分区键问题
问题现象
发现某些客户现场HDFS文件有文件名重复情况,导致部分文件.tmp后缀无法重命名成正式文件。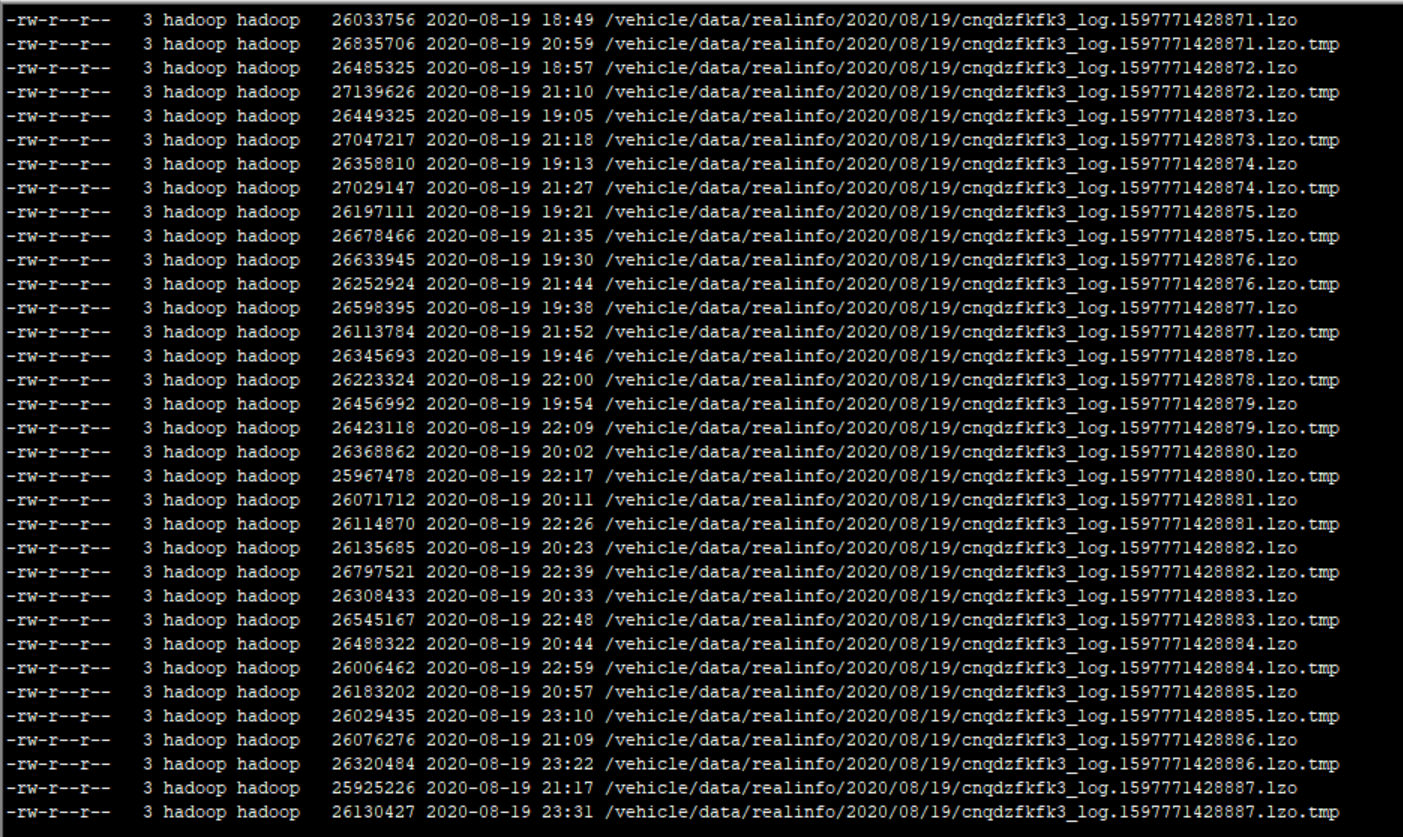
第一反应是不可能啊,我们用机器hostname作为文件前缀,每个机器只有一个Flume进程,Flume是可以通过一个时间戳的后缀来保证同一进程文件名不重复的,马上想到了是不是hostname修改了等等可能性,开始了排查之旅。
原因分析
- 首先怀疑hostname是不是修改过,或者获取host有问题,导致2台机器获取到了同一个host,查了一下记录并没有修改过
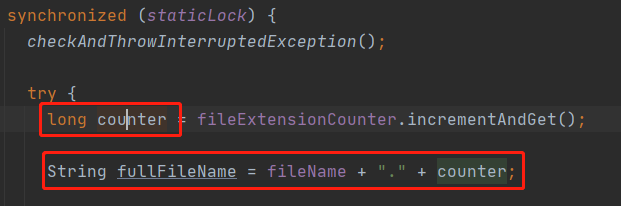
- 然后根据文件创建时间发现2个同名文件并不是同一个时间点创建的,这就更疑惑了,不同时间点为什么文件名会冲突的,并且发现文件名中的时间戳并不是获取当前时间戳的而是基于一个基准递增的
接着查看了HDFSSink源码,发现在使用了文件滚动的情况下文件名中的时间戳并不是每个文件都获取时间戳的,而且每次滚动基于之前缓存的时间戳安全的加1,这样的话如果2台机器写了相同前缀的文件,随着文件滚动是会导致文件名重复的
接着新的问题来了,怎么会前缀相同的呢?不是用了hostname做前缀了吗?
- 继续查Flume日志,发现真的存在单台机器创建不同hostname前缀文件的问题

- 那就需要理一理我们的hostname是从哪来获取的,hostname是通过hostInterceptor添加到header中的,拦截器和sink之间只有Channel那大概率就是Channel的问题了
- 我们近期把MemeryChanel升级了KafkaChannel,这种现象那就是同一进程的Sink消费到了不同hostname的数据
- 查了一下配置信息,KafkaChannel并没有配置分区键,至此我以为问题原因定位到了。去查看KafkaChannel源码分区键如果使用。把车辆唯一标识作为分区键
- 然而还是太年轻,修改之后想到了另外一个问题,hostname在拦截器处理的,拦截器是在Source阶段的,经过KafkaChannel之后同一个Source的数据一定能到同一个Sink吗?如果Source和Sink的分区数相同根据分区键hash之后是可以保证在一个分区里面,如果分区数不同就还是保证不了。
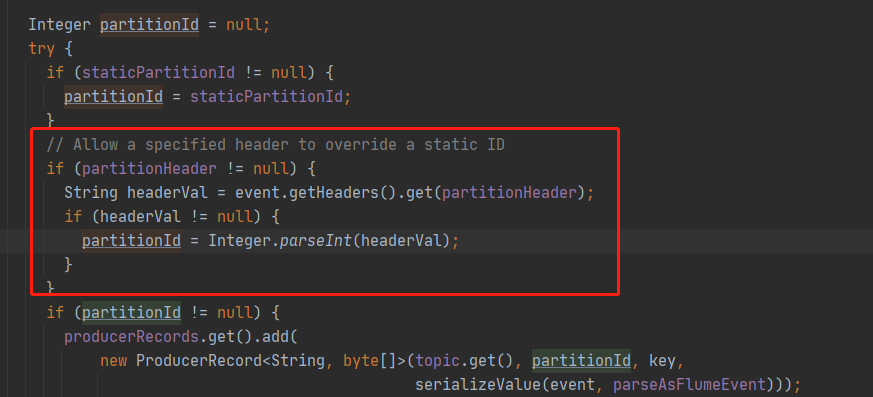
- 那能不能直接指定partitionId?查看源码可以指定,但是如果分区数不一样的话partitionId也有映射不上的问题
- 通过以上思考,形成了下面3个方案,最后选择了方案一来解决
解决方案
- 方案一
- HDFS写入继续使用MemeryChannel,其他使用KafkaChannel,在header中增加车辆唯一标识分区键
- 优点:处理简单不会出现小文件问题
- 缺点:Flume重启时会丢失部分数据
- 方案二
- 手动指定KafkaChannel的partitionId,通过源码分析可以放到header中让KafkaChannel来设别
- 优点:继续享受KafkaChannel的优势,性能高,重启不丢失数据
- 缺点:要保证kafkaSource和KafkaChannel的分区数一样,否则会有partitionId映射不上的问题
- 方案三
- HDFS使用KafkaChannel,在header中分区编号,使用kafka分区编号作为HDFS文件前缀
- 优点:继续享受KafkaChannel的优势,性能高,重启不丢失数据
- 缺点:使用分区号作为文件前缀会导致同时写多个文件,并且随着分区增多会同时写的文件会更多,可能会出现小文件问题
总结
如果没有合理使用KafkaChannel的分区键,又在Sink阶段做了依赖分区的累加计算、source阶段产生的元数据等情况,都会导致结果不符合预期。
但是由于官方文档未对分区键做说明,导致前期忽略这个问题,后期根据源码找到使用方式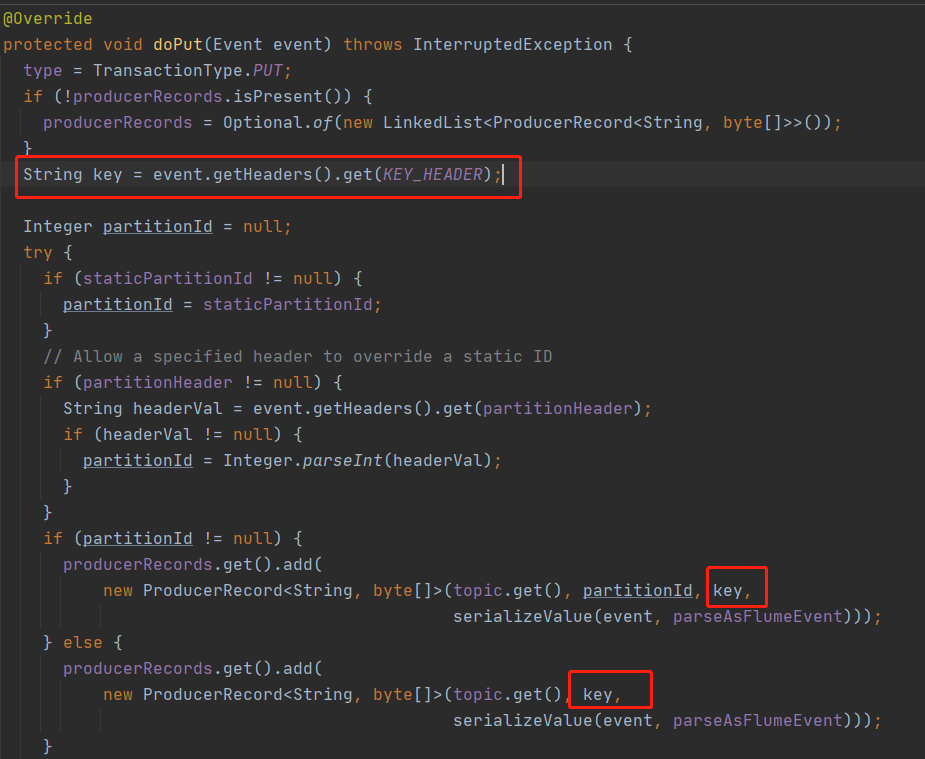
1、目前没有设置消息发送key, 需要设置
String key = event.getHeaders().get(KEY_HEADER);
2、默认acks = all 这个性能比较差
public static final String DEFAULT_ACKS = “all”;
3、不该在拦截器处理格式转换操作,否则source异常时会数据丢失
acks默认值问题
KafkaChannel 默认acks = all 会导致写入Channel延迟显著提高降低吞吐量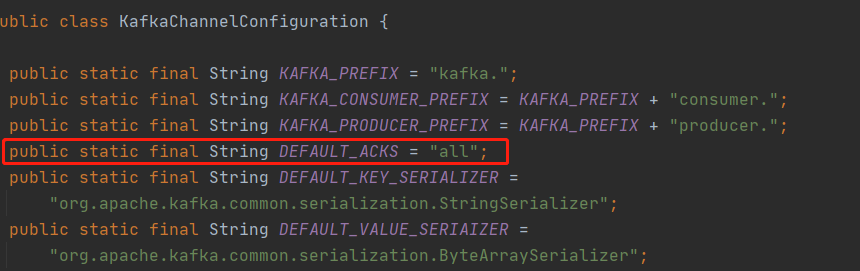
可以通过修改配置文件参数改变默认参数
agent1.channels.packetChannel.kafka.producer.acks = 1

若有收获,就点个赞吧
0 人点赞
