数据结构和算法,这两者出现的本质就是为了能够更快、更省的进行数据处理。

常见的时间复杂度

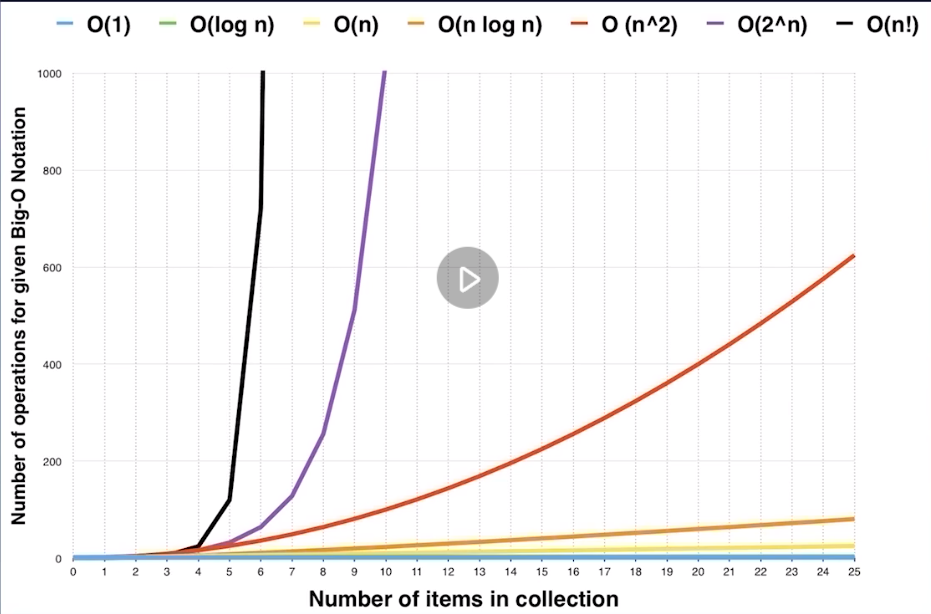
复杂度分析(大O记法)
既然数据结构和算法出现的本质是为了更快、更省的进行数据的处理,那么就需要分析如何让程序运行时间最少,如何让使用空间最小,这两种分别对应时间复杂度和空间复杂度。
时间复杂度
我们无法用实际运行时间预估程序运行时间,所以需要使用 步数 作为时间复杂度的计算, 步数可以简单理解为数组的每次索引值的读取 ,也可被称为 unit-time 。
- 在计算机底层,计算机可以通过一步跳到任意一个索引的位置进行数据的读取。如果用大O记法,称作常数时间——O(1)。(即,无论数组的长度多少,获取数组中的某个值都只需要一步。)
- 那么,步数为
log(N)的就称为 对数时间—-O(log(N))。还有 线性时间—-O(N) , 指数时间—-O(2^n) 等。 - 大O记法表示的是 代码执行时间随数据规模增长的变化趋势 ,所以常数和系数可忽略。
看一下案例:
计算N的阶乘
public int factorial(int n) {int result = 1; //step1for (int i = 1; i <= n; i++) { //step2result *= i; // step3}return result;}
分析时间复杂度如下,大O记法:O(N)。

计算一个数组中的所有组合方式
定义一个函数,能打印传入参数的两两组合情况,例如,传入一个数组 {"hello", "you", "ke", "da"} ,希望两两组合,一共有多少组合呢~

代码如下:
public void combine(String args[]) {for (int i = 0; i < args.length; i++) { //step1for (int j = i + 1; j < args.length; j++) { //step2System.out.println(args[i] + args[j]); //step3}}}
分析复杂度如下,大O记法:O(N^2)。

时间复杂度的趋势
我们可以总结出,大O记法只保留最大趋势公式, 指数 > 线性 > 对数 > 常数 。因此在计算时间复杂度的时候,并不需要一行行看代码,只需要关注for循环嵌套。
写代码的时候,如果能用 线性复杂度 的代码替换 指数复杂度 的代码,那就是大大的性能优化。
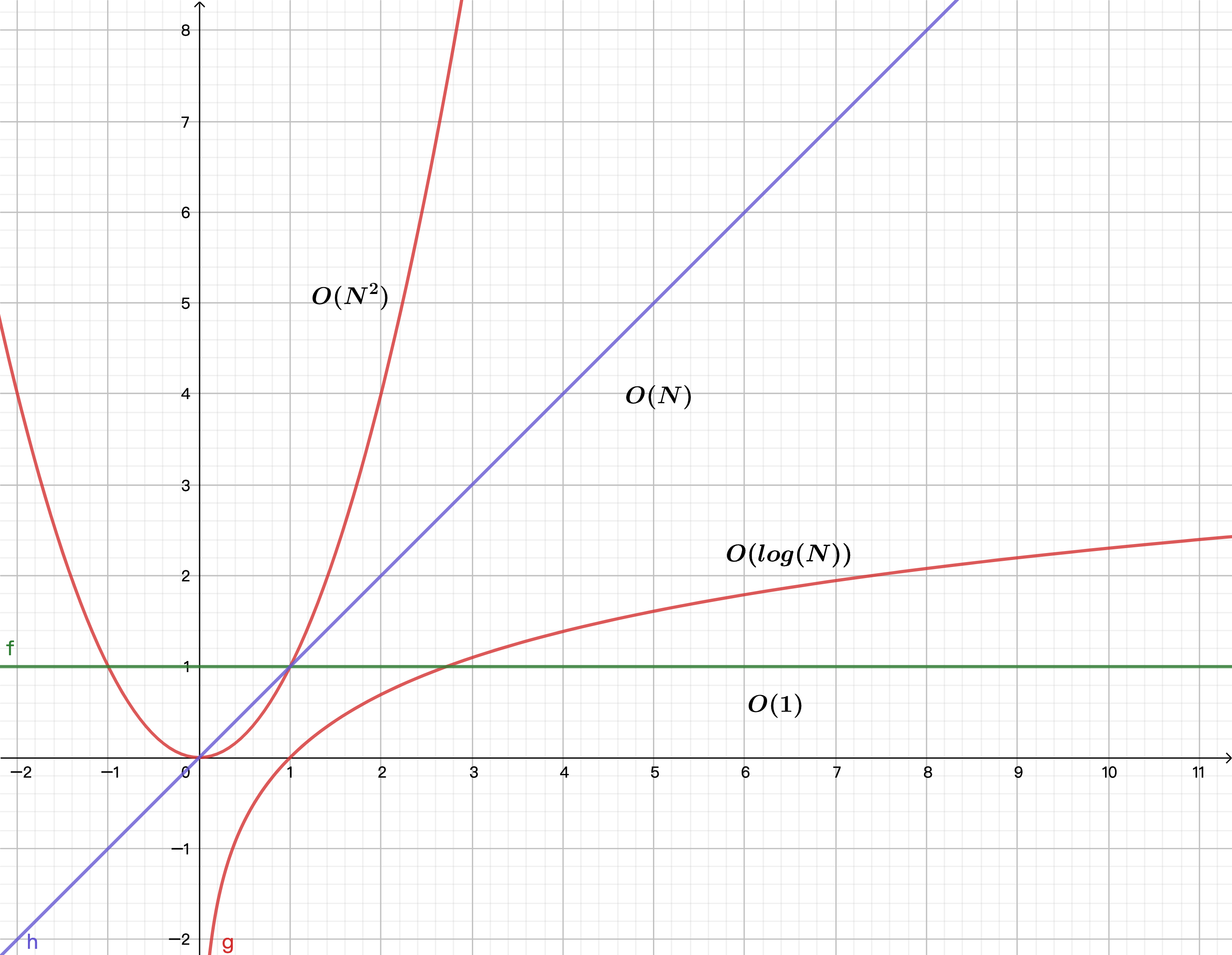
空间复杂度
空间复杂度是以一个基础数据类型值作为基本单位。
简单看一下:
O(1)
int a = 0;int j = 0;
O(N)
int a[] = new int[n]
事实上,我们大多数情况只会考虑时间复杂度!因为我们默认计算机内存是足够给我们使用的。除非参与嵌入式开发,参与单片机相关的编程开发,才需要注意空间问题。
性能优化案例
二分法查找
二分法查找首先满足数组是有序的。通过一个案例来说明如何进行性能的优化。
我们需要在一个有序数组 [2, 3, 22, 75, 80, 90, 100] 里查找是否存在某一个数字。
最最基础粗暴的方法就是线性查找,遍历整个数组。
public static int find(int[] array, int aim) {for (int i = 0; i < array.length; i++) {if (aim == array[i]) {return i;}}return -1;}
这种查找方法的时间复杂度为O(N)。那么采用更快的二分法查找呢~
因为数组是有序的(前提条件),我们可以先对比中间索引值,缩小查找范围。
为了缩小查找范围且不破坏原数组,我们需要定义两个变量left、right分别表示可筛选区域的左侧和右侧的索引。
public static int find(int[] array, int aim) {// 初始化left = 最左侧, right = 最右侧int left = 0;int right = array.length - 1;// 当left > right则表示遍历完成while (left <= right) {// 获取中间的值int middle = (left + right) / 2;int middleValue = array[middle];if (middleValue == aim) {// 已经找到目标return middle;} else if (middleValue < aim) {// 目标在middle的右侧,重置leftleft = middle + 1;} else {// 目标在middle的左侧,重置rightright = middle - 1;}}return -1;}
思考:
- 如果数组是降序的,需要怎么改动~
- 如果类型是字符串呢~
在Java种可以使用String对象 compareTo 方法比较字符串的先后顺序,语法规则为:
str1.compareTo(str2)//结果<0,则表示str1在str2前面
例如,通讯录里的名字已经被排好顺序,如下:
["Allen","Emma","James","Jeanne","Kelly","Kevin","Mary","Natasha","Olivia","Rose"]
代码如下:
//使用ArrayList存储,注意获取长度和值的方法public static int find(ArrayList<String> array,String aim){int left = 0;int right = array.size()-1;while(left <= right){int middle = (left+right)/2;String middlevalue = array.get(middle);if(aim.equals(middlevalue)){return middle;}else if(aim.compareTo(middlevalue) <0){right = middle - 1;}else{left = middle + 1;}}return -1;}
当数据较大时,分别对比查找的时间复杂度,注意,只考虑最坏的情况,因为最好的情况下都是1。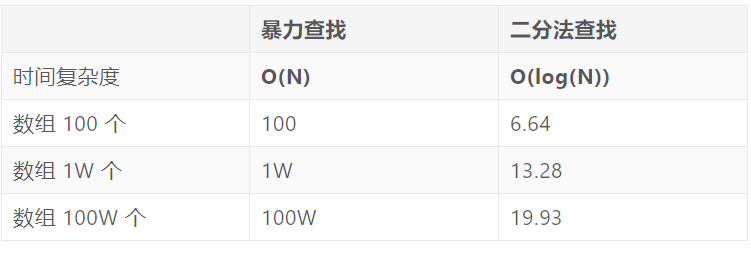
可以看到在数组很大的时候,性能提升非常明显,相差了几个量级。
二次问题
再来一个案例:
给定一个int数组,数组里面每个数字介于0~10之间,请找出里面的重复数字。
暴力破解法
每次获取一个元素,判断这个元素和后面的元素是否有重复:

代码如下:
public static ArrayList<Integer> repeat(int[] array) {ArrayList<Integer> result = new ArrayList<>();for(int i = 0; i < array.length; i++){// 以此判断i位置元素和后面j位置元素是否相等for(int j = i + 1; j < array.length; j++){if(array[i] == array[j]){result.add(array[i]);}}}return result;}
两个for循环嵌套,所以时间复杂度为 O(N^2) 。有没有更快一点的方法呢?
标记法
注意题目说每一个元素都介于0~10之间,那么是否可以用长度为11的数组来标记0-10这11个数字是否存在; 空,表示不存在;1,表示存在 如图所示:

当后面有相同的数字出现时,发现对应的位置已经设置为1了,就说明重复了。
代码如下:
public static ArrayList<Integer> repeat(int[] array) {//创建一个集合用来存放重复的数字ArrayList<Integer> result = new ArrayList<>();//创建一个长度为11的int类型数组,所有元素都为0int[] exists = new int[11];for (int i = 0; i < array.length; i++) {int value = array[i];// 如果当前位置已经为1,则表示重复if (exists[value] == 1) {result.add(value);} else {// 否则将当前位置设置为1exists[value] = 1;}}return result;}
可以知道我们只用了一次for循环,时间复杂度为 O(N) ,性能优化了。同时这个也是空间换时间的典型案例。
思考:
给定一个字符串,如 "abcdkioudofanzdfpqwe" ,规定都是小写介于 a-z ,请找出字符串中重复的字符。
提示:
Java中可以通过索引值来获取对应的字符串
String str = "abcdkioudofanzdfpqwe";str.charAt(0) // 'a'str.charAt(3) // 'd'
ASCII码
小写字母a对应的ASCII码为97,之后的字母的ASCII码值依次递增。所以有以下结论:
'b' - 'a' = 1'c' - 'a' = 2'd' - 'a' = 3
代码如下:
public static ArrayList<Character> repeat(String str) {//创建一个集合来存放重复的字母ArrayList<Character> result = new ArrayList<>();//创建一个数组用来标记,全为nullint[] exists = new int[26];for (int i = 0; i < str.length(); i++) {//这一步用到上面的两个提示,先通过下标获取数组里的字母,再利用ASCII码的规律让value在0~26之间//注意str.chatAt()的返回类型为charint value = str.charAt(i) - 'a';// 如果当前位置已经为1,则表示重复if (exists[value] == 1) {result.add(str.charAt(i));} else {// 否则将当前位置设置为1exists[value] = 1;}}return result;}
数组
问题:为什么数组的索引从0开始呢~这不是违背人类的思维惯性吗?
数组是一种 线性表数据结构 ,用一组 连续的内存空间 ,存储一组具有 相同类型的数据 。
数组的读取
每个数组都有对应的内存地址,称为—- start_adress ;
数组在定义的时候已经确定其数据类型了,所以已经知道每个元素所需的内存大小空间了,称为—- item-size 。
计算:
// 第一个元素地址start_address// 第二个元素地址start_address + item_size * 1// 第三个元素地址start_address + item_size * 2....//第N个元素地址公式,数组索引访问的时间复杂度是O(1)start_adress + item_size * (N-1)
所以,为什么数组索引从0开始呢~
因为内存地址的计算规则决定开始地址为 start_address + item_size * 0 ,计算机中为了方便位置计算,所以数组的索引从0开始。
数组的插入和删除
注意支持扩容的大致思路:
- 每次插入元素,判断元素的个数是否已经达到存储上限
- 如果达到存储上限,则创建一个新的数组(大小可为原来的两倍)准备存储元素
- 将原来的数组拷贝到新数组
- 再执行插入操作 ```java package com.youkeda;
public class YKDArrayList {
// 此处需要声明一个数组,作为底层存储 int[] array = new int[20]; int size = 0;
public YKDArrayList() { }
// 获取数组的长度 public int size() { return this.size; }
// 数组获取某个索引值 public int get(int index) { return this.array[index]; }
// 添加元素在末尾 public void add(int element) { //相当于调用传入this.size this.add(this.size, element); }
// 添加元素在中间 public void add(int index, int element) { if (index < 0 || index > this.size) { return; }
// 支持扩容// 通过传入size+1判断是否达到上限this.judgeMemory(this.size+1);}// 元素依次右移for (int i = this.size - 1; i >= index; i--) {this.array[i + 1] = this.array[i];}// 插入元素this.array[index] = element;// 调整sizethis.size++;
}
// 删除元素 public void remove(int index) { if (index < 0 || index > this.size - 1) { return; }
// 元素依次左移
for (int i = index; i < this.size - 1; i++) {
this.array[i] = this.array[i + 1];
}
// 删除最后一个元素
this.array[this.size - 1] = 0;
// 调整size
this.size--;
} //支持扩容的核心函数 private void judgeMemory(int size) { // 如果内存不满足,则需要扩容 if (size > this.array.length) { // 申明两倍空间 int[] newArray = new int[this.array.length * 2]; // 拷贝操作 this.copy(this.array, newArray); // 新数组赋值给原数组 this.array = newArray; } }
// 拷贝操作 private void copy(int[] source, int[] aim) { for (int i = 0; i < source.length; i++) { aim[i] = source[i]; } }
public static void main(String[] args) { YKDArrayList ykdArrayList = new YKDArrayList(); ykdArrayList.add(1); ykdArrayList.add(2); ykdArrayList.add(3); ykdArrayList.add(4);
ykdArrayList.add(0, 5);
ykdArrayList.remove(3);
} }
```

若有收获,就点个赞吧
0 人点赞
