OpenPAI提供以下三种方式操作集群:1)Web界面、2)Web API;3)SDK套件,其中最常用的是Web界面。在本章节中,我们将大致游览一下Web界面中的各个页面,并简要介绍一下各个页面的功能,更加详细的介绍可以在后续章节查看。
1. 登录页面
点击Sign in按钮,弹出登录页面(登录页面的网址请咨询管理员)。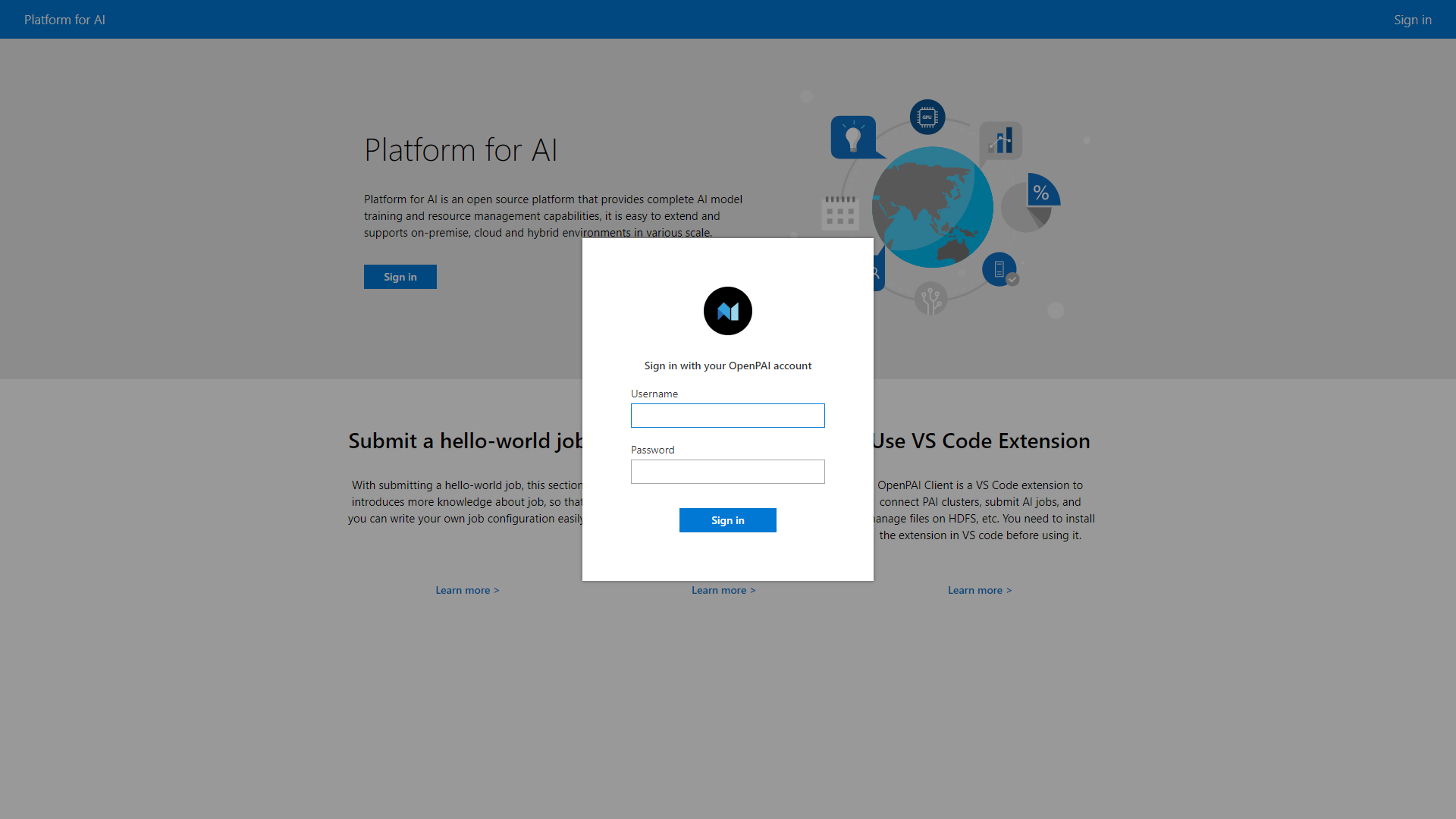
输入用户名和密码进行登录(账号不能自行注册,请在管理员处申请)
登录成功后将在网页左侧的侧边栏上有三个不同的页面按钮,分别是“Home”页面,“Submit Job”页面和“Jobs”页面,下面我们将一一介绍
2. Home页面
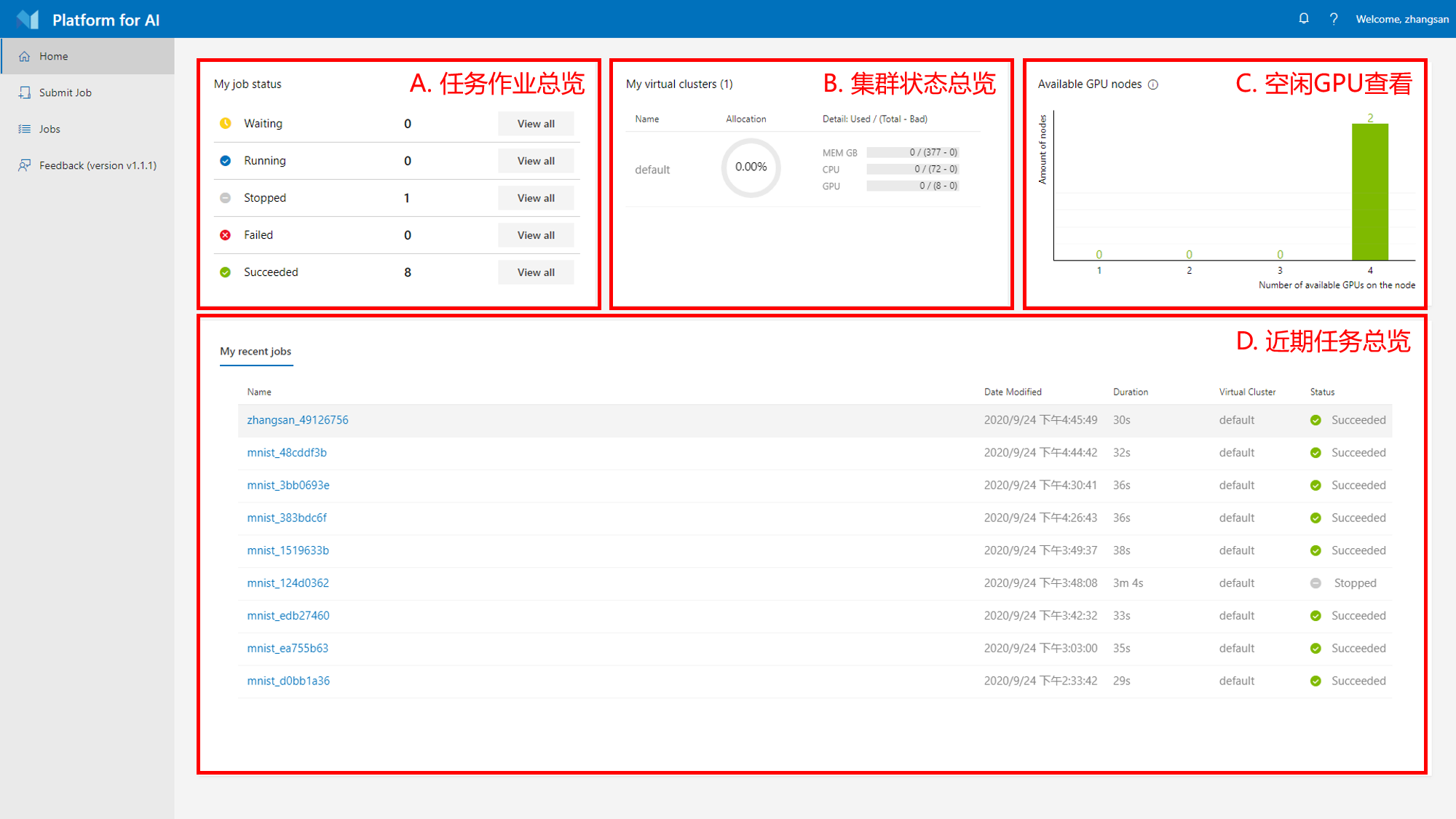
登陆之后默认打开的是home界面,在这里可以看到集群和任务状态的总览
A. 任务作业总览
可以查看本账号下处于各种状态的任务作业数量,点击对应的”View all”按钮可以查看该状态下的所有作业
任务作业是OpenPAI的调度单位,对于集群用户,可以简单理解为一次机器学习实验
B. 集群状态总览
C. 空闲GPU查看
以柱状图的形式给出空闲GPU的数量:每条柱形表示包含某个数量的空闲GPU的节点数量
D. 近期任务查看
查看近期提交的任务作业,并显示任务的简况(任务提交时间,运行时间,所属虚拟集群,状态等)
3. Submit Job 页面
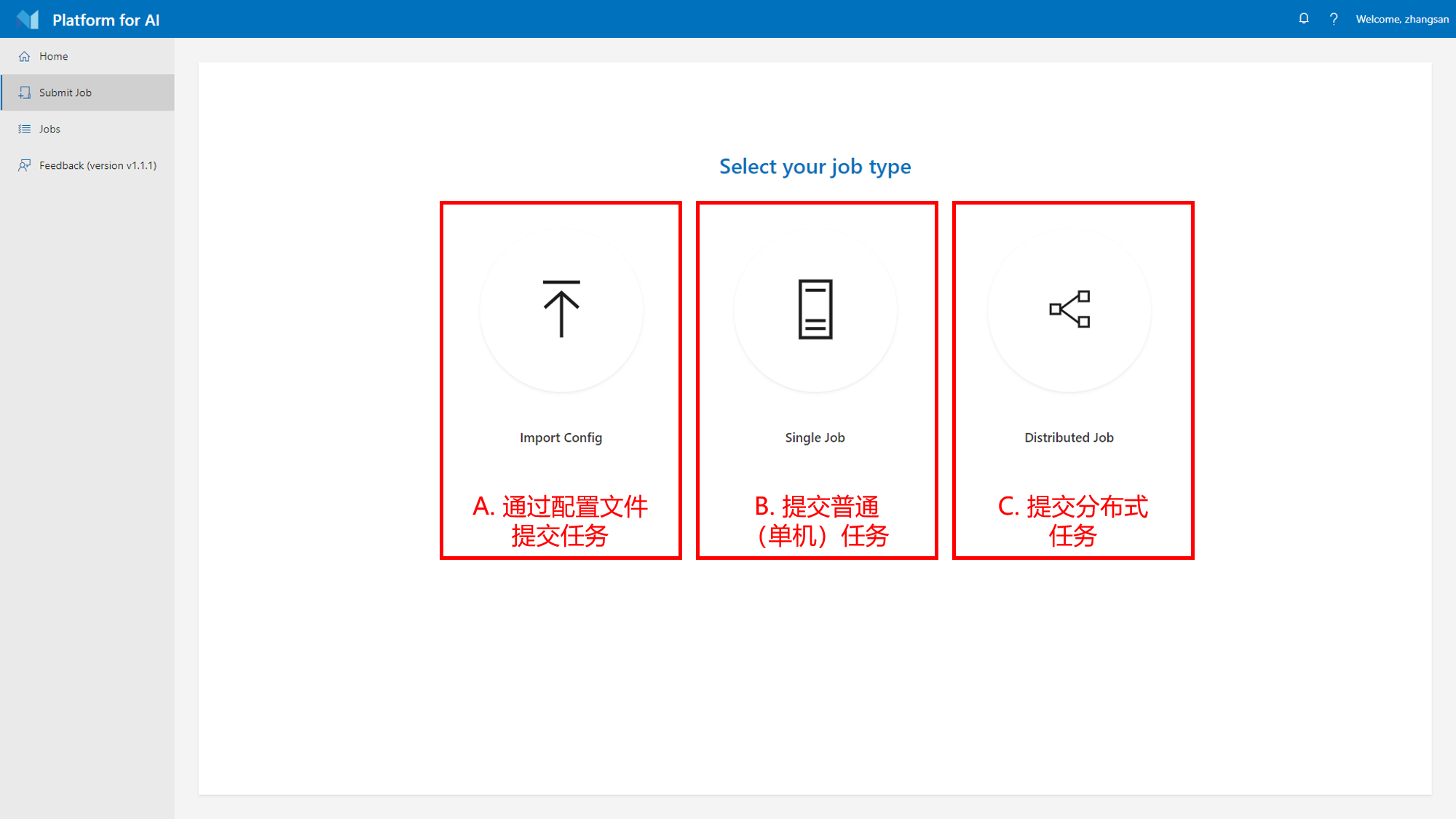
A. 通过配置文件提交任务
可以导入已有的作业YAML配置文件,集群会解析该配置文件并运行该作业
B. 提交普通(单机)任务
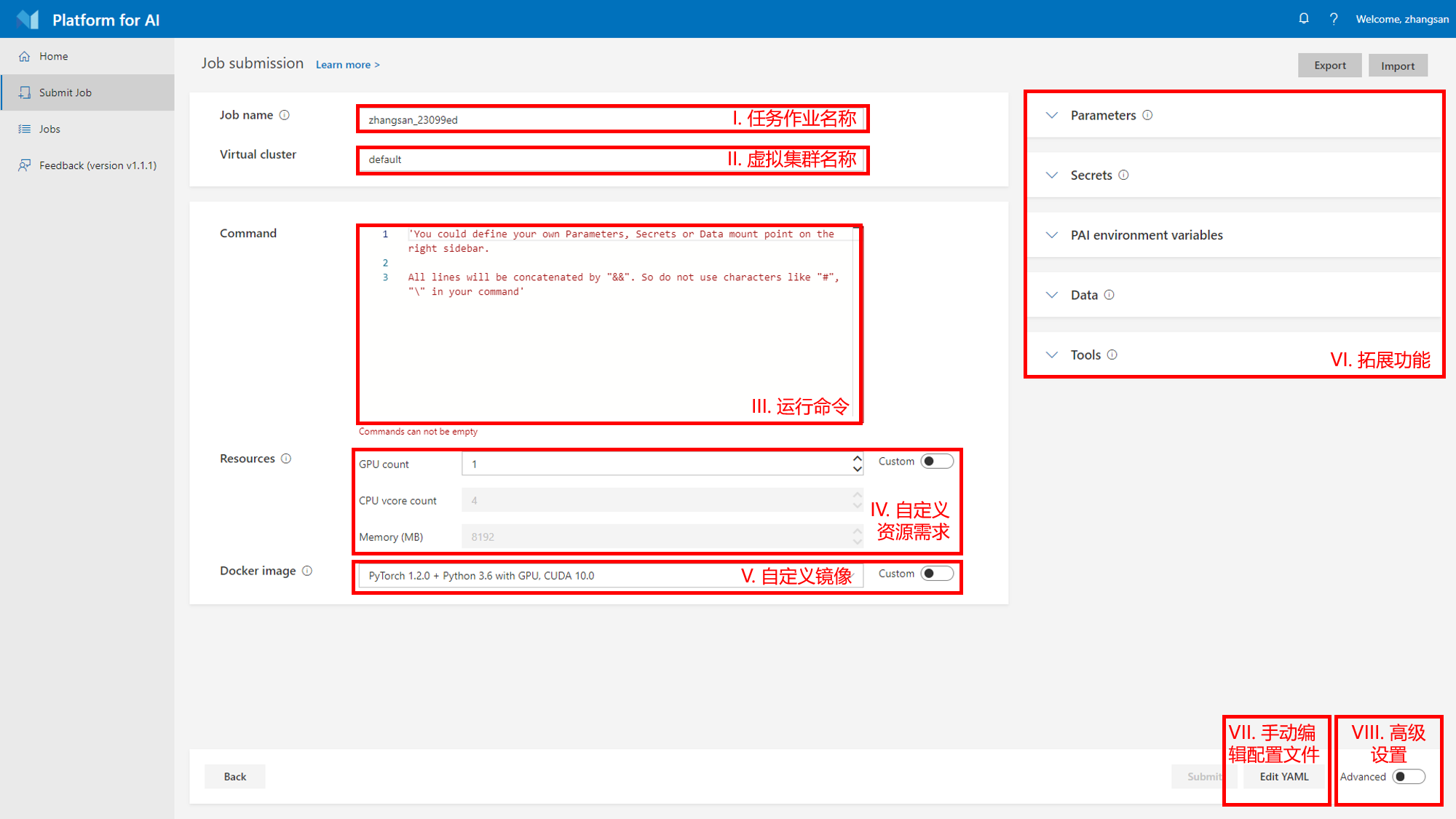
上图是提交普通(单机)任务的页面,具体的介绍可以到后续章节查看,这里只对页面进行简单的介绍
- I. 任务作业名称:该名称是任务的唯一标识符,将会出现在任务列表中
- II. 虚拟集群名称:这里可以选择不同的虚拟集群,具体选择哪个请咨询管理员
- III. 运行命令:这里填写任务的运行命令,一般是机器学习实验的入口脚本
- IV. 自定义资源需求:这里可以设置该任任务作业需要的GPU、GPU已经内存的数量,一般会根据任务本身的特点而定
- V. 自定义镜像:这里可以填写docker的镜像地址,可以是公网的镜像,也可以是私有镜像的地址
- VI. 拓展功能:这部分功能包括设置任务参数、设置任务敏感数据(如密码)、设置任务需要挂载的存储、是否启用tensorboard和SSH功能等,更加详细的介绍可以查看后续的章节
- VII. 这里可以查看该任务对应的YAML配置文件,该配置文件可以保存到本地
- VIII. 这里可以设置该任务需要额外的网络端口,重试次数等
C. 提交分布式任务
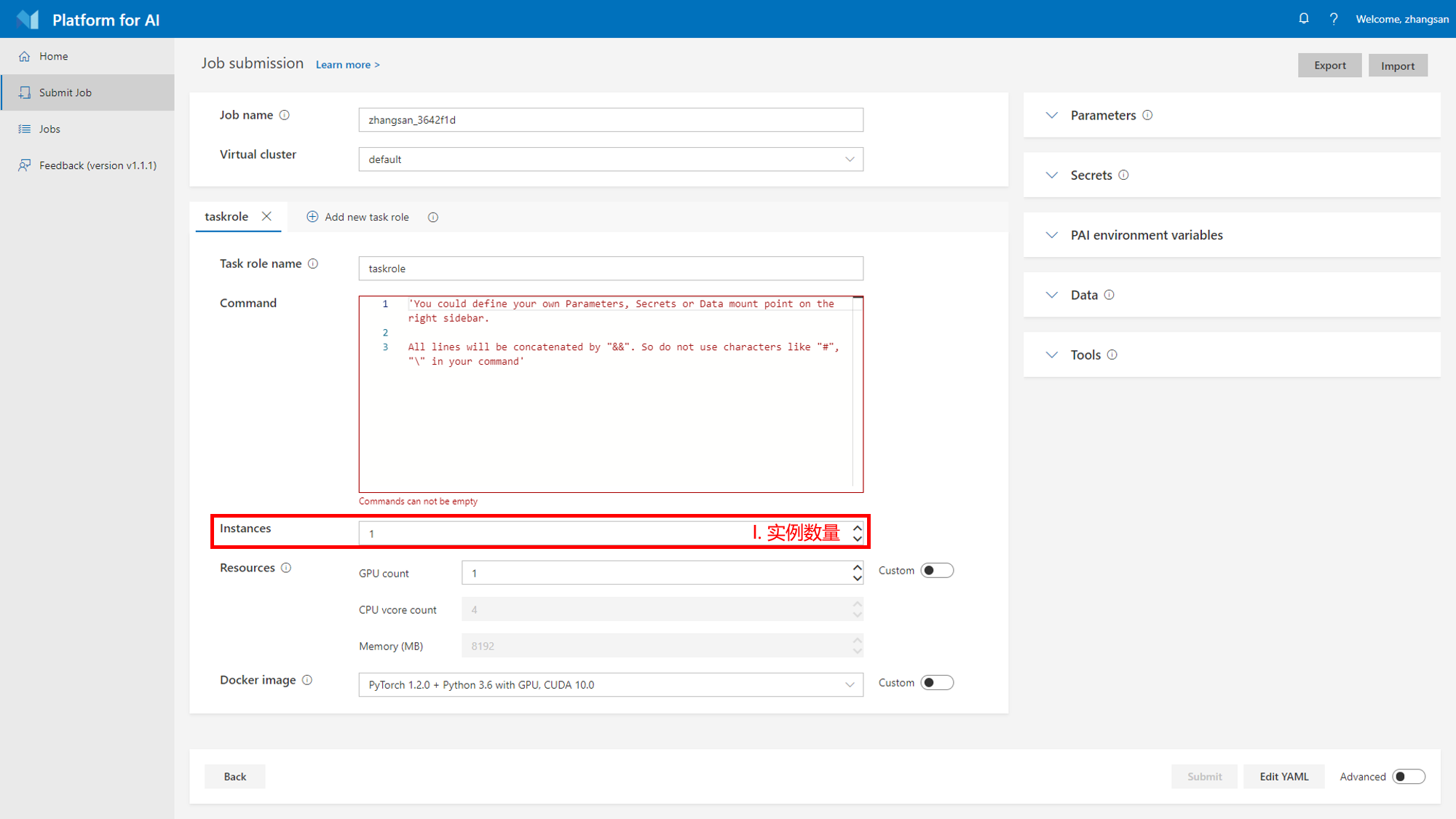
分布式任务和普通任务不同,普通任务只会运行在一台机器上面,而分布式任务可以运行在多台不同的机器上面。现在的深度学习框架(如TensorFlow和PyTorch)都已经支持了分布式训练,分布式训练可以很好地线性拓展,加速大规模深度学习运算
分布式任务提交时其页面与普通任务大致相同,不同的是其需要指定 I. 实例数量,即分布式训练里面的world size,更加详细的介绍可以到后续章节查看
4. Jobs 页面
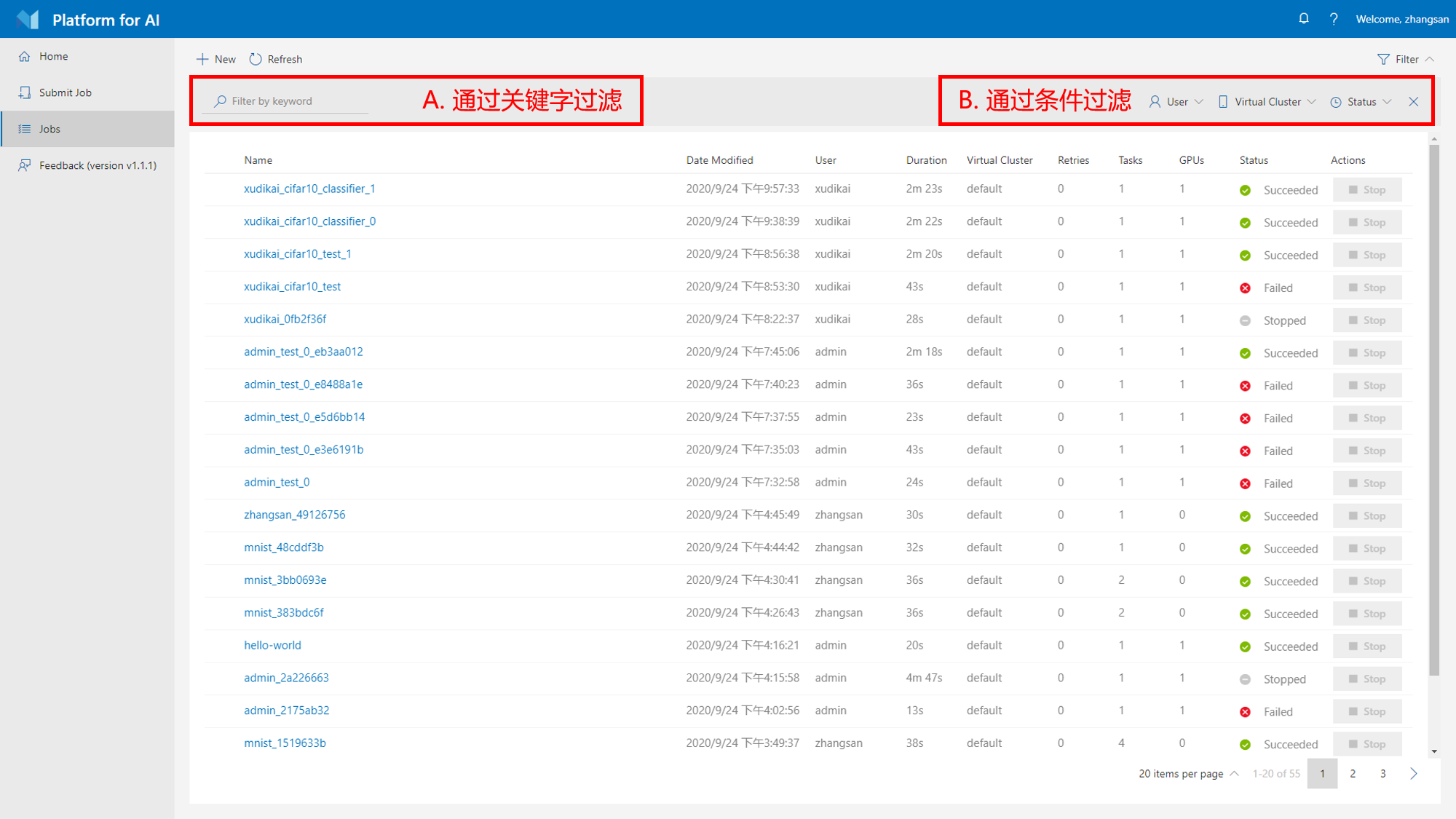
在Jobs页面可以查看所有人的历史作业记录,并且可以 A. 通过关键字过滤任务作业(即3.B中介绍的“任务作业名称”),此外,还可以 B. 通过不同的条件过滤任务作业(包括用户名称,虚拟集群名称,任务作业转台等)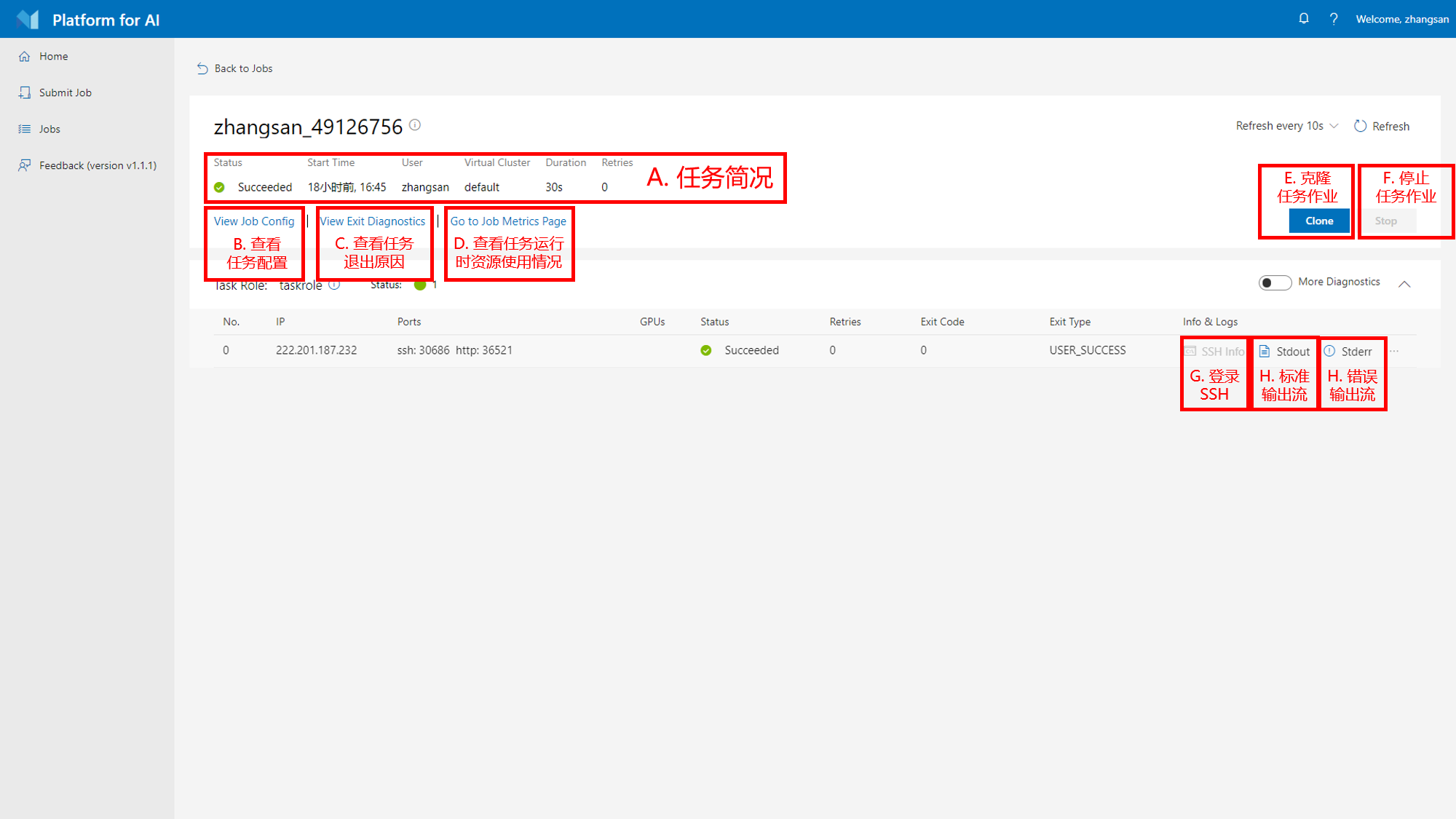
点击某个作业,可以进入任务详情页面查看作业信息
A. 任务简况
B. 查看任务配置
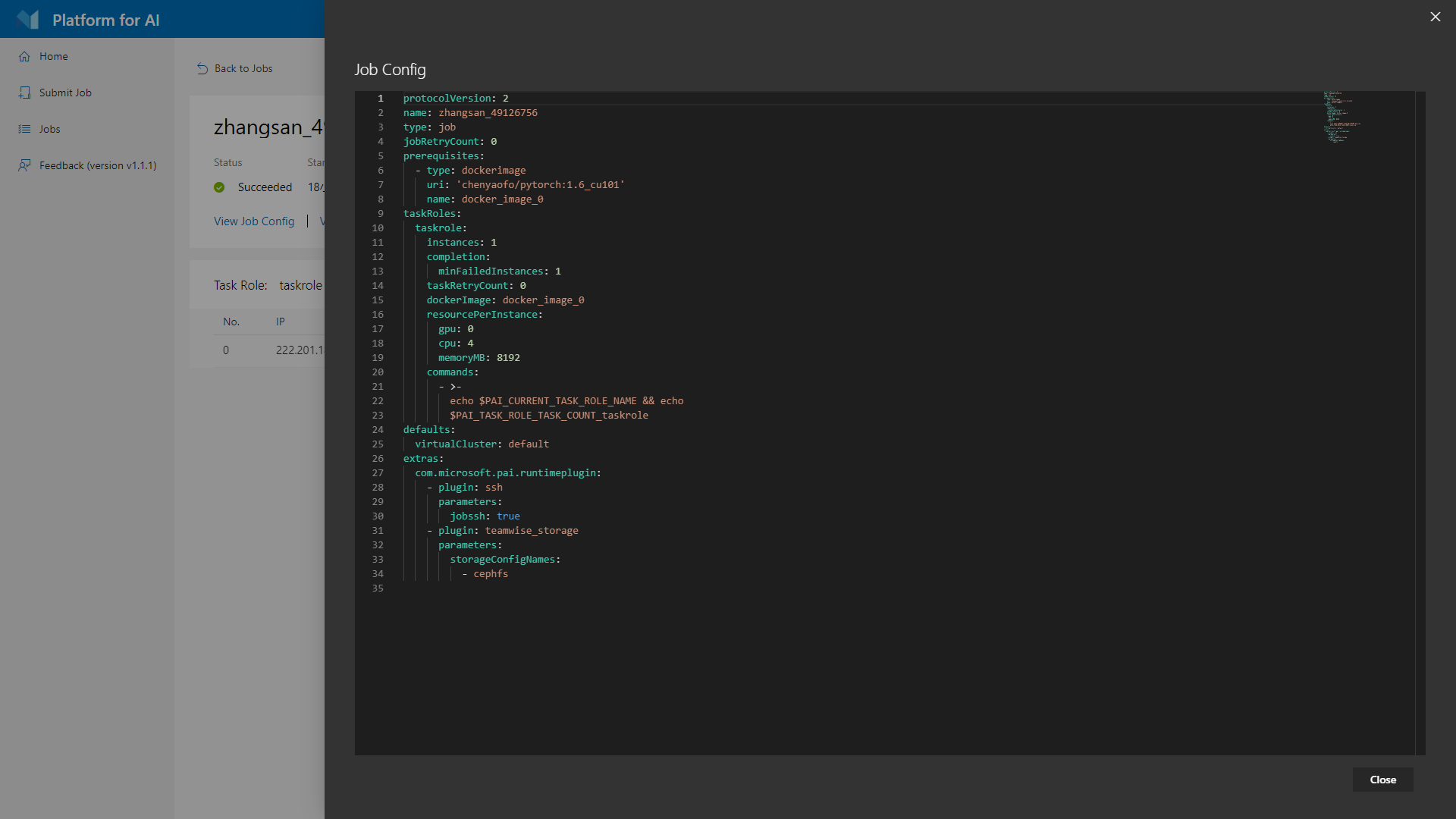
C. 查看任务退出原因
点击后可以查看任务退出的原因,一般包括1)任务成功后自动退出,2)用户手动停止,3)代码运行后出错退出,4)集群节点崩溃退出等,如下图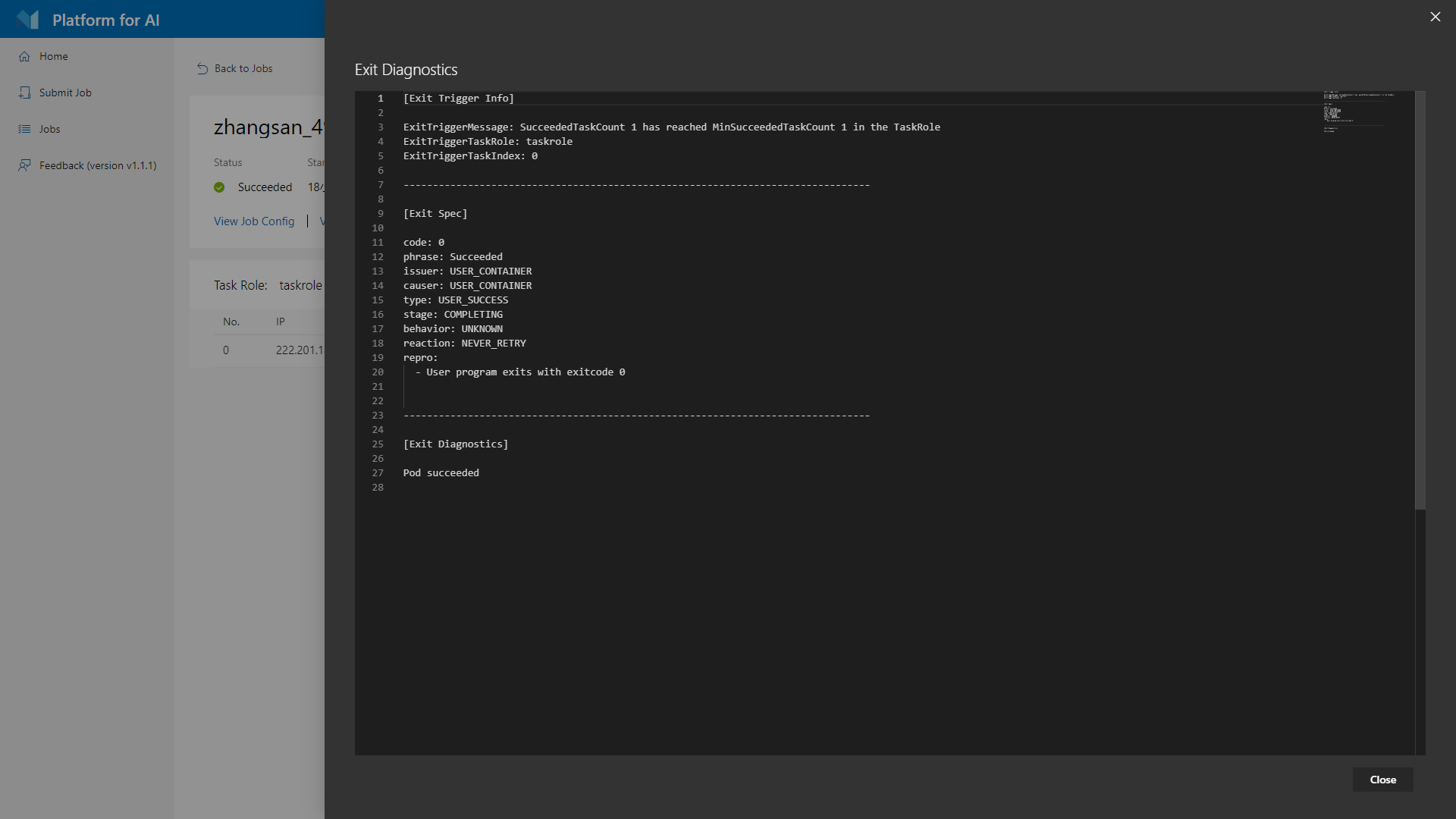
D. 查看任务运行时资源使用情况
可以查看任务运行时CPU、内存、网络、磁盘、GPU和显存的利用率,如下图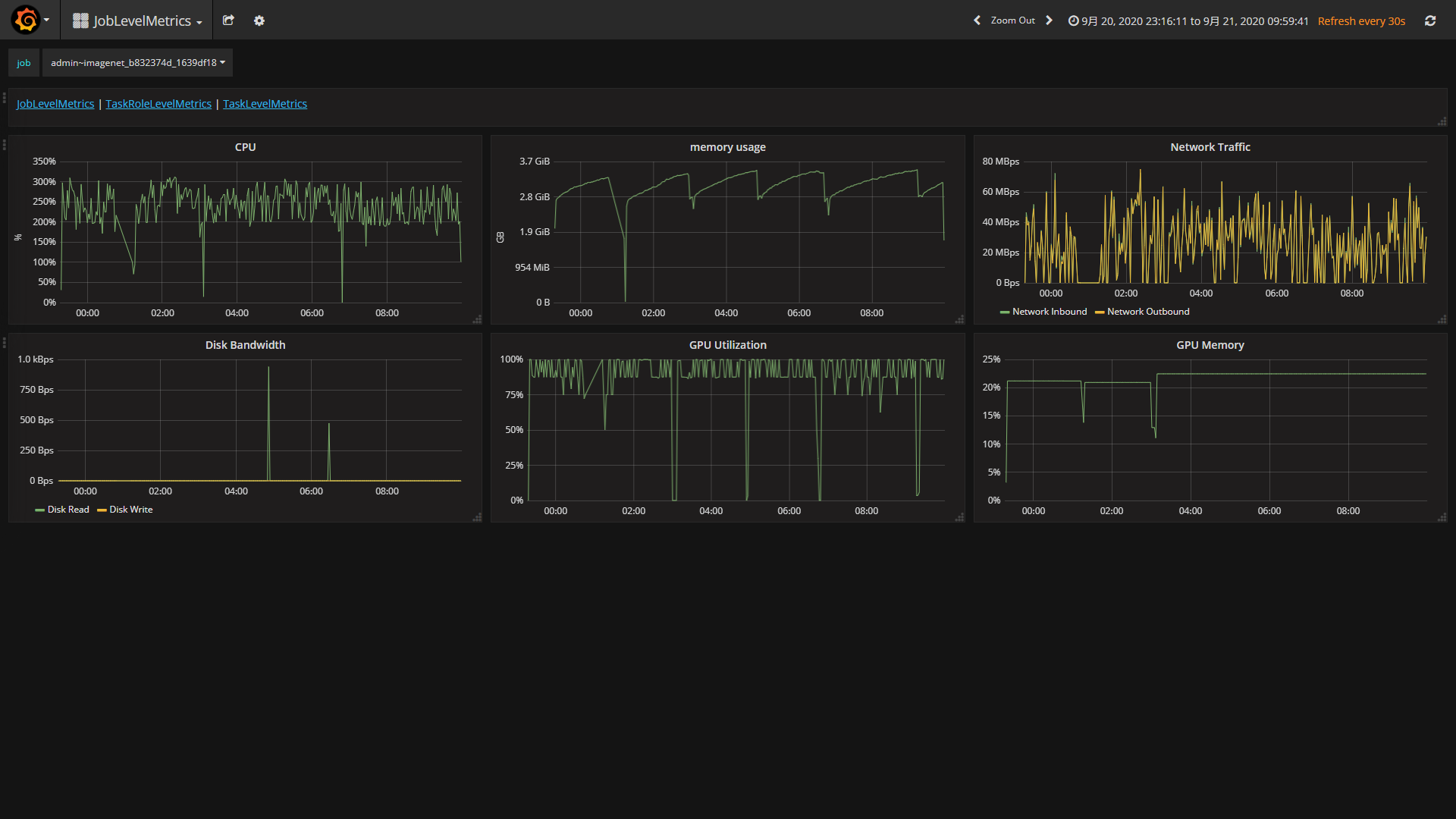
E. 克隆任务作业
点击后会克隆一个配置一样的任务,你可以修改任务的部分设置之后快速提交
F. 停止任务作业
G. 登录SSH
如果开启了SSH拓展功能,点击后可以查看SSH登录信息(即IP和端口),如下图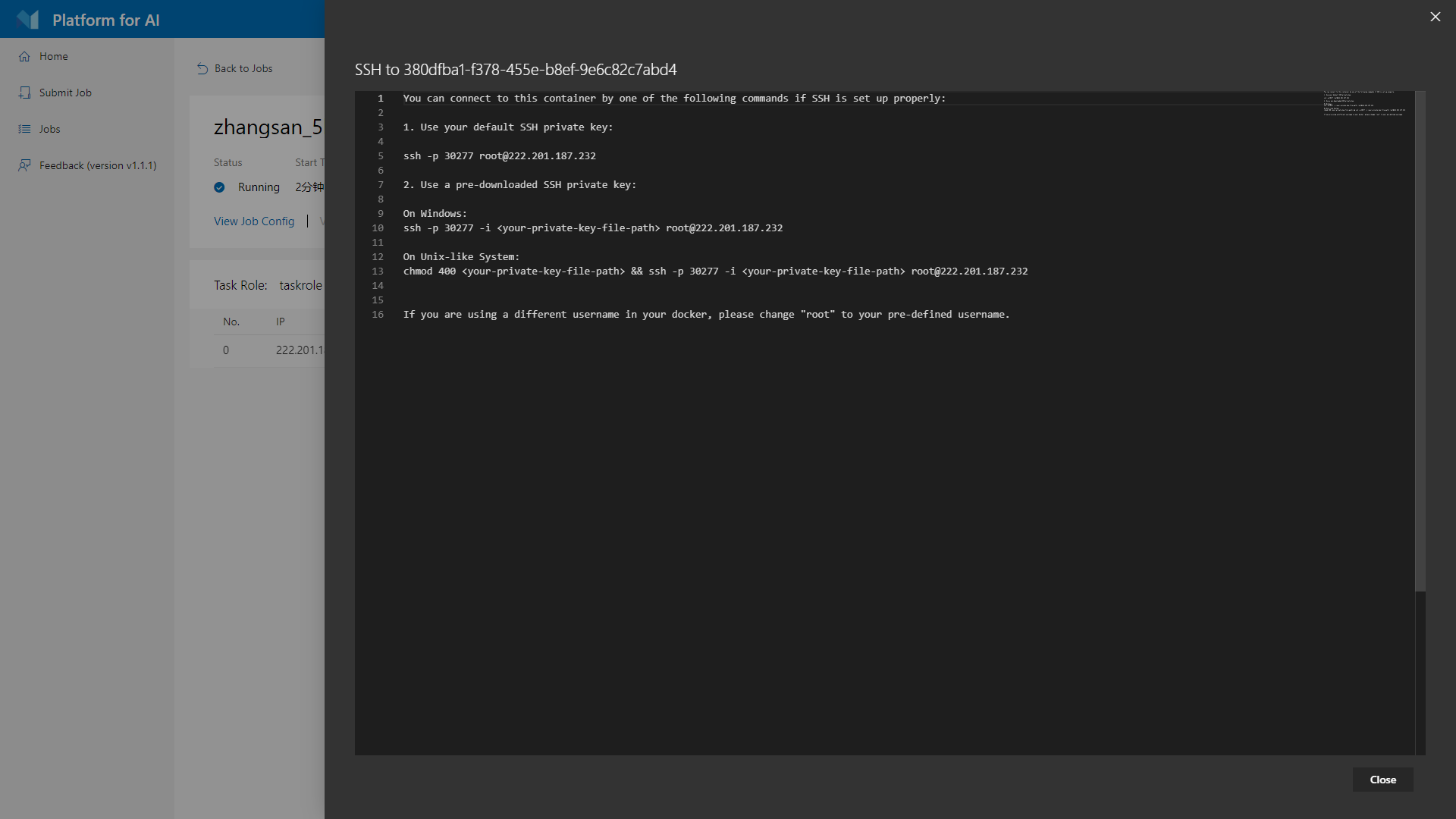
H. 标准输出流
查看任务运行过程中的标准输出流,在弹出的日志窗口中只能查看最近的输出,查看完整的输出可以点击”View FULL Log”按钮,如下图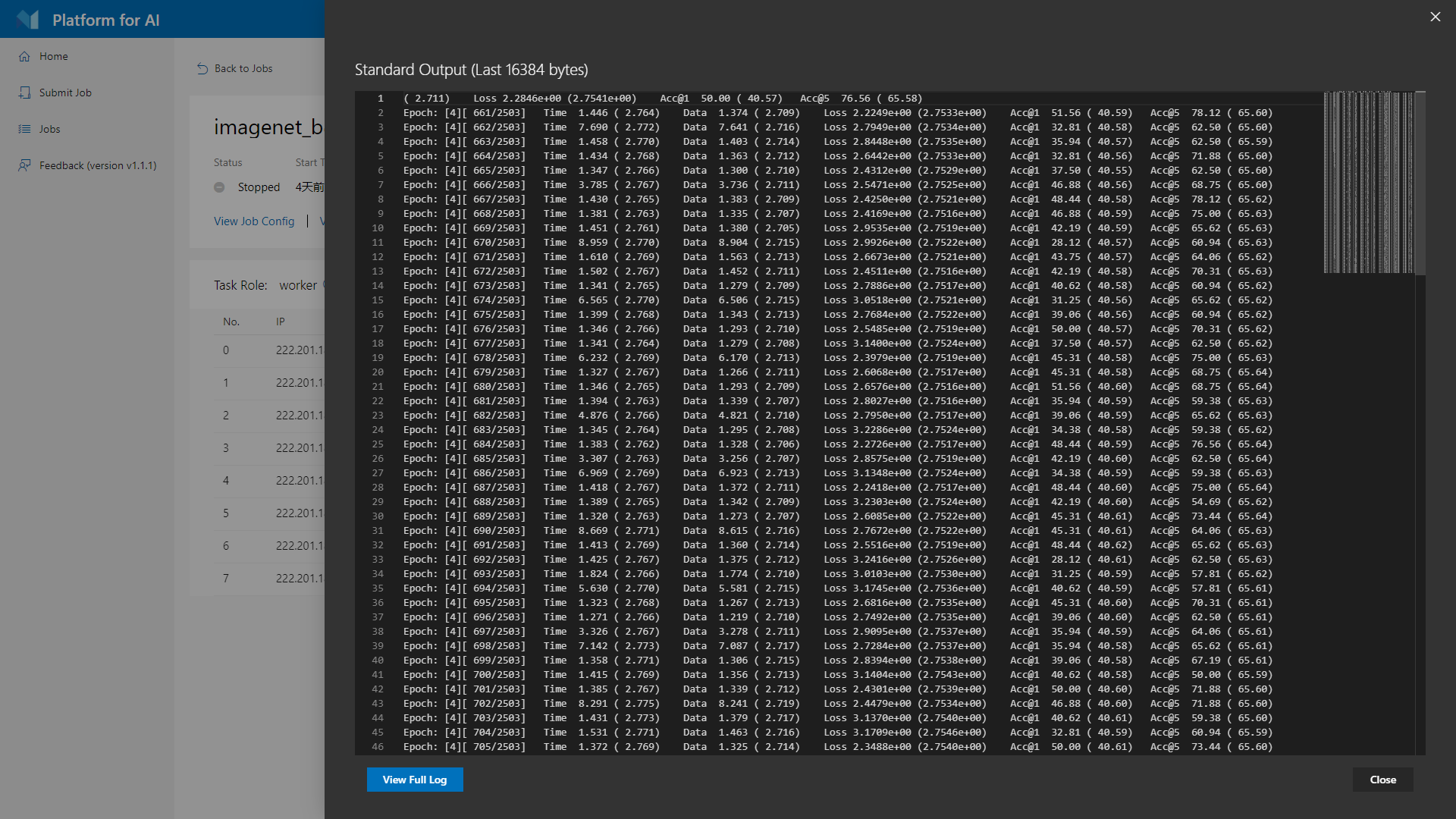
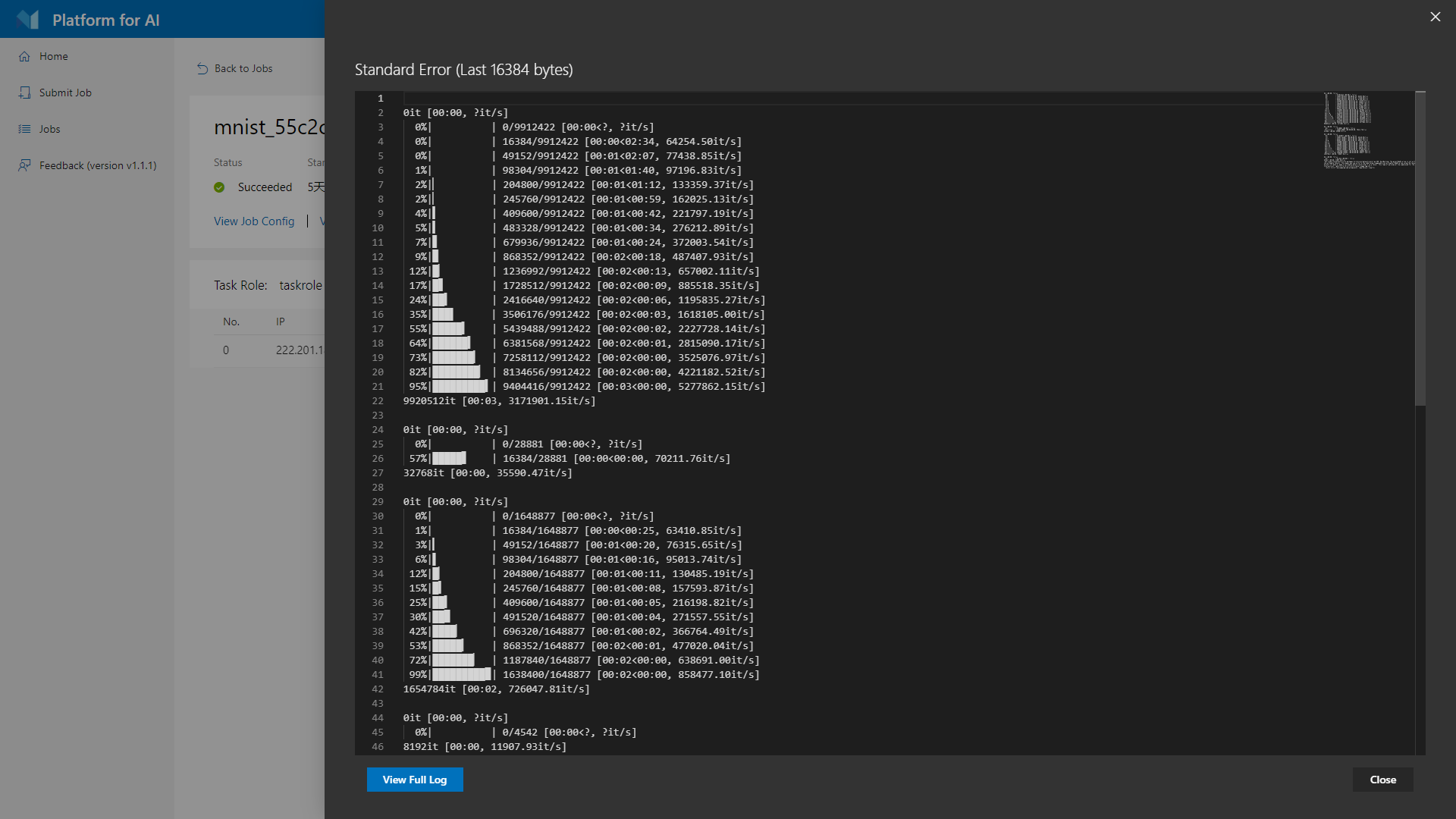
H. 错误输出流
查看任务运行过程中的错误输出流,在弹出的日志窗口中只能查看最近的输出,查看完整的输出可以点击”View FULL Log”按钮,如下图

若有收获,就点个赞吧
0 人点赞
