CPU缓存行与伪共享
数据在缓存中不是以独立的项来存储,不是单独的变量,也不是单独的指针。缓存系统中是以缓存行(cache line)为单位存储,缓存行是2的整数幂个连续字节,一般为32-256个字节,最常见的缓存行大小是64个字节。
无论是一个对象还是一个对象的属性 都是可以单独存为一个缓存行
第一种玩法:
加@sun.misc.Contended 这是java提供的注解 确保Cell 对象能填满一个缓冲行,普通对象头在32位系统上占用8bytes,64位系统上占用16bytes。64位机器上,数组对象的对象头占用24个字节,启用压缩之后占用16个字节,一个long类型占用8个字节,其余字节由@sun.misc.Contended来填充
// 防止缓存行伪共享
@sun.misc.Contended
static final class Cell {
volatile long value;
}
第二种玩法:
通过对热点变量周围进行缓存行填充,来规避缓存伪共享带来的问题,对于缓存行大小是64字节或更少的处理器架构来说是这样的,有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题,通过增加补全变量的个数来确保热点变量不会和其他东西同时存在于一个缓存行中。下面是Disruptor对ring buffer的序列号做的补全代码:
public long p1, p2, p3, p4, p5, p6, p7; // cache line paddingprivate volatile long cursor = INITIAL_CURSOR_VALUE;public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
当cup加载一个long元素(8个字节)的时候会顺带加载靠近他左边或者右边的(56个字节)组成64个字节形成一个缓存行(64个字节内任意一个数据改变都会导致缓存行失效),所以在热点数据左右增加常量数据来达到填充缓存行的目的,这样单独的一个热点数据long cursor就会独占一行缓存行
其中 Cell 即为累加单元
// 防止缓存行伪共享@sun.misc.Contendedstatic final class Cell {volatile long value;Cell(long x) { value = x; }// 最重要的方法, 用来 cas 方式进行累加, prev 表示旧值, next 表示新值final boolean cas(long prev, long next) {return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);}// 省略不重要代码}
得从缓存说起
缓存与内存的速度比较 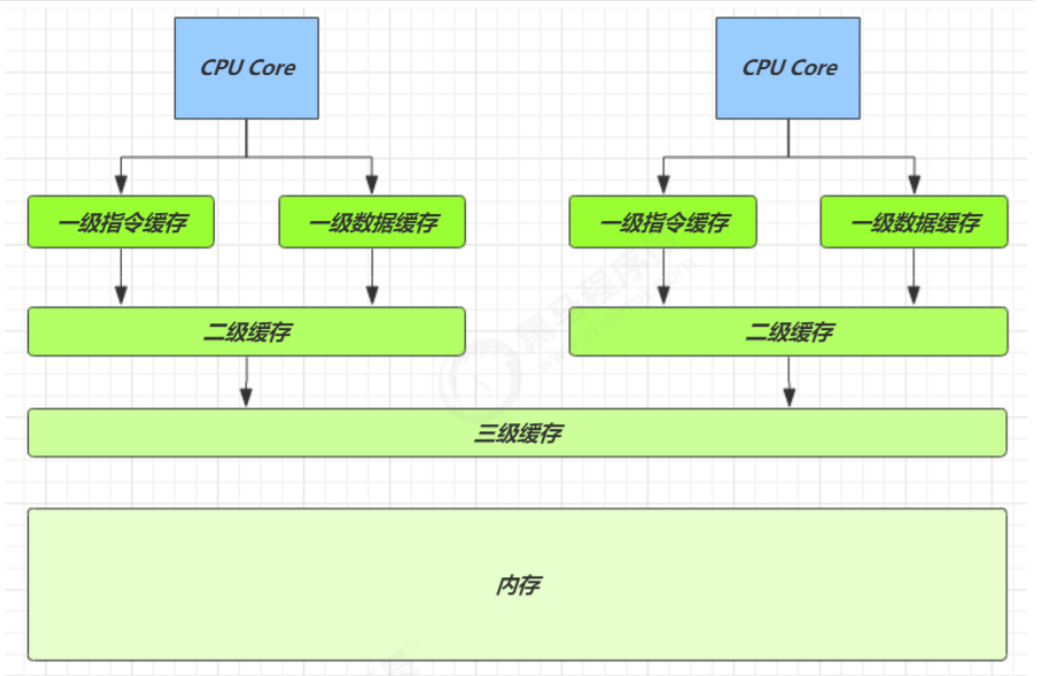
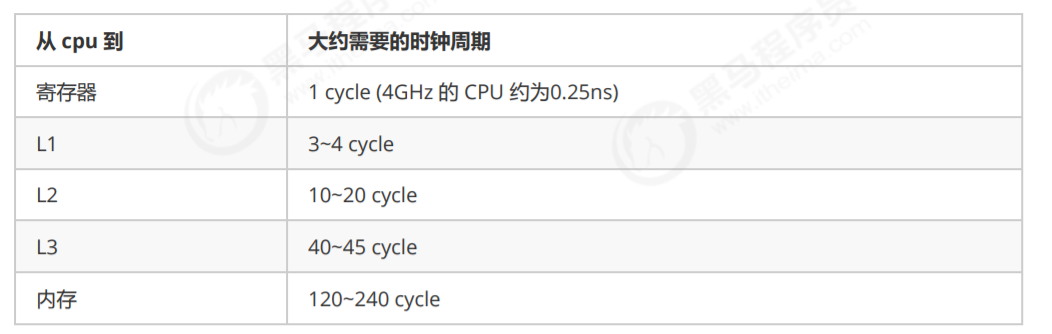
- 因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
- 而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
- 缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
- CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
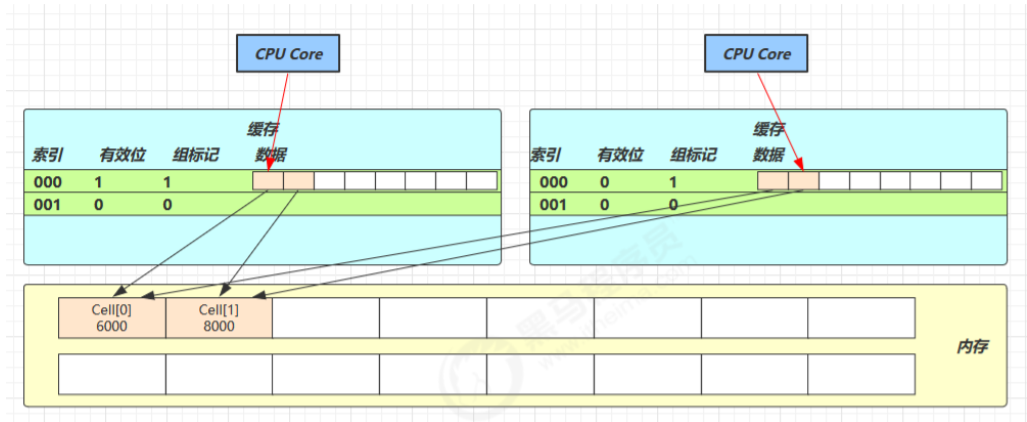
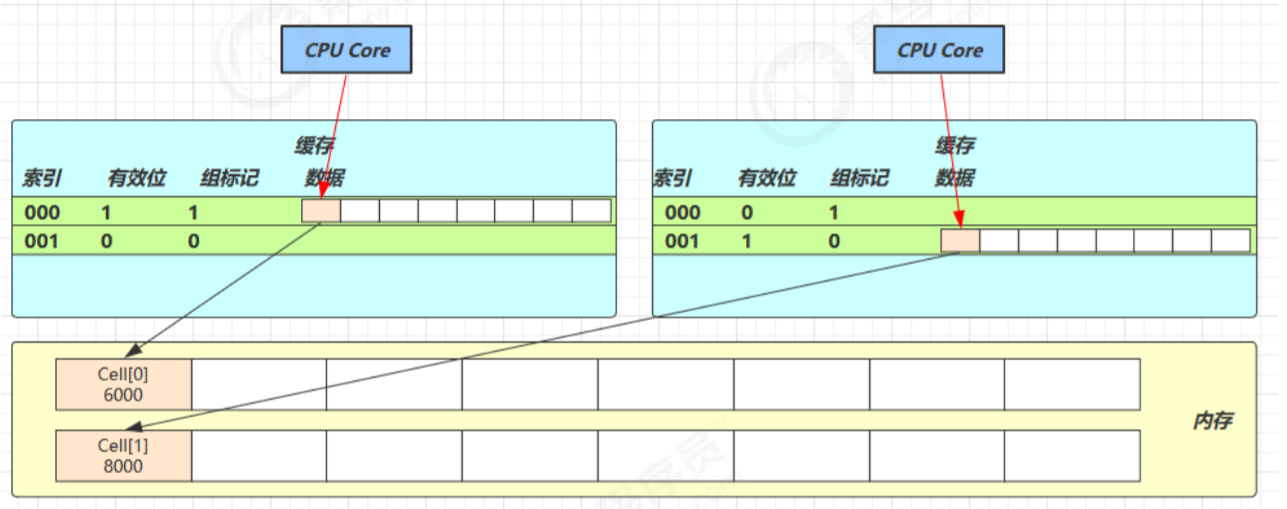
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因 此缓存行可以存下 2 个的 Cell 对象。
这样问题来了:
- Core-0 要修改 Cell[0]
- Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效

若有收获,就点个赞吧
0 人点赞
