链接: https://www.cnblogs.com/shujiying/p/12386505.html
在学习Reactor模式之前,我们需要对“I/O的四种模型”以及“什么是I/O多路复用”进行简单的介绍,因为Reactor是一个使用了同步非阻塞的I/O多路复用机制的模式。
I/O的四种模型
I/O 操作 主要分成两部分
① 数据准备,将数据加载到内核缓存
② 将内核缓存中的数据加载到用户缓存
- Synchronous blocking I/O
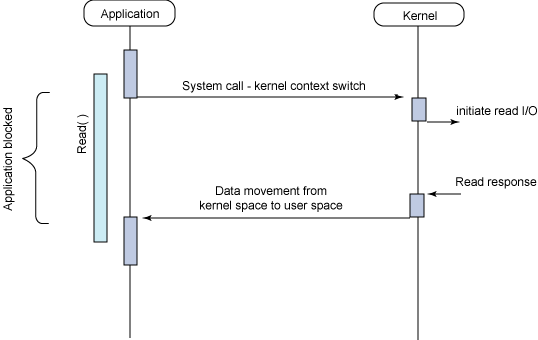
Typical flow of the synchronous blocking I/O model
- Synchronous non-blocking I/O
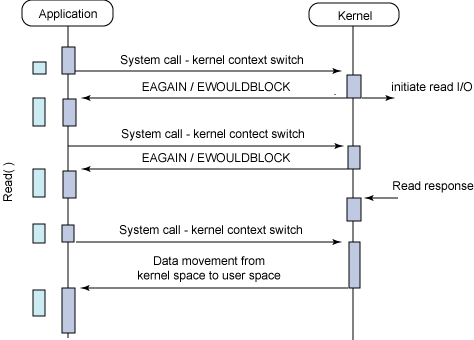
Typical flow of the synchronous non-blocking I/O model
- Asynchronous blocking I/O
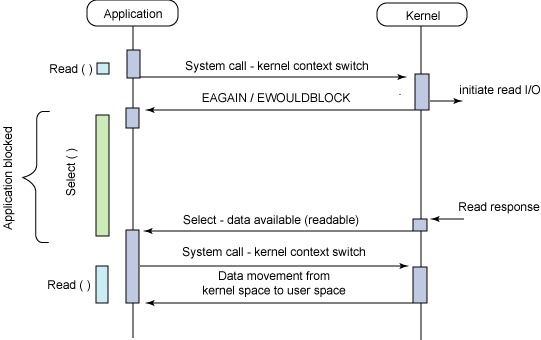
Typical flow of the asynchronous blocking I/O model (select)
- Asynchronous non-blocking I/O
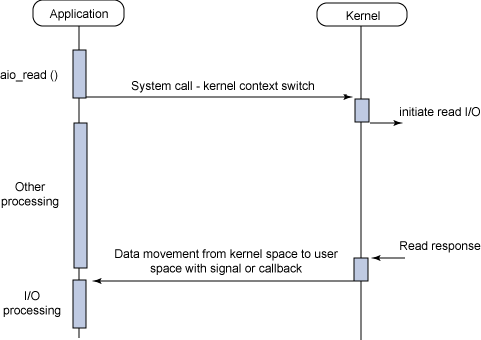
Typical flow of the asynchronous non-blocking I/O model
堵塞、非堵塞的区别是在于第一阶段,即数据准备阶段。无论是堵塞还是非堵塞,都是用应用主动找内核要数据,而read数据的过程是‘堵塞’的,直到数据读取完。
同步、异步的区别在于第二阶段,若由请求者主动的去获取数据,则为同步操作,需要说明的是:read/write操作也是‘堵塞’的,直到数据读取完。
若数据的read都由kernel内核完成了(在内核read数据的过程中,应用进程依旧可以执行其他的任务),这就是异步操作。
换句话说,BIO里用户最关心“我要读”,NIO里用户最关心”我可以读了”,在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步阻塞的(消耗CPU但性能非常高)。
NIO是一种同步非阻塞的I/O模型,也是I/O多路复用的基础。
I/O多路复用
I/O多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
一般情况下,I/O 复用机制需要事件分发器。 事件分发器的作用,将那些读写事件源分发给各读写事件的处理者。
涉及到事件分发器的两种模式称为:Reactor和Proactor。 Reactor模式是基于同步I/O的,而Proactor模式是和异步I/O相关的。本文主要介绍的就是 Reactor模式相关的知识。
经典的I/O服务设计 ———— BIO模式
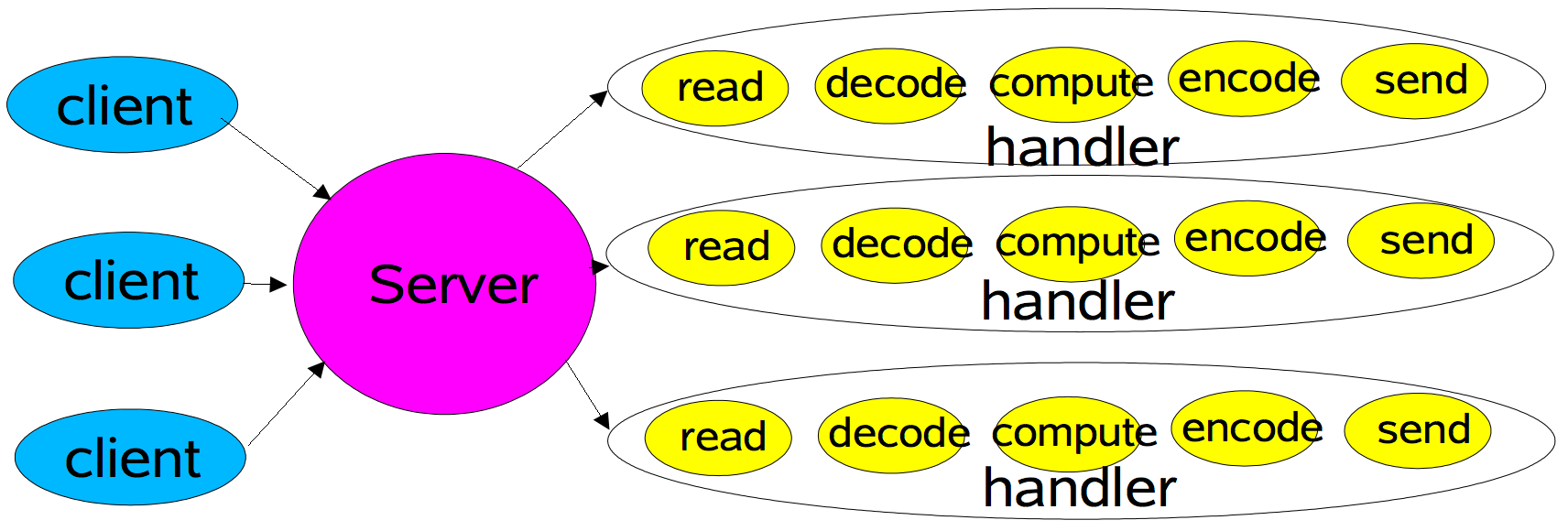
这就是经典的每连接对应一个线程的同步阻塞I/O模式。
- 流程:
① 服务器端的Server是一个线程,线程中执行一个死循环来阻塞的监听客户端的连接请求和通信。
② 当客户端向服务器端发送一个连接请求后,服务器端的Server会接受客户端的请求,ServerSocket.accept()从阻塞中返回,得到一个与客户端连接相对于的Socket。
③ 构建一个handler,将Socket传入该handler。创建一个线程并启动该线程,在线程中执行handler,这样与客户端的所有的通信以及数据处理都在该线程中执行。当该客户端和服务器端完成通信关闭连接后,线程就会被销毁。
④ 然后Server继续执行accept()操作等待新的连接请求。 - 优点:
① 使用简单,容易编程
② 在多核系统下,能够充分利用了多核CPU的资源。即,当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。 - 缺点:
该模式的本质问题在于严重依赖线程,但线程Java虚拟机非常宝贵的资源。随着客户端并发访问量的急剧增加,线程数量的不断膨胀将服务器端的性能将急剧下降。
① 线程生命周期的开销非常高。线程的创建与销毁并不是没有代价的。在Linux这样的操作系统中,线程本质上就是一个进程,创建和销毁都是重量级的系统函数。
② 资源消耗。 内存:大量空闲的线程会占用许多内存,给垃圾回收器带来压力; CPU:如果你已经拥有足够多的线程使所有CPU保持忙碌状态,那么再创建更过的线程反而会降低性能。
③ 稳定性。在可创建线程的数量上存在一个限制。这个限制值将随着平台的不同而不同,并且受多个因素制约:a)JVM的启动参数; b)Threa的构造函数中请求的栈大小; c)底层操作系统对线程的限制 等。如果破坏了这些限制,那么很可能抛出OutOfMemoryError异常。
④ 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,不仅会带来许多无用的上下文切换,还可能导致执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统负载偏高、CPU sy(系统CPU)使用率特别高,导致系统几乎陷入不可用的状态。
⑤ 容易造成锯齿状的系统负载。一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
⑥ 若是长连接的情况下并且客户端与服务器端交互并不频繁的,那么客户端和服务器端的连接会一直保留着,对应的线程也就一直存在在,但因为不频繁的通信,导致大量线程在大量时间内都处于空置状态。 - 适用场景:如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的IO服务器实现可能非常契合。
Reactor模式
Reactor模式(反应器模式)是一种处理一个或多个客户端并发交付服务请求的事件设计模式。当请求抵达后,服务处理程序使用I/O多路复用策略,然后同步地派发这些请求至相关的请求处理程序。
Reactor结构
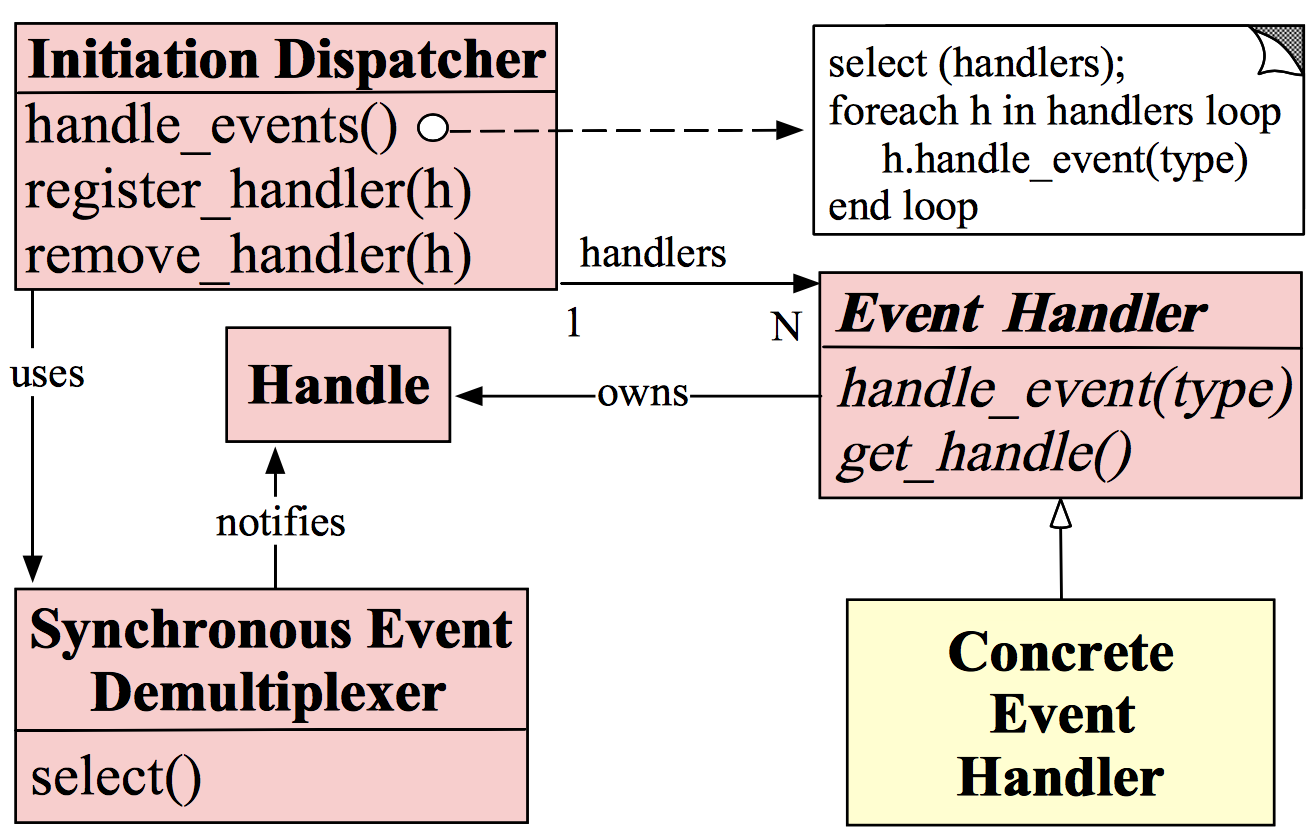
Reactor模式的角色构成(Reactor模式一共有5中角色构成):
- Handle(句柄或描述符,在Windows下称为句柄,在Linux下称为描述符):本质上表示一种资源(比如说文件描述符,或是针对网络编程中的socket描述符),是由操作系统提供的;该资源用于表示一个个的事件,事件既可以来自于外部,也可以来自于内部;外部事件比如说客户端的连接请求,客户端发送过来的数据等;内部事件比如说操作系统产生的定时事件等。它本质上就是一个文件描述符,Handle是事件产生的发源地。
- Synchronous Event Demultiplexer(同步事件分离器):它本身是一个系统调用,用于等待事件的发生(事件可能是一个,也可能是多个)。调用方在调用它的时候会被阻塞,一直阻塞到同步事件分离器上有事件产生为止。对于Linux来说,同步事件分离器指的就是常用的I/O多路复用机制,比如说select、poll、epoll等。在Java NIO领域中,同步事件分离器对应的组件就是Selector;对应的阻塞方法就是select方法。
- Event Handler(事件处理器):本身由多个回调方法构成,这些回调方法构成了与应用相关的对于某个事件的反馈机制。在Java NIO领域中并没有提供事件处理器机制让我们调用或去进行回调,是由我们自己编写代码完成的。Netty相比于Java NIO来说,在事件处理器这个角色上进行了一个升级,它为我们开发者提供了大量的回调方法,供我们在特定事件产生时实现相应的回调方法进行业务逻辑的处理,即,ChannelHandler。ChannelHandler中的方法对应的都是一个个事件的回调。
- Concrete Event Handler(具体事件处理器):是事件处理器的实现。它本身实现了事件处理器所提供的各种回调方法,从而实现了特定于业务的逻辑。它本质上就是我们所编写的一个个的处理器实现。
- Initiation Dispatcher(初始分发器):实际上就是Reactor角色。它本身定义了一些规范,这些规范用于控制事件的调度方式,同时又提供了应用进行事件处理器的注册、删除等设施。它本身是整个事件处理器的核心所在,Initiation Dispatcher会通过Synchronous Event Demultiplexer来等待事件的发生。一旦事件发生,Initiation Dispatcher首先会分离出每一个事件,然后调用事件处理器,最后调用相关的回调方法来处理这些事件。Netty中ChannelHandler里的一个个回调方法都是由bossGroup或workGroup中的某个EventLoop来调用的。
Reactor模式流程
① 初始化Initiation Dispatcher,然后将若干个Concrete Event Handler注册到Initiation Dispatcher中。当应用向Initiation Dispatcher注册Concrete Event Handler时,会在注册的同时指定感兴趣的事件,即,应用会标识出该事件处理器希望Initiation Dispatcher在某些事件发生时向其发出通知,事件通过Handle来标识,而Concrete Event Handler又持有该Handle。这样,事件 ————> Handle ————> Concrete Event Handler 就关联起来了。
② Initiation Dispatcher 会要求每个事件处理器向其传递内部的Handle。该Handle向操作系统标识了事件处理器。
③ 当所有的Concrete Event Handler都注册完毕后,应用会调用handle_events方法来启动Initiation Dispatcher的事件循环。这是,Initiation Dispatcher会将每个注册的Concrete Event Handler的Handle合并起来,并使用Synchronous Event Demultiplexer(同步事件分离器)同步阻塞的等待事件的发生。比如说,TCP协议层会使用select同步事件分离器操作来等待客户端发送的数据到达连接的socket handler上。
比如,在Java中通过Selector的select()方法来实现这个同步阻塞等待事件发生的操作。在Linux操作系统下,select()的实现中 a)会将已经注册到Initiation Dispatcher的事件调用epollCtl(epfd, opcode, fd, events)注册到linux系统中,这里fd表示Handle,events表示我们所感兴趣的Handle的事件;b)通过调用epollWait方法同步阻塞的等待已经注册的事件的发生。不同事件源上的事件可能同时发生,一旦有事件被触发了,epollWait方法就会返回;c)最后通过发生的事件找到相关联的SelectorKeyImpl对象,并设置其发生的事件为就绪状态,然后将SelectorKeyImpl放入selectedSet中。这样一来我们就可以通过Selector.selectedKeys()方法得到事件就绪的SelectorKeyImpl集合了。
④ 当与某个事件源对应的Handle变为ready状态时(比如说,TCP socket变为等待读状态时),Synchronous Event Demultiplexer就会通知Initiation Dispatcher。
⑤ Initiation Dispatcher会触发事件处理器的回调方法,从而响应这个处于ready状态的Handle。当事件发生时,Initiation Dispatcher会将被事件源激活的Handle作为『key』来寻找并分发恰当的事件处理器回调方法。
⑥ Initiation Dispatcher会回调事件处理器的handle_event(type)回调方法来执行特定于应用的功能(开发者自己所编写的功能),从而相应这个事件。所发生的事件类型可以作为该方法参数并被该方法内部使用来执行额外的特定于服务的分离与分发。
Reactor模式的实现方式
单线程Reactor模式
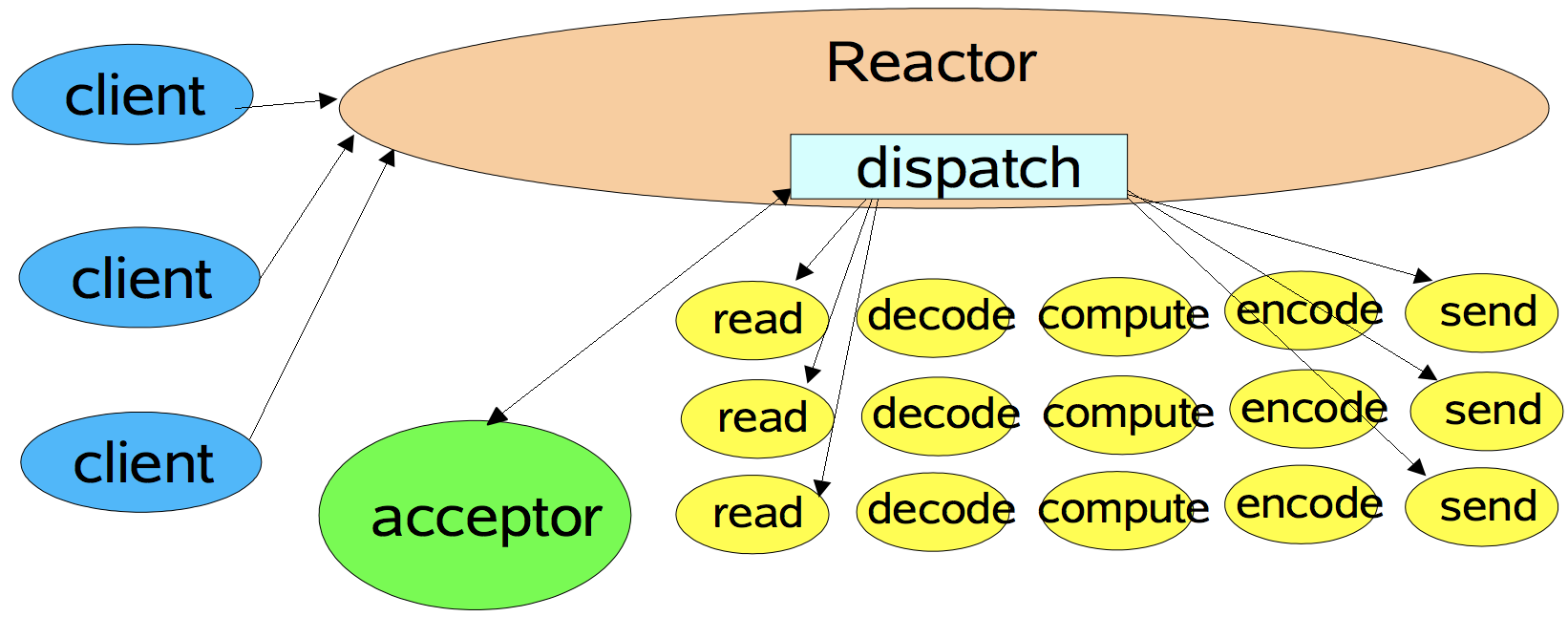
流程:
① 服务器端的Reactor是一个线程对象,该线程会启动事件循环,并使用Selector来实现IO的多路复用。注册一个Acceptor事件处理器到Reactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样Reactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。
② 客户端向服务器端发起一个连接请求,Reactor监听到了该ACCEPT事件的发生并将该ACCEPT事件派发给相应的Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将该连接所关注的READ事件以及对应的READ事件处理器注册到Reactor中,这样一来Reactor就会监听该连接的READ事件了。或者当你需要向客户端发送数据时,就向Reactor注册该连接的WRITE事件和其处理器。
③ 当Reactor监听到有读或者写事件发生时,将相关的事件派发给对应的处理器进行处理。比如,读处理器会通过SocketChannel的read()方法读取数据,此时read()操作可以直接读取到数据,而不会堵塞与等待可读的数据到来。
④ 每当处理完所有就绪的感兴趣的I/O事件后,Reactor线程会再次执行select()阻塞等待新的事件就绪并将其分派给对应处理器进行处理。
注意,Reactor的单线程模式的单线程主要是针对于I/O操作而言,也就是所以的I/O的accept()、read()、write()以及connect()操作都在一个线程上完成的。
但在目前的单线程Reactor模式中,不仅I/O操作在该Reactor线程上,连非I/O的业务操作也在该线程上进行处理了,这可能会大大延迟I/O请求的响应。所以我们应该将非I/O的业务逻辑操作从Reactor线程上卸载,以此来加速Reactor线程对I/O请求的响应。
改进:使用工作者线程池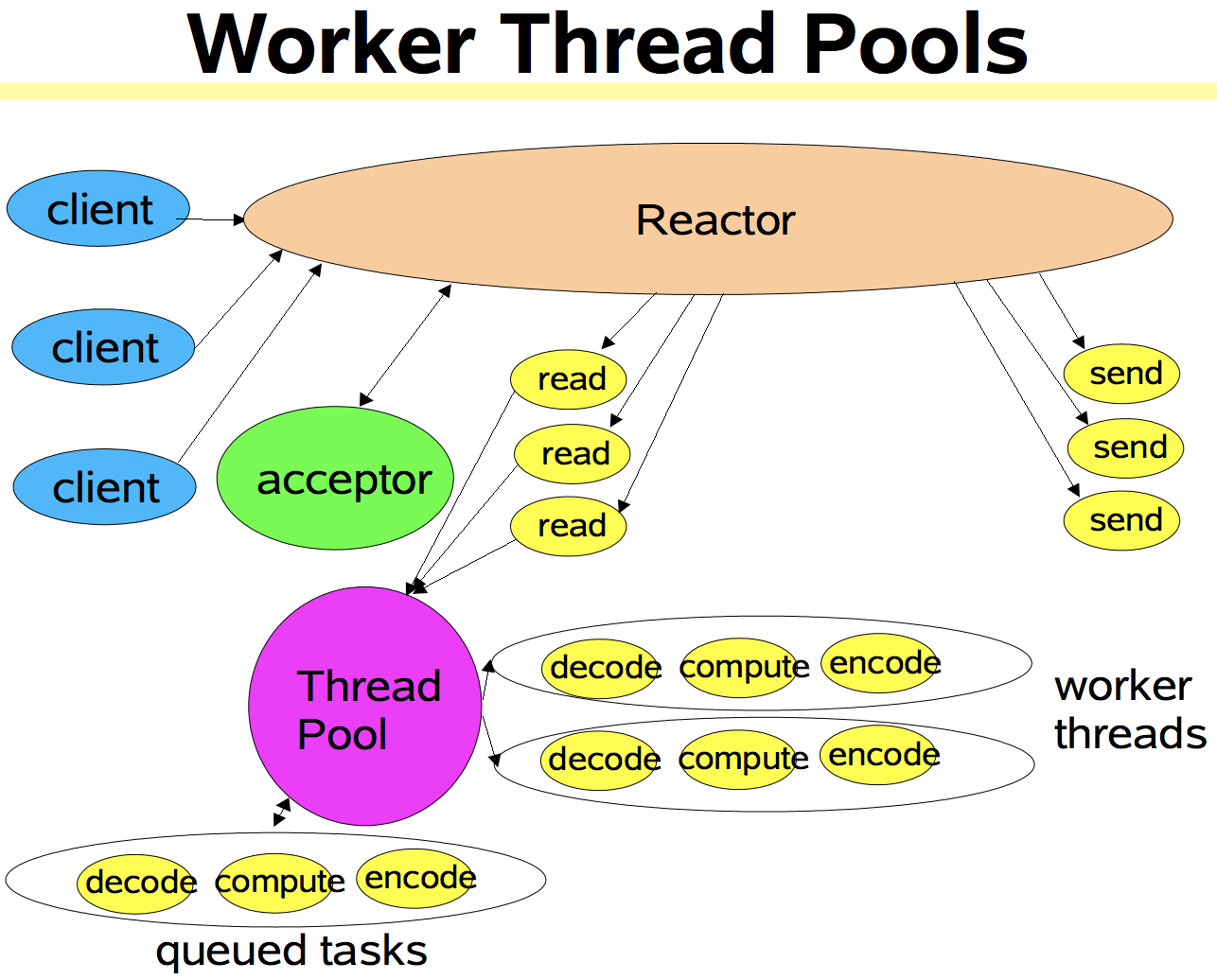
与单线程Reactor模式不同的是,添加了一个工作者线程池,并将非I/O操作从Reactor线程中移出转交给工作者线程池来执行。这样能够提高Reactor线程的I/O响应,不至于因为一些耗时的业务逻辑而延迟对后面I/O请求的处理。
使用线程池的优势:
① 通过重用现有的线程而不是创建新线程,可以在处理多个请求时分摊在线程创建和销毁过程产生的巨大开销。
② 另一个额外的好处是,当请求到达时,工作线程通常已经存在,因此不会由于等待创建线程而延迟任务的执行,从而提高了响应性。
③ 通过适当调整线程池的大小,可以创建足够多的线程以便使处理器保持忙碌状态。同时还可以防止过多线程相互竞争资源而使应用程序耗尽内存或失败。
注意,在上图的改进的版本中,所以的I/O操作依旧由一个Reactor来完成,包括I/O的accept()、read()、write()以及connect()操作。
对于一些小容量应用场景,可以使用单线程模型。但是对于高负载、大并发或大数据量的应用场景却不合适,主要原因如下:
① 一个NIO线程同时处理成百上千的链路,性能上无法支撑,即便NIO线程的CPU负荷达到100%,也无法满足海量消息的读取和发送;
② 当NIO线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO线程的负载,最终会导致大量消息积压和处理超时,成为系统的性能瓶颈;
多Reactor线程模式
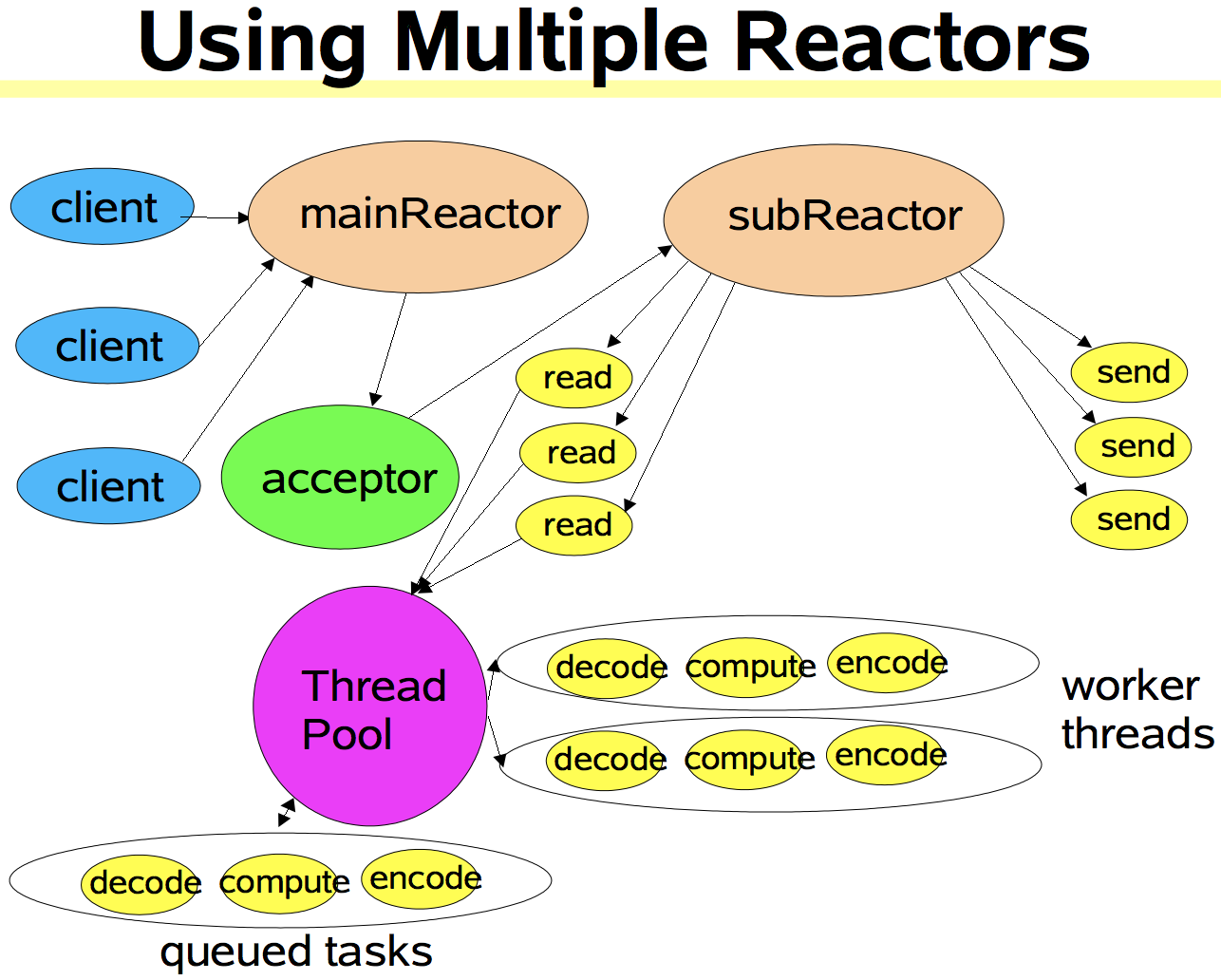
Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的事件循环逻辑。
mainReactor可以只有一个,但subReactor一般会有多个。mainReactor线程主要负责接收客户端的连接请求,然后将接收到的SocketChannel传递给subReactor,由subReactor来完成和客户端的通信。
流程:
① 注册一个Acceptor事件处理器到mainReactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样mainReactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。启动mainReactor的事件循环。
② 客户端向服务器端发起一个连接请求,mainReactor监听到了该ACCEPT事件并将该ACCEPT事件派发给Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将这个SocketChannel传递给subReactor线程池。
③ subReactor线程池分配一个subReactor线程给这个SocketChannel,即,将SocketChannel关注的READ事件以及对应的READ事件处理器注册到subReactor线程中。当然你也注册WRITE事件以及WRITE事件处理器到subReactor线程中以完成I/O写操作。Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的循环逻辑。
④ 当有I/O事件就绪时,相关的subReactor就将事件派发给响应的处理器处理。注意,这里subReactor线程只负责完成I/O的read()操作,在读取到数据后将业务逻辑的处理放入到线程池中完成,若完成业务逻辑后需要返回数据给客户端,则相关的I/O的write操作还是会被提交回subReactor线程来完成。
注意,所以的I/O操作(包括,I/O的accept()、read()、write()以及connect()操作)依旧还是在Reactor线程(mainReactor线程 或 subReactor线程)中完成的。Thread Pool(线程池)仅用来处理非I/O操作的逻辑。
多Reactor线程模式将“接受客户端的连接请求”和“与该客户端的通信”分在了两个Reactor线程来完成。mainReactor完成接收客户端连接请求的操作,它不负责与客户端的通信,而是将建立好的连接转交给subReactor线程来完成与客户端的通信,这样一来就不会因为read()数据量太大而导致后面的客户端连接请求得不到即时处理的情况。并且多Reactor线程模式在海量的客户端并发请求的情况下,还可以通过实现subReactor线程池来将海量的连接分发给多个subReactor线程,在多核的操作系统中这能大大提升应用的负载和吞吐量。
Netty 与 Reactor模式
Netty的线程模式就是一个实现了Reactor模式的经典模式。
- 结构对应:
NioEventLoop ———— Initiation Dispatcher
Synchronous EventDemultiplexer ———— Selector
Evnet Handler ———— ChannelHandler
ConcreteEventHandler ———— 具体的ChannelHandler的实现 - 模式对应:
Netty服务端使用了“多Reactor线程模式”
mainReactor ———— bossGroup(NioEventLoopGroup) 中的某个NioEventLoop
subReactor ———— workerGroup(NioEventLoopGroup) 中的某个NioEventLoop
acceptor ———— ServerBootstrapAcceptor
ThreadPool ———— 用户自定义线程池 - 流程:
① 当服务器程序启动时,会配置ChannelPipeline,ChannelPipeline中是一个ChannelHandler链,所有的事件发生时都会触发Channelhandler中的某个方法,这个事件会在ChannelPipeline中的ChannelHandler链里传播。然后,从bossGroup事件循环池中获取一个NioEventLoop来现实服务端程序绑定本地端口的操作,将对应的ServerSocketChannel注册到该NioEventLoop中的Selector上,并注册ACCEPT事件为ServerSocketChannel所感兴趣的事件。
② NioEventLoop事件循环启动,此时开始监听客户端的连接请求。
③ 当有客户端向服务器端发起连接请求时,NioEventLoop的事件循环监听到该ACCEPT事件,Netty底层会接收这个连接,通过accept()方法得到与这个客户端的连接(SocketChannel),然后触发ChannelRead事件(即,ChannelHandler中的channelRead方法会得到回调),该事件会在ChannelPipeline中的ChannelHandler链中执行、传播。
④ ServerBootstrapAcceptor的readChannel方法会该SocketChannel(客户端的连接)注册到workerGroup(NioEventLoopGroup) 中的某个NioEventLoop的Selector上,并注册READ事件为SocketChannel所感兴趣的事件。启动SocketChannel所在NioEventLoop的事件循环,接下来就可以开始客户端和服务器端的通信了。

若有收获,就点个赞吧
0 人点赞
