- 利用 kubeadm 创建高可用集群
- 查看可用docker版本
- 安装指定版本docker
- 添加用户到docker组
- 当前会话立即更新docker组
- 修改cgroup驱动为systemd[k8s官方推荐]、限制容器日志量、修改存储类型,最后的docker家目录可修改
- 添加开机自启,立即启动
- —disableexcludes=kubernetes 禁掉除了这个之外的别的仓库
- 将 SELinux 设置为 permissive 模式(相当于将其禁用)
- kubeadm-config.yaml
- !/bin/bash
- Script For Quick Pull K8S Docker Images
- pull kubernetes images from hub.docker.com
- pull aliyuncs mirror docker images
- retag to k8s.gcr.io prefix
- untag origin tag, the images won’t be delete.
- ——————————————————————————————————-
- Global settings
- ——————————————————————————————————-
- ——————————————————————————————————-
- common defaults that all the ‘listen’ and ‘backend’ sections will
- use if not designated in their block
- ——————————————————————————————————-
- ——————————————————————————————————-
- apiserver frontend which proxys to the control plane nodes
- ——————————————————————————————————-
- ——————————————————————————————————-
- round robin balancing for apiserver
- ——————————————————————————————————-
- !/bin/sh
- 五、配置自动补全命令
利用 kubeadm 创建高可用集群
高可用拓扑
可以设置 HA 集群:
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存;
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行;
1、堆叠(Stacked) etcd 拓扑

主要特点:
- etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行。
- 每个控制平面节点运行 kube-apiserver,kube-scheduler 和 kube-controller-manager 实例。
- kube-apiserver 使用 LB 暴露给工作节点。
- 每个控制平面节点创建一个本地 etcd 成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
- 简单概况:每个 master 节点上运行一个 apiserver 和 etcd, etcd 只与本节点 apiserver 通信。
- 这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群,设置起来更简单,而且更易于副本管理。
- 然而堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都将丢失,并且冗余会受到影响。可以通过添加更多控制平面节点来降低此风险。应该为 HA 集群运行至少三个堆叠的控制平面节点(防止脑裂)。
这是 kubeadm 中的默认拓扑。当使用 kubeadm init 和 kubeadm join —control-plane 时,在控制平面节点上会自动创建本地 etcd 成员。
2、外部 etcd 拓扑
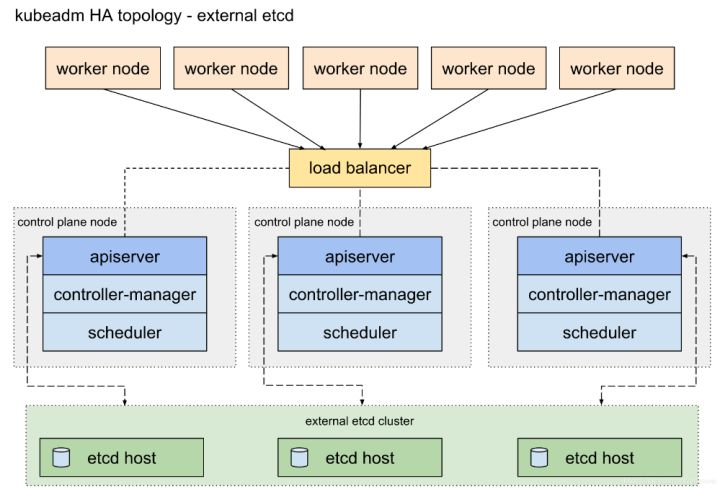
主要特点:具有外部 etcd 的 HA 集群是一种这样的拓扑,其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。
- 就像堆叠的 etcd 拓扑一样,外部 etcd 拓扑中的每个控制平面节点都运行 kube-apiserver,kube-scheduler 和 kube-controller-manager 实例。
- 同样 kube-apiserver 使用负载均衡器暴露给工作节点。但是,etcd 成员在不同的主机上运行,每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信。
- 简单概况: etcd 集群运行在单独的主机上,每个 etcd 都与 apiserver 节点通信。
- 这种拓扑结构解耦了控制平面和 etcd 成员。因此,它提供了一种 HA 设置,其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余。
- 但是,此拓扑需要两倍于堆叠 HA 拓扑的主机数量。具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机。
-
3、小结
官方这里主要是解决了高可用场景下 apiserver 与 etcd 集群的关系,以及控制平面节点防止单点故障。但是集群对外访问接口不可能将三个 apiserver 都暴露出去,一个节点挂掉时还是不能自动切换到其他节点。官方只提到了一句“使用负载均衡器将 apiserver 暴露给工作节点”,而这恰恰是部署过程中需要解决的重点问题。
Notes: 此处的负载均衡器并不是 kube-proxy,此处的 Load Balancer 是针对 apiserver 的。
最后,我们总结一下两种拓扑: 堆叠(Stacked) etcd 拓扑:设置简单,易于副本管理 ,不过存在耦合失败风险。如果节点发生故障,则 etcd 成员和控制平面实例有丢失的可能,推荐测试开发环境;
- 外部 etcd 拓扑:解耦了控制平面和 etcd 成员,不会像堆叠的 HA 拓扑那样有影响集群冗余的风险,不过需要两倍于堆叠 HA 拓扑的主机数量,设置相对复杂,推荐生产环境。
部署架构
以下是我们在测试环境所用的部署架构:
这里采用 kubeadm 方式搭建高可用 k8s 集群,k8s 集群的高可用实际是 k8s 各核心组件的高可用,这里使用主备模式:
- apiserver 通过 keepalived+haproxy 实现高可用,当某个节点故障时触发 keepalived vip 转移,haproxy 负责将流量负载到 apiserver 节点;
- controller-manager k8s 内部通过选举方式产生领导者(由 —leader-elect 选型控制,默认为 true),同一时刻集群内只有一个 controller-manager 组件运行,其余处于 backup 状态;
- scheduler k8s 内部通过选举方式产生领导者(由 —leader-elect 选型控制,默认为 true),同一时刻集群内只有一个scheduler组件运行,其余处于 backup 状态;
- etcd 通过运行 kubeadm 方式自动创建集群来实现高可用,部署的节点数为奇数,3节点方式最多容忍一台机器宕机。
一、安装kubeadm
1.1、准备工作
- 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
- 每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
- 2 CPU 核或更多
- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 开启机器上的某些端口。请参见这里 了解更多详细信息。
- 禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区。
1.1.1、硬件信息
| 主机hostname | IP地址 | 安装组件 | 主机配置 | explain |
|---|---|---|---|---|
| master-01 | 10.113.66.167 | docker-ce v20.10.9 yum-utils v1.1.31 device-mapper-persistent-data v0.8.5 lvm2 v2.02.187 kubeadm v1.22.7 kubelet v1.22.7 kubectl v1.22.7 |
4C-8G | control plane |
| master-02 | 10.113.66.153 | 4C-8G | ||
| master-03 | 10.113.66.157 | 4C-8G | ||
| work-01 | 10.113.65.74 | docker-ce v20.10.9 yum-utils v1.1.31 device-mapper-persistent-data v0.8.5 lvm2 v2.02.187 kubeadm v1.22.7 kubelet v1.22.7 kubectl v1.22.7 |
4C-8G | worker nodes |
| work-02 | 4C-8G | |||
| VIP | 172.16.106.187 | 在control plane浮动 |
1.1.2、保证环境正确性
| purpose | commands |
|---|---|
| 保证集群各节点互通 | ping -c 3 |
| 保证MAC地址唯一 | ip link 或 ifconfig -a |
| 保证集群内主机名唯一 | 查询 hostnamectl status,修改 hostnamectl set-hostname |
| 保证系统产品uuid唯一 | sudo cat /sys/class/dmi/id/product_uuid |
修改MAC地址参考命令:
ifconfig eth0 downifconfig eth0 hw ether 00:0C:18:EF:FF:EDifconfig eth0 up
如product_uuid不唯一,请考虑重装CentOS系统.
1.1.3、检查所需端口
启用这些必要的端口后才能使 Kubernetes 的各组件相互通信。可以使用 telnet 来检查端口是否启用,例如:
telnet 127.0.0.1 6443
控制面
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API server | 所有 |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 10259 | kube-scheduler | 自身 |
| TCP | 入站 | 10257 | kube-controller-manager | 自身 |
尽管 etcd 的端口也列举在控制面的部分,但你也可以在外部自己托管 etcd 集群或者自定义端口。
工作节点
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 30000-32767 | NodePort Services | 所有 |
1.1.4、禁用swap
swap仅当内存不够时会使用硬盘块充当额外内存,硬盘的io较内存差距极大,禁用swap以提高性能
各节点均需执行:
swapoff -ased -i 's/.*swap.*/#&/' /etc/fstab
1.1.5、安装 runtime
官网:安装runtime
这里以为docker为例,所有节点均需安装部署docker。
安装docker
删掉旧的docker
sudo yum remove docker docker-common docker-selinux docker-engine
安装一些依赖
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
根据你的发行版下载repo文件:
wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.sangfor.org/assistants/docker/centos/docker-ce.repo
安装指定版本docker ```
查看可用docker版本
yum list docker-ce.x86_64 —showduplicates | sort -r
安装指定版本docker
yum install -y docker-ce-19.03.12-3.el7
> 这里以安装19.03.12版本举例,注意版本号不包含:与之前的数字5. **添加用户到docker组**非root用户,无需sudo即可使用docker命令
添加用户到docker组
usermod -aG docker
当前会话立即更新docker组
newgrp docker
6. **配置docker**
$ mkdir /etc/docker
修改cgroup驱动为systemd[k8s官方推荐]、限制容器日志量、修改存储类型,最后的docker家目录可修改
cat > /etc/docker/daemon.json <<EOF { “exec-opts”: [“native.cgroupdriver=systemd”], “log-driver”: “json-file”, “log-opts”: { “max-size”: “100m” }, “storage-driver”: “overlay2”, “storage-opts”: [ “overlay2.override_kernel_check=true” ], “registry-mirrors”: [“https://7uuu3esz.mirror.aliyuncs.com“], “data-root”: “/data/docker” } EOF
添加开机自启,立即启动
$ systemctl enable —now docker
<a name="J86ck"></a>#### 1.1.6、确保网络模块开机自动加载
lsmod | grep overlay lsmod | grep br_netfilter
若上面命令无返回值输出或提示文件不存在,需执行以下命令:
cat > /etc/modules-load.d/docker.conf <<EOF overlay br_netfilter EOF
modprobe overlay modprobe br_netfilter
<a name="vGbFy"></a>
#### 1.1.7、允许桥接流量对iptables可见
各节点均需执行:
cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sysctl —system
验证是否生效,均返回 1 即正确
sysctl -n net.bridge.bridge-nf-call-iptables sysctl -n net.bridge.bridge-nf-call-ip6tables
<a name="Rxwau"></a>
## 二、安装 kubeadm、kubelet 和 kubectl
你需要在每台机器上安装以下的软件包:
- kubeadm:用来初始化集群的指令。
- kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
- kubectl:用来与集群通信的命令行工具。
<a name="qbFGw"></a>
### 2.1、配置kubernetes源
首先配置内部kubernetes源: 配置文件 /etc/yum.repos.d/kubernetes.repo
[kubernetes] name=Kubernetes baseurl=http://mirrors.sangfor.org/nexus/repository/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.sangfor.org/nexus/repository/kubernetes/yum/doc/yum-key.gpg http://mirrors.sangfor.org/nexus/repository/kubernetes/yum/doc/rpm-package-key.gpg
执行
sudo yum makecache
<a name="uDseE"></a>
### 2.2、各节点均需安装kubeadm、kubelet,kubectl
yum install -y kubelet-1.22.7 kubeadm-1.22.7 kubectl-1.22.7 —disableexcludes=kubernetes
—disableexcludes=kubernetes 禁掉除了这个之外的别的仓库
systemctl enable —now kubelet
<a name="v6RpJ"></a>
#### 2.2.1、禁用selinux
关闭 SELinux,否则 kubelet 挂载目录时可能报错 `Permission denied`,可以设置为`permissive`或`disabled`,`permissive` 会提示warn信息
将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0 sudo sed -i ‘s/^SELINUX=enforcing$/SELINUX=permissive/‘ /etc/selinux/config
**注意:**
- 通过运行命令 setenforce 0 和 sed ... 将 SELinux 设置为 permissive 模式 可以有效地将其禁用。 这是允许容器访问主机文件系统所必需的,而这些操作时为了例如 Pod 网络工作正常。你必须这么做,直到 kubelet 做出对 SELinux 的支持进行升级为止。
- 如果你知道如何配置 SELinux 则可以将其保持启用状态,但可能需要设定 kubeadm 不支持的部分配置。
kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
<a name="JnNRt"></a>
## 三、配置 cgroup 驱动程序
容器运行时和 kubelet 都具有名字为 ["cgroup driver"](https://kubernetes.io/zh/docs/setup/production-environment/container-runtimes/) 的属性,该属性对于在 Linux 机器上管理 CGroups 而言非常重要。
> **警告:**
> 你需要确保容器运行时和 kubelet 所使用的是相同的 cgroup 驱动,否则 kubelet 进程会失败。
kubeadm 支持在执行 kubeadm init 时,传递一个 KubeletConfiguration 结构体。 KubeletConfiguration 包含 cgroupDriver 字段,可用于控制 kubelet 的 cgroup 驱动。
> **说明:** 在版本 1.22 中,如果用户没有在 KubeletConfiguration 中设置 cgroupDriver 字段, kubeadm init 会将它设置为默认值 systemd。
这是一个最小化的示例,其中显式的配置了此字段:
kubeadm-config.yaml
kind: ClusterConfiguration apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 cgroupDriver: systemd
这样一个配置文件就可以传递给 kubeadm 命令了:
kubeadm init —config kubeadm-config.yaml
> **说明:**
> Kubeadm 对集群所有的节点,使用相同的 KubeletConfiguration。 KubeletConfiguration 存放于 kube-system 命名空间下的某个 [ConfigMap](https://kubernetes.io/zh/docs/concepts/configuration/configmap) 对象中。
> 执行 init、join 和 upgrade 等子命令会促使 kubeadm 将 KubeletConfiguration 写入到文件 /var/lib/kubelet/config.yaml 中, 继而把它传递给本地节点的 kubelet。
**相关细节可参见**[配置 cgroup 驱动](https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/configure-cgroup-driver/)**。**
<a name="m5cWH"></a>
## 四、利用 kubeadm 创建高可用集群
<a name="I52dO"></a>
### 4.1、拉取k8s镜像
查看指定k8s版本需要哪些镜像
$ kubeadm config images list —kubernetes-version v1.22.7
k8s.gcr.io/kube-apiserver:v1.22.7 k8s.gcr.io/kube-controller-manager:v1.22.7 k8s.gcr.io/kube-scheduler:v1.22.7 k8s.gcr.io/kube-proxy:v1.22.7 k8s.gcr.io/pause:3.5 k8s.gcr.io/etcd:3.5.0-0 k8s.gcr.io/coredns/coredns:v1.8.4
在 /root/k8s 目录下,新建脚本get-k8s-images.sh,内容如下:
!/bin/bash
Script For Quick Pull K8S Docker Images
KUBE_VERSION=v1.18.5 PAUSE_VERSION=3.2 CORE_DNS_VERSION=1.6.7 ETCD_VERSION=3.4.3-0
pull kubernetes images from hub.docker.com
docker pull kubeimage/kube-proxy-amd64:$KUBE_VERSION docker pull kubeimage/kube-controller-manager-amd64:$KUBE_VERSION docker pull kubeimage/kube-apiserver-amd64:$KUBE_VERSION docker pull kubeimage/kube-scheduler-amd64:$KUBE_VERSION
pull aliyuncs mirror docker images
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:$PAUSE_VERSION docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:$CORE_DNS_VERSION docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:$ETCD_VERSION
retag to k8s.gcr.io prefix
docker tag kubeimage/kube-proxy-amd64:$KUBE_VERSION k8s.gcr.io/kube-proxy:$KUBE_VERSION docker tag kubeimage/kube-controller-manager-amd64:$KUBE_VERSION k8s.gcr.io/kube-controller-manager:$KUBE_VERSION docker tag kubeimage/kube-apiserver-amd64:$KUBE_VERSION k8s.gcr.io/kube-apiserver:$KUBE_VERSION docker tag kubeimage/kube-scheduler-amd64:$KUBE_VERSION k8s.gcr.io/kube-scheduler:$KUBE_VERSION docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:$PAUSE_VERSION k8s.gcr.io/pause:$PAUSE_VERSION docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:$CORE_DNS_VERSION k8s.gcr.io/coredns:$CORE_DNS_VERSION docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:$ETCD_VERSION k8s.gcr.io/etcd:$ETCD_VERSION
untag origin tag, the images won’t be delete.
docker rmi kubeimage/kube-proxy-amd64:$KUBE_VERSION docker rmi kubeimage/kube-controller-manager-amd64:$KUBE_VERSION docker rmi kubeimage/kube-apiserver-amd64:$KUBE_VERSION docker rmi kubeimage/kube-scheduler-amd64:$KUBE_VERSION docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:$PAUSE_VERSION docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:$CORE_DNS_VERSION docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:$ETCD_VERSION
脚本添加可执行权限,执行脚本拉取镜像:
chmod +x get-k8s-images.sh ./get-k8s-images.sh
拉取完成,执行 docker images 查看镜像<br />
<a name="h6y9n"></a>
### 4.2、配置负载均衡
官网:[配置负载均衡](https://github.com/kubernetes/kubeadm/blob/main/docs/ha-considerations.md#bootstrap-the-cluster)<br />在三个master节点上安装了 Keepalived 和 HAproxy,如果其中一个节点故障,虚拟 IP 地址(即浮动 IP 地址)将自动与另一个节点关联,使集群仍然可以正常运行,从而实现高可用。若有需要,也可以此为目的,添加更多安装 Keepalived 和 HAproxy 的节点。
先运行以下命令安装 Keepalived 和 HAproxy。
yum install keepalived haproxy psmisc -y
<a name="Yfjoa"></a>
#### 4.2.1、配置HAproxy
1、在三台用于负载均衡的机器上运行以下命令以配置 Proxy(三台机器的 Proxy 配置相同):
vi /etc/haproxy/haproxy.cfg
2、以下是示例配置,供您参考:
——————————————————————————————————-
Global settings
——————————————————————————————————-
global log /dev/log local0 log /dev/log local1 notice daemon
——————————————————————————————————-
common defaults that all the ‘listen’ and ‘backend’ sections will
use if not designated in their block
——————————————————————————————————-
defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 1 timeout http-request 10s timeout queue 20s timeout connect 5s timeout client 20s timeout server 20s timeout http-keep-alive 10s timeout check 10s
——————————————————————————————————-
apiserver frontend which proxys to the control plane nodes
——————————————————————————————————-
frontend apiserver bind *:${APISERVER_DEST_PORT} mode tcp option tcplog default_backend apiserver
——————————————————————————————————-
round robin balancing for apiserver
——————————————————————————————————-
backend apiserver option httpchk GET /healthz http-check expect status 200 mode tcp option ssl-hello-chk balance roundrobin server ${HOST1_ID} ${HOST1_ADDRESS}:${APISERVER_SRC_PORT} check
# [...]
各个参数解析:
- ${APISERVER_DEST_PORT} :kubernetes与kube-apiserver交互的端口,也就是loadBanlander服务的端口。
- ${APISERVER_SRC_PORT} :kube-apiserver实例使用的端口,一般默认为6443。
- ${HOST1_ID} :kube-apiserver实例1的主机ID。
- ${HOST1_ADDRESS}:可以解析的地址 (DNS name, IP address) 作为loadBalander第一个主机。
```go
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log /dev/log local0
log /dev/log local1 notice
daemon
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 1
timeout http-request 10s
timeout queue 20s
timeout connect 5s
timeout client 20s
timeout server 20s
timeout http-keep-alive 10s
timeout check 10s
#---------------------------------------------------------------------
# apiserver frontend which proxys to the control plane nodes
#---------------------------------------------------------------------
frontend apiserver
bind *: 8443
mode tcp
option tcplog
default_backend apiserver
#---------------------------------------------------------------------
# round robin balancing for apiserver
#---------------------------------------------------------------------
backend apiserver
option httpchk GET /healthz
http-check expect status 200
mode tcp
option ssl-hello-chk
balance roundrobin
server kube-apiserver-1 192.168.0.31:6443 check
server kube-apiserver-2 192.168.0.32:6443 check
server kube-apiserver-3 192.168.0.33:6443 check
4.2.2、配置keepalived
1、运行以下命令以配置 Keepalived。
vi /etc/keepalived/keepalived.conf
以下是示例配置 (master-01),供您参考:
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state ${STATE}
interface ${INTERFACE}
virtual_router_id ${ROUTER_ID}
priority ${PRIORITY}
authentication {
auth_type PASS
auth_pass ${AUTH_PASS}
}
virtual_ipaddress {
${APISERVER_VIP}
}
track_script {
check_apiserver
}
}
- ${STATE} :一个主机为MASTER,其他主机为BACKUP,因此虚拟IP最初将分配给MASTER。
- ${INTERFACE} :参与虚拟IP协商的网络接口,例如eth0。
- ${ROUTER_ID} :所有保持活的集群主机应该是相同的,而在同一子网中的所有集群中是唯一的。许多发行版将其值预先配置为51。
- ${PRIORITY}: 在控制平面节点上的值应该高于备份节点上的值。因此分别是101和100就足够了。
- ${AUTH_PASS} :对于所有的keepalive集群主机应该是相同的
- ${APISERVER_VIP} :是keepalive集群主机之间协商的虚拟IP地址。 ```go ! Configuration File for keepalived global_defs { router_id LVS_DEVEL } vrrp_script check_apiserver { script “/etc/keepalived/check_apiserver.sh” interval 3 weight -2 fall 10 rise 2 }
vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 50 priority 100 authentication { auth_type PASS auth_pass 111 } virtual_ipaddress { 192.168.0.200 } track_script { check_apiserver } }
上面使用的kube-apiserver健康检测脚本<br />/etc/keepalived/check_apiserver.sh
!/bin/sh
errorExit() { echo “** $“ 1>&2 exit 1 }
curl —silent —max-time 2 —insecure https://localhost:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit “Error GET https://localhost:${APISERVER_DEST_PORT}/“ if ip addr | grep -q ${APISERVER_VIP}; then curl —silent —max-time 2 —insecure https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit “Error GET https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/“ fi
变量参数解析:
- ${APISERVER_VIP} :是keepalive集群主机之间协商的虚拟IP地址。
- ${APISERVER_DEST_PORT} :Kubernetes与API Server通信的端口。
运行方式一:以服务的方式<br />先运行以下命令安装 Keepalived 和 HAproxy。
```go
yum install keepalived haproxy psmisc -y
# systemctl enable haproxy --now
# systemctl enable keepalived --now
运行方式二:静态pod运行
/etc/kubernetes/manifests/keepalived.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: keepalived
namespace: kube-system
spec:
containers:
- image: osixia/keepalived:2.0.17
name: keepalived
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_BROADCAST
- NET_RAW
volumeMounts:
- mountPath: /usr/local/etc/keepalived/keepalived.conf
name: config
- mountPath: /etc/keepalived/check_apiserver.sh
name: check
hostNetwork: true
volumes:
- hostPath:
path: /etc/keepalived/keepalived.conf
name: config
- hostPath:
path: /etc/keepalived/check_apiserver.sh
name: check
status: {}
/etc/kubernetes/manifests/haproxy.yaml:
apiVersion: v1
kind: Pod
metadata:
name: haproxy
namespace: kube-system
spec:
containers:
- image: haproxy:2.1.4
name: haproxy
livenessProbe:
failureThreshold: 8
httpGet:
host: localhost
path: /healthz
port: ${APISERVER_DEST_PORT}
scheme: HTTPS
volumeMounts:
- mountPath: /usr/local/etc/haproxy/haproxy.cfg
name: haproxyconf
readOnly: true
hostNetwork: true
volumes:
- hostPath:
path: /etc/haproxy/haproxy.cfg
type: FileOrCreate
name: haproxyconf
status: {}
4.3、初始化控制平面:
4.3.1、修改kubelet配置默认cgroup driver
cat > /var/lib/kubelet/config.yaml <<EOF
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
EOF
systemctl restart kubelet
4.3.2、生成kubeadm初始化配置文件
[可选] 仅当需自定义初始化配置时用
kubeadm config print init-defaults > init.default.yaml
4.3.3、测试环境是否正常
(WARNING是正常的)
kubeadm init phase preflight [--config kubeadm-init.yaml]
4.3.4、初始化
sudo kubeadm init --kubernetes-version=v1.22.7 \
--control-plane-endpoint "192.168.0.200:8443" \
--pod-network-cidr=10.244.0.0/16 \
--config=init.default.yaml \
--upload-certs
4.3.5、其他控制节点
执行先前由第一个节点上的 kubeadm init 输出提供给你的 join 命令。 它看起来应该像这样:
sudo kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 --control-plane --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07
4.4、安装工作节点
sudo kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv --discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866
五、配置自动补全命令
#安装bash自动补全插件
yum install bash-completion -y
#设置kubectl与kubeadm命令补全,下次login生效
kubectl completion bash >/etc/bash_completion.d/kubectl
kubeadm completion bash > /etc/bash_completion.d/kubeadm

若有收获,就点个赞吧
0 人点赞
