为什么使用ES
传统的数据库查询,假如现在有一个商品表
需求1:从 title 获取包含“手机”的数据
select * from goods where title like ‘%手机%’
这个sql存在的问题:
- 使用like时,以‘%’开头,会导致索引失效,这时候全表扫描,效率低
而且,如果表中数据太多,比如:1亿条,假设1秒钟查询十万,也需要1000秒,速度慢
需求2:从 title 获取包含“华为手机”的数据
select * from goods where title like ‘%华为手机%’,这个sql根本就查不出来
总结,使用数据库查询
- 效率低
- 功能弱
两种索引
假设有一本古诗集,包含
《静夜思》窗前明月光,疑是地上霜。举头望明月,低头思故乡。《水调歌头》明月几时有?把酒问青天。不知天上宫阙,今夕是何年?.....《月下独酌四首》花间一壶酒,独酌无相亲。举杯邀明月,对影成三人。.....
正向索引
搜索逻辑:先看《静夜思》里有没有“明月”,有就记录,再看《水调歌头》里有没有“明月”,有就记录。。。。
就这样一首一首的判断下去,很明显效率很慢
反向索引
又称:倒排索引,按照规则,对文本内容进行分词,拆分出不同的词条(term)
比如:床前明月光,就可能分成:床前、明月、光、月光 等词
所以它最终的索引结构:
这样就能根据“明月”快速的查询到对应古诗
总结:倒排索引,对文档内容进行分词,最终得出词条和文档唯一标示(文档id)的对应关系
ES的存储和搜索原理
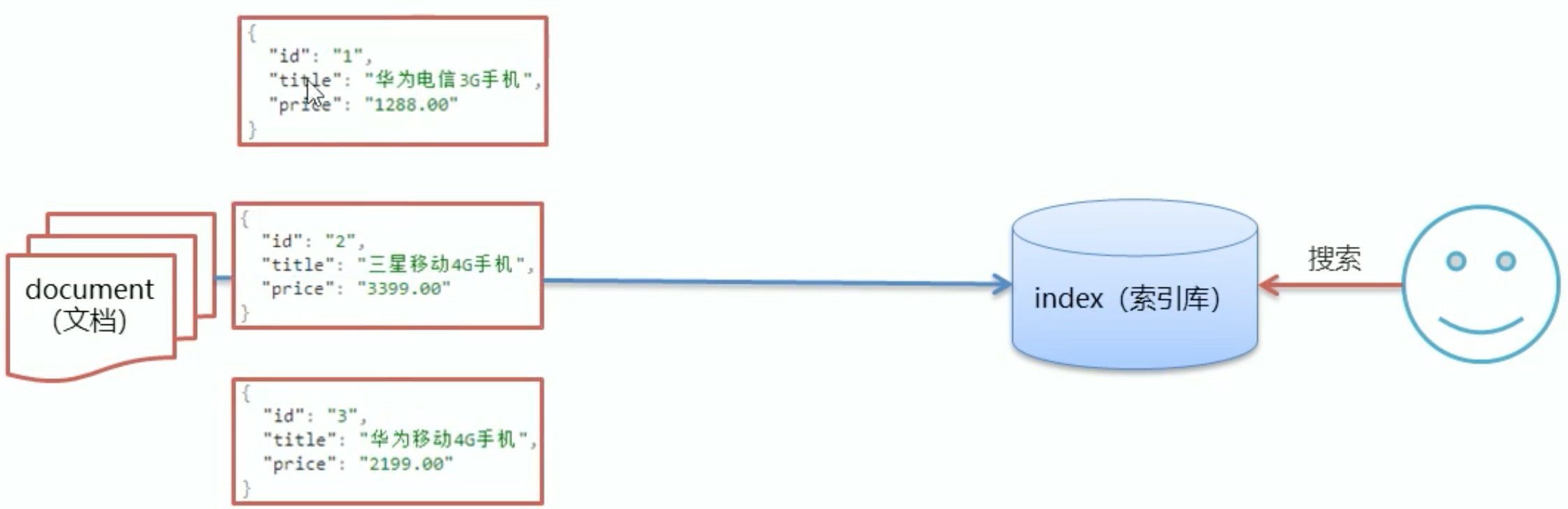
ES中存在文档、索引库着两个概念
- 文档经过分词后存到索引库
- ES中的文档是json
- 索引库存储着词条跟文档的对应关系,并向用户提供搜索服务
倒排索引建立的过程:
| id | title |
|---|---|
| 1 | 华为 电信3G手机 |
| 2 | 三星 移动4G手机 |
- id=1 的数据第一个存进来,分词后
- 然后 id=2 的数据进来,分词后:三星、移动、4G、手机
- 三星、移动、4G是新增的词条,手机是已存在的词条
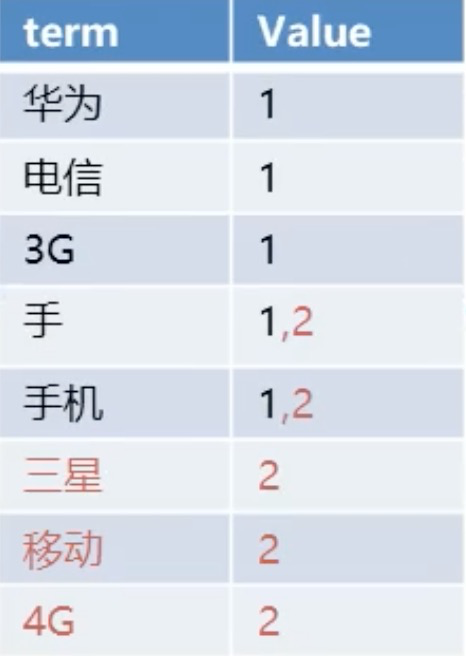

就这样,文档以倒排索引的方式存放到索引库
同时也会对词条进行处理,形成树形结构,有点儿类似数据库中跟某个字段建立索引,目的是提高查询速度
查询时,如果用户输入“华为手机”
Elasticvue-Index
打开 extension://geifniocjfnfilcbeloeidajlfmhdlgo/index.html#/cluster/0/rest
创建索引
创建Index = create table
PUT /gb
{"mappings": {"properties": {"tweet": {"type": "text"},"date": {"type": "date"},"name": {"type": "text"},"user_id": {"type": "long"}}}}

更新Index
更新Index-PUT = alert table
PUT /gb/_mapping
{"properties" : {"tag" : {"type" : "text"}}}
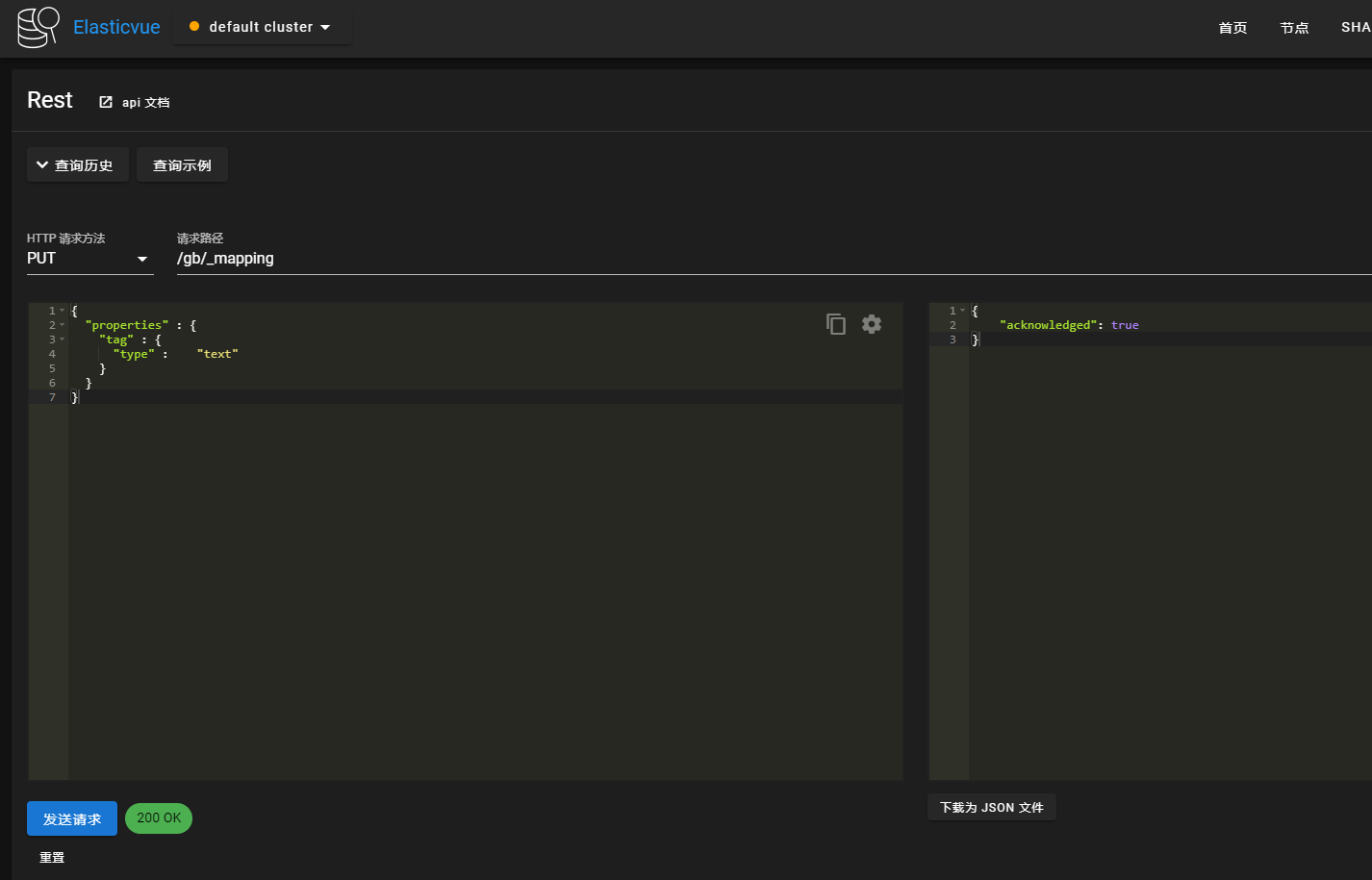
获取index
GET /gb
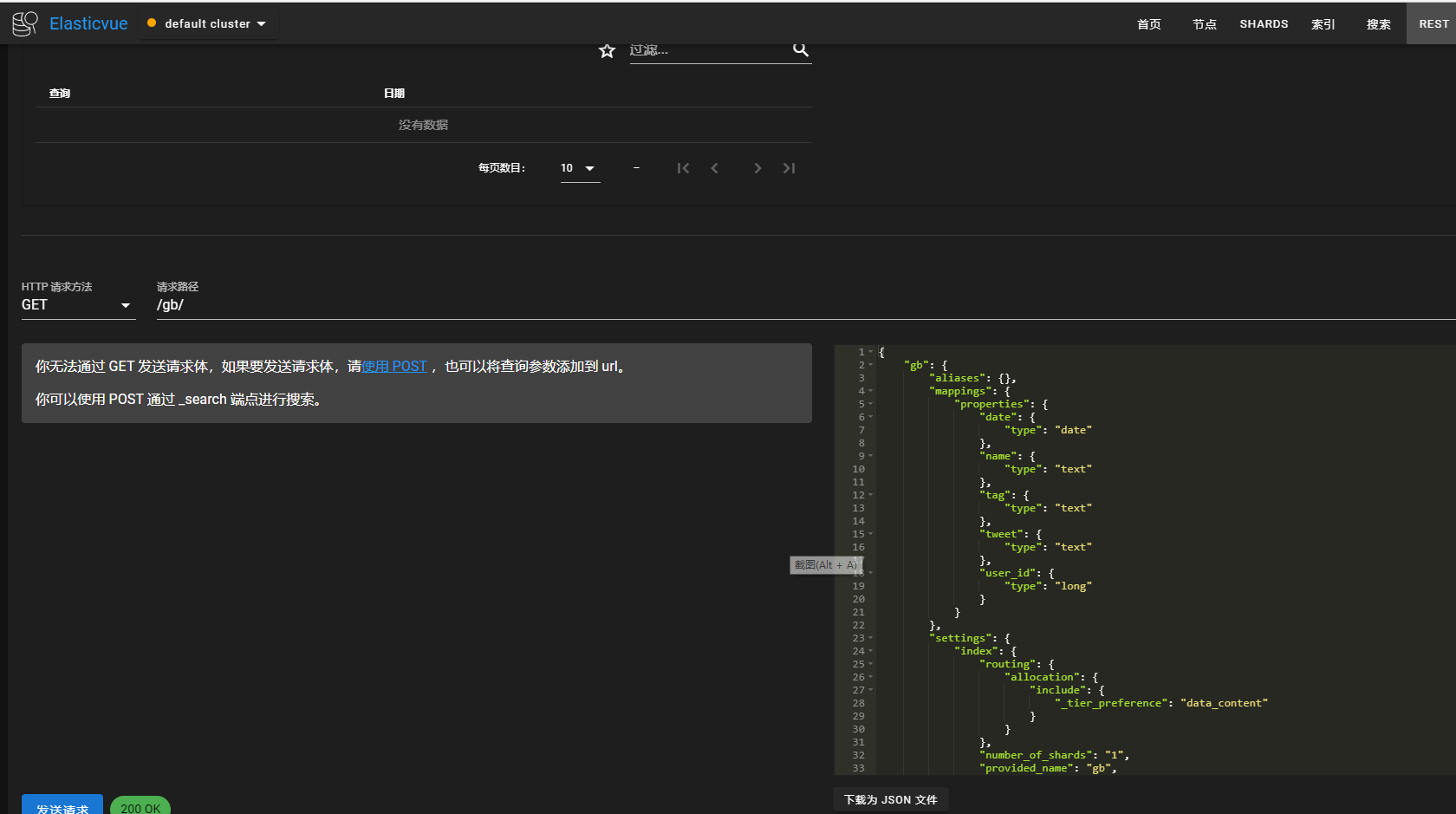
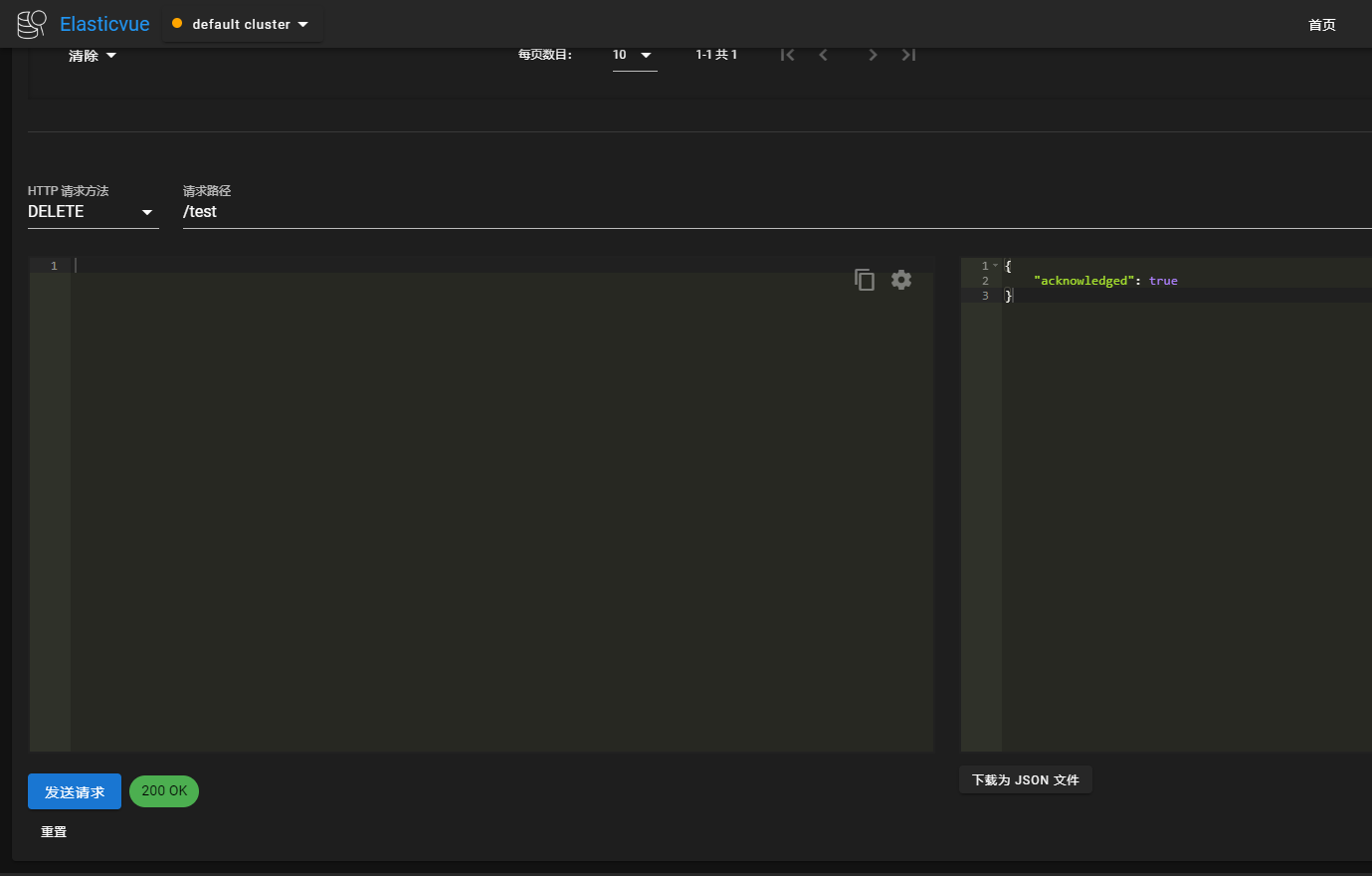
删除index
DELETE /test
Elasticvue-Doc
新增doc(自动生成文档id)
通过 POST index_name/_doc 系统会自动生成document id
POST /longfc/_doc
{"username": "xiaoming_new"}
返回
{"_index": "longfc","_id": "Uw4QnYMBUnW7A9JlFtkY","_version": 1,"result": "created","_shards": {"total": 3,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1}

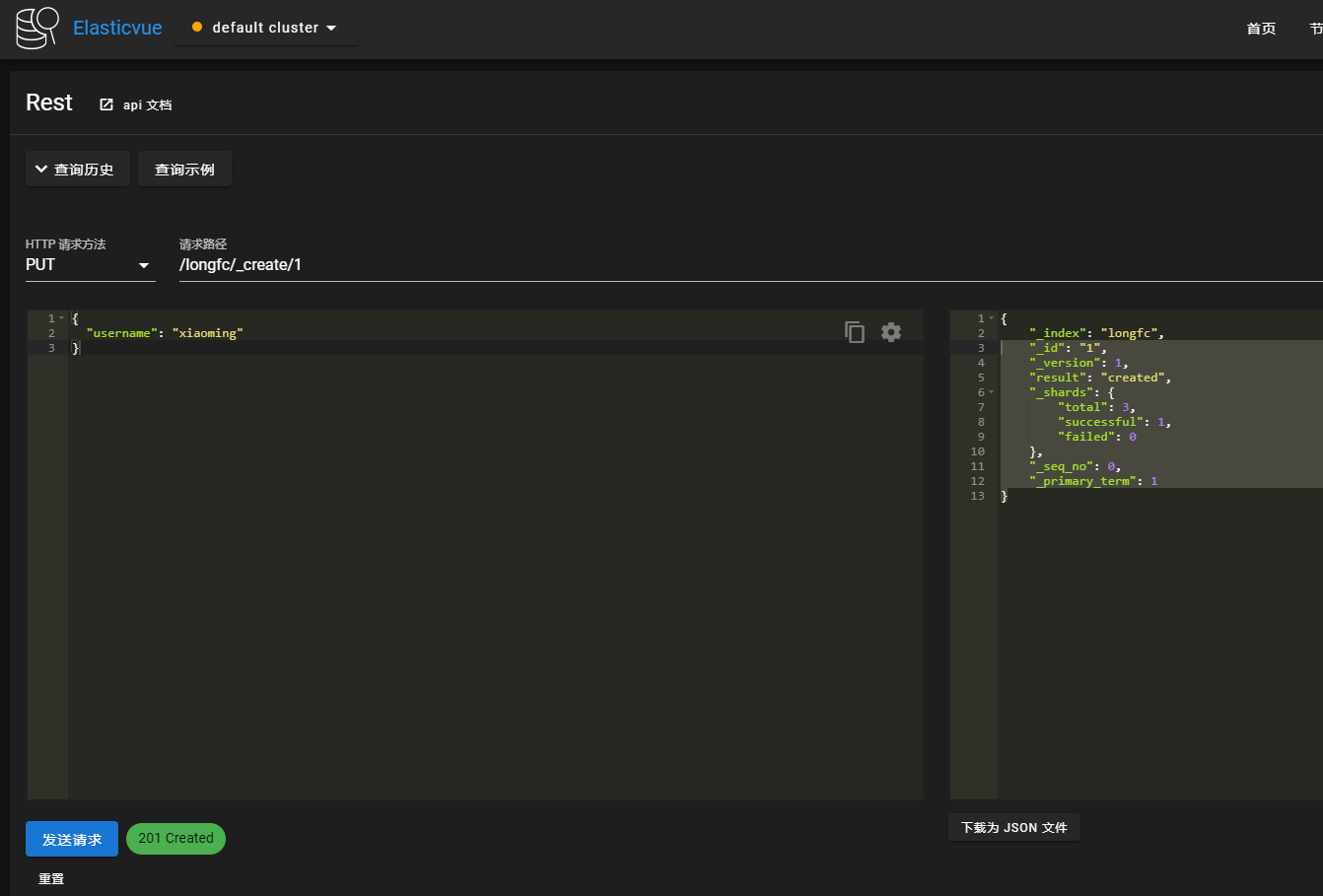
新增doc(指定文档id)
通过 PUT index_name/_create/doc_id ,例如doc_id为1,则可以指定id创建。如果该id对应的文档已经存在,则操作失败
PUT /longfc/_create/1
{"username": "xiaoming"}
返回
{"_index": "longfc","_id": "1","_version": 1,"result": "created","_shards": {"total": 3,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1}
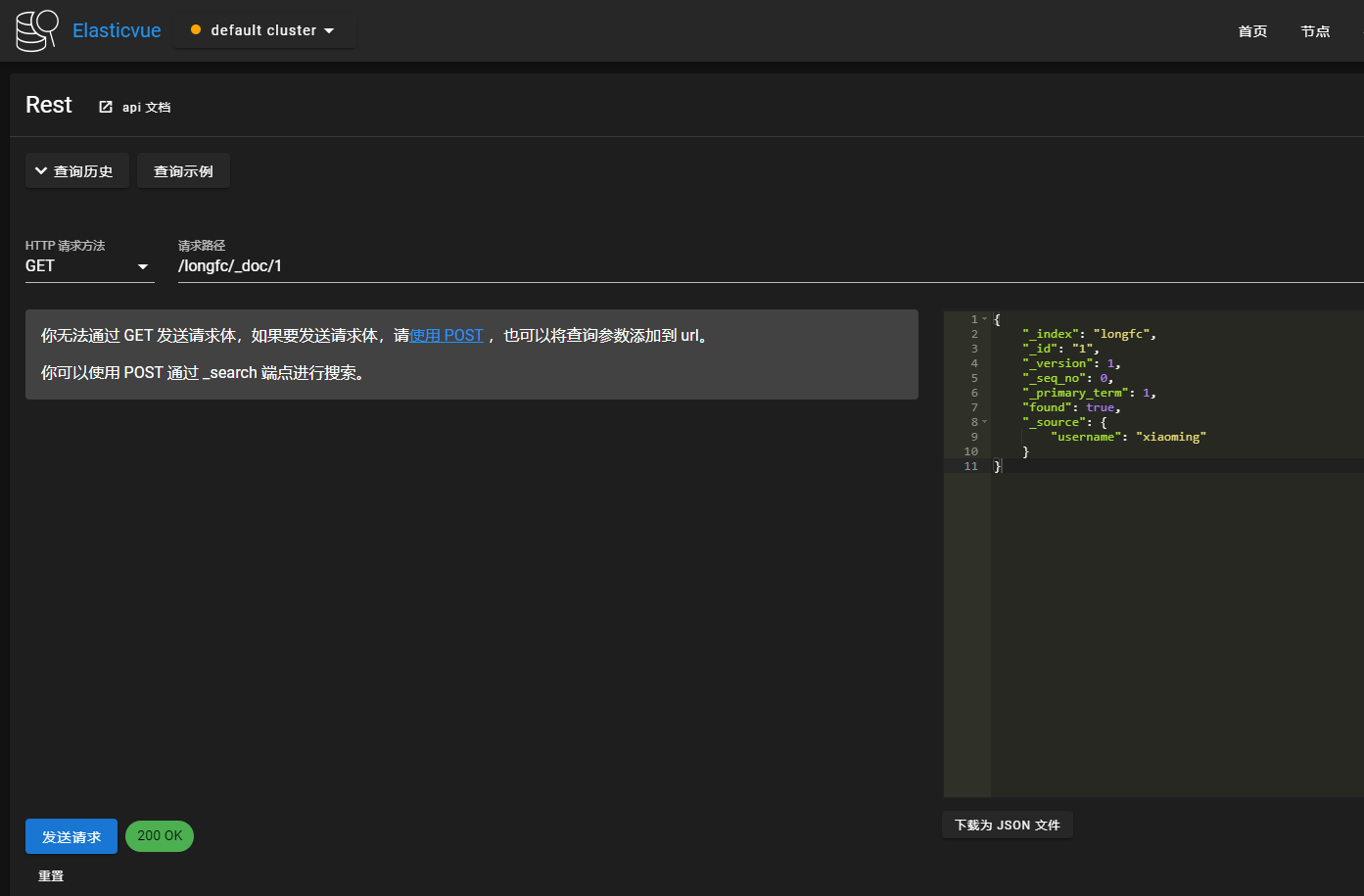
获取文档
GET /longfc/_doc/1
返回
{"_index": "longfc","_id": "1","_version": 1,"_seq_no": 0,"_primary_term": 1,"found": true,"_source": {"username": "xiaoming"}}
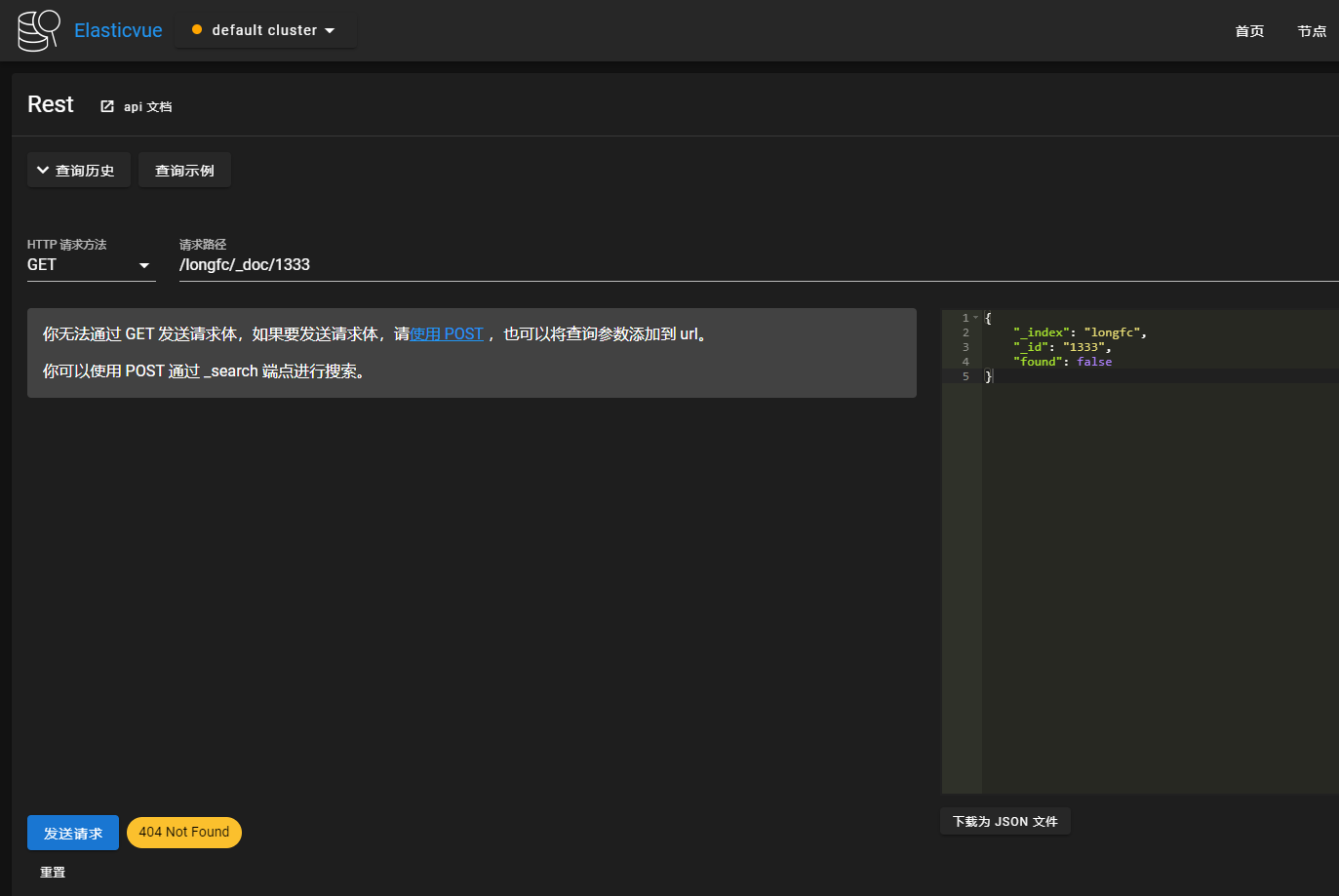
如里文档不存在,如以下查询
GET /longfc/_doc/1333
则返回
{"_index": "longfc","_id": "1333","found": false}
更新文档
- Update方法不会删除原来的文档,是真正的更新数据
- POST方法 / Payload需要包含在
doc中 - 可以用来新增字段
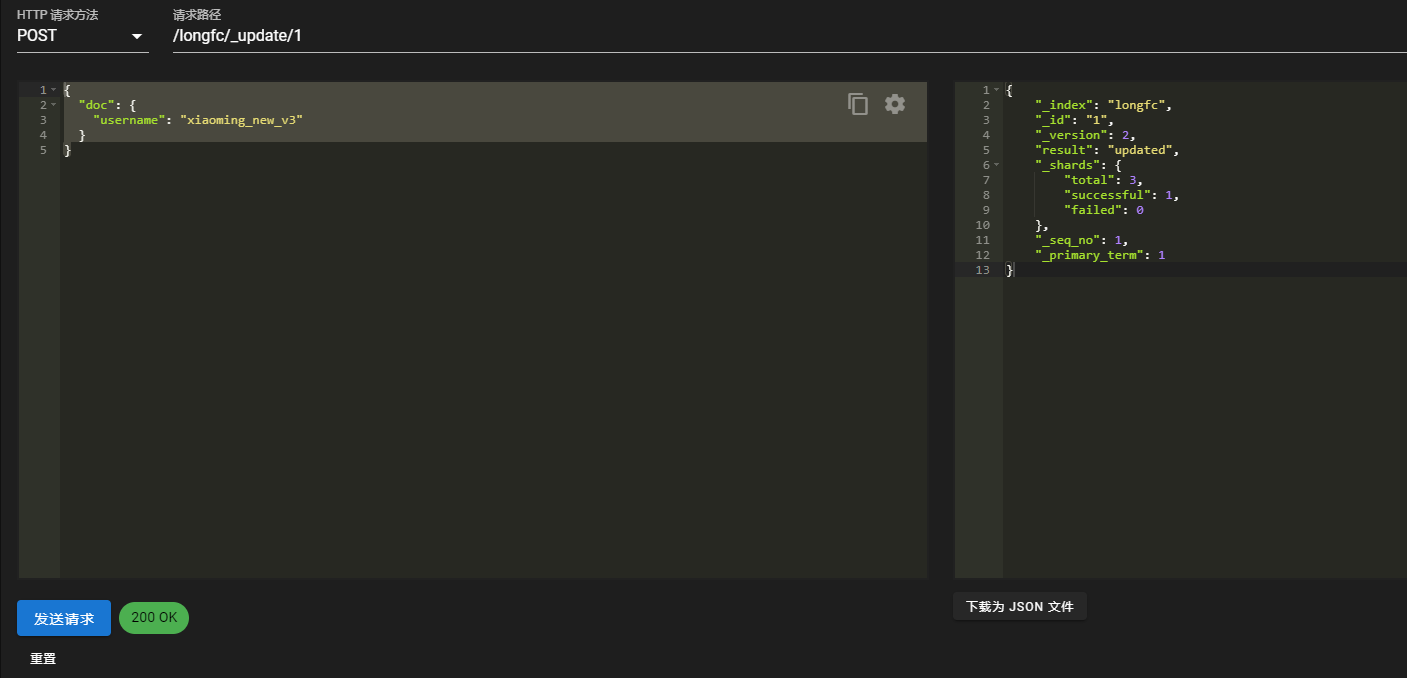
POST /longfc/_update/1
返回{"doc": {"fullname": "xiaoming_new_v3"}}
“_version”字段又增加了1{"_index": "longfc","_id": "1","_version": 2,"result": "updated","_shards": {"total": 3,"successful": 1,"failed": 0},"_seq_no": 1,"_primary_term": 1}
文档为1的其他内容如username还存在

若有收获,就点个赞吧
0 人点赞
