黑马程序员的课程 20h
Spark 基础入门
第一章:Spark框架概述




- 运行速度快
- 易用
- 通用性强
- 运行方式多

- 完成流式计算,推荐structure streaming 模块。

- 左侧是YARN 右侧是Spark ,角色几乎一致。
-
第二章:Spark环境搭建-Local
local 模式就是一台机器开启一个进程,通过多个线程进行模拟多台服务器。

一个local 进程只能负责一个任务。

我的hadoop 是2.7 版本
因此下载spark包 http://spark.apache.org/downloads.html 下载这个版本
:::info
此处教学在linux 安装anaconda3
1、首先下载 Anaconda3-2021.05-Linux-x86_64.sh 可以指定版本
2、传输到linux的软件安装文件夹
3、cd 到export 的 software 下面 执行
[root@hadoop100 software]# sh ./Anaconda3-2021.05-Linux-x86_64.sh
4、选择安装路径
发现文件太大了
需要清理 var 和 usr 文件夹
使用du -h -x —max-depth=1 查看哪个目录占用过高,对于过大目录中的内容适当删减
5、我的安装目录是 /root/anaconda
6、切换源
7、配置虚拟环境 pyspark
- conda create -n pyspark python=3.8
- 激活环境 conda activate pyspark
- 退出环境 conda deactivate :::
安装本地模式的pyspark
- 解压下载好的spark-3.2.0-bin-hadoop3.2.tgz
- 由于spark目录名称很长, 给其一个软链接:
ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark
- 之后配置环境变量。

- 进入 bin/pyspark 程序, 可以提供一个
交互式的 Python解释器环境, 在这里面可以写普通 python代码, 和spark代码 - Spark 的 UI 界面
第三章:Spark环境搭建-StandAlone
在三台node 上面搭建环境。



第四章:Spark环境搭建-StandAlone-HA

zookeeper 没有安装,所以没有搭建这个 环境。
第五章:Spark环境搭建-Spark On YARN
hadoop100:8088 查看yarn 的页面
启动语句,切换到spark 目录下面,执行: bin/pyspark —master yarn

- 客户端模式看日志比较方便



- 集群模式
第六章:PySpark 安装
- conda activate pyspark
- pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
- conda deactivate
第七章:本机开发环境搭建
本机的 windows 环境的搭建。
连接远程SSH 在自己的机器写代码,在远程服务器跑代码。


在服务器上 运行代码。代码是windows写好上传过去的。读取的文件路径最好是HDFS。
第八章:分布式代码执行分析
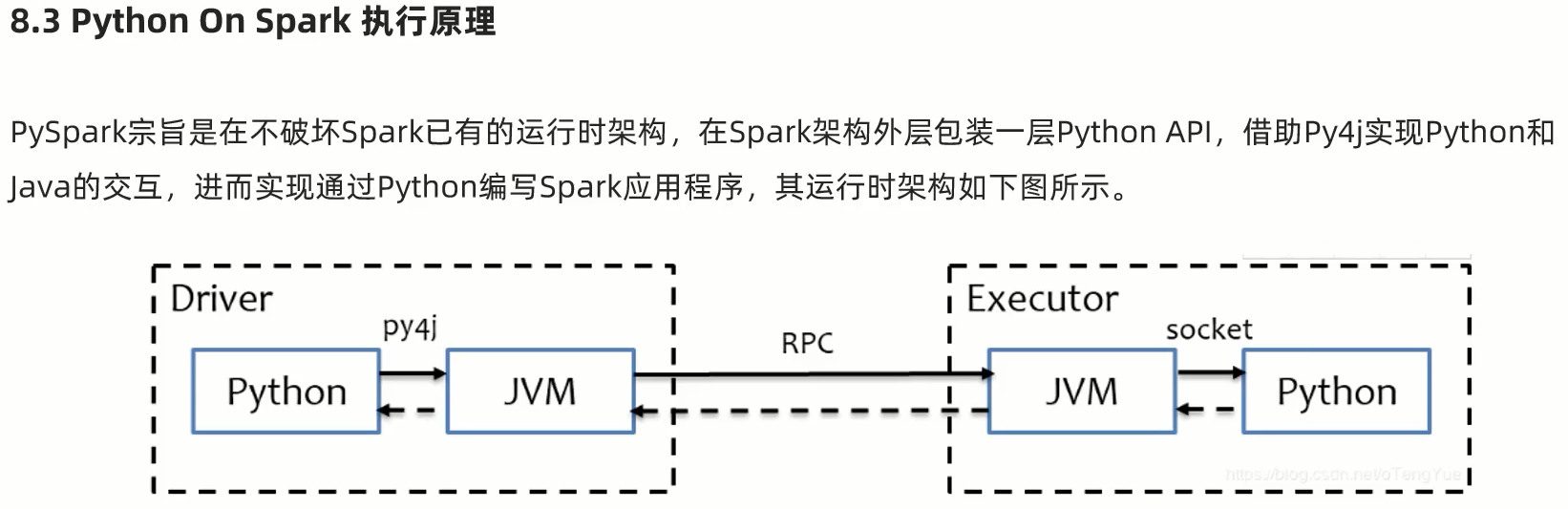
SparkCore
第一章 RDD详解


第二章 RDD 编程入门

rdd读入数据。一种是写进去的,一种是本地文件。
# coding:utf8import osfrom pyspark import SparkContext, SparkConfPYSPARK_PYTHON = "/root/anaconda3/envs/pyspark/bin/python"# 当存在多个版本时,不指定很可能会导致出错os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHONos.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHONif __name__ == '__main__':conf = SparkConf().setMaster("local[*]").setAppName("RDD") # 这个是local 模式,在一个节点运行。sc = SparkContext(conf=conf)# rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)# print(rdd1.getNumPartitions())# rdd2 = rdd1.glom().collect()# print(rdd2)rdd1 = sc.textFile('../data/words.txt')print(rdd1.collect())
2.3 算子

- map 算子:map 会作用于每一个分区上,的每一条数据。
- flatMap 对rdd 先执行map 然后执行解除嵌套操作。
第三章 RDD持久化
rdd数据是过程数据,旧的会被清除。
使用 rdd.cache()
第四章 RDD 案例练习
jeiba的使用。案例
第五章 RDD 共享变量
第六章 Spark 内核调度
SparkSQL
第一章
第二章
第三章
Spark新特性

若有收获,就点个赞吧
0 人点赞
