一、基本操作
1、启动
我在本机已经部署三台虚拟机。在第一台和第三台部署了hive
先在第一台上面执行:start-all.sh 启动hadoop。
等待两分钟之后执行下面的语句。
#后台启动 进程挂起 关闭使用jps+ kill -9nohup /export/sofeware/apache-hive-3.1.2-bin/bin/hive --service metastore &nohup /export/sofeware/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
然后到第三台执行:
/export/sofeware/apache-hive-3.1.2-bin/bin/beeline
beeline> ! connect jdbc:hive2://hadoop100:10000
beeline> root
beeline> 直接回车
即可在node3上进入hadoop100 的hive。
2、使用DataGrip连接
连接10000端口,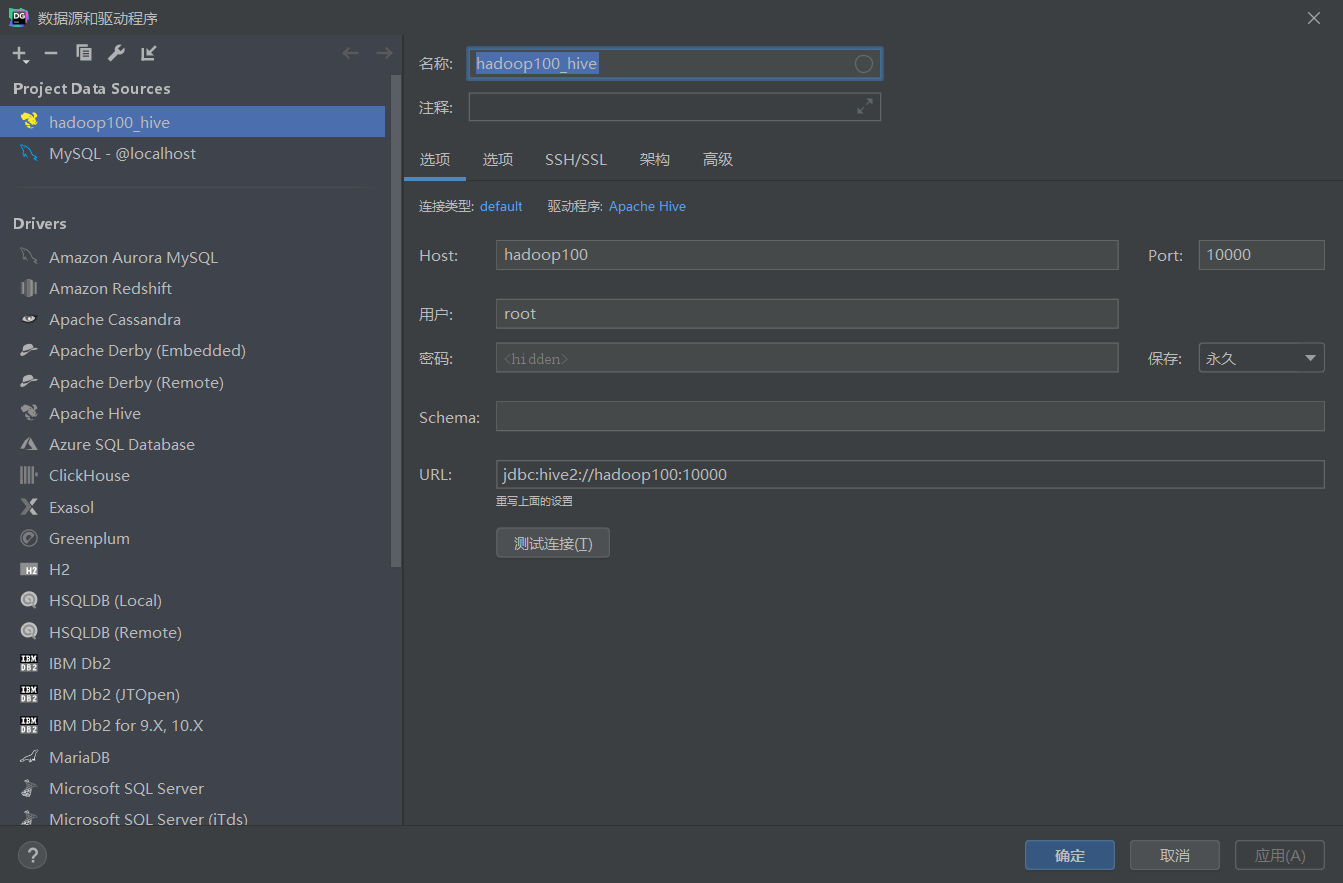
连接成功之后可查看 node1 上面的HDFS 存储的表。
在本机的50070 可查看数据库的内容。
3、建表与插入(hive 初体验)

使用create 建立表格和数据库。
使用insert 插入 耗时极大。
所以比较好的插入数据的方法是:上传结构化数据到HDFS 之后使用建表语句建立对应的表格。建表的时候要加上分隔符。
-- 建表student_HDFS 用于演示从HDFS加载数据
create table student_HDFS(
num int,name string,
sex string,age int,dept string)
row format delimited fields terminated by ',';

二、数据库语句
1、DDL 语言
- 不涉及表内部的数据操作;
- 也叫数据描述语言。
- create alter drop


1、数据类型

2、内部的读写文件机制

READ:先读数据 (使用textinputformat),之后再切割数据(使用 LazySimpleSerDe)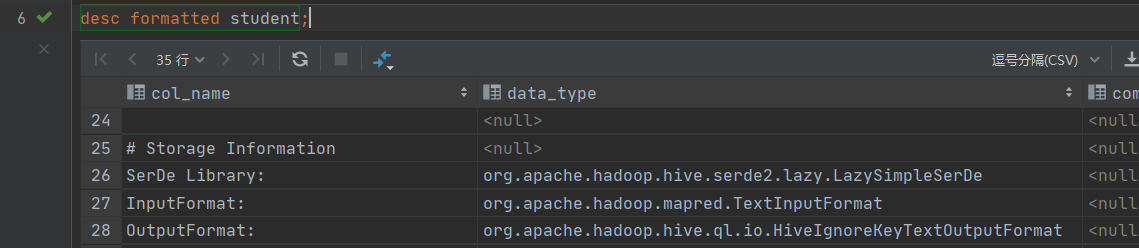
3、SerDe语法


-
4、加载数据
将数据通过 hadoop fs -put 传入HDFS 里面,然后建表。
比如我先上传一个文件到任意位置,然后建表语句就可以通过location 进行定位,但是我的表不会存储在默认数据库下面。5、内部表和外部表
默认为内部表



6、分区表
- 产生背景

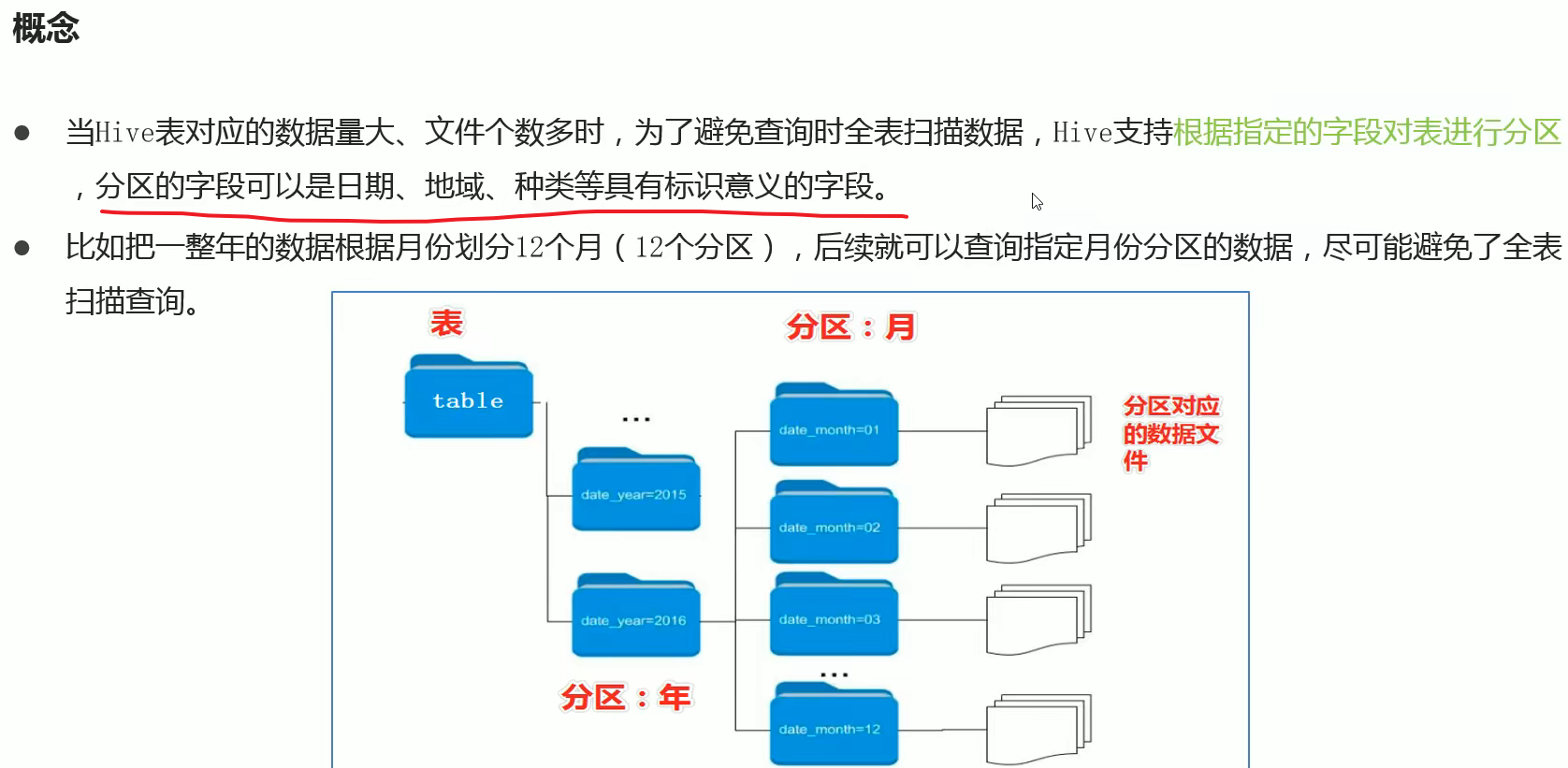
- 使用 建表语句 partitioned by 语句
- 注意分区的字段 不能是 table 主体里面的字段。(可以重新起一个名字。)
那么怎么将数据和新的分区字段对应呢?答案是使用load 加载,加载的时候指定
分区字段=分区值静态分区


- 上面的语句local 代表文件在linux 上面。

- 分区表会在数据上建立各个指定好的文件夹,文件夹下面存储数据。


- 通过 select 语句 动态的确定分区值是什么。


7、分桶表
8、事务表
9、视图
2、DML 语言

3、DQL 语言
三、Hive参数配置与函数、运算符的使用
1、属性配置
2、内置运算符
3、函数入门
4、函数高阶
四、函数应用案例

五、性能优化和hive3 新特性

若有收获,就点个赞吧
0 人点赞
