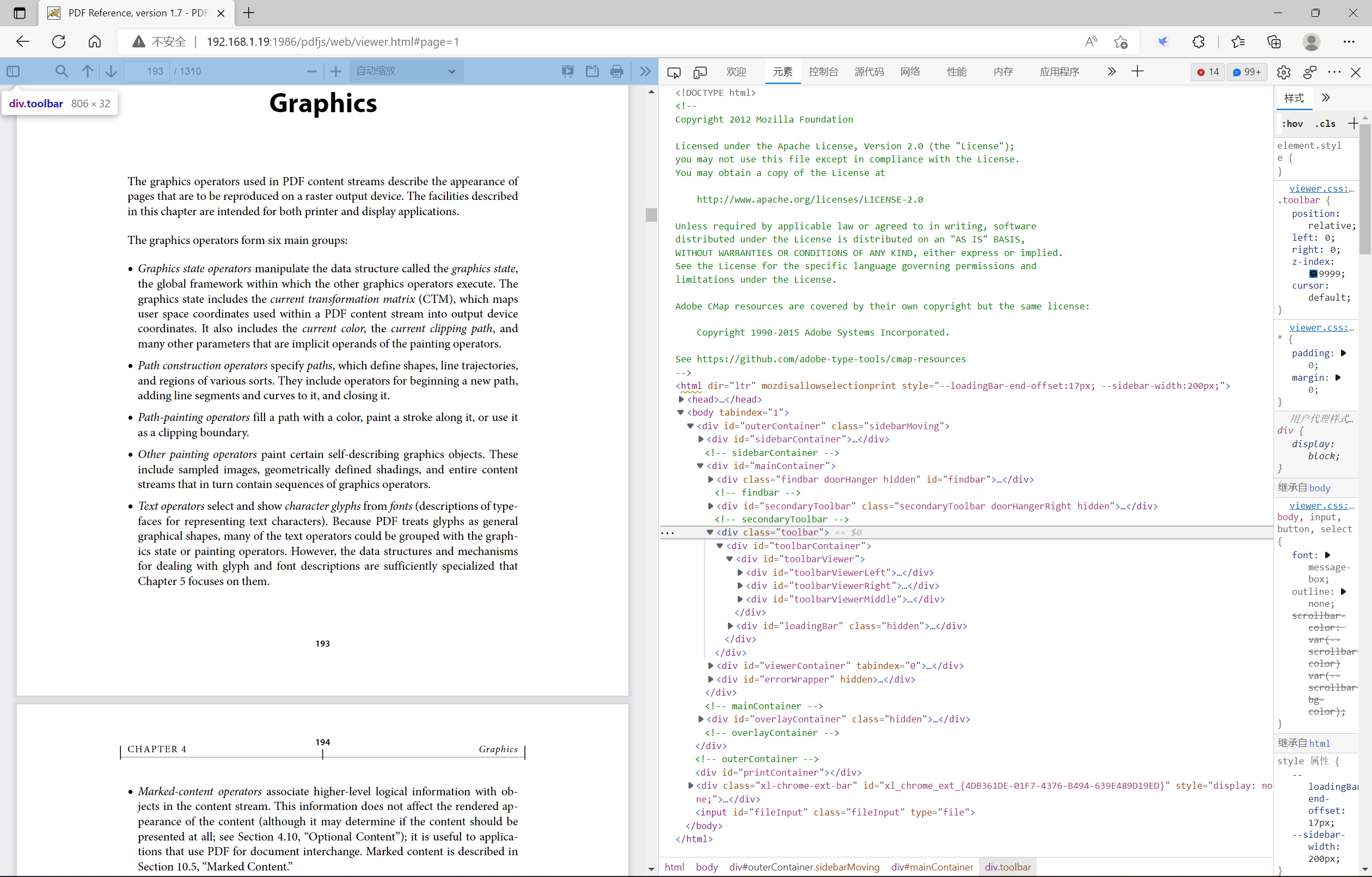
findbar doorHanger层
该层主要是为了给toolbar层中的在文档中查找按钮(搜寻图标)所服务的,即定义了一些查找对应的设置。例如需要查找的文本框、上一个按钮、下一个按钮、设置全部高亮显示属性、是否分区大小写属性、字词匹配属性。每个按钮里面具体的内容值就不再详细的讲述了。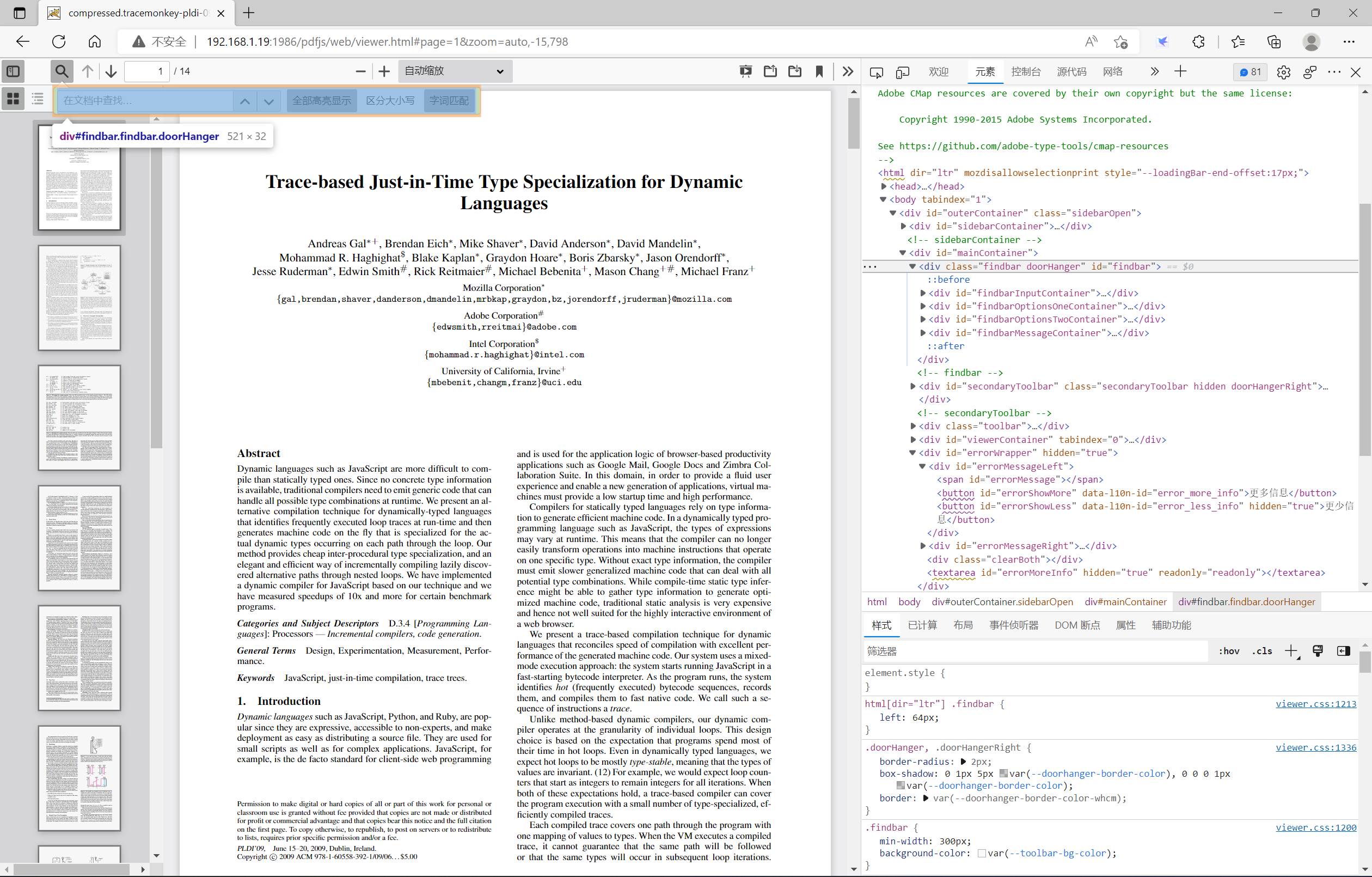
secondaryToolbar层
该层主要是为了给toolbar层中的在工具按钮所服务的,即定义了一些其他按钮。例如转到第一页按钮、转到最后一页按钮、顺时针旋转按钮、逆时针旋转按钮、启用文本选择工具按钮、启用手形工具按钮、使用垂直滚动按钮、使用水平滚动按钮、使用平铺滚动按钮、单页视图按钮、双页视图按钮、书籍视图按钮、文档属性查看按钮。每个按钮里面具体的内容值就不再详细的讲述了。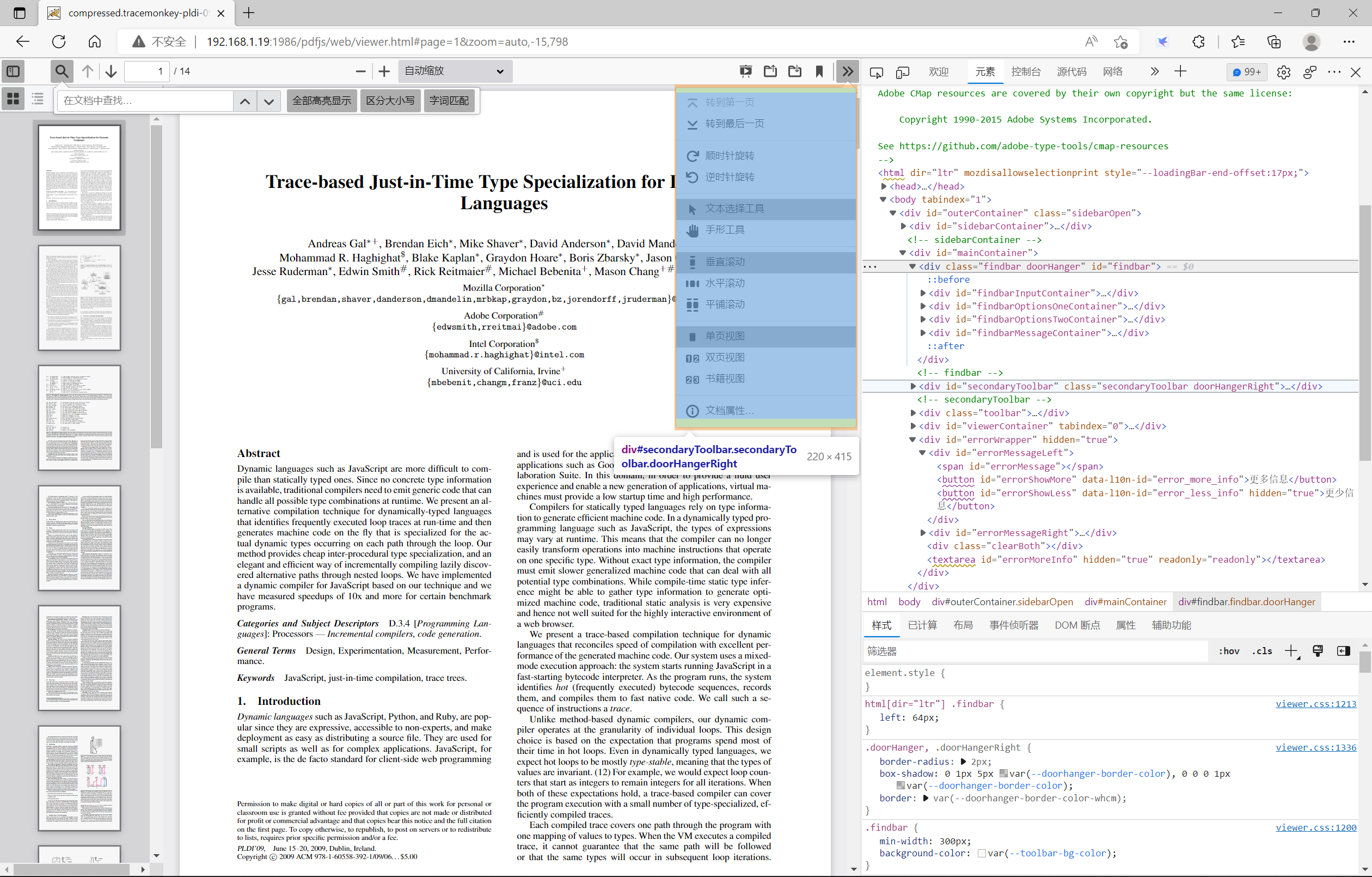
viewerContainer层
该层是重中之重。主要用于显示打开的PDF文档以及根据上面的toolbar按钮的调用来显示文档。主要显示如下: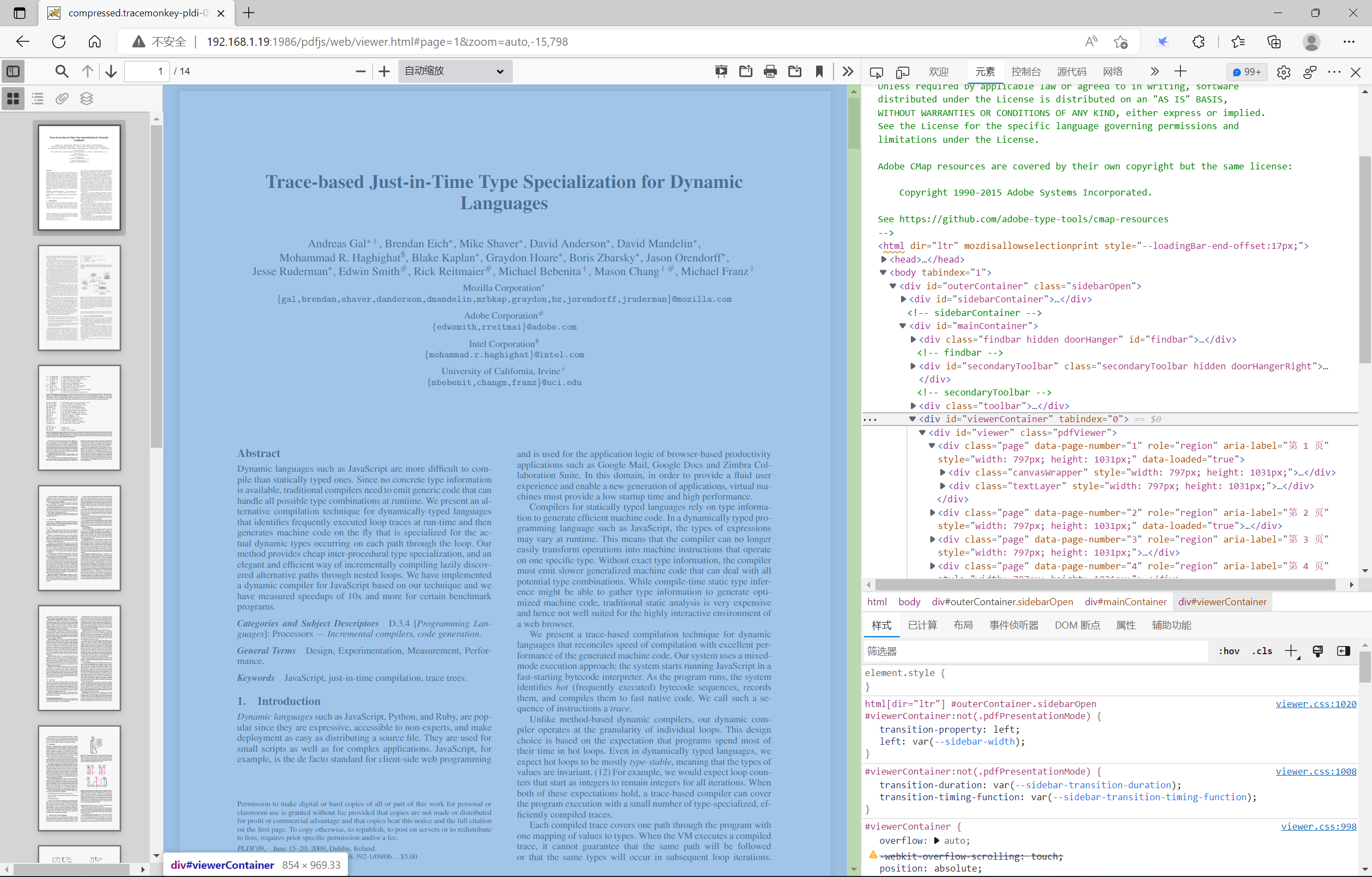
打开viewer.html发现。打开的文档后,发现每一页的Page div层里面嵌入了两个div,一个div名为canvasWrapper层,该层将每一页PDF文档绘制成一块画布,嵌入在最底层。如果将该画布删除,则看到的是一篇空白;另一个div层即为textLayer层,该层则根据PDF的标准,将连续的文本内容提取出来,按照对应的位置贴在canvasWrapper层上,让你进行一些对文字的操作,例如选中等。如果把这层删除,则对文档操作不了。如下图所示: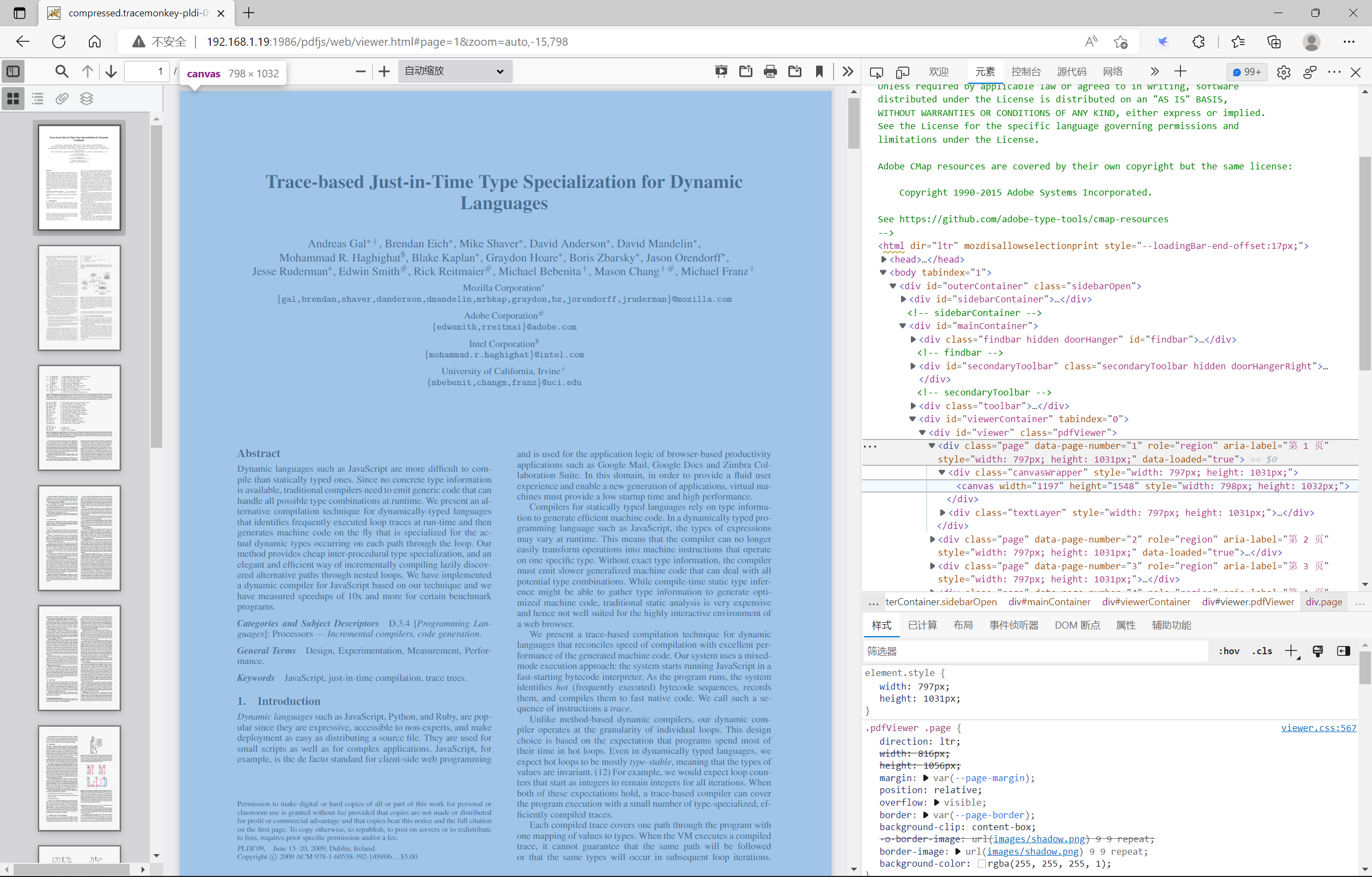
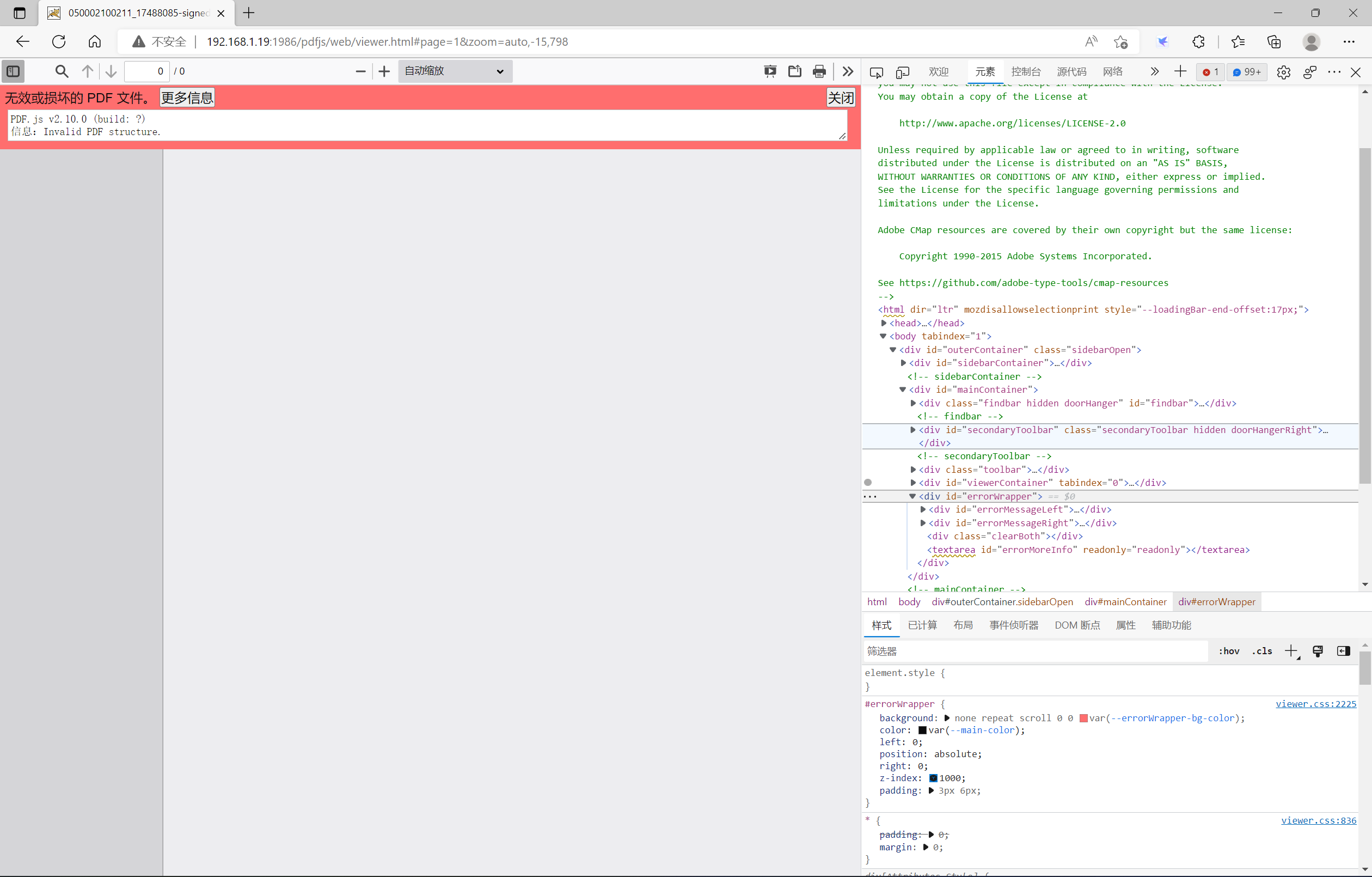
errorWrapper层
该层主要是显示在打开PDF文档时的错误信息,默认是隐藏的。只有在打开指定的PDF文件出错时,该层才会显示。下面的图片则是我打开一份非标准的PDF文档时,页面的显示。
 (3)、overlayContainer层
(3)、overlayContainer层
该层主要定义了三层,默认是隐藏的,只有调到对应的显示操作时,才显示到mainContainer层上。分别为:passwordOverlay层、documentPropertiesOverlay层、printServiceOverlay层。每一层都定义了一个dialog框,js代码如下图所示:
passwordOverlay层
该层主要定义了一个密码框,该框只有在打开带密码的PDF文档时,才会出现。下图是打开带密码的PDF文档的截图: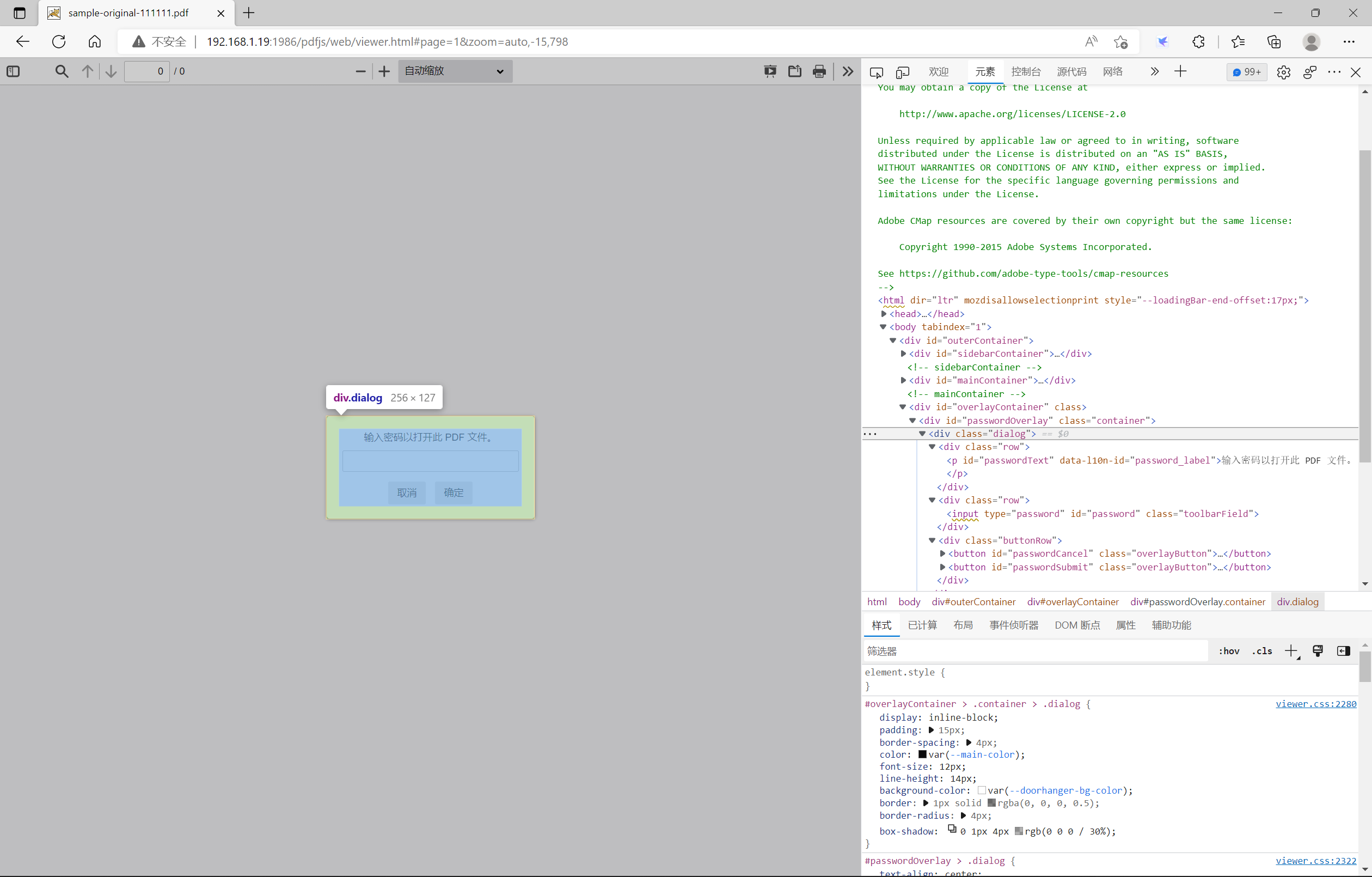
documentPropertiesOverlay层
该层主要展示打开的文档的相关属性信息。即可通过toolbar层中的文档属性按钮展示出来。如下图所示:
printServiceOverlay层
该层主要为打印服务,即调用打印按钮时,则会弹出该层。如下图所示: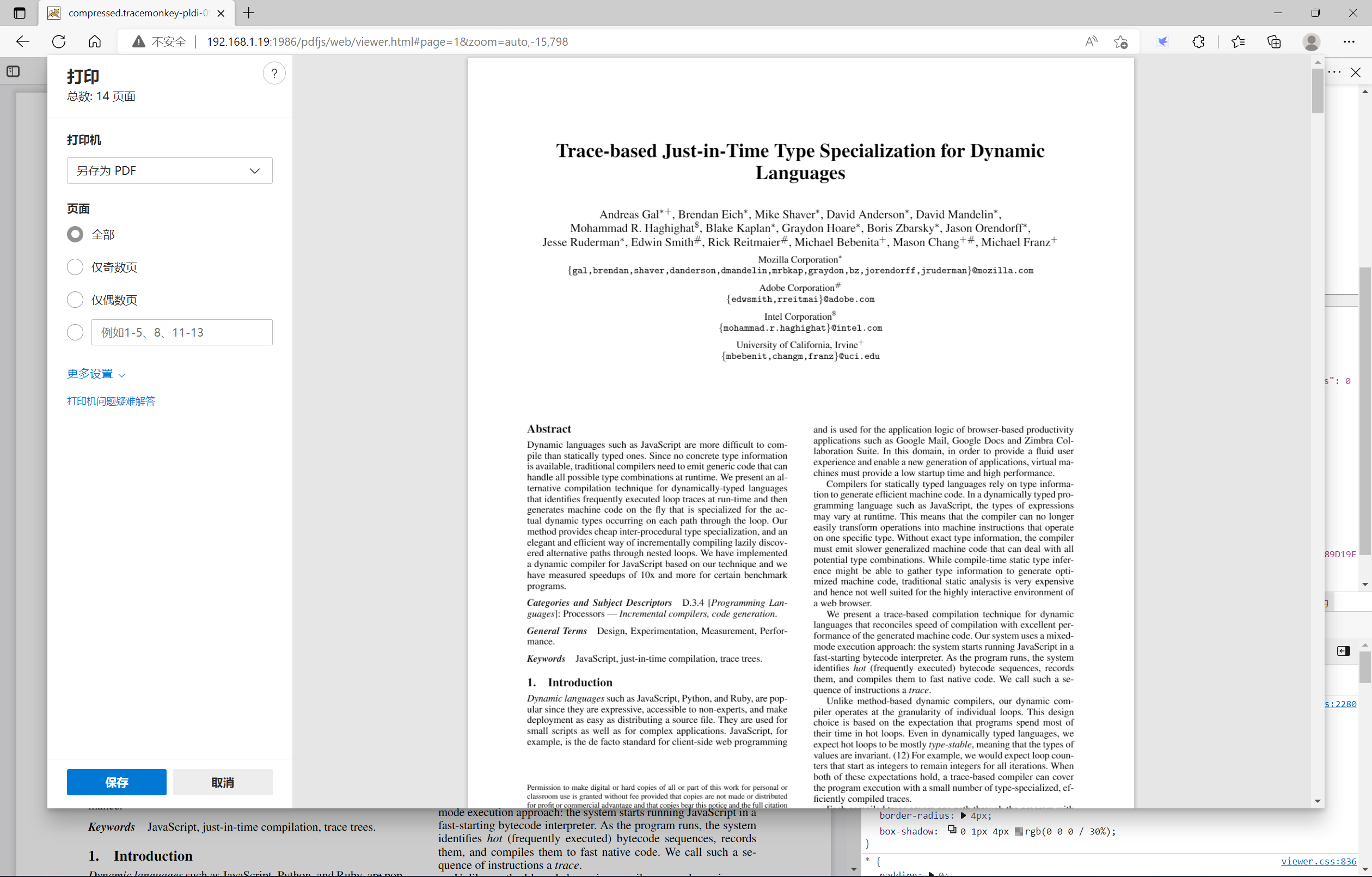
2、xl-chrome-ext-bar层
该层主要用于chrome扩展,目前没有进行研究,也没有进行测试,目前不写。
3、fileInput域
该域用于可以选择本地文件,如果申明了,则toolbar上的打开本地文档按钮则可用。

若有收获,就点个赞吧
0 人点赞
