布隆过滤
如果面试中遇到网页黑名单系统、垃圾邮件过滤系统、爬虫网址判重系统等场景题,又看到系统容忍一定程度的失误率,但是空间十分有限,那么很可能是面试官希望面试者具备布隆过滤器的知识。
布隆过滤器具有节约内存、无需存储数据、利于算法并行实现等优点,但前提是能够容忍一定的误判率。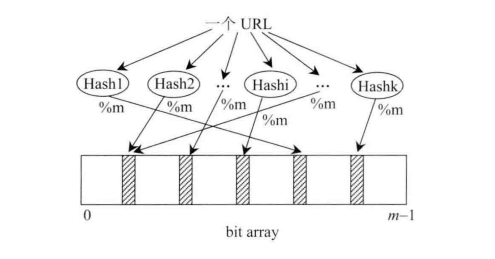

明显这是一个需要布隆过滤器的场景题。设计的一个布隆过滤器,需要先确定映射空间长度m,并行计算的哈希函数的数量k,最后再确定合适的哈希函数即可。
哈希函数出名的有md5,SHA-1,不过这里需要选择murmur4 hash 算法,该算法计算量相较于前两者小很多,并且散列值均匀分布。
针对误报问题,一般采用白名单机制来解决。
顺序分流

面试官:如果我给你 2GB 的内存,并且给你 20 亿个 int 型整数,让你来找出次数出现最多的数,你会怎么做?
小秋:(嗯?怎么感觉和之前的那道判断一个数是否出现在这 40 亿个整数中有点一样?可是,如果还是采用 bitmap 算法的话,好像无法统计一个数出现的次数,只能判断一个数是否存在),我可以采用哈希表来统计,把这个数作为 key,把这个数出现的次数作为 value,之后我再遍历哈希表哪个数出现最多的次数最多就可以了。
面试官:你可以算下你这个方法需要花费多少内存吗?
小秋:key 和 value 都是 int 型整数,一个 int 型占用 4B 的内存,所以哈希表的一条记录需要占用 8B,最坏的情况下,这 20 亿个数都是不同的数,大概会占用 16GB 的内存。
面试官:你的分析是对的,然而我给你的只有 2GB 内存。
小秋:(感觉这道题有点相似,不过不知为啥,没啥思路,这下凉凉),目前没有更好的方法。
面试官:按照你那个方法的话,最多只能记录大概 2 亿多条不同的记录,2 亿多条不同的记录,大概是 1.6GB 的内存。
小秋:(嗯?面试官说这话是在提示我?)我有点思路了,我可以把这 20 亿个数存放在不同的文件,然后再来筛选。
面试题:可以具体说说吗?
小秋:刚才你说,我的那个方法,最多只能记录大概 2 亿多条的不同记录,那么我可以把这 20 亿个数映射到不同的文件中去,例如,数值在 0 至 2亿之间的存放在文件1中,数值在2亿至4亿之间的存放在文件2中….,由于 int 型整数大概有 42 亿个不同的数,所以我可以把他们映射到 21 个文件中去,如图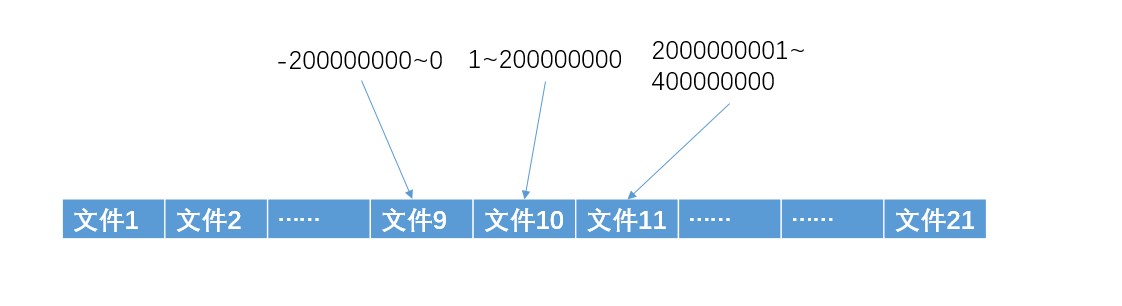
显然,相同的数一定会在同一个文件中,我们这个时候就可以用我的那个方法,统计每个文件中出现次数最多的数,然后再从这些数中再次选出最多的数,就可以了。
面试官:嗯,这个方法确实不错,不过,如果我给的这 20 亿个数数值比较集中的话,例如都处于 1~20000000 之间,那么你都会把他们全部映射到同一个文件中,你有优化思路吗?
小秋:那我可以先把每个数先做哈希函数映射,根据哈希函数得到的哈希值,再把他们存放到对应的文件中,如果哈希函数设计到好的话,那么这些数就会分布的比较平均。(关于哈希函数的设计,我就不说了,我这只是提供一种思路)
40亿级别
面试官:那如果我把 20 亿个数加到 40 亿个数呢?
小秋:(这还不简单,映射到42个文件呗)那我可以加大文件的数量啊。
面试官:那如果我给的这 40 亿个数中数值都是一样的,那么你的哈希表中,某个 key 的 value 存放的数值就会是 40 亿,然而 int 的最大数值是 21 亿左右,那么就会出现溢出,你该怎么办?
小秋:(那我把 int 改为 long 不就得了,虽然会占用更多的内存,那我可以把文件分多几份呗,不过,这应该不是面试官想要的答案),我可以把 value 初始值赋值为 负21亿,这样,如果 value 的数值是 21 亿的话,就代表某个 key 出现了 42 亿次了。
这里说明下,文件还是 21 个就够了,因为 21 个文件就可以把每个文件的数值种类控制在 2亿种了,也就是说,哈希表存放的记录还是不会超过 2 亿中。
80亿级别
面试官:反应挺快哈,那我如果把 40 亿增加到 80 亿呢?
小秋:(我靠,这变本加厉啊)………我知道了,我可以一边遍历一遍判断啊,如果我在统计的过程中,发现某个 key 出现的次数超过了 40 亿次,那么,就不可能再有另外一个 key 出现的次数比它多了,那我直接把这个 key 返回就搞定了。
面试官:行,此次面试到此结束,回去等通知吧。
Bitmap

10MB内存能容纳的bitMap:
>>> 10*2**20*883886080>>> 2**32/(10*2**20*8)51.2
但是按照这个长度进行划分不太好计算:
[0,len-1],[len,2*len-1],...,[51*len,51.2*len-1]
所以再想出一种很好划分,单个bitMap长度又不超过10MB的的方案。按照整数份进行划分:
>>> 2**27/(8*2**20) #如果划分为32份,每份长度是2**27,即16MB,超了10MB内存限制。
16.0
>>> 2**26/(8*2**20)#如果划分为64份,每份长度是2**26,即8MB,正好可以。
8.0


Non-Bitmap


哈希分流



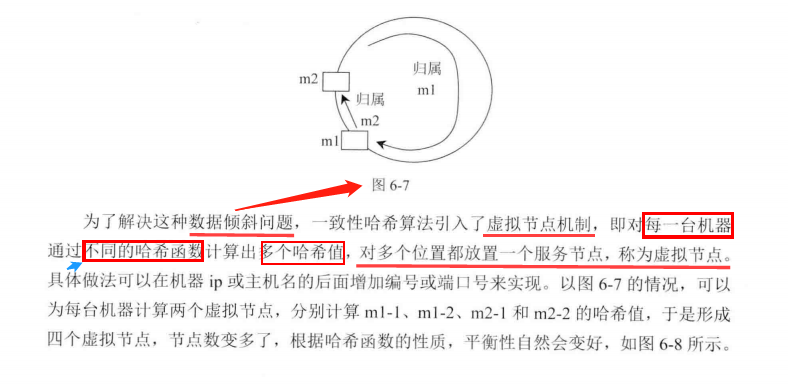
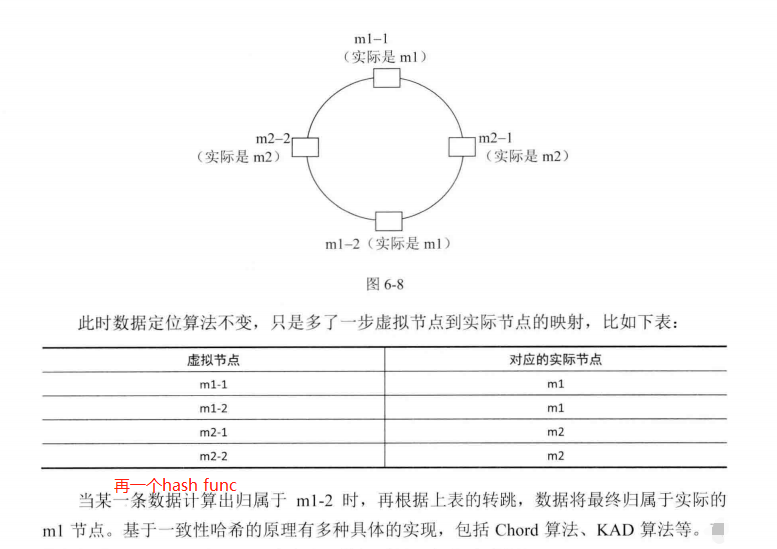
一致性哈希


若有收获,就点个赞吧
0 人点赞
