OpenPAI将/mnt/cephfs目录挂载到系统中,所以请将 /mnt/cephfs/home/用户名/ 作为你的个人目录, 建议创建Code目录存放你的代码。数据集则保存在/mnt/cephfs/dataset下。以下将具体举例如何提交一个普通单机作业任务。
准备训练数据
OpenPAI集群已经集成了分布式存储,公开数据集保存会保存在 /mnt/cephfs/dataset 中。本节中使用的CIFAR-10数据集已经存放在/mnt/cephfs/dataset/CIFAR-10 下,可以直接使用。为了节约集群的存储空间,所有的公开数据集都要存放在 /mnt/cephfs/dataset 中,方便各位同学共享使用。更多关于数据集如何存储和使用的介绍可以在xxx查看。
准备训练代码
Cifar10
以 pytorch 官网cifar10分类任务为例进行演示。我们将其网页上的代码保存为train.py文件。
1. 代码
a. 代码存放目录:/mnt/cephfs/home/用户名/Code/ , 在本例中代码路径为/mnt/cephfs/home/用户名/Code/``test/train.py
b. 数据集存放路径:/mnt/cephfs/dataset,将下载好的数据集保存在该目录中。我们对代码中的数据集目录进行相应的修改。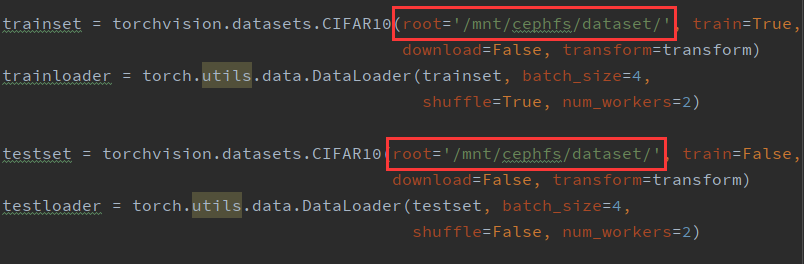
c. 结果存放路径:/mnt/cephfs/home/用户名/Code/test/result 我们在实验目录下创建了result目录保存结果。对代码进行相应的修改。
2. 提交任务
A. 选择提交作业类型

在Submit job界面下点击Single job进入填写页面
B. 填写作业信息
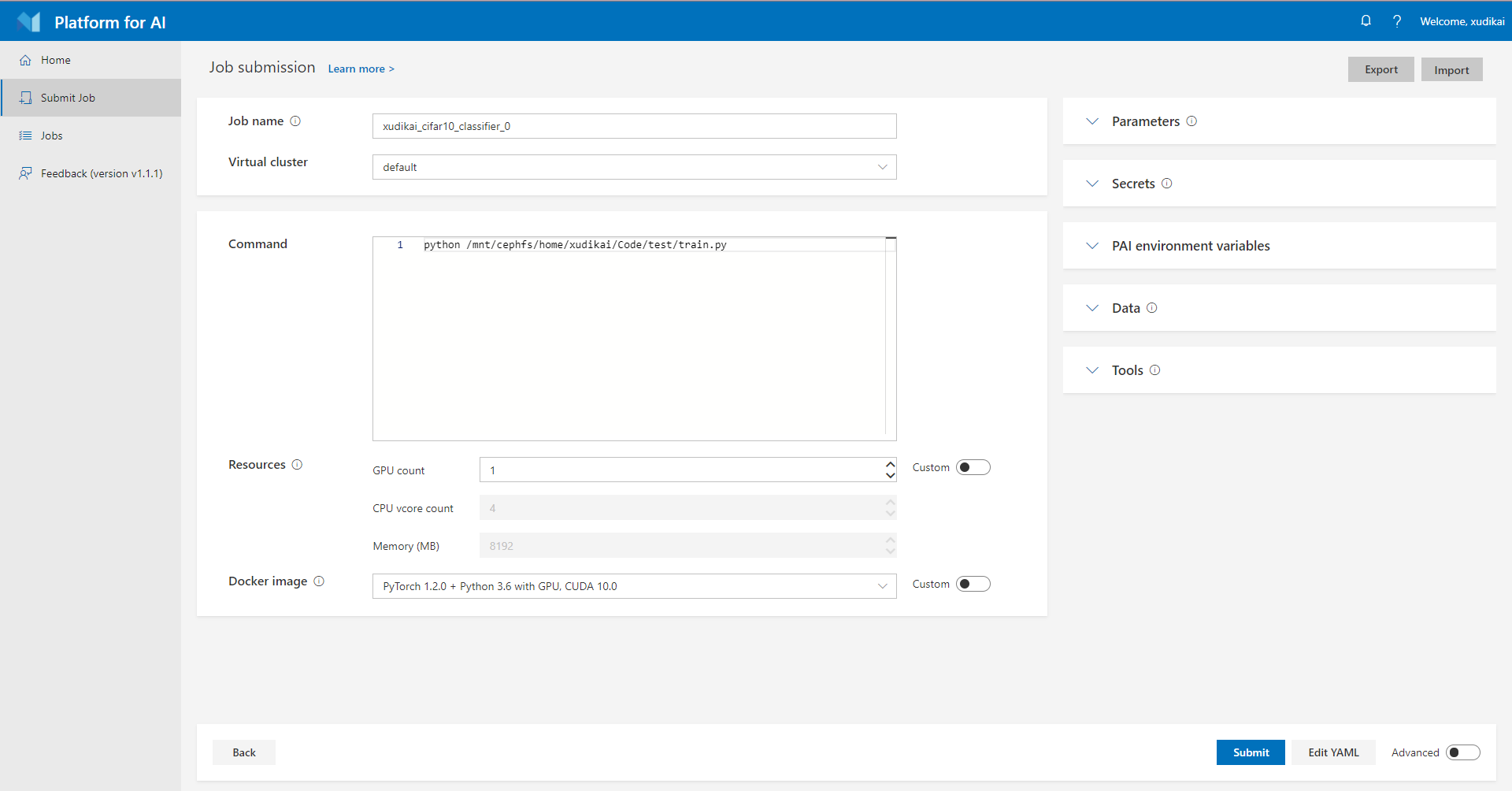
A. Job name:
填入本次作业的名称,建议起一个有意义的名字,本例为cifar10_classifier_0
B. Virtual cluster:
虚拟集群,默认defaul,目前无需选择
C. Command:
填入你需要运行的命令。例如本例为 python /mnt/cephfs/home/xudikai/Code/test/train.py。 这与你在普通服务器上所需要运行的命令相同。请注意你代码所在的路径。
D. Resources:
配置你本次实验所需要的的资源。可以选择所需GPU的数量。打开Custom按钮,可以配置CPU核心数量和内存大小。
E. Docker image:
选择Docker镜像,即实验运行的环境。本例中选择PyTorch 1.2.0 + Python 3.6 with GPU, CUDA 10.0镜像。
C. 提交作业
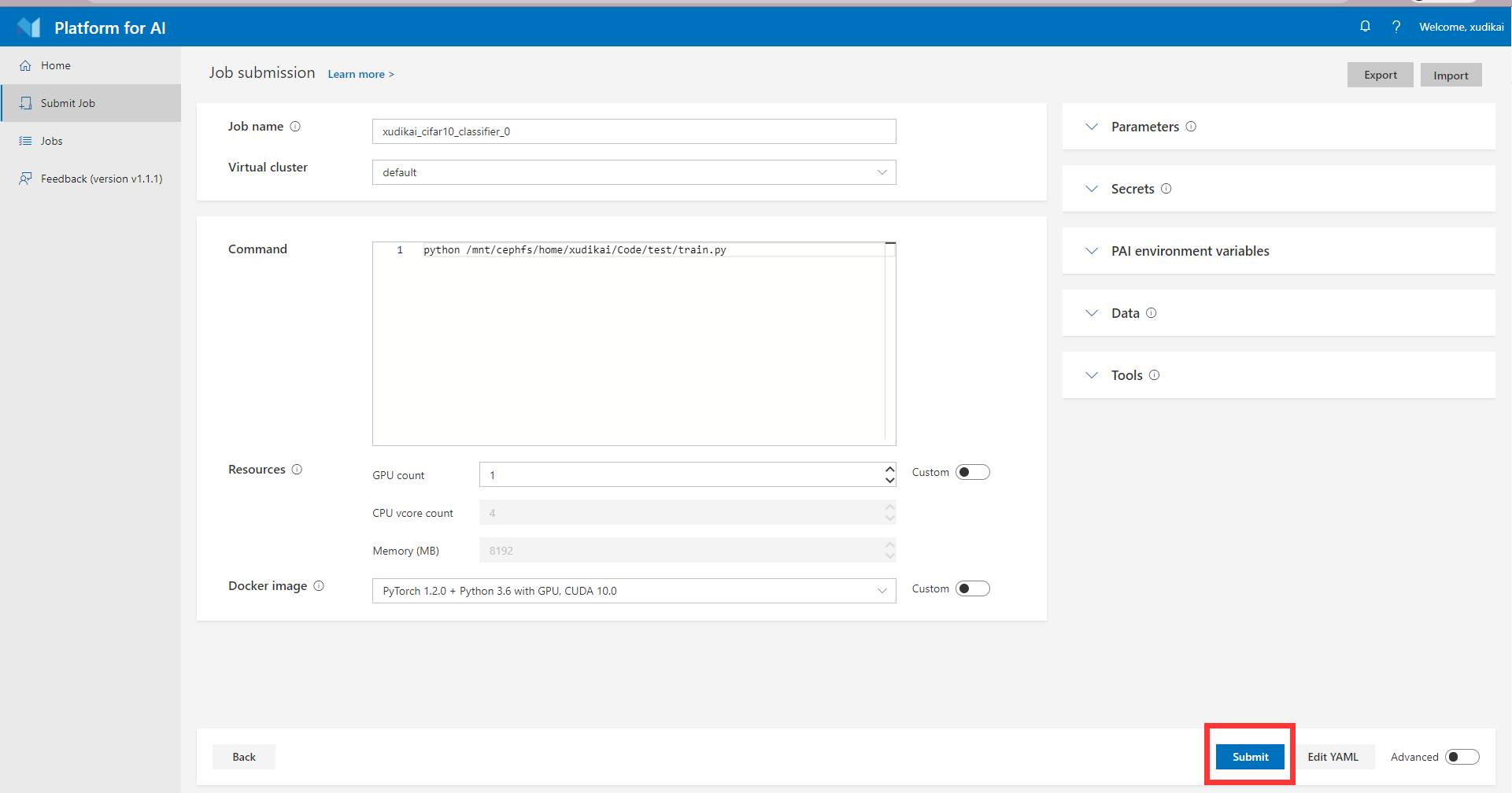
填写完成后,即可点击页面底部的 Submit 按钮,提交作业。
3. 查看作业
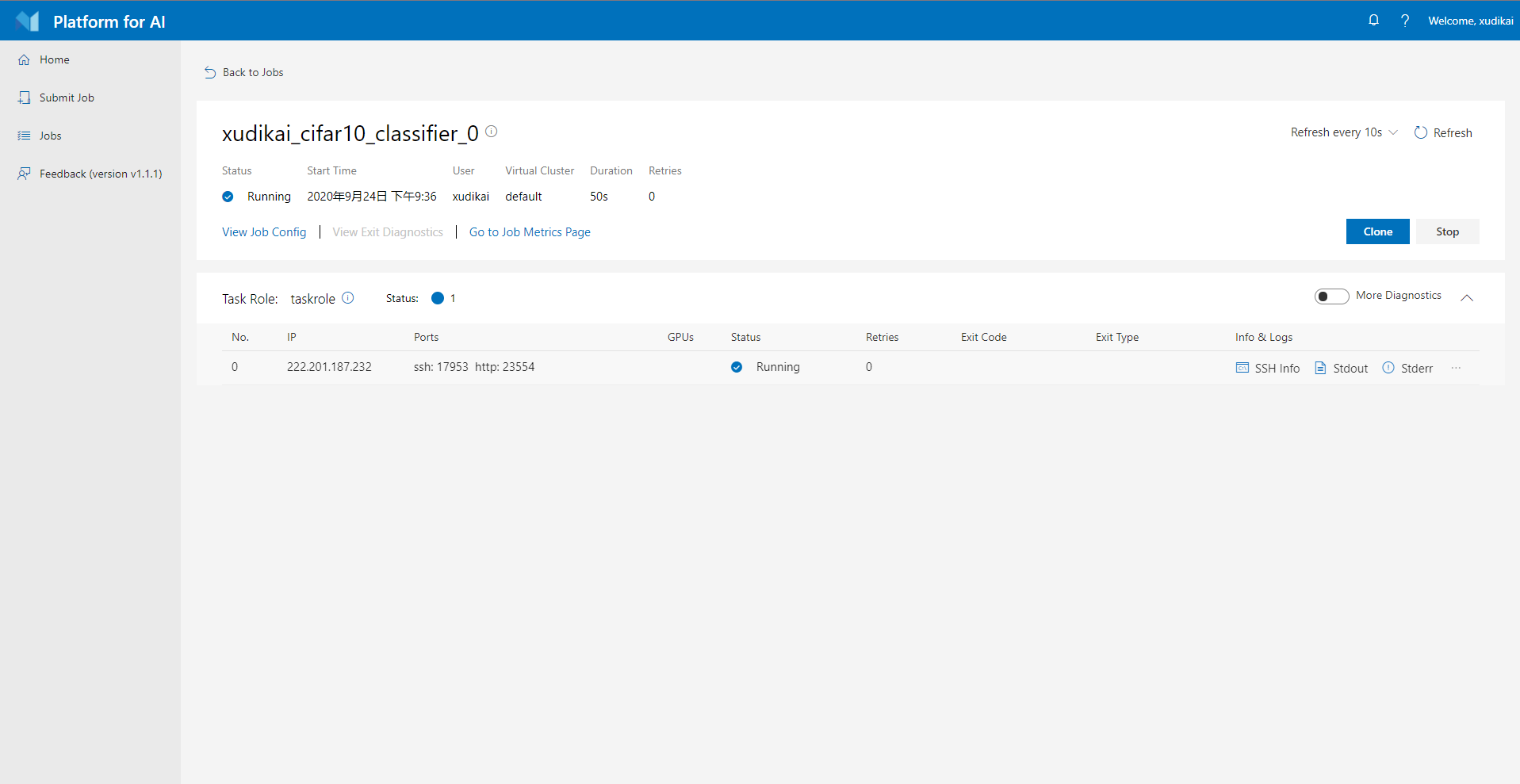
提交后会跳转到作业具体的信息页面。
可以点击Stdout查看运行过程中的输出,或当程序出错时点击Stderr查看错误信息。

若有收获,就点个赞吧
0 人点赞
