oozie+hue
标签(空格分隔): Oozie Azkaban HUE 调度
1.Oozie简介
①什么是Oozie
Oozie:
- Hadoop平台的开源的工作流调度引擎;
- 是用来管理Hadoop作业,属于web应用程序,由Oozie client和Oozie Server两个组件构成;Oozie Server运行于Java Servlet容器(Tomcat)中的web程序;
- 主要用于管理与组织,Hadoop工作流;
- Oozie的工作流必须是一个有向无环图,实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流。一个Oozie的job,是只有Map Task的mapreduce程序。
②工作流调度框架Oozie
要点概述
1,一个基于工作流引擎的开源框架,是由Cloudera公司贡献给Apache的,它能够提供对Hadoop Mapreduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。
2,Oozie工作流定义,同Jboss jBPM提供的jPDL一样,提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。对于工作流系统,一般会有很多不同功能的节点,比如分支,并发,汇合等等。
3,Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision,fork,join等;而动作节点包括Haoop map-reduce hadoop文件系统,Pig,SSH,HTTP,eMail和Oozie子流程。
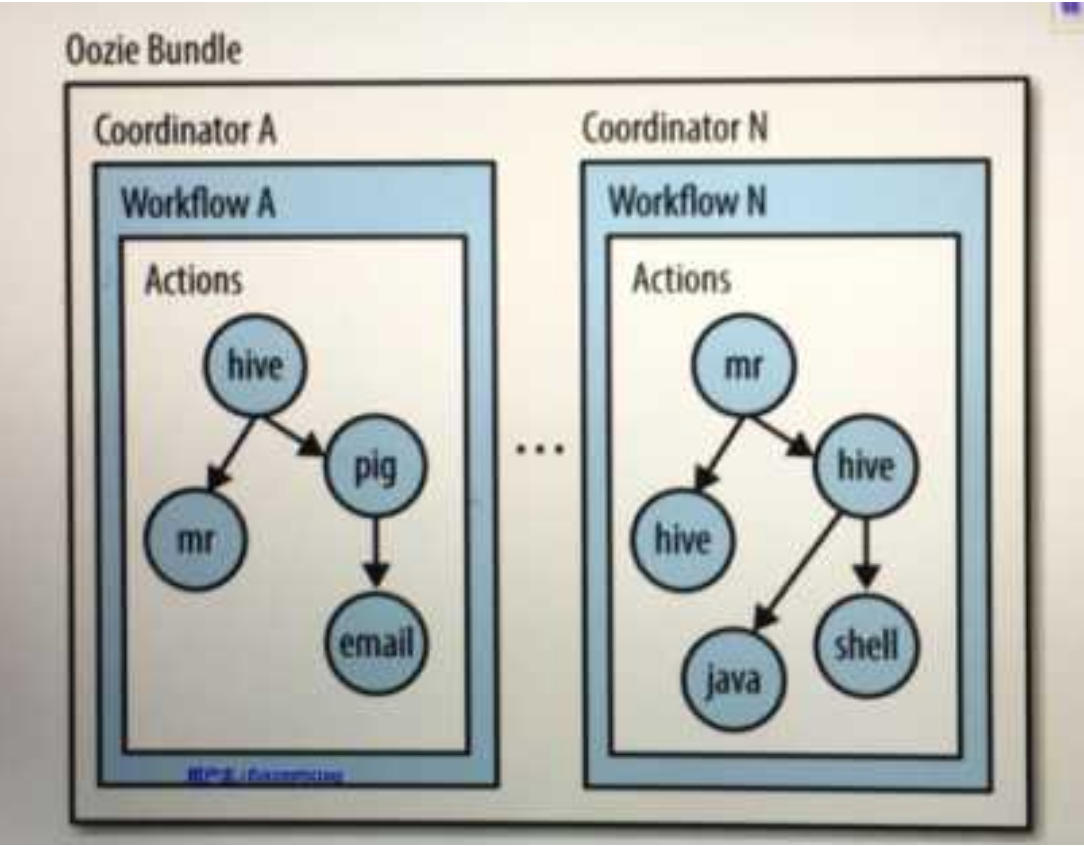
workflow、Coordinator以及Bundle
workflow从某种程度上来说是job的DAG
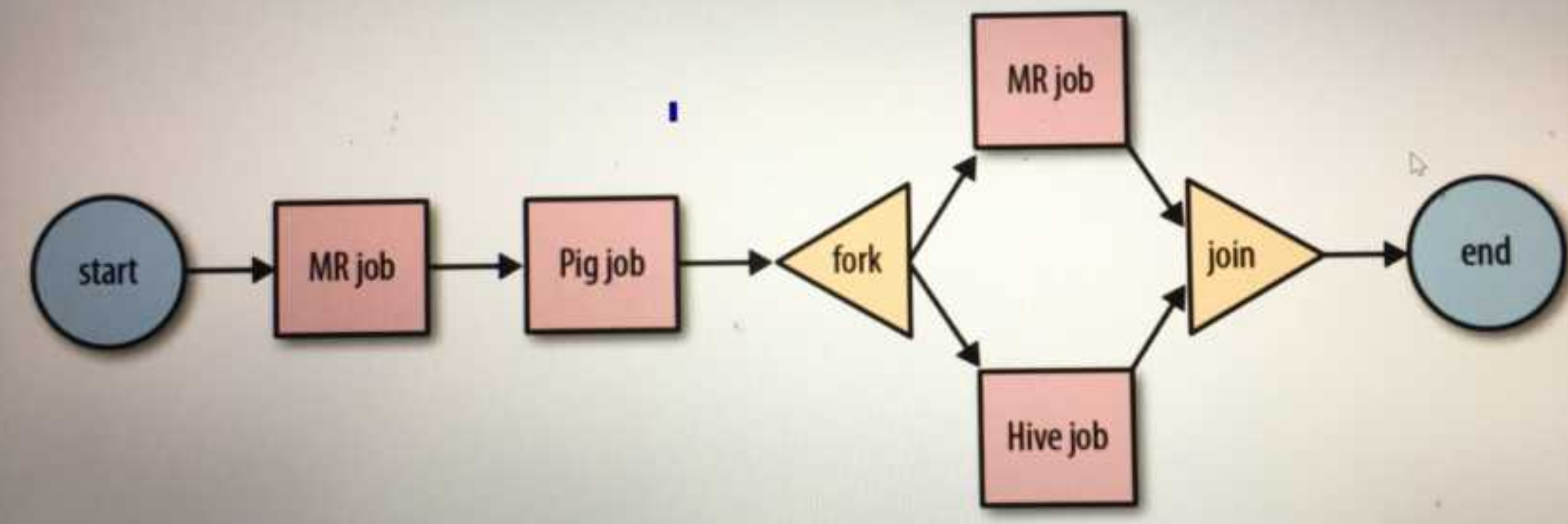
Oozie Coordinator是对workflow的定时或条件触发型的调度
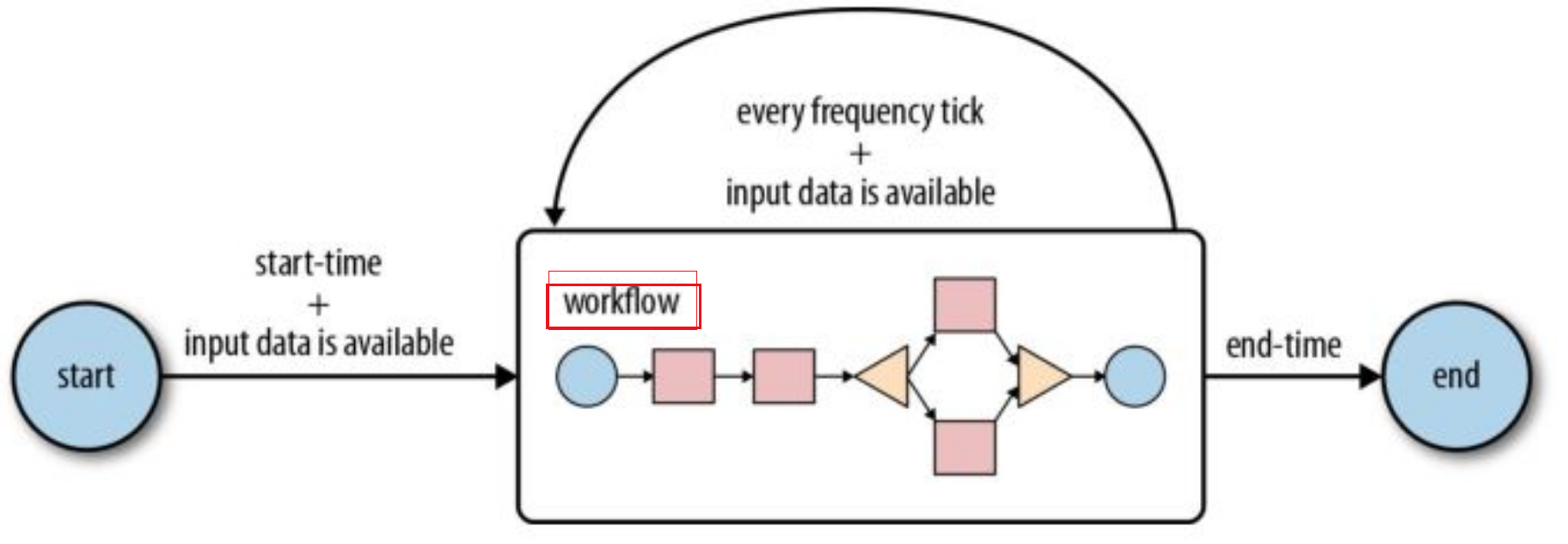
Oozie Bundle是对多个Oozie Coordinator的捆绑
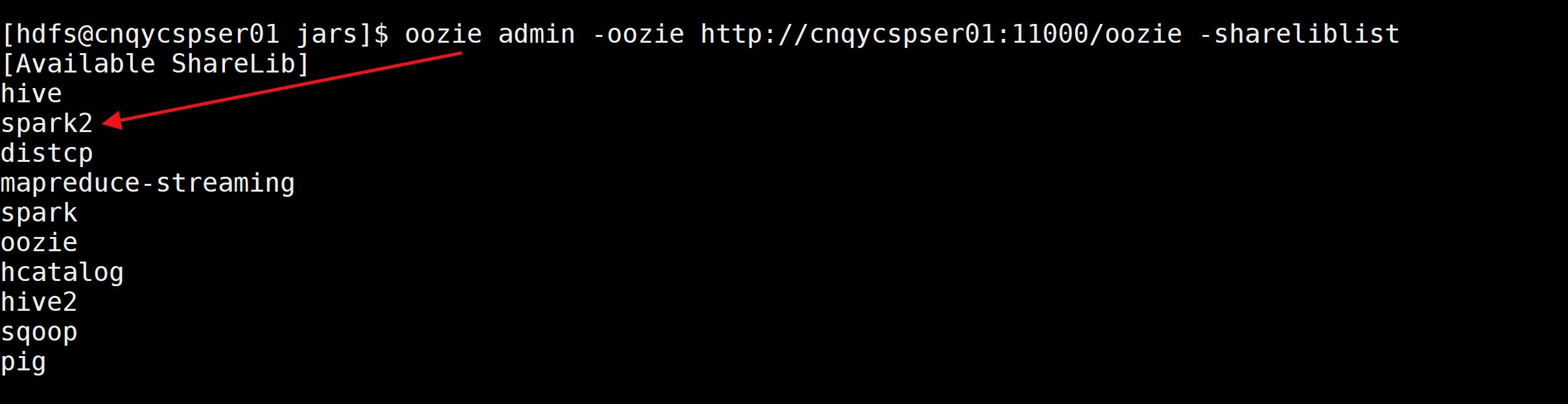
2.在oozie中添加spark2依赖
查看当前Oozie的share-lib共享库HDFS目录(无spark2相关依赖)
oozie admin -oozie http://cnqycspser01:11000/oozie -shareliblist

oozie的共享目录结构
hdfs dfs -ls /user/oozie/share/lib/
hdfs上对应的oozie目录库结构(若无lib_20190717154150目录,需要在/user/oozie/share/lib/下寻找类似结构目录)
hdfs dfs -ls /user/oozie/share/lib/lib_20190717154150/

在Oozie的/user/oozie/share/lib/lib_20170921070424创建spark2目录
hdfs dfs -mkdir /user/oozie/share/lib/lib_20190717154150/spark2
向spark2目录添加spark2的jars和oozie-sharelib-spark*.jar
##提交jar包
hdfs dfs -put /opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/jars/ /user/oozie/share/lib/lib_20190717154150/spark2/
##提交另一批jar包
hdfs dfs -put /opt/cloudera/parcels/CDH/lib/oozie/oozie-sharelib-yarn/lib/spark/oozie-sharelib-spark*.jar /user/oozie/share/lib/lib_20190717154150/spark2/
##最后一批jar包
hdfs dfs -cp /user/oozie/share/lib/lib_20190717154150/spark/oozie-sharelib-spar* /user/oozie/share/lib/lib_20190717154150/spark2/
##查看jar包是否成功提交
hdfs dfs -ls /user/oozie/share/lib/lib_20190717154150/spark2/
修改权限及用户组
hdfs dfs -chown -R oozie:oozie /user/oozie/share/lib/lib_20190717154150/spark2/
hdfs dfs -chmod -R 775 /user/oozie/share/lib/lib_20190717154150/spark2/
更新共享目录并且确认
oozie admin -oozie http://cnbjsjqpclwcdh01:11000/oozie -sharelibupdate
oozie admin -oozie http://cnbjsjqpclwcdh01:11000/oozie -shareliblist
更新确认

展示 (确认spark2相关依赖已经添加)
3.Oozie和Hue界面简介
oozie界面安装
在安装Oozie的节点,执行如下操作;
#1.下载 ext-2.2.
wget -c http://tiny.cloudera.com/oozie-ext-2.2
unzip ext-2.2.zip -d /var/lib/oozie
chown -R oozie:oozie /var/lib/oozie/ext-2.2
修改配置如下:
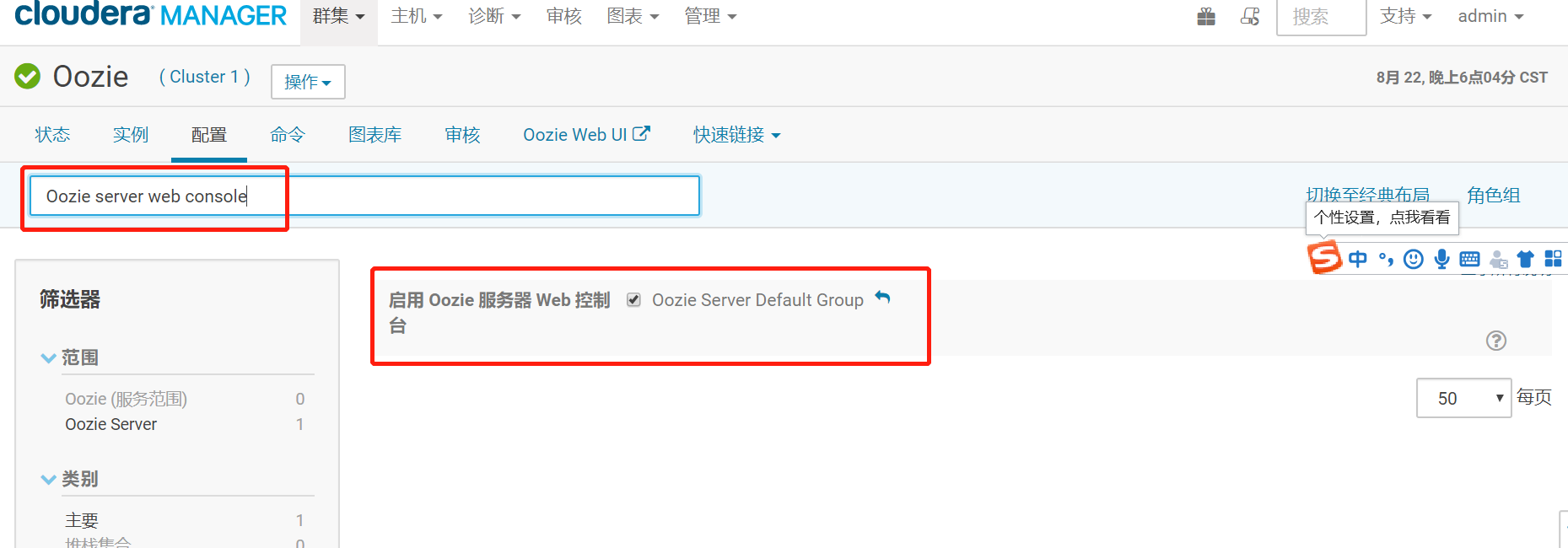
重新部署后,打开Oozie WEB界面
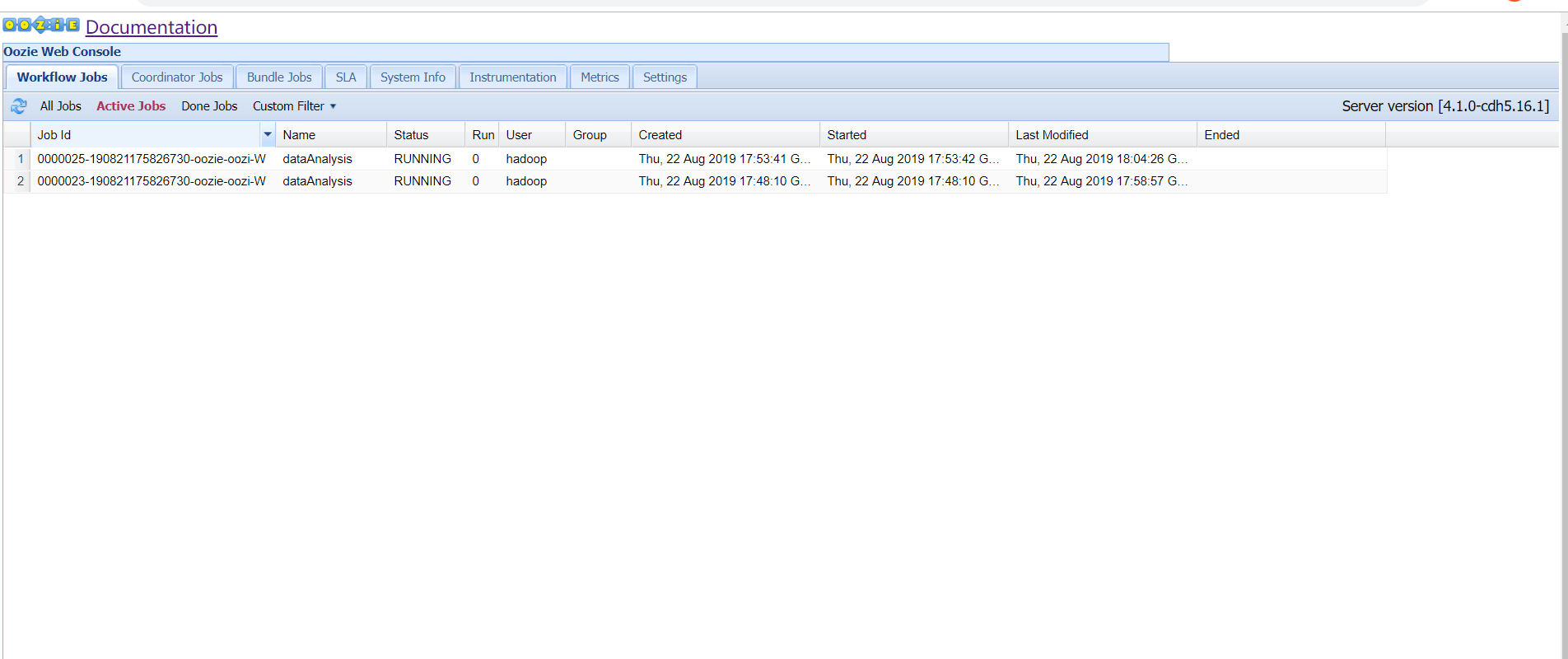
Hue界面简介
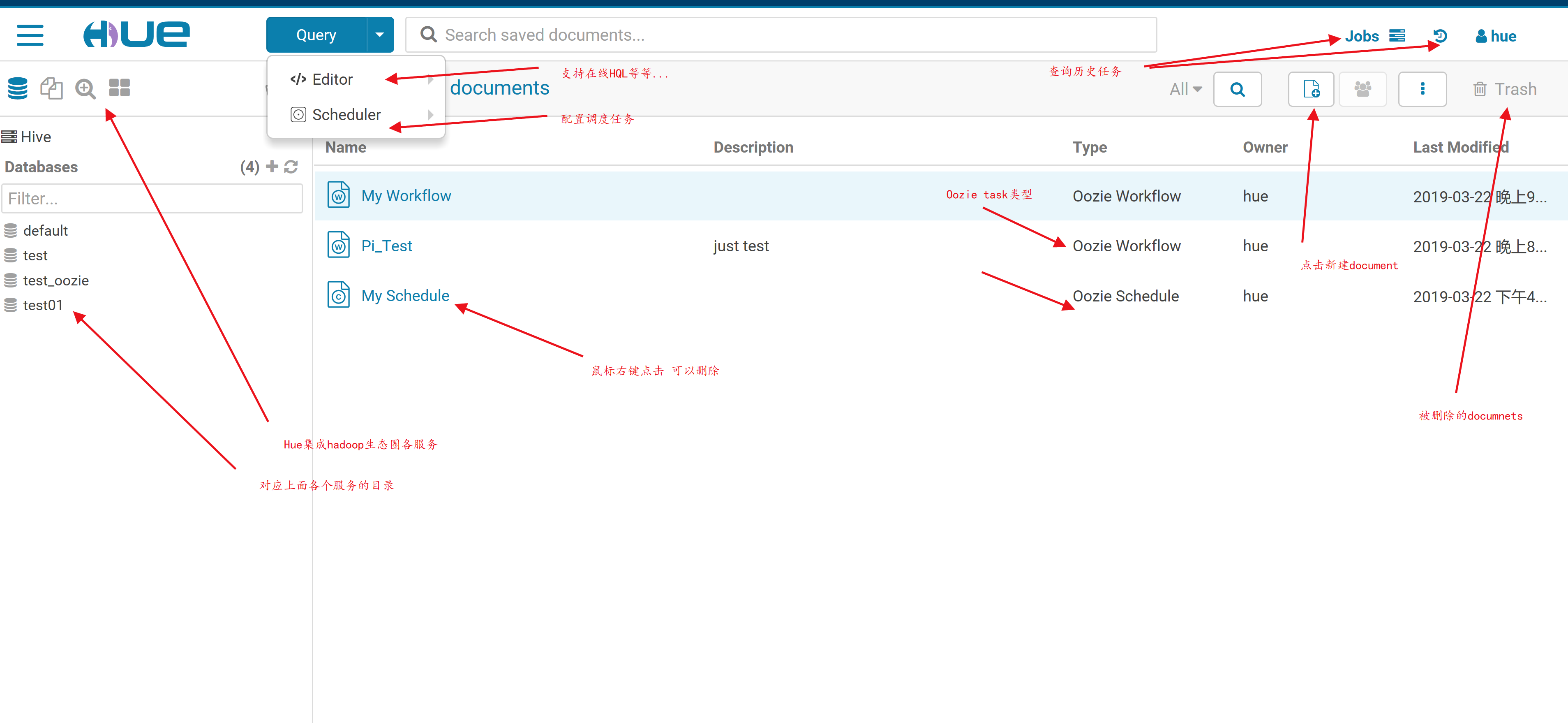
4.Hue编排oozie流程(spark任务)
如何使用Hue创建Spark1和Spark2的Oozie工作流的实现
0.上传测试jar包
hdfs dfs -put /opt/cloudera/parcels/CDH/lib/spark/examples/lib/spark-examples-1.6.0-cdh5.16.1-hadoop2.6.0-cdh5.16.1.jar /user/hue/test/
1.添加一个新的workflow

2.创建一个spark任务
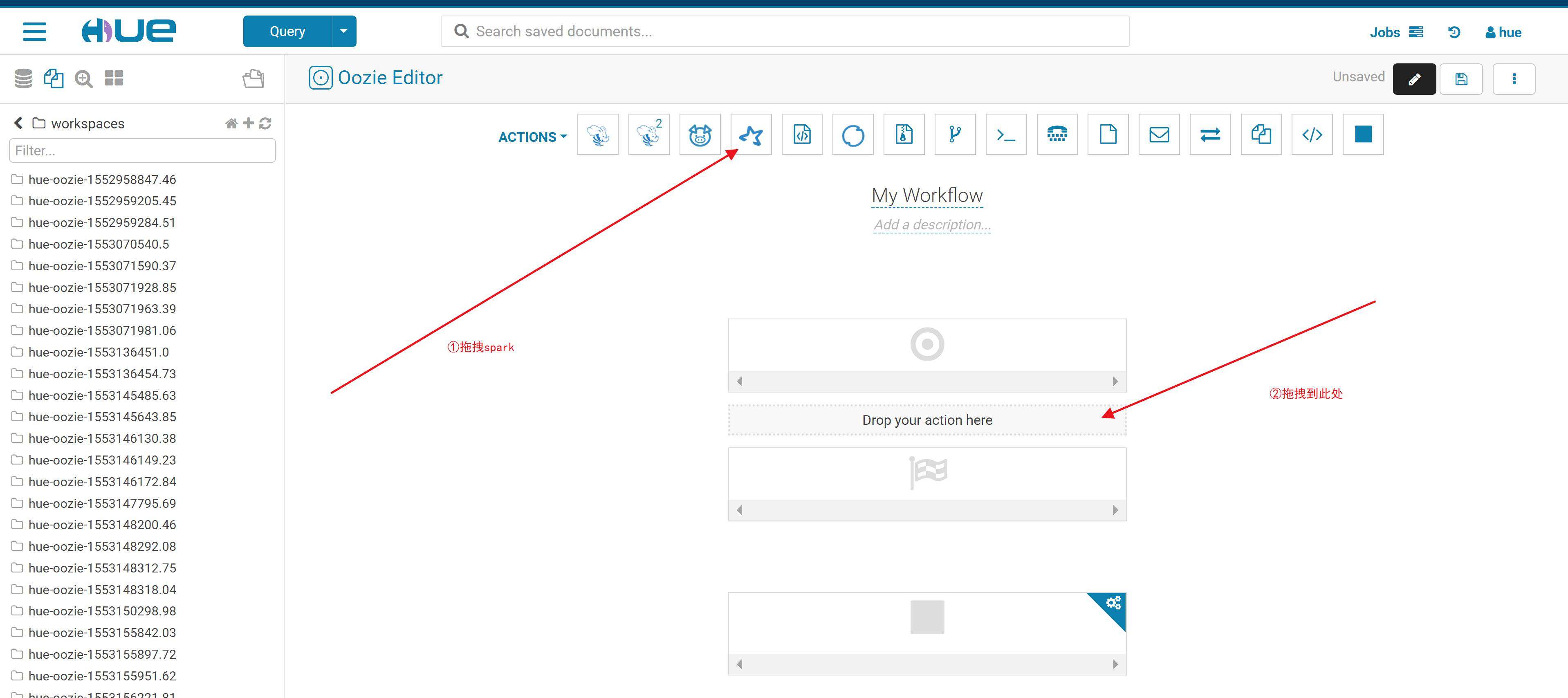
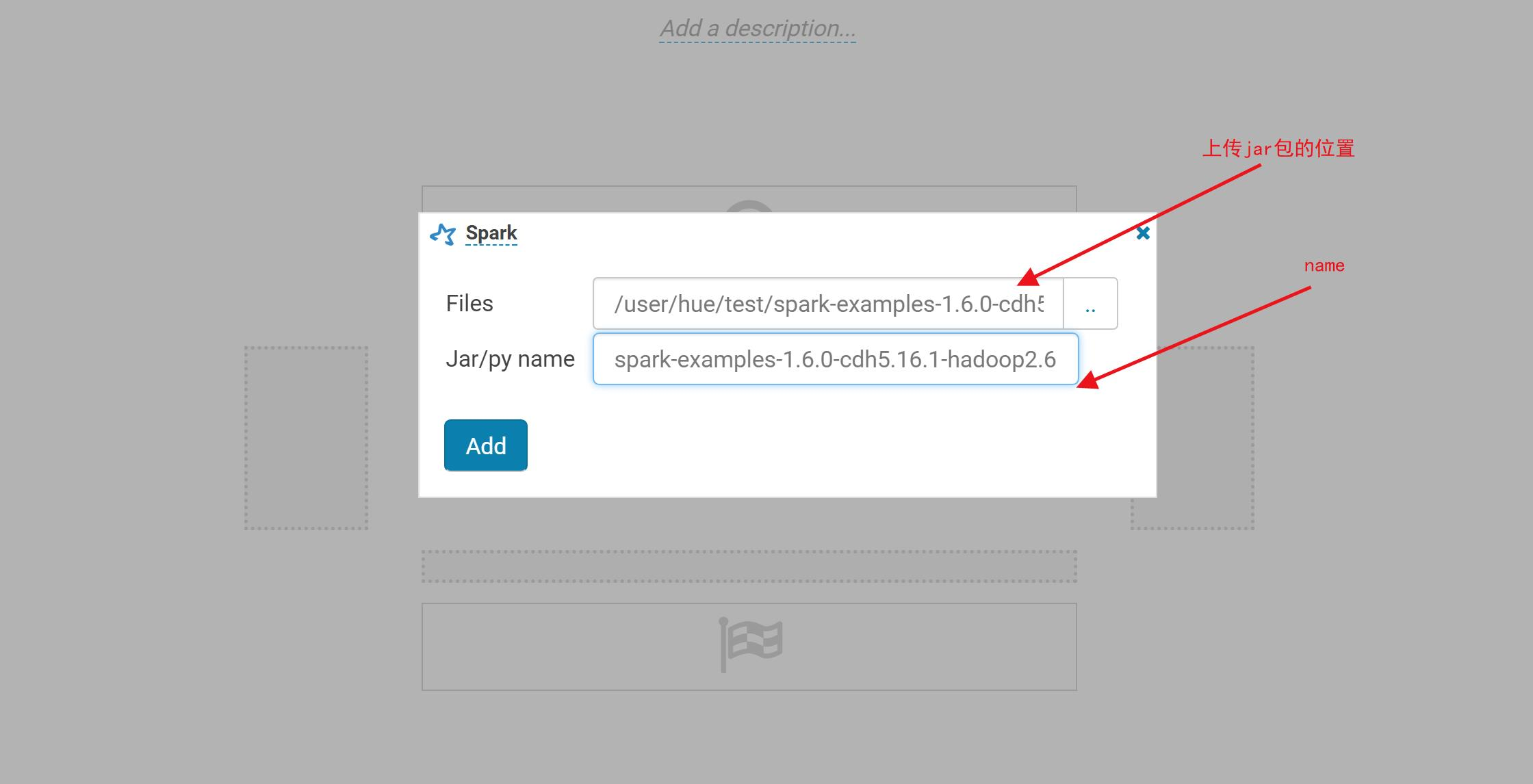
3.确认上传jar包位置(HDFS),确认jar包name(注意一定要带.jar后缀,否则后面无法识别主类)。
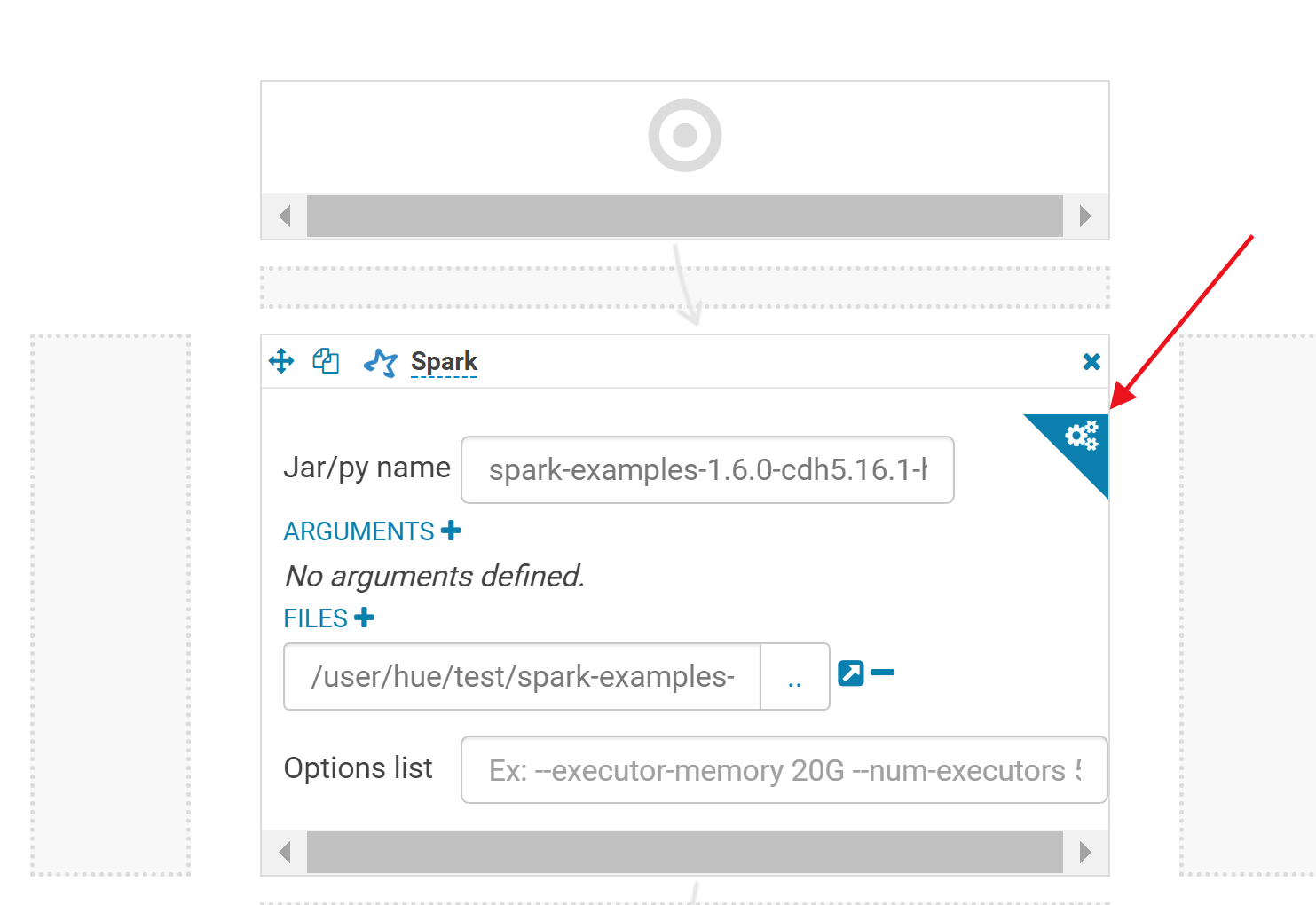
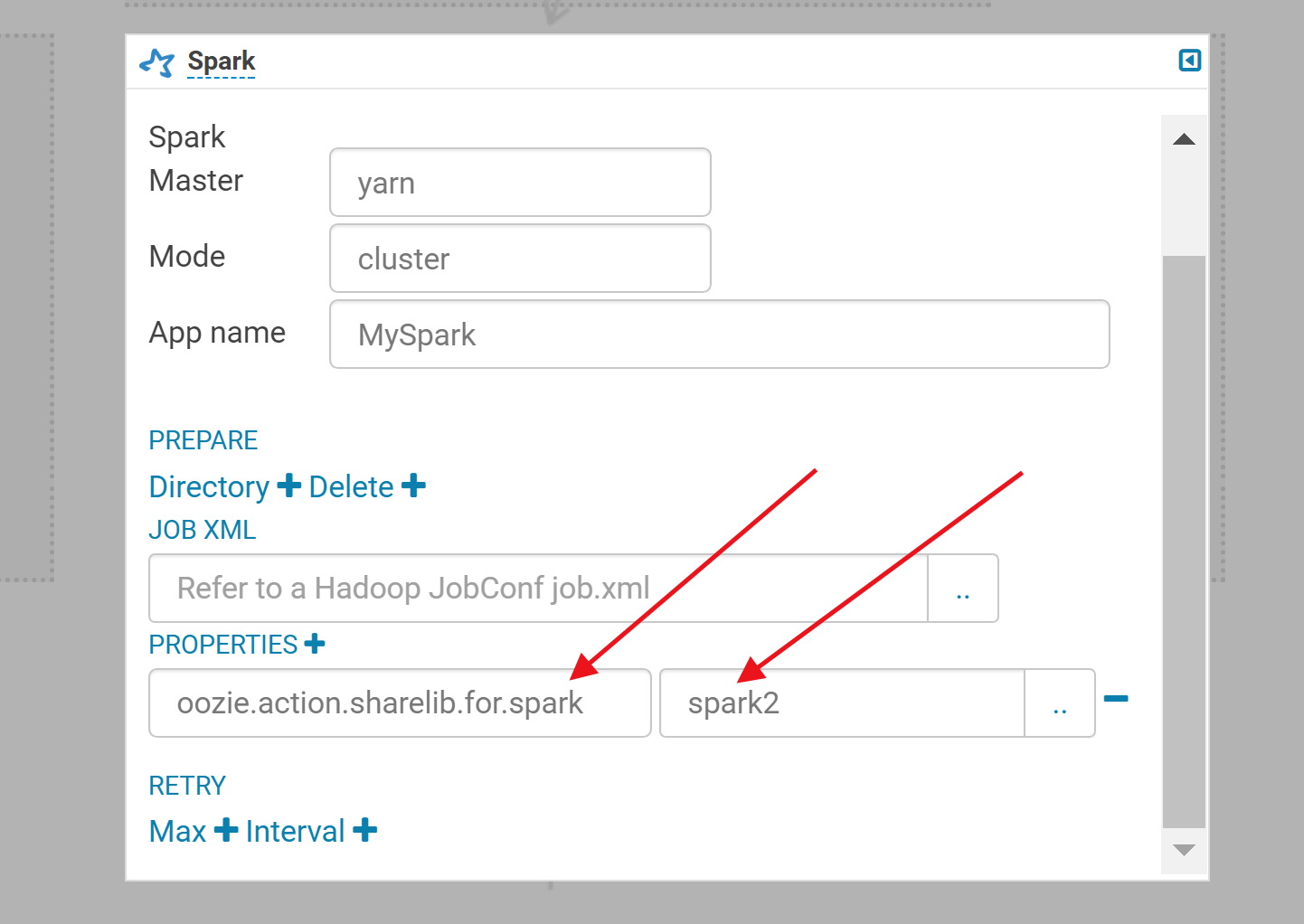
4.修改任务的依赖环境为spark2,否则默认为spark1
5.添加一些其他任务
6.流程编排
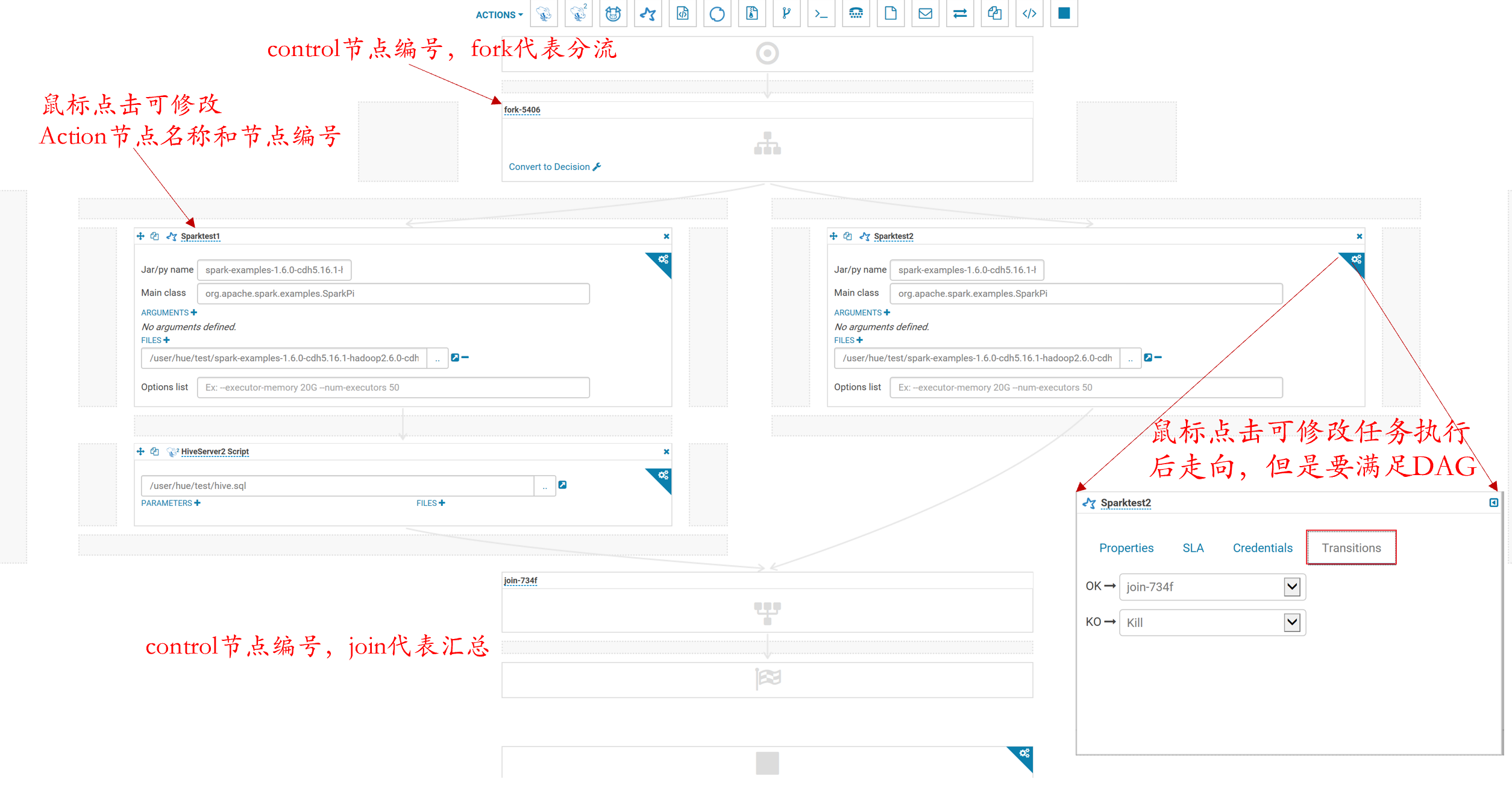
7.点击保存

8.提交运行

9.运行监控
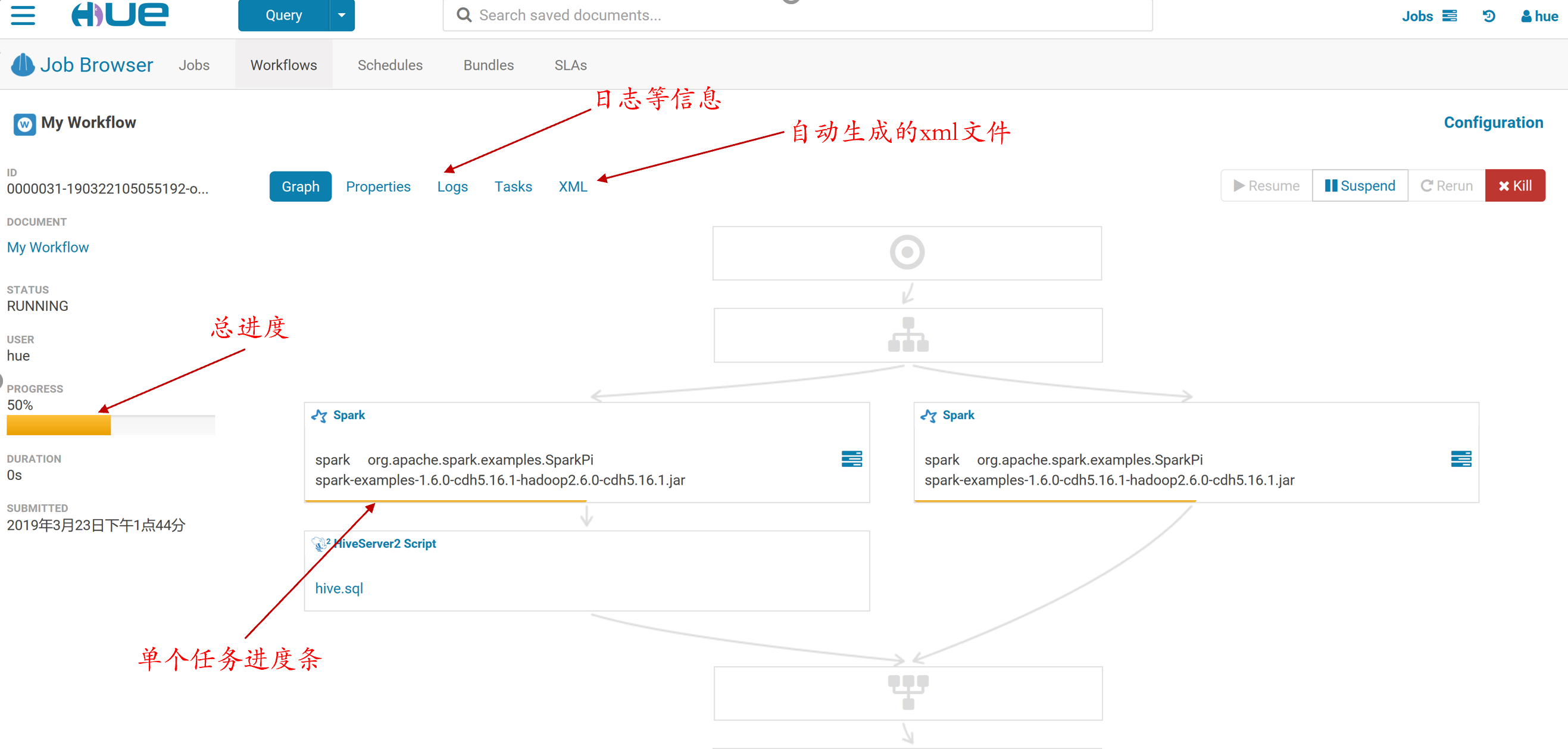
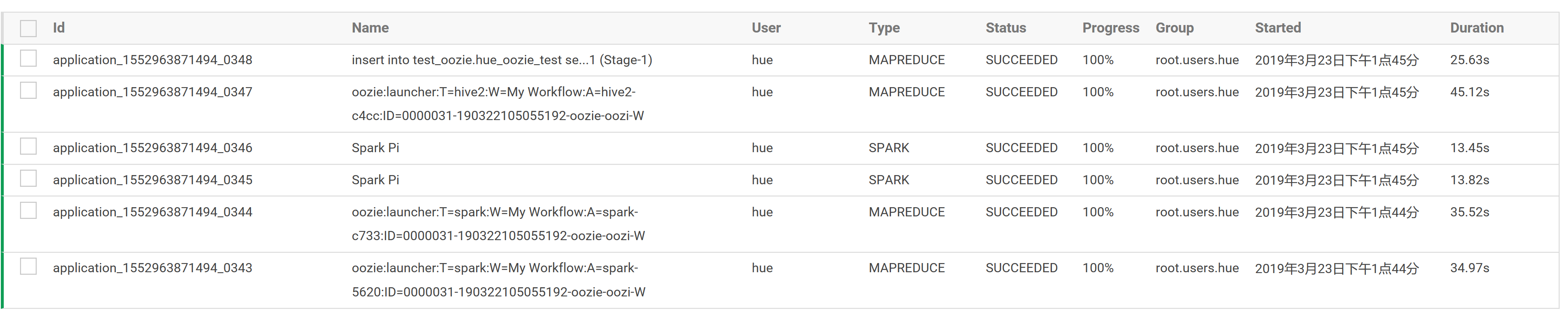
10.每个任务提交时都会伴随着一个只有map任务的oozie mapreduce.
使用shell的方式实现Hue创建Spark2的Oozie工作流
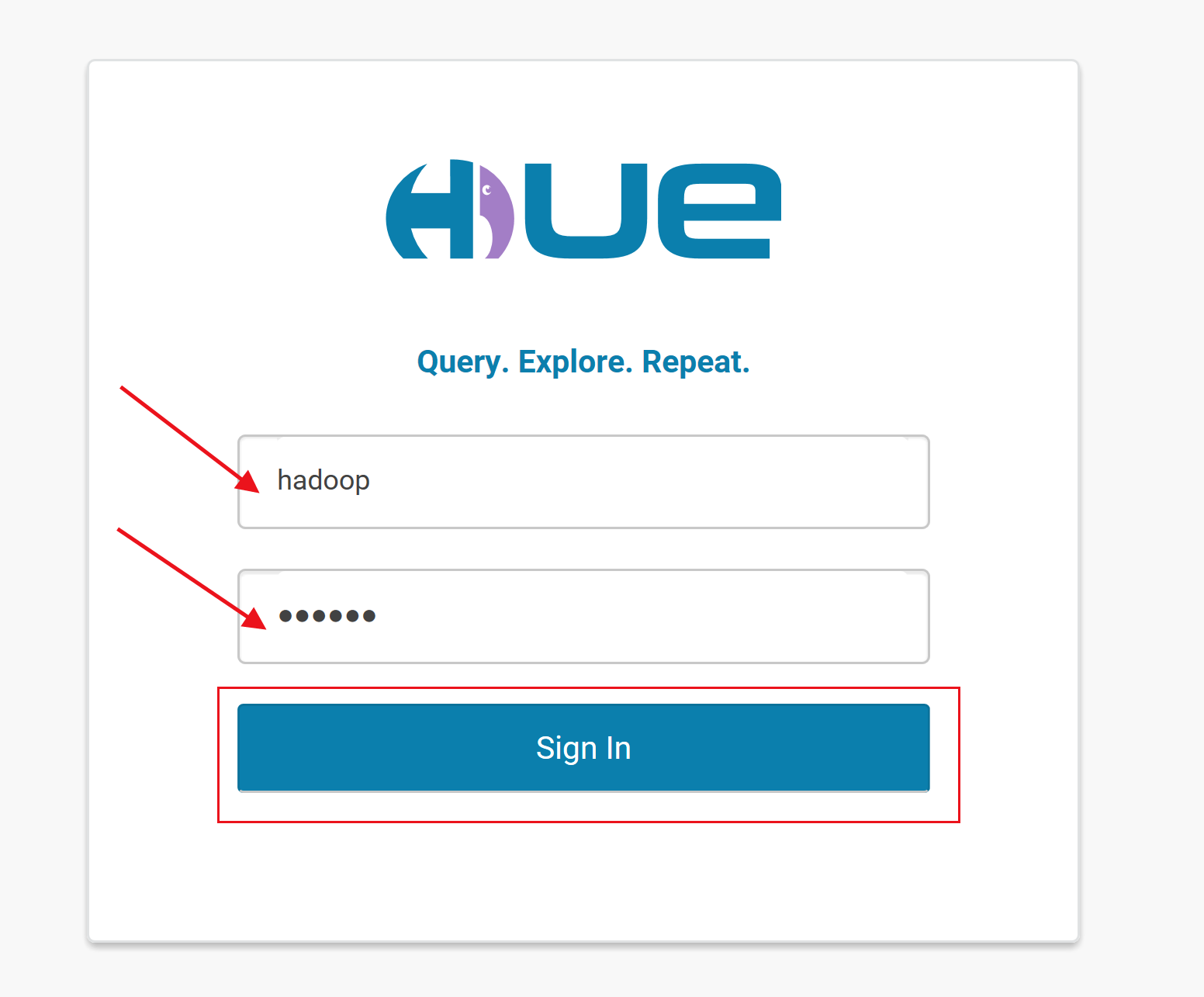
1.以hadoop用户登陆Hue。填写账号密码后,点击登陆。
账号:hadoop
密码:hadoop
2.创建一个workflow
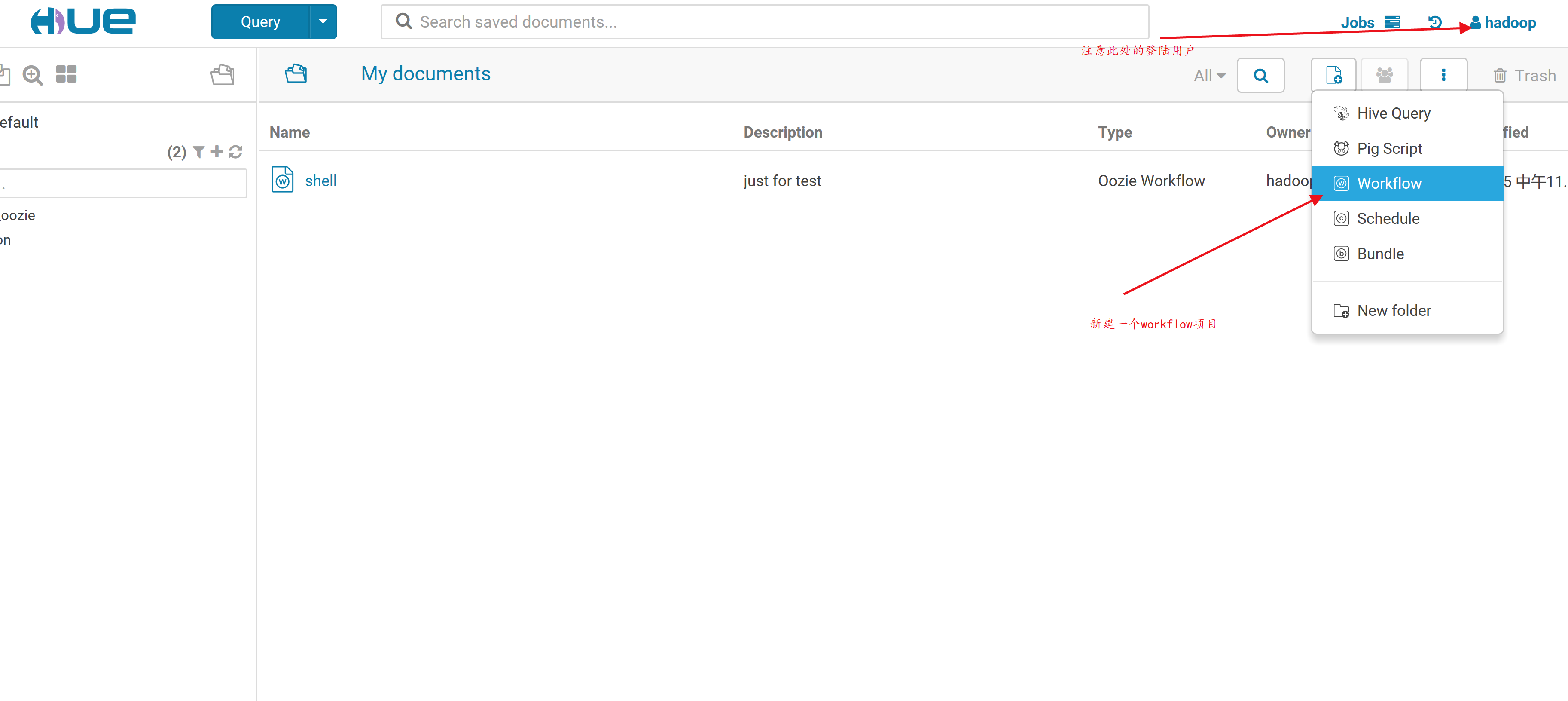
3.修改workflow等配置
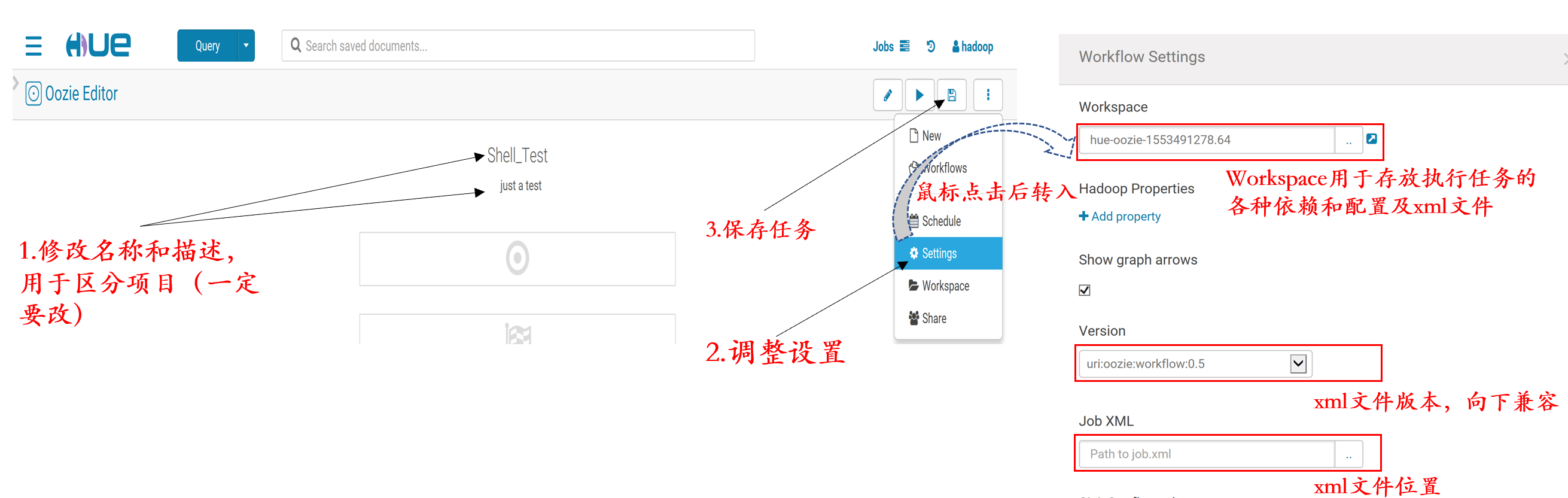
4.在hdfs:///.../hue-oozie-1553491278.64/目录下保存着运行任务所需要的所有配置(以之前运行过的一个workflow的gon工作目录为例子),各个文件详情可参见附录
hdfs dfs -ls /user/hue/oozie/workspaces/hue-oozie-1553481337.07/

5.创建一个执行脚本,并且上传到hdfs
vim sparkJob.sh
hdfs dfs -put sparkJob.sh /user/hue/oozie/workspaces/hue-oozie-1553491278.64/lib/
脚本内容如下:
#!/bin/bash
source /etc/profile
source /root/.bash_profile
source /root/.bashrc
export HADOOP_USER_NAME=hadoop
/opt/cloudera/parcels/SPARK2/bin/spark2-submit --master yarn\
--num-executors 4 --driver-memory 1g\
--driver-cores 1 --executor-memory 1g\
--executor-cores 2\
--class org.apache.spark.examples.SparkPi /tmp/spark-examples_2.11-2.3.0.cloudera4.jar
7.选取调用脚本,确认配置,而后提交任务
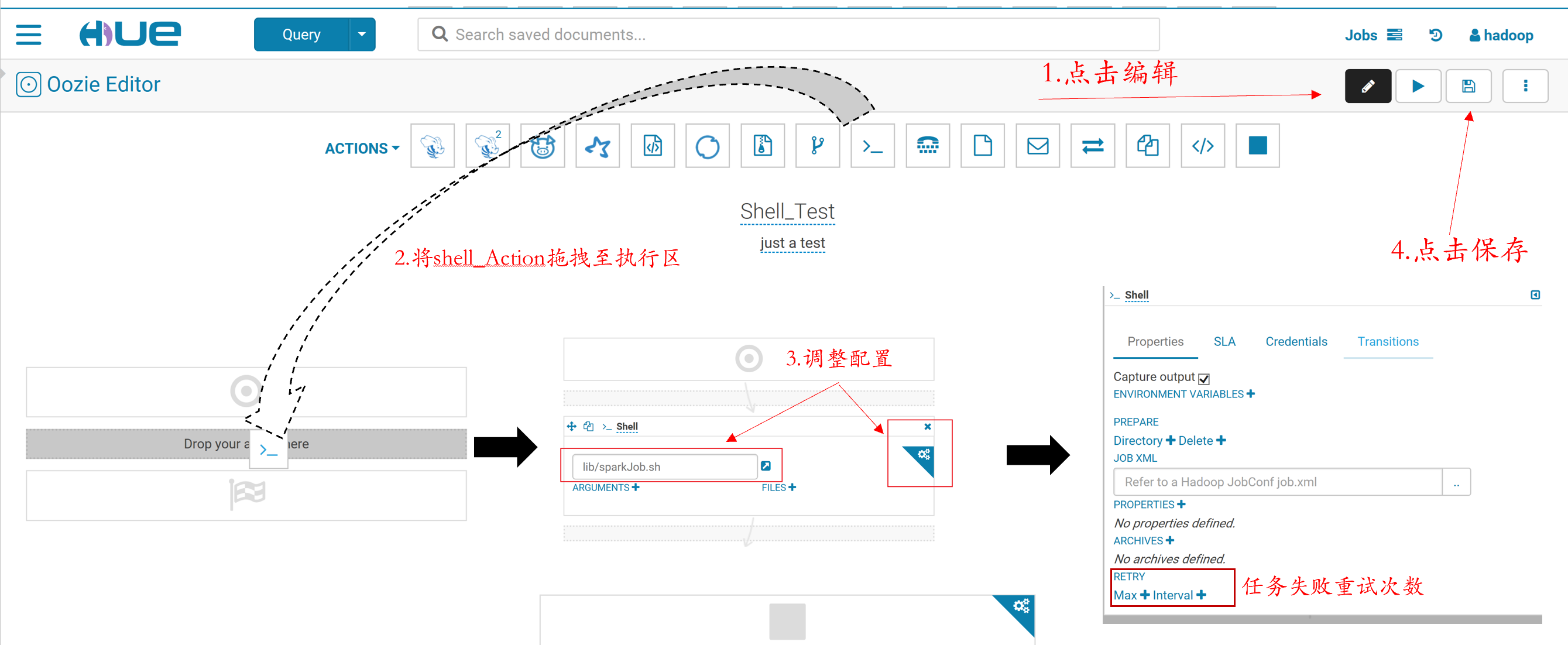
8.执行成功!
ps:
通过使用Shell脚本的方式向集群提交Spark2的作业,注意在shell脚本中指定的spark-examples_2.11-2.1.0.cloudera1.jar包,要确保在集群的所有节点相应的目录存在,否则会执行失败。目录访问权限问题也会导致执行失败。
5创建Spark2的调度工作流
1.进入schedule

2.修改时间和时区

3.保存后可提交

6hue+hive+oozie
由hue的hive查询创建一个hive的workflow
HUE主界面,依次点击
Query -> Editor -> Hive,如下:
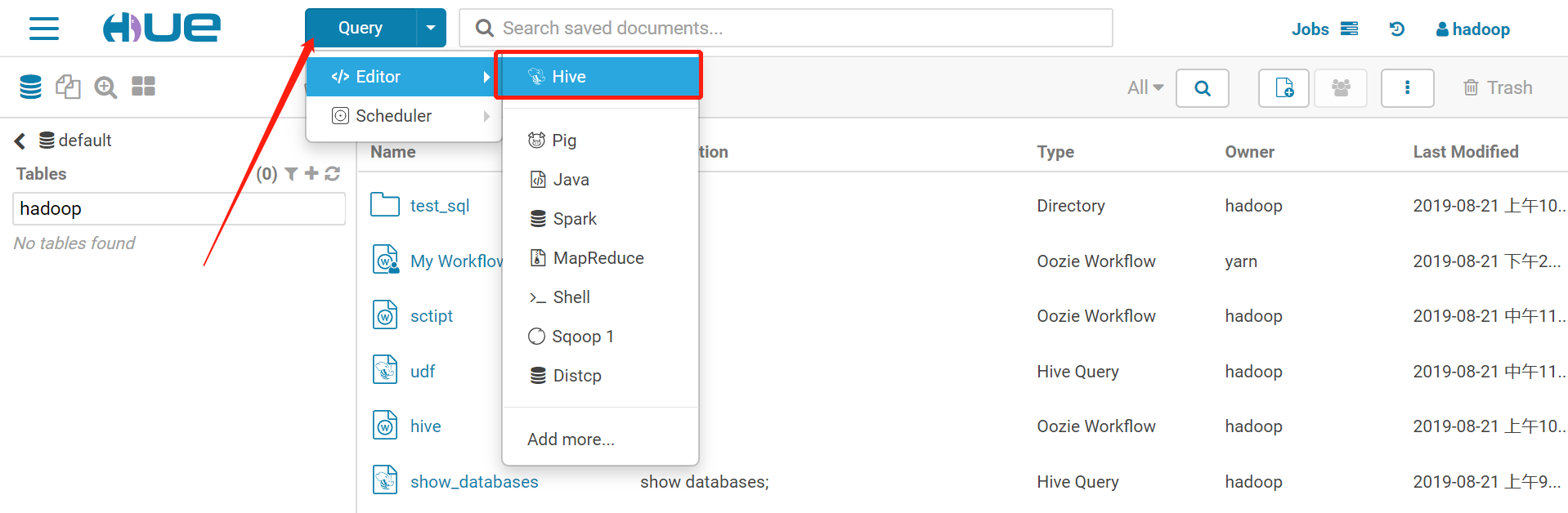
创建一个新的查询语句
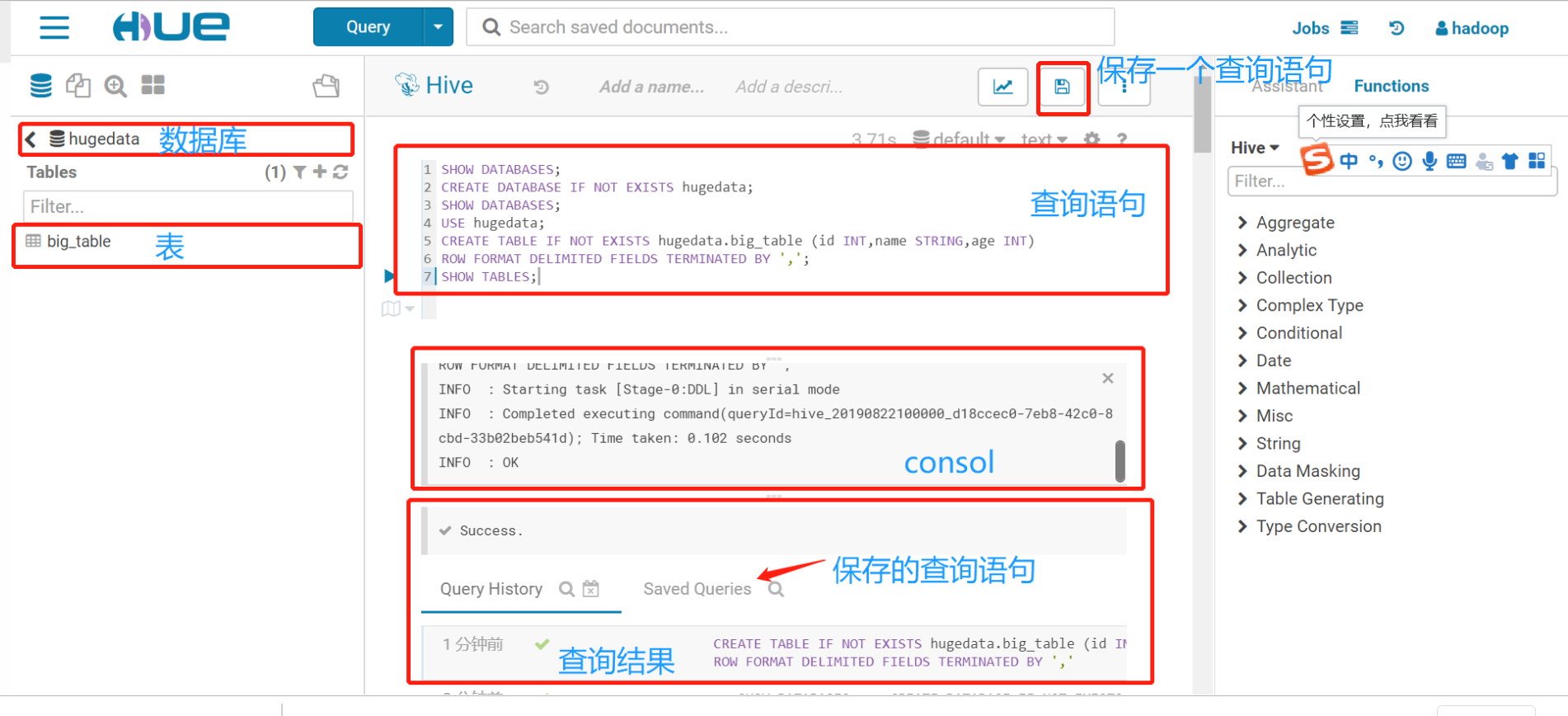
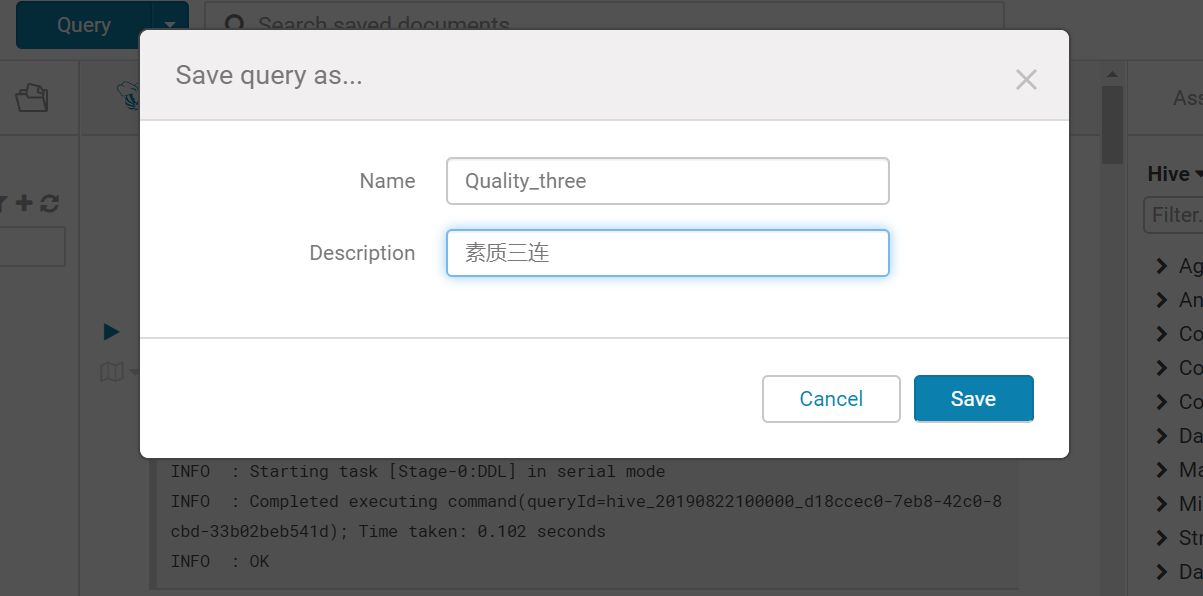
点击保存,为查询创建一个名字,及描述
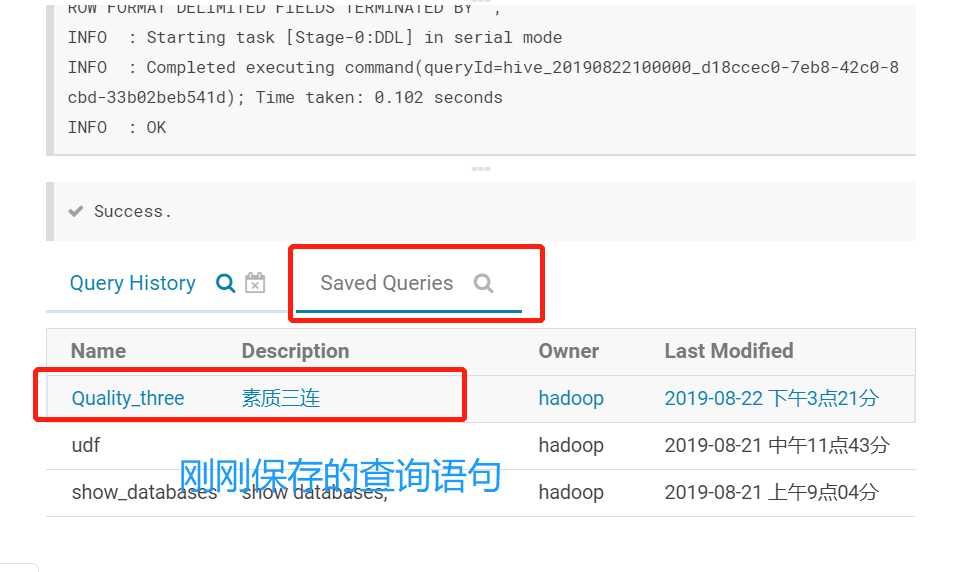
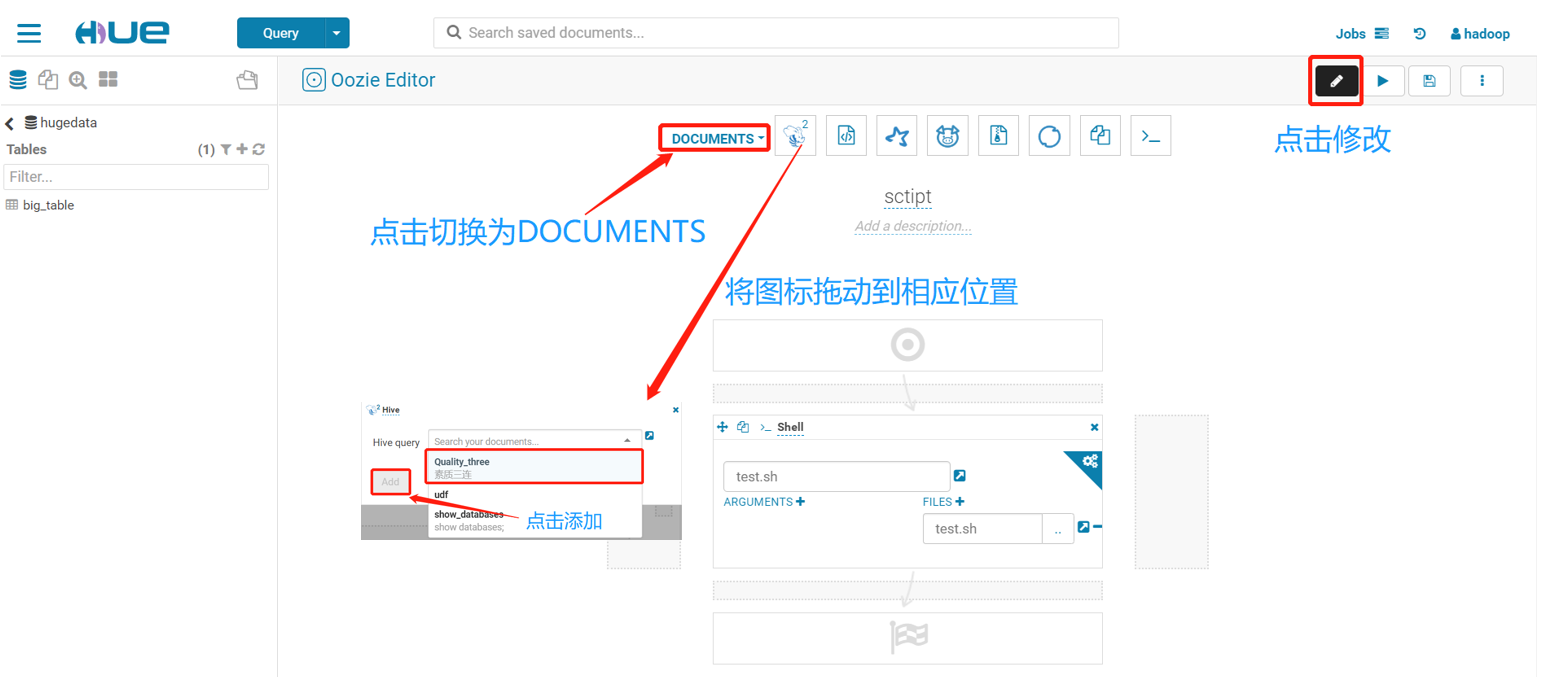
使用保存的查询语句成为一个工作流
使用hiveserver2脚本调度的workflow
使用hive脚本调度的workflow
使用yarn用户登录(账号:yarn,密码:yarn)

修改yarn的配置
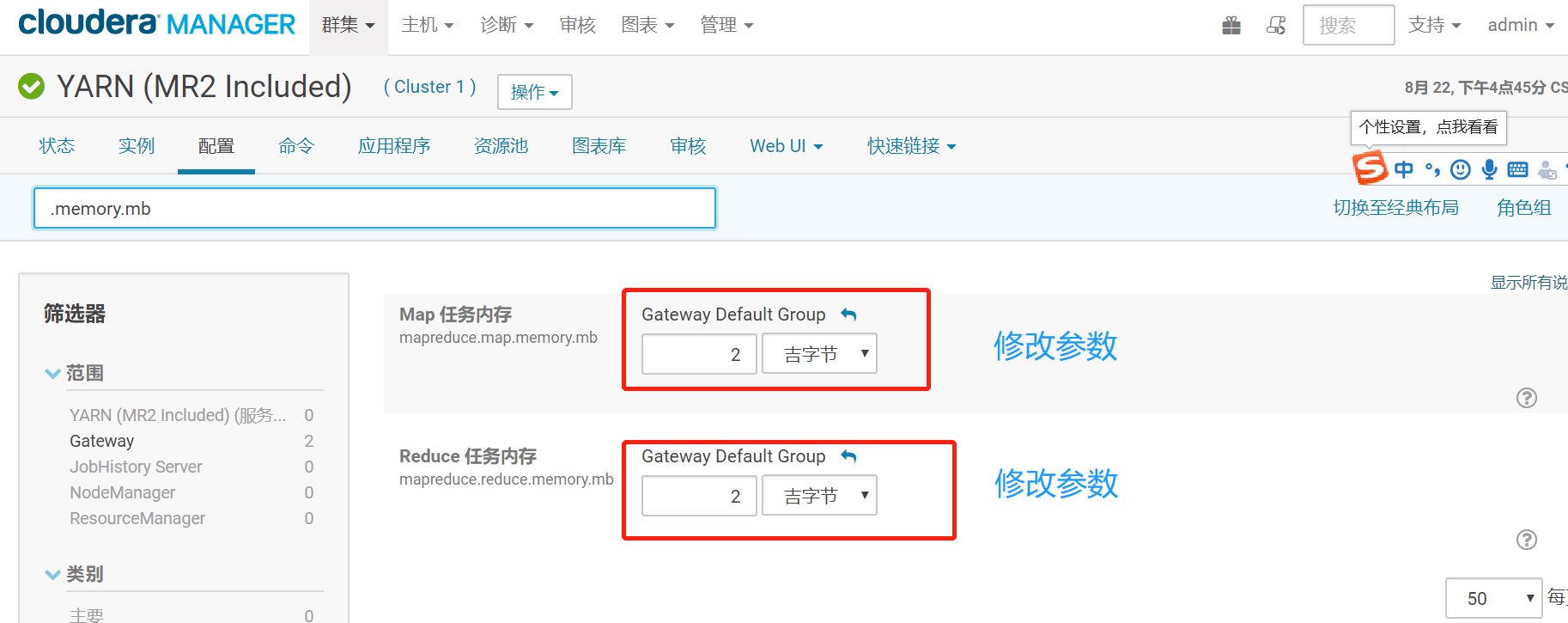
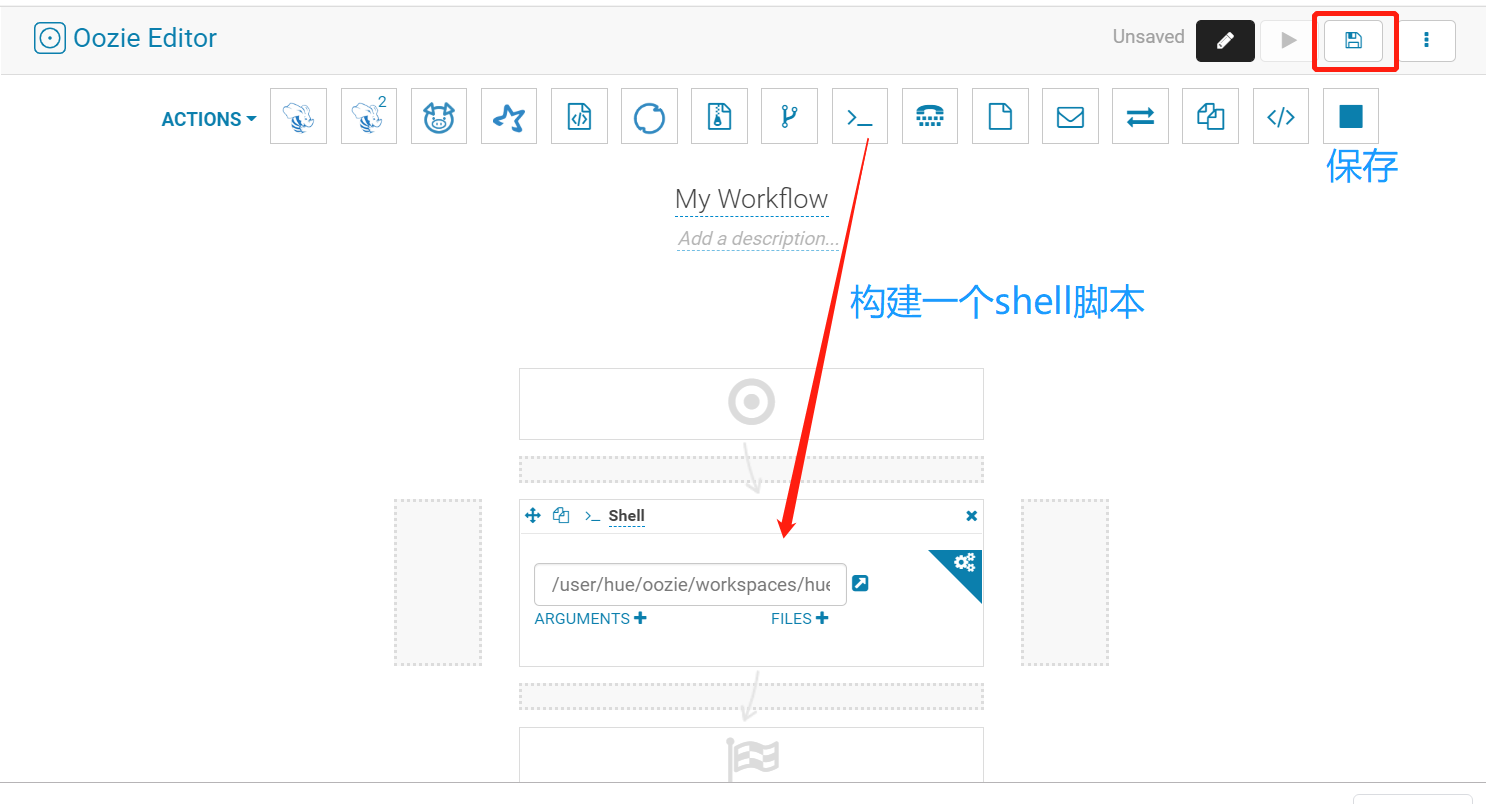
编辑一个shell脚本
创建工作
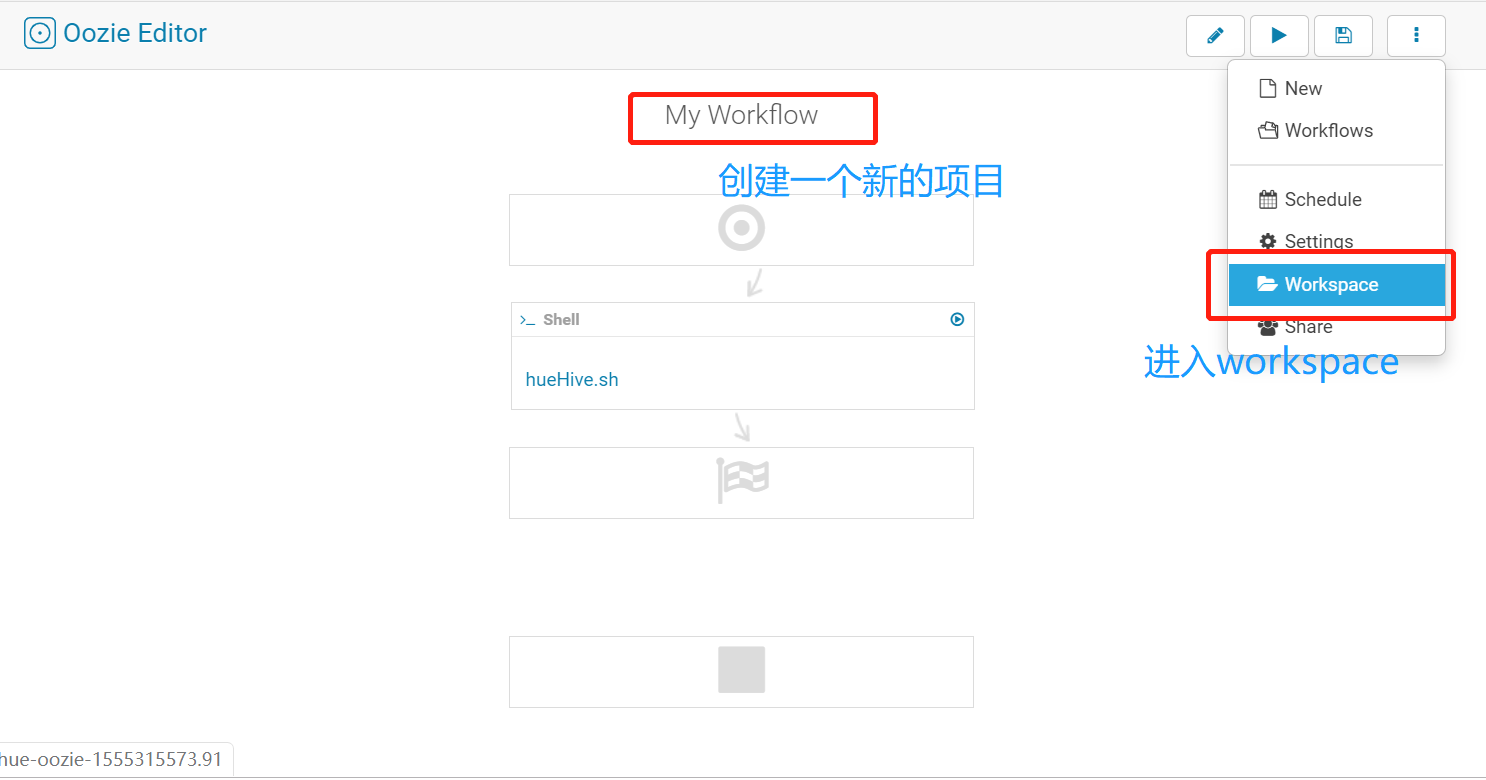
创建脚本
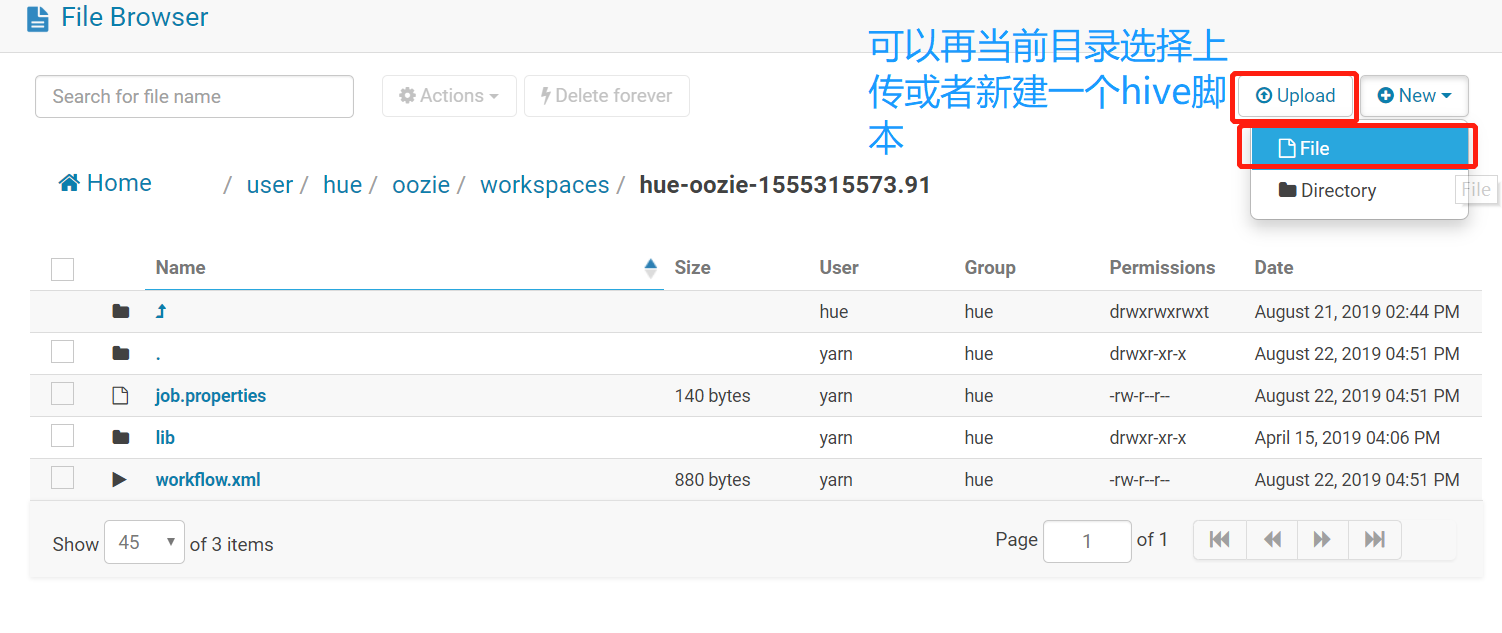
创建内容
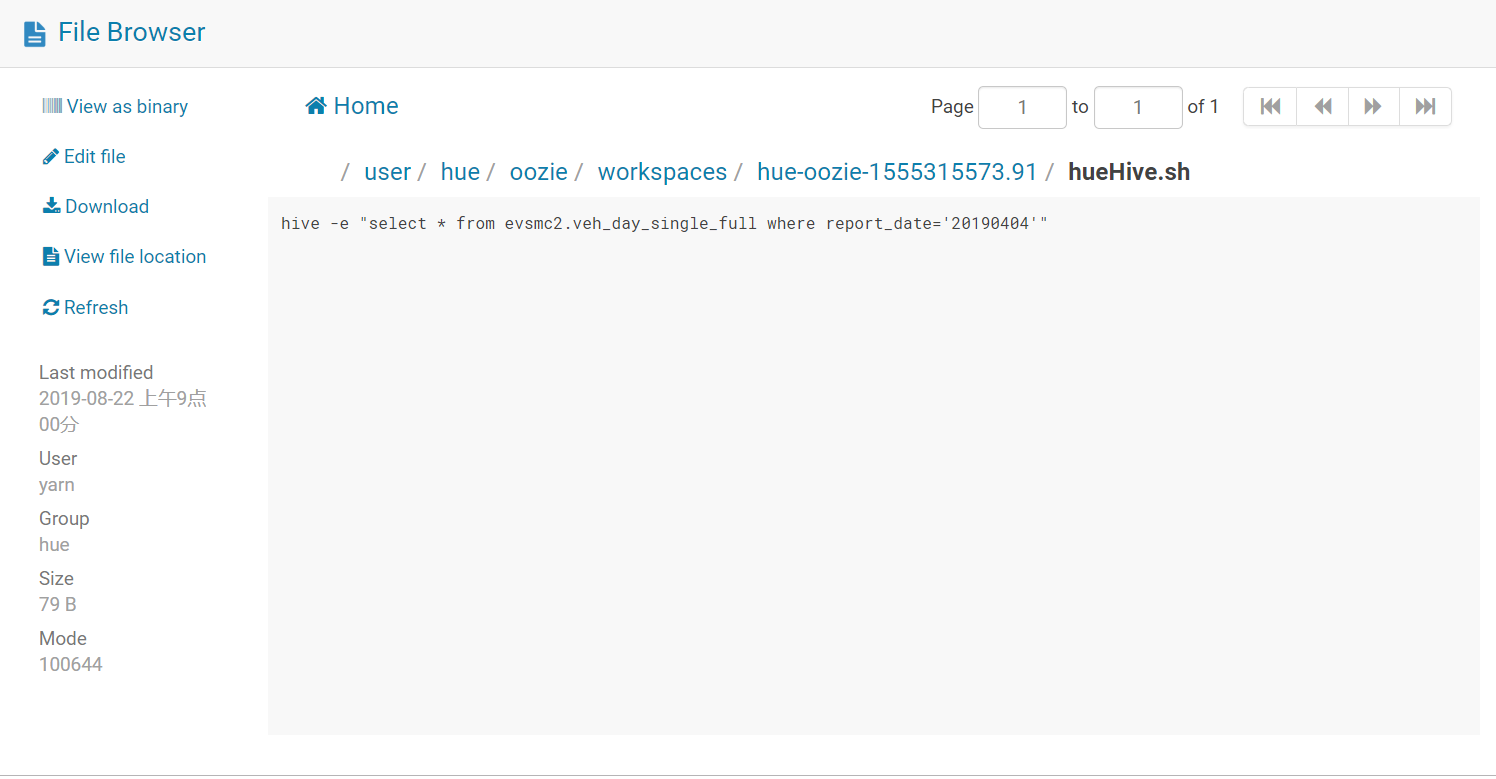
hueHive.sh
hive -e "select * from evsmc2.veh_day_single_full where report_date='20190404'"
提交任务
运行
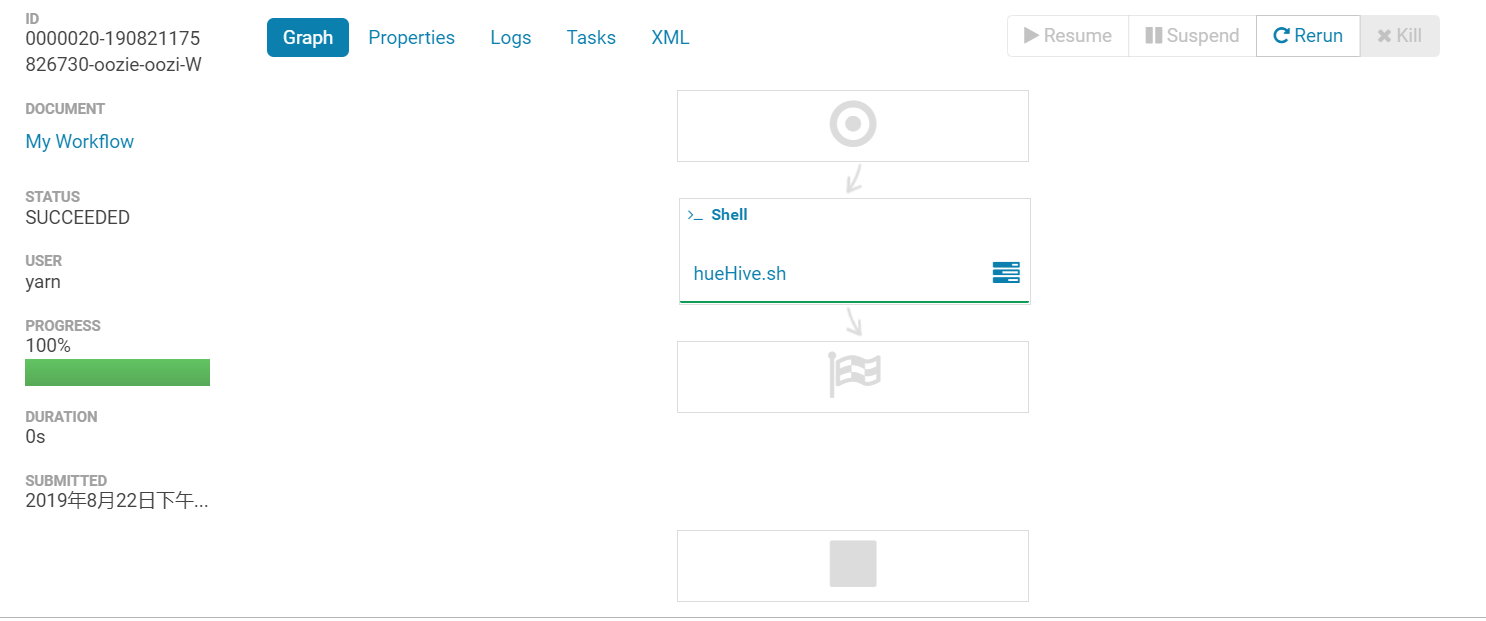
问题汇总:
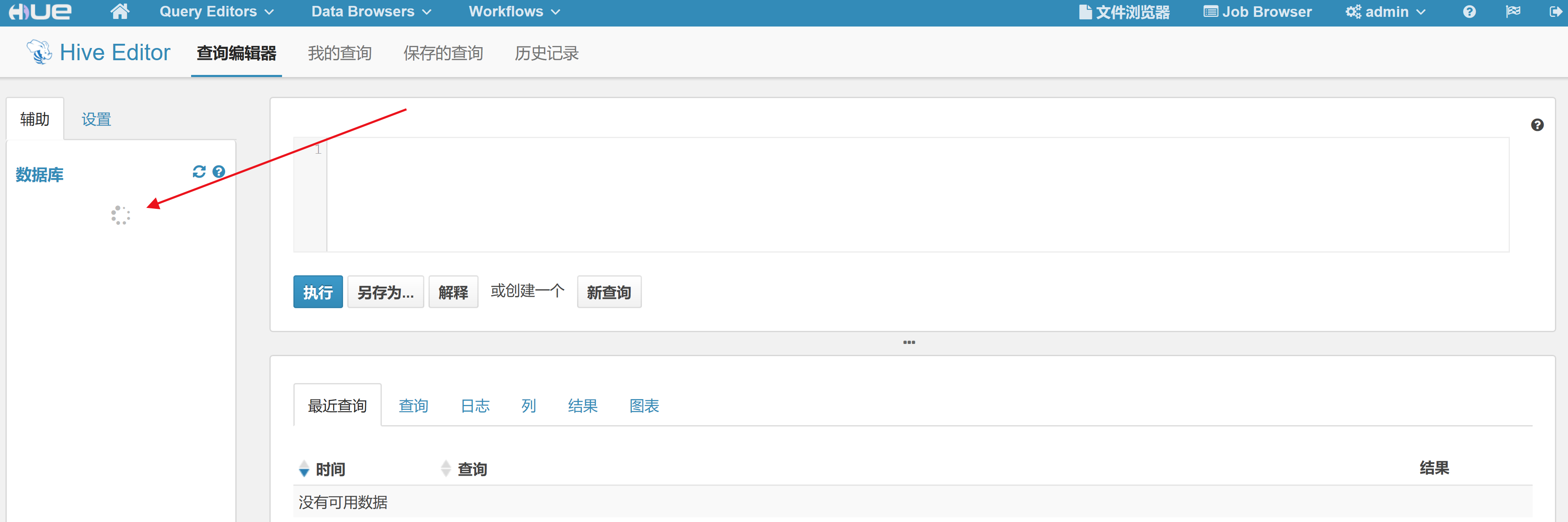
1.HDFS和HiveServer2的thriftserver问题

Hue: HDFS Web 界面角色问题:
HUE的使用需要添加的角色实例
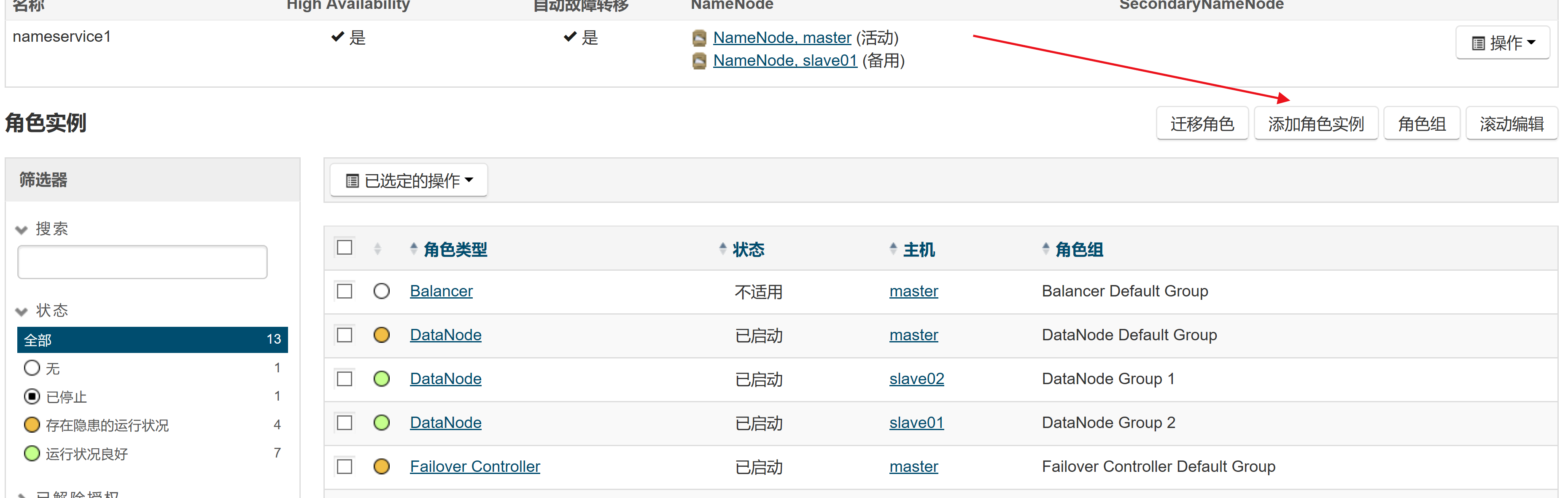
在HDFS的namenode系欸但添加HttpFS角色实例

修改配置

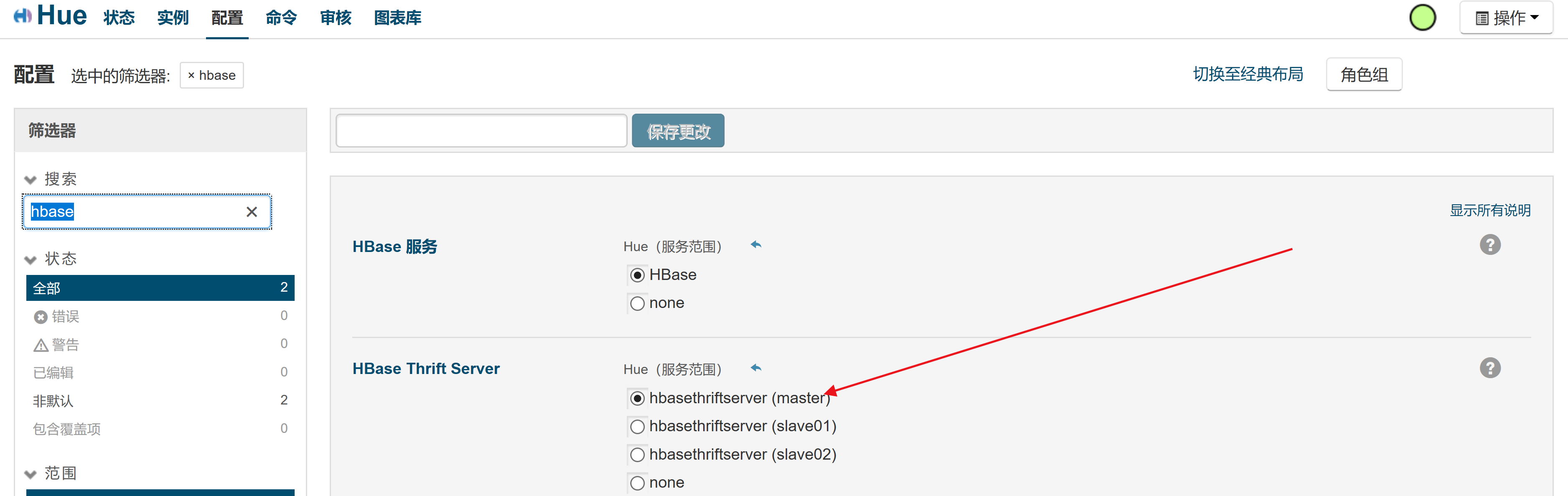
HBase Thrift Server问题:
选择添加实例

添加HBase Thrift Server角色实例
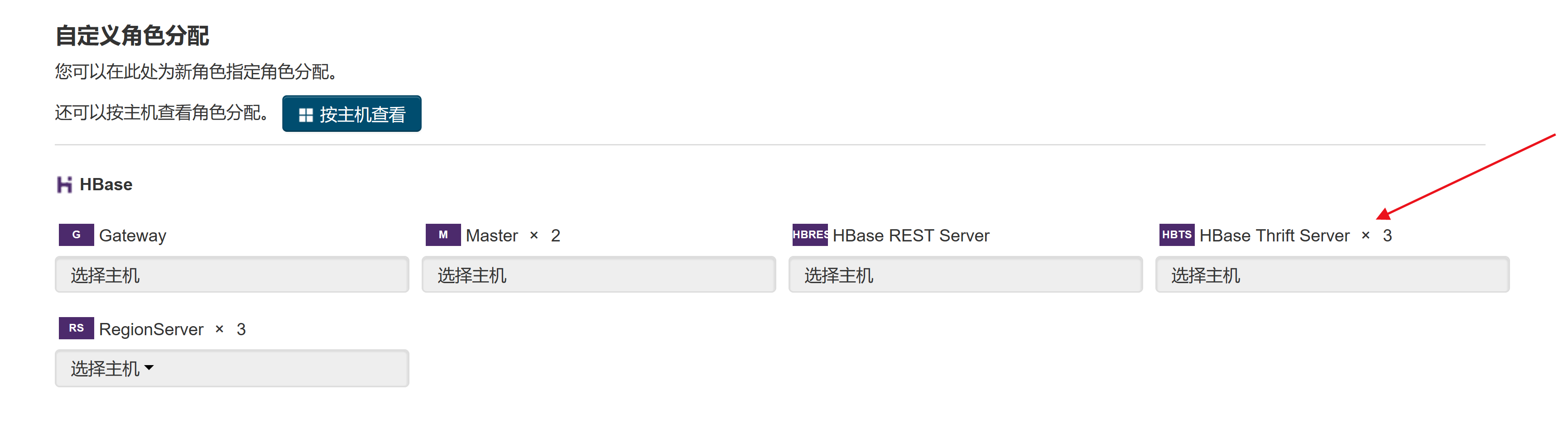
在hue中添加配置
连接hiveserver2失败
oozie
hive -e 'select * from test.spark'
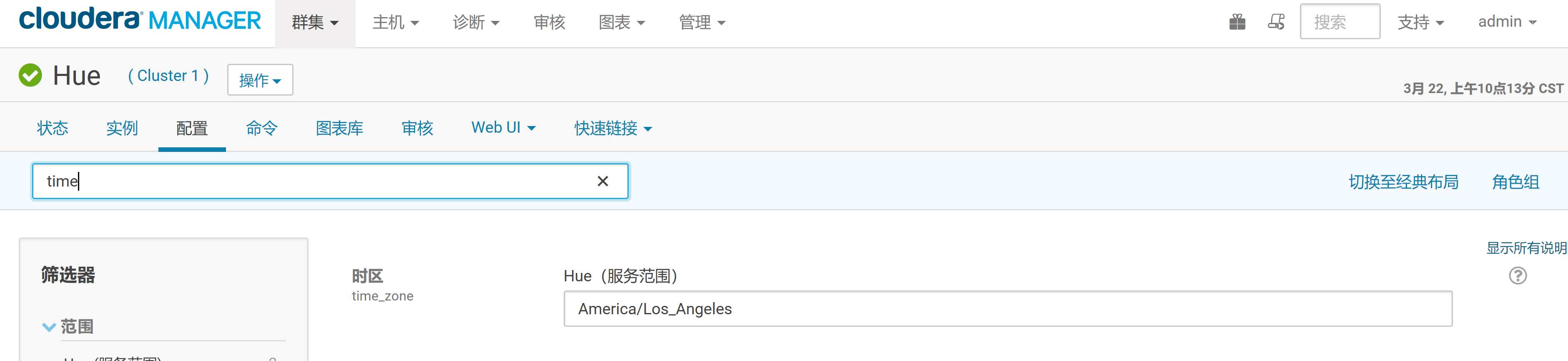
2.Oozie和Hue的时区统一问题
ps:因为Hue在CM中默认配置的是美国洛杉矶时间,需要单独为Hue服务进行修改时区。
1.登录CM,选择Hue服务,并点击配置搜索“time”
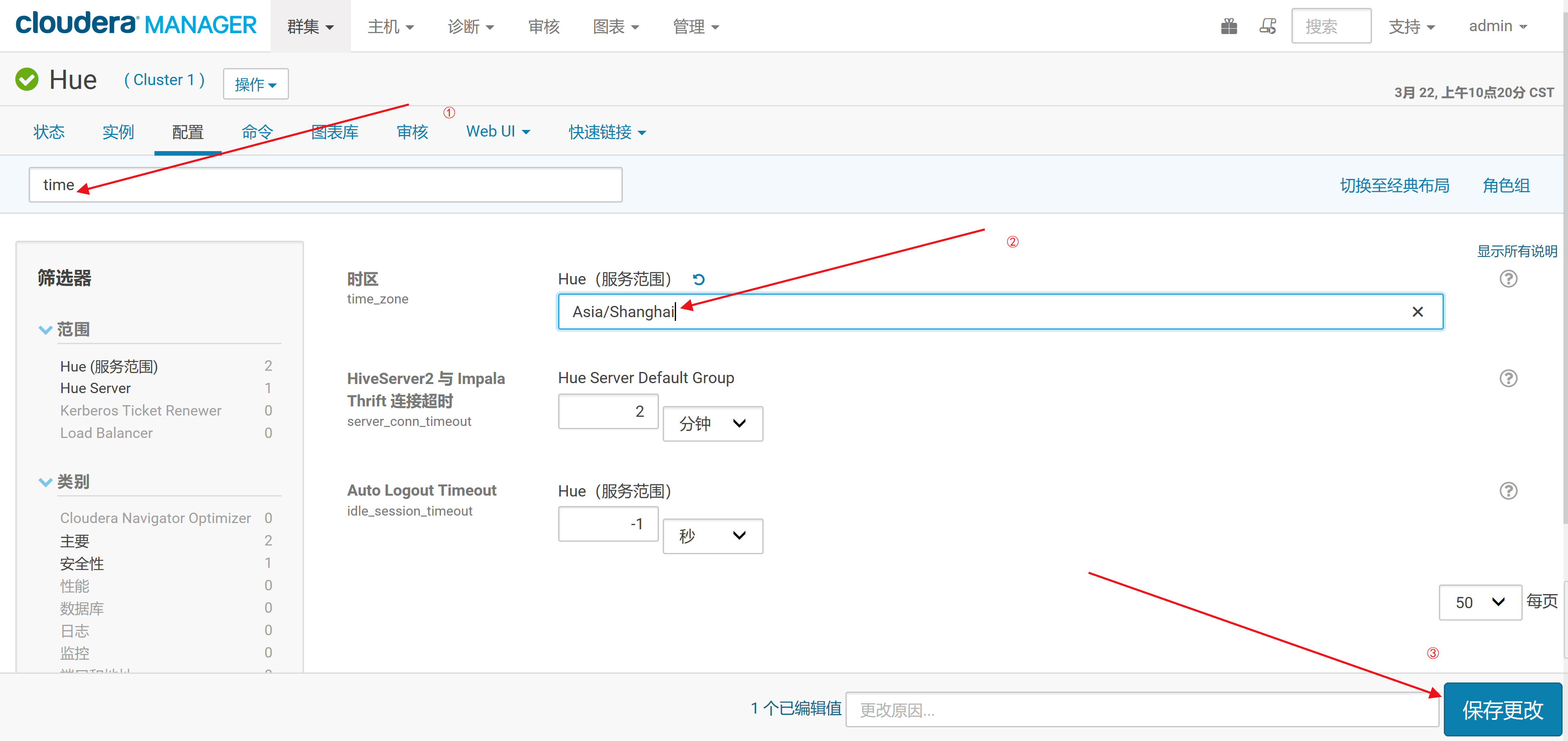
2.将时区配置项由默认的“America/Los_Angeles”改为“Asia/Shanghai”,保存配置。
3.重启Hue服务
4.修改Oozie时区,1.登录Cloudera Manager,进入Ooize服务的配置界面搜索“oozie-site.xml”,添加如下内容
<property>
<name>oozie.processing.timezone</name>
<value>GMT+0800</value>
</property>
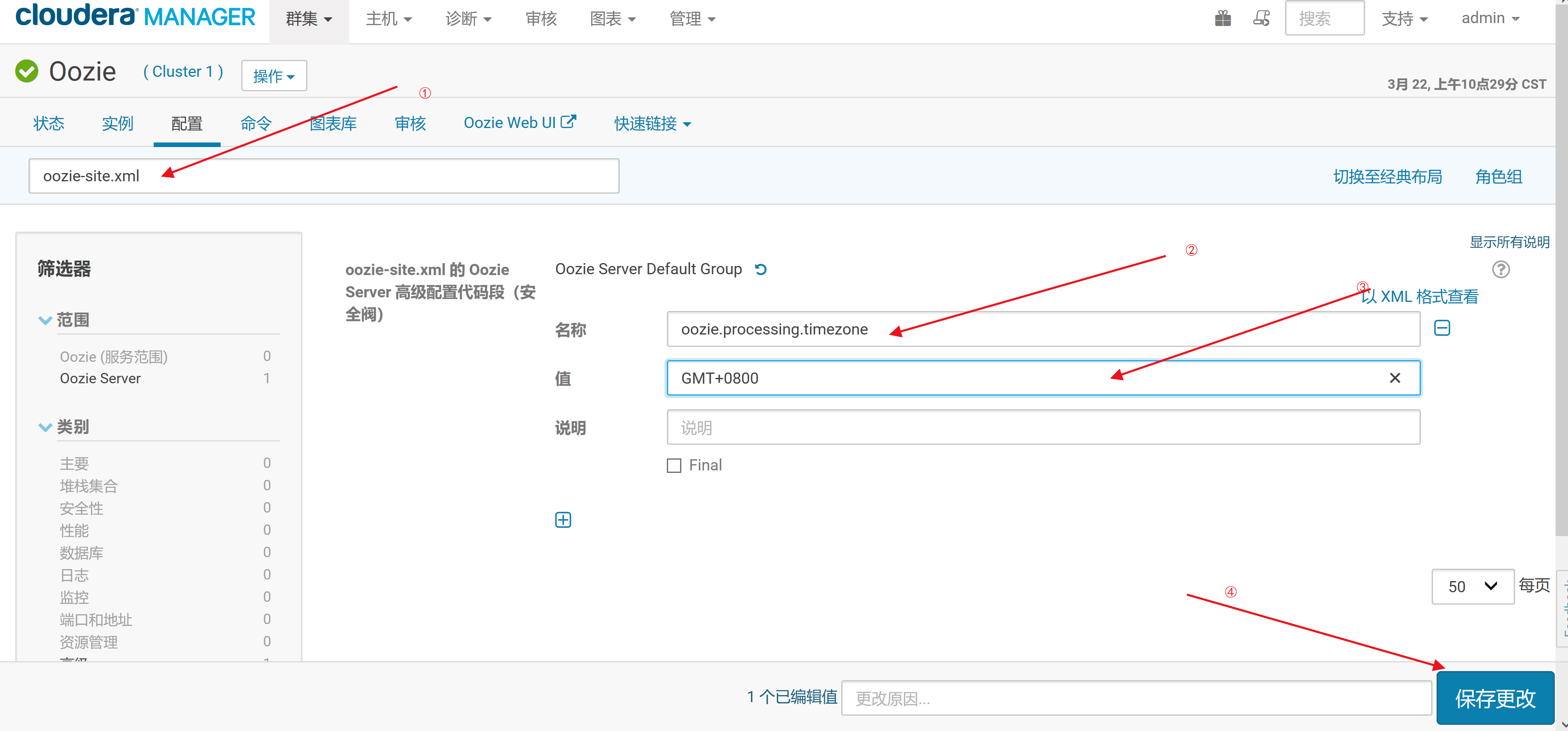
5.完成后保存并重启Oozie服务。
附录
1.job.properties 文件详情:
hdfs dfs -get /user/hue/oozie/workspaces/hue-oozie-1553481337.07/job.properties
cat job.properties
oozie.use.system.libpath=True
send_email=False
dryrun=False
nameNode=hdfs://nameservice1
jobTracker=cnqycspser02:8032
2.XML文件详情:
<workflow-app name="shell" xmlns="uri:oozie:workflow:0.5">
<start to="shell-571c"/>
<kill name="Kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<action name="shell-571c">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<exec>lib/sparkJob.sh</exec>
<capture-output/>
</shell>
<ok to="End"/>
<error to="Kill"/>
</action>
<end name="End"/>
3.lib文件夹主要用于存放shell脚本及jar包

若有收获,就点个赞吧
0 人点赞
