一、概述
有人会问:什么是缓存穿透?什么是缓存雪崩?如果你了解 Redis 的话,上面的问题对你来说不算什么?虽然在面试的时候,必问这些名词,而且大多数人都知道,如何在代码层面上运用上,通过这篇文章,你会有一个更深的理解
缓存穿透:首先:话不多说,用户查询数据的过程中,如果 redis 数据库没有数据,就会穿透到数据库中查询,如果大量的请求都直接查找数据库,就会造成对数据库很大的压力,相当于出现了缓存穿透。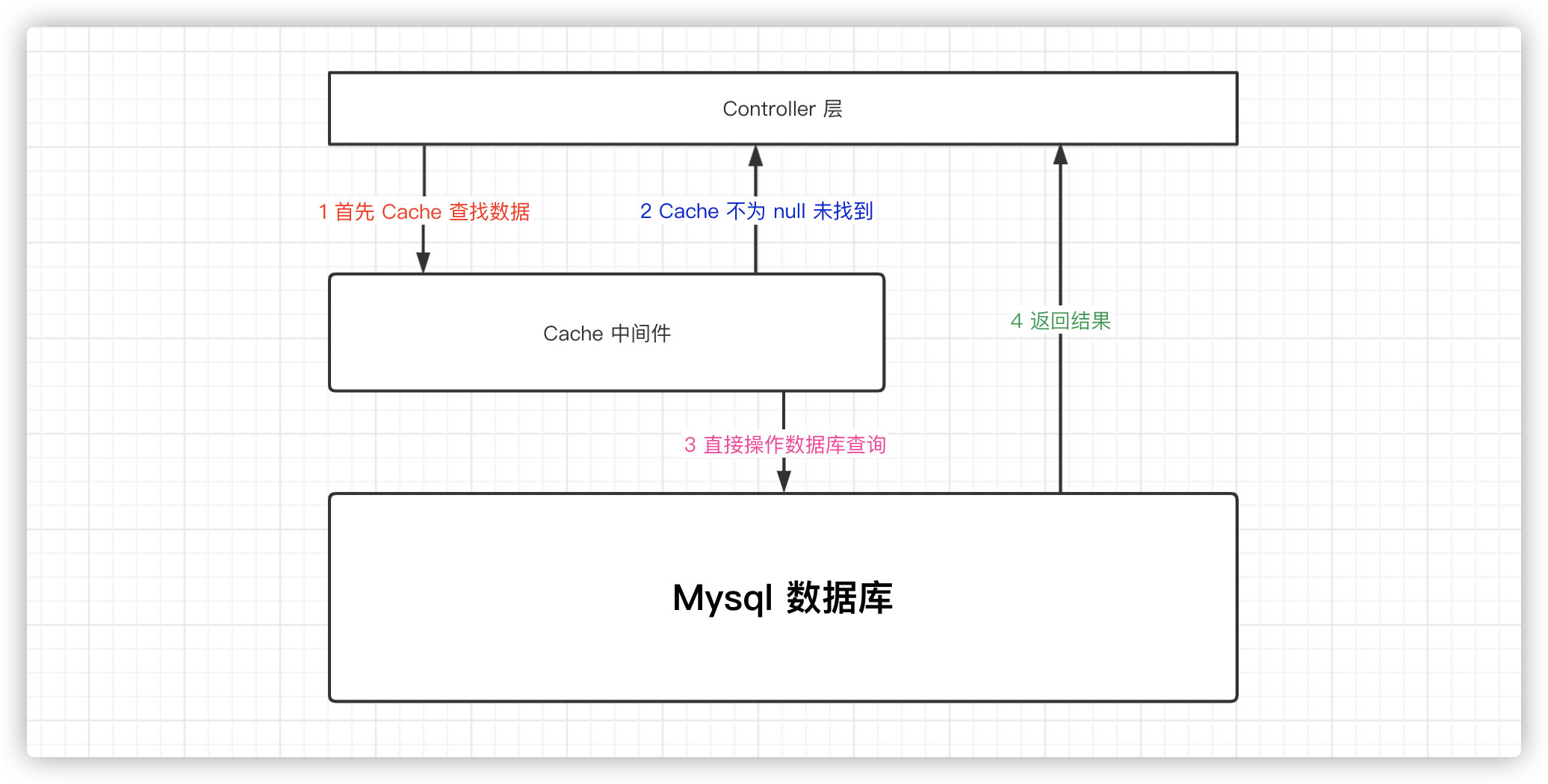
二、有效避免缓存穿透问题
常见的避免缓存穿透问题解决方式有两种:设置初始值 和 布隆表达式。
1、方式一:设置初始值。
早期我们写一个 Redis 的查询接口是这样的。如下所示:(
public Optional<User> getUserById(Integer userId) {User user = redisUtil.get(group_userId.concat(String.valueOf(userId)), User.class);if (Objects.isNull(user)){user = mapper.selectById(userId);if (Objects.isNull(user)) {redisUtil.set(group_userId.concat(String.valueOf(userId)), user,TimeoutUtils.toSeconds(1, TimeUnit.HOURS));}}return Optional.of(user);}
注意:以上代码是 ❌ 错误代码!!!
思考一下:这里真的能防止缓存穿透吗? 答案:不能,如果第 4 行没有查到数据,user 就不会存到 redis 中,等下次再来请求,还是会直接去数据库中查询,想想如果线上有大量的这样的数据请求,对我们的数据库是有多大的危险性呀!想想就可怕!
说到这里,大家恐怕要着急了,那该怎么写的?不用着急,其实写法不唯一,任何一种写法都可以,我这里提供一个我常用的方式,仅供大家借鉴一下。
@Repositorypublic class UserDao {private static final User u = new User();/*** 根据用户id 获取用户 【防止缓存穿透】* @param userId* @return*/public Optional<User> getUserById(Integer userId) {User user = redisUtil.get(group_userId.concat(String.valueOf(userId)), User.class);if (Objects.isNull(user)){user = mapper.selectById(userId);if (Objects.isNull(user)){user = u;}redisUtil.set(group_userId.concat(String.valueOf(userId)), user,TimeoutUtils.toSeconds(1, TimeUnit.HOURS));}if (Objects.nonNull(user) && Objects.isNull(user.getId())){return Optional.empty();}return Optional.of(user);}}
这种方法在编码层次上简单,但是也会给我们带来一些 缺点 :我们每次数据不再的时候,就 new 一个空对象存放到 Redis 中,这会让 Redis 有大量的无效的数据占据这 Redis 的内存空间。
其他方法:布隆过滤器。

若有收获,就点个赞吧
0 人点赞
