2020.12.19:
对于NLP论文的理解:数据增强;记忆;过滤;任务开拓;数学理论搭建
1.数据构造+增强
- 1. 有监督
根据任务来设计:任务标签
- 2. 无监督
根据类间差:空间标签
- 3. 半监督
少量带标签数据(数据增强:(增强范围:自然文本;增强方式:无监督聚类)
- 3.1 远程监督
少量带标签数据(数据增强:(增强范围:自然文本))
数据噪声比较大问题
- 4. 自监督->迁移学习
大量无标签数据->带标签数据
I love china -> l love [mask]:[mask]=china
根据数据本身设计标签:用于下游任务。
强化学习;
“Tony was born in New York.” ,能否设计一个模型/方法自动判断出该句子中有“born in”的关系。
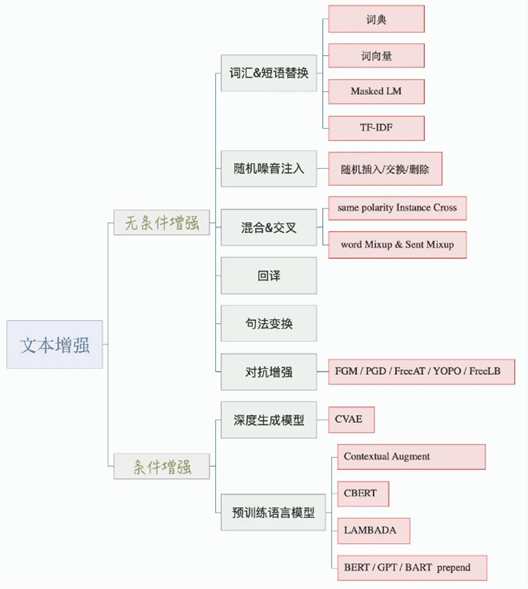
④ 自然语言处理数据增强
基于词向量:在嵌入空间中找寻相邻词汇进行替换,我们所熟知的TinyBERT[3] 就利用这种技术进行了数据增强。
基于词向量空间:自然文本空间不存在的增强
数据集增强
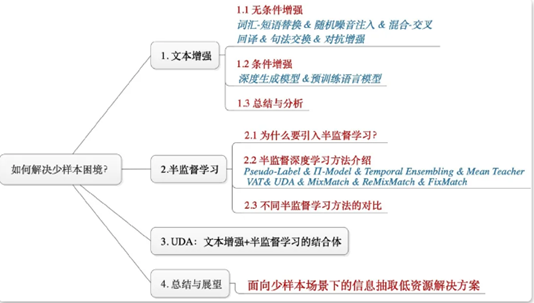
2.过滤
- 模型过滤
① 标签注意力
② 标签注意力的延伸
- 数据过滤
③ 错的再出现,对的不出现
10000
10000+x(错的) 允许错一次

若有收获,就点个赞吧
0 人点赞
