2020_TPLinker_Wang_TPLinker Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking (COLING)
TPLinker是实体关系抽取的新范式,巧妙设计了统一的联合抽取标注框架,可实现单阶段联合抽取、并解决暴漏偏差,同时依旧可以解决复杂的重叠关系抽取。
1.提出问题:
1.1 关系抽取中的实体重叠问题任然是挑战。
解决方法:关键在于对于每种关系类别建立模型(原因:实体重叠,关系必不重叠)
分为两种主流:(1)根据不同类别调整句向量的参数:如SMHSA、RSAN
(2)根据不同类别调整神经网络的参数:如CasRel
1.2 joint model性能存在上限:产生暴露偏差。(非新问题)
暴露偏差:训练的过程分为两步,均用的真实结果;
测试过程的第二步依赖第一步的预测结果
(此问题类似于之前的error propagation problem )
解决方法:用并联模型:如SMHSA、RSAN等
2.现有方法
2.1 分步骤的joint model (例如CasRel),在两步级联(串联)的传递过程中,产生了暴露偏差
2.2 但是也存在模型可以处理此类问题:如Table-filling中的SMHSA模型
可以解决暴露偏差和实体重叠问题
3.主要挑战:
3.1 构建耦合单步骤并联模型:TPLinker
3.2 个人理解TPLinker: 属于Table-filling,就是SMHSA模型的扩展
文中提到的 token pair linking problem —> word pair
4.设计方法:
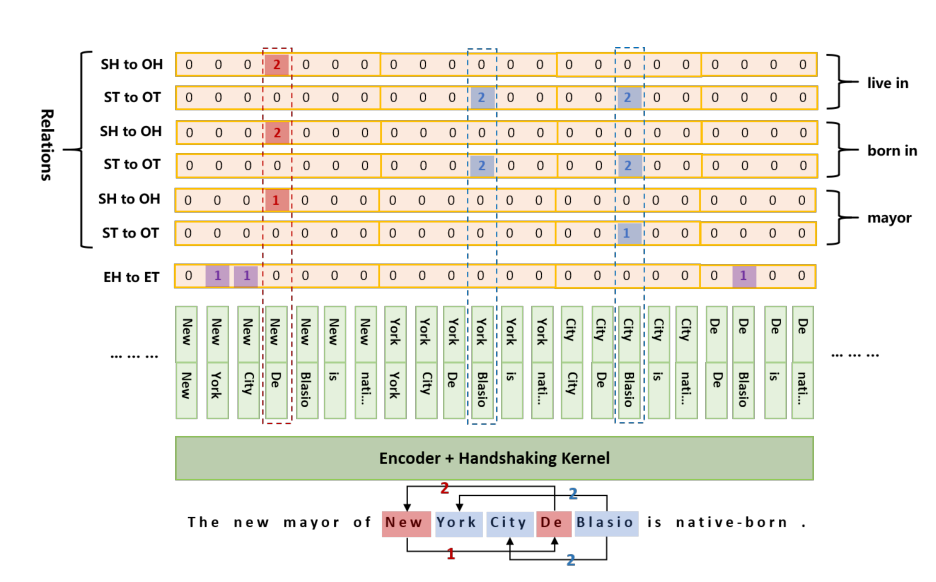
4.1 TPLinker: handshaking tagging scheme
4.2 对比SHMSA和TPLinker:(R为关系类别数)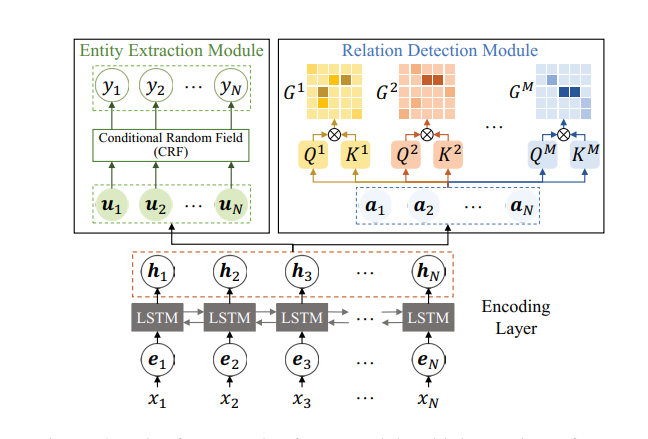
SHMSA: 构造了R(实体级别整体的链接) +1(实体边界学习:Bi-LSTM+CRF)
TPLinker:构造了2R(实体首位置链接+实体尾位置链接)+1(实体边界学习:softmax)
4.3 两种方法本质是一样的:
个人感觉:左边TPLinker更好:多了一倍的学习任务,可以更好地矫正错误;softmax更实用于单点学习
(问题:只关注首位置和尾位置的链接,不关注整体,类似于记忆模型;考虑到NYT和WebNLG出现大量三元组重复)
右边采用(BERT+CRF)更好:BERT+CRF为当前较为稳定和有效的实体边界识别方法
5.存在问题:
5.1 TPLinker:(1)Table-filling方法的包装;(2)所提出的暴露偏差问题(exposure bias)实际上就是error propagation problem
(3)所解决的实体重叠问题不是他解决的主要问题
(4)对于解决暴露偏差问题(exposure bias)提高效果的分析缺乏合理依据和分析
(参考陈丹琦新作:A Frustratingly Easy Approach for Joint Entity and Relation Extraction)

5.2 缺乏解释性的方法
5.3 过度记忆:(1)只关注主客体首位置链接和主客体尾位置的链接,不关注整体,类似于记忆模型
(2)过分考虑到NYT和WebNLG出现大量三元组重复(对于不存在重复的数据集效果较差)
5.4 当前模型存在的问题:(1)过度记忆;
(2)预训练模型过于通用;
(3)缺少重复三元组少的关系抽取数据集

若有收获,就点个赞吧
0 人点赞
