第一章.数据采集
1.实时电商数仓项目分层
- ODS层: 原始数据: 采集日志数据和业务数据到kafka
- DWD层: 依据数据对象为单位进行分流,比如订单,页面访问等,将事实数据采集到kafka,维度数据采集到Hbase
- DIM层(Hbase + phoenix): 维度数据,例如user_info,spu_info
- DWM层: 对于部分数据对象进行进一步加工,比如独立访问,跳出行为,也可以和维度进行关联.形成宽表,仍然是明细数据
- DWS层: 根据某个主题将多个事实数据轻度聚合,形成主题宽表,数据存储到clickhouse
- ADS层: 把Clickhouse中的数据根据可视化需要进行筛选聚合
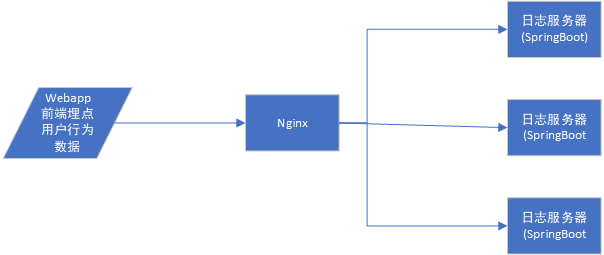
2.用户行为数据采集(日志数据)
这里使用模拟生成数据的jar包模拟生成数据,可以将日志发送给某一个指定的端口
模拟数据文件

一.编写日志服务器
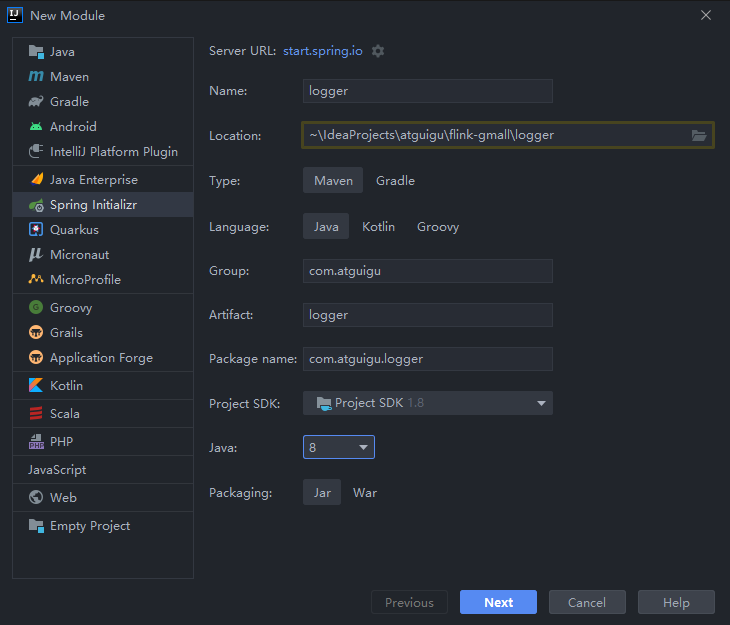
- 新建一个maven工程: flink-gmall
- 在该工程中创建一个springboot子模块(logger),用于采集日志数据
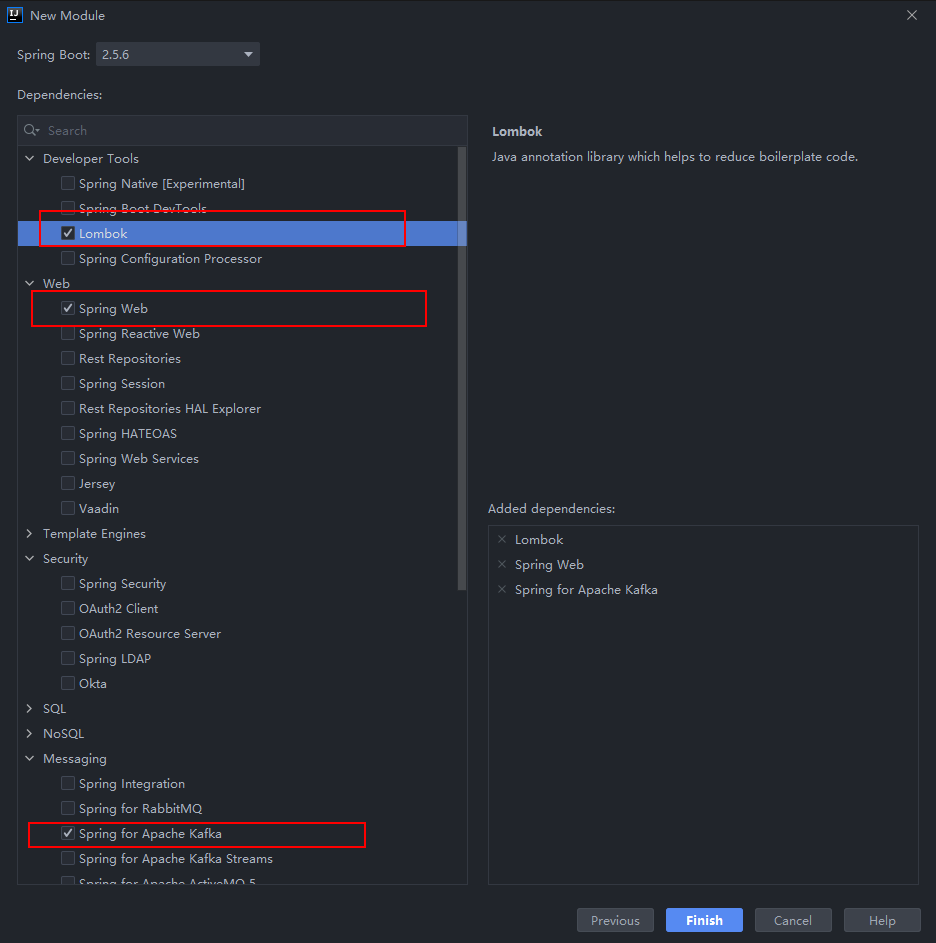
- 编写配置文件application.properties,用于配置端口和kafka信息
server.port=8081spring.kafka.bootstrap-servers=hadoop162:9092,hadoop163:9092,hadoop164:9092spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializerspring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
- 添加配置文件logback.xml,用于将日志数据落盘
<?xml version="1.0" encoding="UTF-8"?><configuration><!--日志的根目录, 根据需要更改成日志要保存的目录--><property name="LOG_HOME" value="/home/atguigu/applog"/><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%msg%n</pattern></encoder></appender><appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${LOG_HOME}/app.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%msg%n</pattern></encoder></appender><!-- 将某一个包下日志单独打印日志 需要更换我们的 Controller 类 --><logger name="com.atguigu.logger.controller.LoggerController"level="INFO" additivity="true"><appender-ref ref="rollingFile"/><appender-ref ref="console"/></logger><root level="error" additivity="true"><appender-ref ref="console"/></root></configuration>
- 编写controller,用来处理客户端的http请求
package com.atguigu.logger.controller;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;@RestController@Slf4jpublic class LoggerController {@RequestMapping("/applog")public Object doLog(@RequestParam("param") String log){//1.把数据落盘saveToDisk(log);//2.把数据直接写入到kafka中writeToKafka(log);return "success";}@AutowiredKafkaTemplate producer;private void writeToKafka(String log){producer.send("ods_log",log);}private void saveToDisk(String strLog) {log.info(strLog);}}
- 新建一个文件夹(shell),用于存放脚本
- 将项目打包上传至linux服务器上(/opt/module/gmall-flink)
- 分别启动hadoop,zookeeper,和kafka
- 启动模拟数据脚本,和kafka消费者客户端,验证是否可以写入到kafka
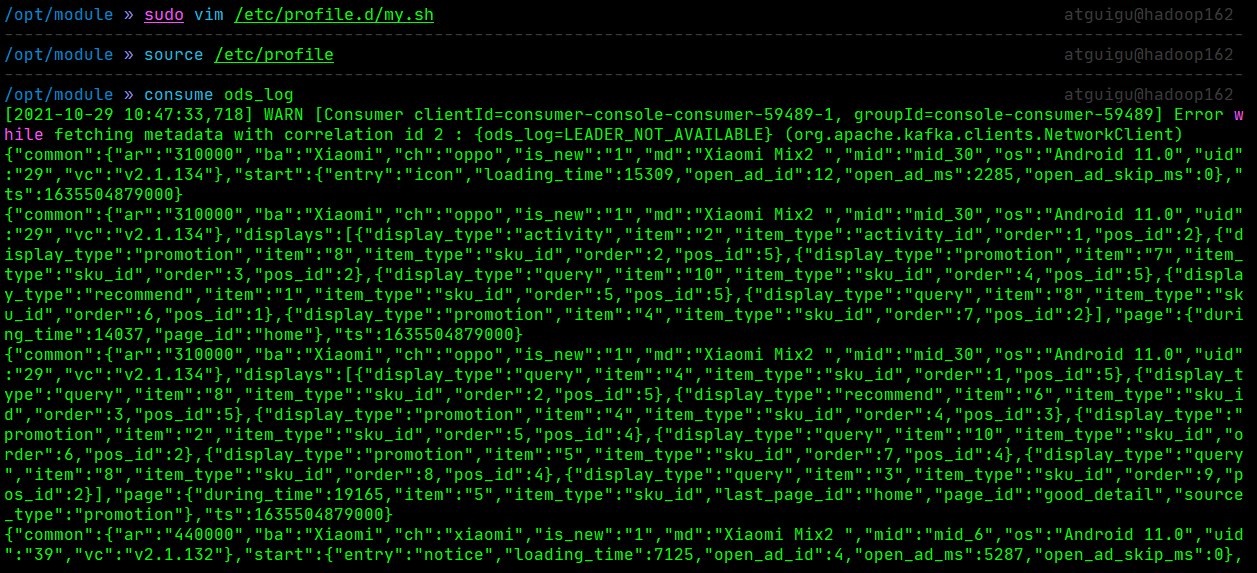
可以看出,模拟生成的数据已经写入到kafka的ods_log主题
- 将日志服务器分发至hadoop163,hadoop164并使用nginx做负载均衡
http {# 启动省略upstream logcluster{server hadoop162:8081 weight=1;server hadoop163:8081 weight=1;server hadoop164:8081 weight=1;}server {listen 80;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;location / {#root html;#index index.html index.htm;# 代理的服务器集群 命名随意, 但是不能出现下划线proxy_pass http://logcluster;proxy_connect_timeout 10;}# 其他省略}
- 日志服务器群起脚本
#!/bin/bash# 启动 nginx# 启动springboot 日志服务器nginx_home=/opt/module/nginxapp_home=/opt/module/gmall-flinkapp=logger-0.0.1-SNAPSHOT.jarcase $1 in"start")if [[ -z "`pgrep -f nginx`" ]]; thenecho "在 hadoop162 启动 nginx"sudo $nginx_home/sbin/nginxelseecho " nginx 已经启动无序重复启动...."fifor host in hadoop162 hadoop163 hadoop164 ; doecho "在 $host 启动日志服务器"ssh $host "nohup java -jar $app_home/$app 1>>$app_home/log.out 2>>$app_home/log.err &"done;;"stop")echo "在 hadoop162 停止 nginx"sudo $nginx_home/sbin/nginx -s stopfor host in hadoop162 hadoop163 hadoop164 ; doecho "在 $host 停止日志服务器"ssh $host "jps | awk '/$app/ {print \$1}' |xargs kill -9"done;;*)echo "执行的姿势不对: "echo "log.sh start 启动日志采集服务器 "echo "log.sh stop 停止日志采集服务器 ";;esac
3.业务数据采集
业务数据一般存放在mysql中,可以实时采集mysql数据的工具有canal和maxwell,debzium
本项目使用maxwell实时采集业务数据
一.mysql的binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。二进制日志包括/两类文件:A: 二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制的文件,B:二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件
二.开启binlog
默认情况下,mysql是没有开启binlog的,需要手动开启
- 编辑mysql的配置文件my.cnf(/etc/my.cnf)
server-id= 1log-bin=mysql-binbinlog_format=rowbinlog-do-db=gmall2021
- 重启mysql服务器
sudo systemctl restart mysqld
- 在mysql准备业务数据
CREATE DATABASE `gmall2021` CHARACTER SET utf8 COLLATE utf8_general_ci;USE gmall2021;source /opt/software/mock/mock_db/gmall2020_12_08.sql
三.使用maxwell实时采集mysql数据
- 什么是maxwell
maxwell 是由美国zendesk开源,用java编写的Mysql实时抓取软件。 其抓取的原理也是基于binlog
- maxwell与canal的对比
- Maxwell 没有 Canal那种server+client模式,只有一个server把数据发送到消息队列或redis。
- Maxwell 有一个亮点功能,就是Canal只能抓取最新数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
- Maxwell不能直接支持HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
- Maxwell只支持json格式,而Canal如果用Server+client模式的话,可以自定义格式。
- Maxwell比Canal更加轻量级
- 安装和配置maxwell
# 解压tar -zxvf maxwell-1.27.1.tar.gz -C /opt/module
# 配置maxwellcd /opt/module/maxwell-1.27.1vim config.properties
# 添加如下配置# tl;dr configlog_level=infoproducer=kafkakafka.bootstrap.servers=hadoop162:9092,hadoop163:9092,hadoop164:9092kafka_topic=ods_db# 按照主键的hash进行分区, 如果不设置是按照数据库分区producer_partition_by=table# mysql login infohost=hadoop162user=rootpassword=aaaaaa# 排除掉不想监控的数据库filter=exclude:gmall2021_realtime.*# 初始化维度表数据的时候使用client_id=maxwell_1
- 启动maxwell
bin/maxwell --config=config.properties
- 启动kafka终端消费者,观察是否能消费到数据
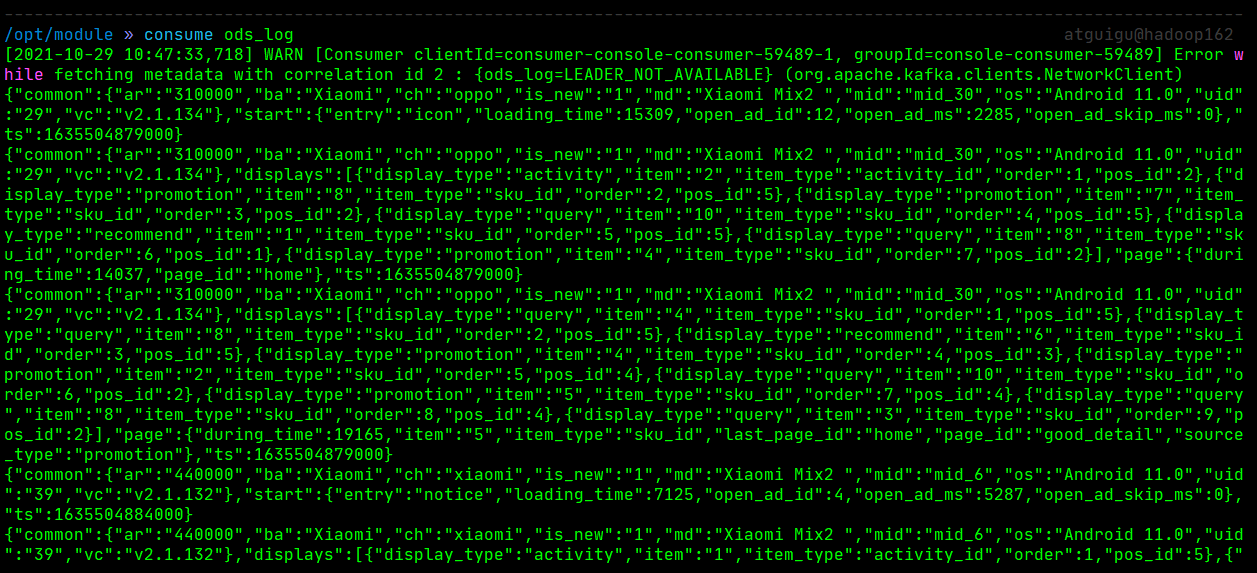
可以看出,模拟生成的数据已成功的写入ods_db主题
- Maxwell的初始化数据功能
对于mysql中已有的旧数据,如何导入到kafka中? Canal无能为力.maxwell提供了一个初始化功能,可以满足我们的需求
bin/maxwell-bootstrap --user root --password aaaaaa --host hadoop162 --database gmall2021 --table user_info --client_id maxwell_1
第二章.实时数仓环境搭建(DWD层)
上一章中,我们已经将日志数据和业务数据都采集到了相应的kafka的topic中
为了增加数据计算的复用性我们需要将ods层的数据简单处理,写回到kafka中作为dwd层
| 分层 | 数据描述 | 生成计算工具 | 存储媒介 |
|---|---|---|---|
| ODS | 原始数据,日志和业务数据 | 日志服务器,maxwell | KAFKA |
| DWD | 根据数据对象为单位进行分流,比如订单、页面访问等等。 | FLINK | KAFKA |
| DWM | 对于部分数据对象进行进一步加工,比如独立访问、跳出行为。依旧是明细数据。 进行了维度冗余(宽表) | FLINK | KAFKA |
| DIM | 维度数据 | FLINK | HBASE |
| DWS | 根据某个维度主题将多个事实数据轻度聚合,形成主题宽表。 | FLINK | Clickhouse |
| ADS | 把Clickhouse中的数据根据可视化需要进行筛选聚合。 | Clickhouse SQL | 可视化展示 |
1.创建gmall-realtime模块
该模块用于实时计算流式数据
- pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>flink-gmall</artifactId><groupId>com.atguigu</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>gmall-realtime</artifactId><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.13.1</flink.version><scala.binary.version>2.12</scala.binary.version><hadoop.version>3.1.3</hadoop.version><slf4j.version>1.7.30</slf4j.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.16</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.75</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.16</version></dependency><!--commons-beanutils是Apache开源组织提供的用于操作JAVA BEAN的工具包。使用commons-beanutils,我们可以很方便的对bean对象的属性进行操作--><dependency><groupId>commons-beanutils</groupId><artifactId>commons-beanutils</artifactId><version>1.9.3</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.0.1</version></dependency><dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-core</artifactId><version>5.0.0-HBase-2.0</version><exclusions><exclusion><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId></exclusion></exclusions></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30.1-jre</version></dependency><dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>2.5.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins></build></project>
- 添加log4j.properties
log4j.rootLogger=error, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
- 创建包结构
2.DWD层(用户行为日志)
主要任务
- 识别新老客户:本身客户端业务有新老用户的标识,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)
- 数据拆分
- 不同数据写入Kafka不同的topic中
- 读取kafka数据工具类
package com.atguigu.gmall.util;import com.atguigu.gmall.common.Constant;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;/*** 读取kafka指定topic的数据*/public class FlinkSourceUtil {public static FlinkKafkaConsumer<String> getKafkaSource(String groupId,String topic){Properties properties = new Properties();properties.put("bootstrap.servers", Constant.KAFKA_BROKERS);properties.put("group.id",groupId);properties.put("auto.offset.reset","latest");//如果没有上次的消费记录,则从最新开始消费,如果有记录,则从上次的位置开始消费properties.put("isolation.level","read_committed");//设置kafka只有完成两阶段提交时才能被消费,影响时效性return new FlinkKafkaConsumer<String>(topic,new SimpleStringSchema(),properties);}}
- BaseApp(将消费kafka数据的代码封装为一个模板抽象类)
package com.atguigu.gmall.app;import com.atguigu.gmall.util.FlinkSourceUtil;import org.apache.flink.configuration.Configuration;import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public abstract class BaseAppV1 {public abstract void run(StreamExecutionEnvironment env, DataStreamSource<String> stream);public void init(int port,int p,String ck,String groupId,String topic){System.setProperty("HADOOP_USER_NAME","atguigu");Configuration conf = new Configuration();conf.setInteger("rest.port",port);//设置web端端口号StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(p);//配置checkpointenv.enableCheckpointing(3000, CheckpointingMode.EXACTLY_ONCE);env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop162:8020/gmall/" + ck);env.getCheckpointConfig().setCheckpointTimeout(10 * 1000);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);DataStreamSource<String> stream = env.addSource(FlinkSourceUtil.getKafkaSource(groupId, topic));//不同的APP有不同的业务逻辑run(env,stream);try {env.execute(ck);} catch (Exception e) {e.printStackTrace();}}}
- 封装常量类
package com.atguigu.gmall.common;/*** 封装经常使用的常量*/public class Constant {public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";public static final String PHOENIX_URL = "jdbc:phoenix:hadoop162,hadoop163,hadoop164:2181";public static final String KAFKA_BROKERS = "hadoop162:9092,hadoop163:9092,hadoop164:9092";// ods层topicpublic static final String TOPIC_ODS_LOG = "ods_log";public static final String TOPIC_ODS_DB = "ods_db"; // shift+ctrl+u 大小写切换//dwd层 日志的 topicpublic static final String TOPIC_DWD_START = "dwd_start";public static final String TOPIC_DWD_DISPLAY = "dwd_display";public static final String TOPIC_DWD_PAGE = "dwd_page";public static final String DWD_SINK_KAFKA = "kafka";public static final String DWD_SINK_HBASE = "hbase";}
- 自定义工具类
package com.atguigu.gmall.util;import java.util.ArrayList;import java.util.List;/*** 将iterable(迭代器)转换成list(集合)*/public class IteratorToListUtil {public static<T> List<T> toList(Iterable<T> it){ArrayList<T> result = new ArrayList<>();for (T t : it) {result.add(t);}return result;}}
一.数据流程图
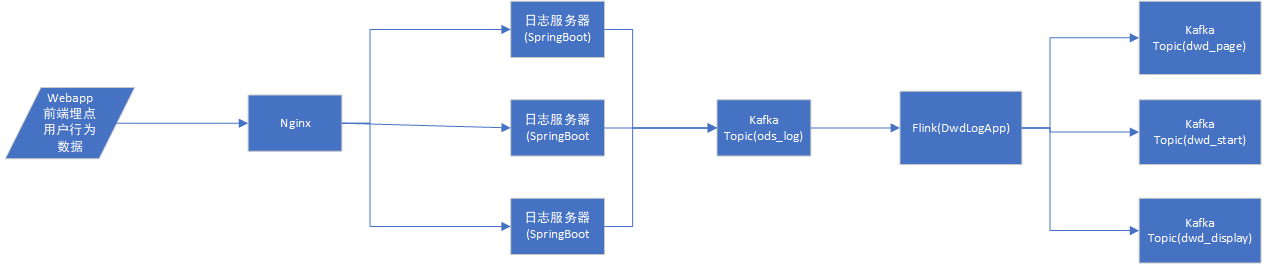
二.识别新老访客
实现思路:
- 考虑数据的乱序,使用event-time语义
- 按照mid(设备id)分组
- 添加5s的滚动窗口
- 使用状态记录首次访问的时间戳
- 如果状态为空, 则此窗口内的最小时间戳的事件为首次访问, 其他均为非首次访问
- 如果状态不为空,则此窗口内所有的事件均为非首次访问
/*** 区别新老用户* @param stream*/private SingleOutputStreamOperator<JSONObject> distinguishNewOrOld(DataStreamSource<String> stream) {//使用事件时间加窗口,找到第一条记录作为新用户,其他都是老用户return stream.map(new MapFunction<String, JSONObject>() {@Overridepublic JSONObject map(String value) throws Exception {return JSON.parseObject(value);}}).assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {@Overridepublic long extractTimestamp(JSONObject element, long recordTimestamp) {return element.getLong("ts");}})).keyBy(new KeySelector<JSONObject, String>() {@Overridepublic String getKey(JSONObject value) throws Exception {return value.getJSONObject("common").getString("mid");}}).window(TumblingEventTimeWindows.of(Time.seconds(5))).process(new ProcessWindowFunction<JSONObject, JSONObject, String, TimeWindow>() {private ValueState<Boolean> isFirstState;@Overridepublic void open(Configuration parameters) throws Exception {isFirstState = getRuntimeContext().getState(new ValueStateDescriptor<Boolean>("isFirstState",Boolean.class));}@Overridepublic void process(String key, Context context, Iterable<JSONObject> elements, Collector<JSONObject> out) throws Exception {if(isFirstState.value() == null){//这是设备id的第一个窗口,找到时间戳最小的那个,标记为新用户,其他的标记为老用户//先更新状态isFirstState.update(true);//找到时间最小的那个List<JSONObject> list = IteratorToListUtil.toList(elements);list.sort(new Comparator<JSONObject>() {@Overridepublic int compare(JSONObject o1, JSONObject o2) {return o1.getLong("ts").compareTo(o2.getLong("ts"));}});for (int i = 0; i < list.size(); i++) {JSONObject obj = list.get(i);if(i == 0){obj.getJSONObject("common").put("is_new","1");}else{obj.getJSONObject("common").put("is_new","0");}out.collect(obj);}}else{//其他的窗口,所有记录全部标记为老用户for(JSONObject obj : elements){obj.getJSONObject("common").put("is_new","0");out.collect(obj);}}}});}
三.数据分流
根据日志数据内容,将日志数据分为三类:页面日志,启动日志和曝光日志
页面日志输出到主流,启动日志和曝光日志输出到侧输出流,并写入到对应的kafka的topic中
/*** 分流: 启动日志 页面日志 曝光日志* @param stream*/private HashMap<String, DataStream<JSONObject>> splitStream(SingleOutputStreamOperator<JSONObject> stream) {OutputTag<JSONObject> pageTag = new OutputTag<JSONObject>(PAGE) {};OutputTag<JSONObject> displayTag = new OutputTag<JSONObject>(DISPLAY) {};SingleOutputStreamOperator<JSONObject> startStream = stream.process(new ProcessFunction<JSONObject, JSONObject>() {@Overridepublic void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {//主流:启动日志 侧输出流2个:页面和曝光日志if (value.containsKey("start")) {//启动日志out.collect(value);} else {//有可能是曝光和页面if (value.containsKey("page")) {//页面ctx.output(pageTag, value);}if (value.containsKey("displays")) {//曝光JSONArray displays = value.getJSONArray("displays");for (int i = 0; i < displays.size(); i++) {JSONObject obj = displays.getJSONObject(i);obj.putAll(value.getJSONObject("common"));obj.putAll(value.getJSONObject("page"));obj.put("ts", value.getLong("ts"));ctx.output(displayTag, obj);}}}}});DataStream<JSONObject> pageStream = startStream.getSideOutput(pageTag);DataStream<JSONObject> displayStream = startStream.getSideOutput(displayTag);HashMap<String, DataStream<JSONObject>> result = new HashMap<>();result.put(PAGE,pageStream);result.put(START,startStream);result.put(DISPLAY,displayStream);return result;}
四.不同流写入到kafka不同Topic中
- 将数据写入到kafka的工具类
package com.atguigu.gmall.util;import com.alibaba.fastjson.JSONObject;import com.atguigu.gmall.common.Constant;import com.atguigu.gmall.pojo.TableProcess;import com.atguigu.gmall.sink.PhoenixSink;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.functions.sink.SinkFunction;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;import org.apache.kafka.clients.producer.ProducerRecord;import javax.annotation.Nullable;import java.nio.charset.StandardCharsets;import java.util.Properties;/*** 向kafka指定的topic写数据*/public class FlinkSinkUtil {public static SinkFunction<String> getKafkaSink(String topic){Properties properties = new Properties();properties.put("bootstrap.servers", Constant.KAFKA_BROKERS);properties.put("transaction.timeout.ms",15 * 60 * 1000);return new FlinkKafkaProducer<String>("default",new KafkaSerializationSchema<String>() {@Overridepublic ProducerRecord<byte[], byte[]> serialize(String s, @Nullable Long aLong) {return new ProducerRecord<byte[], byte[]>(topic,s.getBytes(StandardCharsets.UTF_8));}},properties,FlinkKafkaProducer.Semantic.EXACTLY_ONCE);}}
- 具体实现方法
/**
* 把不同的流的数据写入到不同的topic中
* @param streams
*/
private void writeToKafka(HashMap<String, DataStream<JSONObject>> streams) {
streams.get(START)
.map(new MapFunction<JSONObject, String>() {
@Override
public String map(JSONObject value) throws Exception {
return value.toJSONString();
}
})
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_START));
streams.get(DISPLAY)
.map(new MapFunction<JSONObject, String>() {
@Override
public String map(JSONObject value) throws Exception {
return value.toJSONString();
}
})
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_DISPLAY));
streams.get(PAGE)
.map(new MapFunction<JSONObject, String>() {
@Override
public String map(JSONObject value) throws Exception {
return value.toJSONString();
}
})
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_PAGE));
}
五.完整代码
package com.atguigu.gmall.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.gmall.app.BaseAppV1;
import com.atguigu.gmall.common.Constant;
import com.atguigu.gmall.util.FlinkSinkUtil;
import com.atguigu.gmall.util.IteratorToListUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
public class DwdLogApp extends BaseAppV1 {
public static final String PAGE = "page";
public static final String DISPLAY = "display";
public static final String START = "start";
public static void main(String[] args) {
new DwdLogApp().init(2001,1,"DwdLogApp","DwdLogApp", Constant.TOPIC_ODS_LOG);
}
/**
* DwdlogApp具体实现
* @param env
* @param stream
*/
@Override
public void run(StreamExecutionEnvironment env, DataStreamSource<String> stream) {
//stream.print();
/**
* 1.区分新老用户,对已有的字段 is_new做一个纠正
*/
SingleOutputStreamOperator<JSONObject> validateStream = distinguishNewOrOld(stream);
//validateStream.print();
/**
* 2.分流: 启动日志 页面日志 曝光日志
*/
HashMap<String, DataStream<JSONObject>> threeStreams = splitStream(validateStream);
//threeStreams.get(START).print(START);
//threeStreams.get(DISPLAY).print(DISPLAY);
//threeStreams.get(PAGE).print(PAGE);
/**
* 3.把不同的流的数据写入到不同的topic中
*/
writeToKafka(threeStreams);
}
/**
* 把不同的流的数据写入到不同的topic中
* @param streams
*/
private void writeToKafka(HashMap<String, DataStream<JSONObject>> streams) {
streams.get(START)
.map(new MapFunction<JSONObject, String>() {
@Override
public String map(JSONObject value) throws Exception {
return value.toJSONString();
}
})
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_START));
streams.get(DISPLAY)
.map(new MapFunction<JSONObject, String>() {
@Override
public String map(JSONObject value) throws Exception {
return value.toJSONString();
}
})
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_DISPLAY));
streams.get(PAGE)
.map(new MapFunction<JSONObject, String>() {
@Override
public String map(JSONObject value) throws Exception {
return value.toJSONString();
}
})
.addSink(FlinkSinkUtil.getKafkaSink(Constant.TOPIC_DWD_PAGE));
}
/**
* 分流: 启动日志 页面日志 曝光日志
* @param stream
*/
private HashMap<String, DataStream<JSONObject>> splitStream(SingleOutputStreamOperator<JSONObject> stream) {
OutputTag<JSONObject> pageTag = new OutputTag<JSONObject>(PAGE) {};
OutputTag<JSONObject> displayTag = new OutputTag<JSONObject>(DISPLAY) {};
SingleOutputStreamOperator<JSONObject> startStream = stream.process(new ProcessFunction<JSONObject, JSONObject>() {
@Override
public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {
//主流:启动日志 侧输出流2个:页面和曝光日志
if (value.containsKey("start")) {
//启动日志
out.collect(value);
} else {
//有可能是曝光和页面
if (value.containsKey("page")) {
//页面
ctx.output(pageTag, value);
}
if (value.containsKey("displays")) {
//曝光
JSONArray displays = value.getJSONArray("displays");
for (int i = 0; i < displays.size(); i++) {
JSONObject obj = displays.getJSONObject(i);
obj.putAll(value.getJSONObject("common"));
obj.putAll(value.getJSONObject("page"));
obj.put("ts", value.getLong("ts"));
ctx.output(displayTag, obj);
}
}
}
}
});
DataStream<JSONObject> pageStream = startStream.getSideOutput(pageTag);
DataStream<JSONObject> displayStream = startStream.getSideOutput(displayTag);
HashMap<String, DataStream<JSONObject>> result = new HashMap<>();
result.put(PAGE,pageStream);
result.put(START,startStream);
result.put(DISPLAY,displayStream);
return result;
}
/**
* 区别新老用户
* @param stream
*/
private SingleOutputStreamOperator<JSONObject> distinguishNewOrOld(DataStreamSource<String> stream) {
//使用事件时间加窗口,找到第一条记录作为新用户,其他都是老用户
return stream.map(new MapFunction<String, JSONObject>() {
@Override
public JSONObject map(String value) throws Exception {
return JSON.parseObject(value);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
return element.getLong("ts");
}
})
)
.keyBy(new KeySelector<JSONObject, String>() {
@Override
public String getKey(JSONObject value) throws Exception {
return value.getJSONObject("common").getString("mid");
}
})
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<JSONObject, JSONObject, String, TimeWindow>() {
private ValueState<Boolean> isFirstState;
@Override
public void open(Configuration parameters) throws Exception {
isFirstState = getRuntimeContext().getState(new ValueStateDescriptor<Boolean>("isFirstState",Boolean.class));
}
@Override
public void process(String key, Context context, Iterable<JSONObject> elements, Collector<JSONObject> out) throws Exception {
if(isFirstState.value() == null){
//这是设备id的第一个窗口,找到时间戳最小的那个,标记为新用户,其他的标记为老用户
//先更新状态
isFirstState.update(true);
//找到时间最小的那个
List<JSONObject> list = IteratorToListUtil.toList(elements);
list.sort(new Comparator<JSONObject>() {
@Override
public int compare(JSONObject o1, JSONObject o2) {
return o1.getLong("ts").compareTo(o2.getLong("ts"));
}
});
for (int i = 0; i < list.size(); i++) {
JSONObject obj = list.get(i);
if(i == 0){
obj.getJSONObject("common").put("is_new","1");
}else{
obj.getJSONObject("common").put("is_new","0");
}
out.collect(obj);
}
}else{
//其他的窗口,所有记录全部标记为老用户
for(JSONObject obj : elements){
obj.getJSONObject("common").put("is_new","0");
out.collect(obj);
}
}
}
});
}
}
六.测试
- 将项目打包上传到服务器上
- 启动 flink-yarn-session
/opt/module/flink-yarn » bin/yarn-session.sh -d
- 启动Job
/opt/module/flink-yarn » bin/flink run -c com.atguigu.gmall.app.dwd.DwdDbApp /opt/module/gmall-flink gmall-realtime-1.0-SNAPSHOT.jar
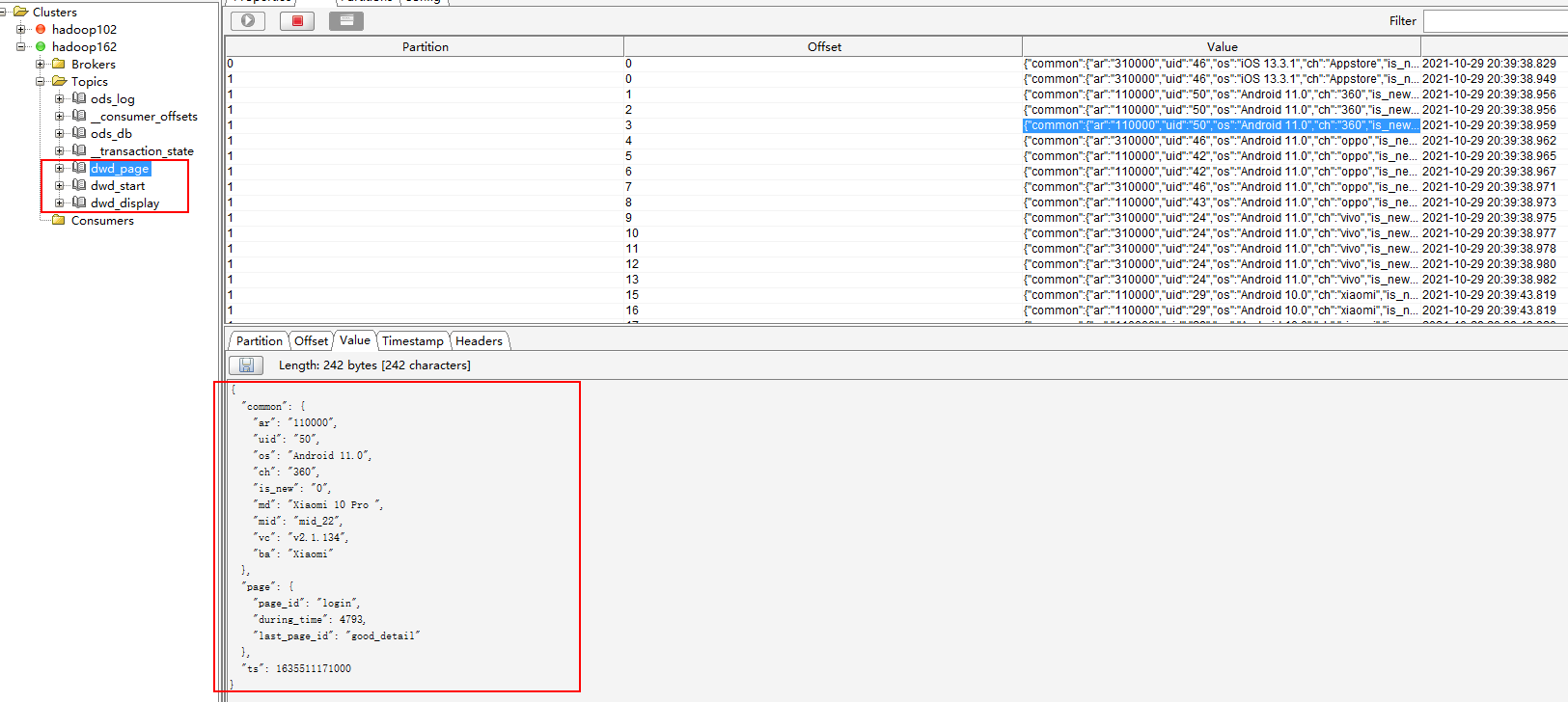
- 打开kafka可视化客户端,可以看到数据已经成功写入到kafka对应的topic中
3.DWD层(业务数据)
业务数据的变化,我们可以通过maxwell采集到,但是Maxwell是把全部数据统一写到一个topic中,这些数据包括业务数据,也包含维度数据,这样显然不利于日后的数据处理
所以需要从ods层读取数据,经过处理后将维度数据保存到Hbase,将事实数据写回到kafka作为业务数据的DWD层
其中将数据写入kafka和hbase这里采用动态分流来实现
一.数据流程图
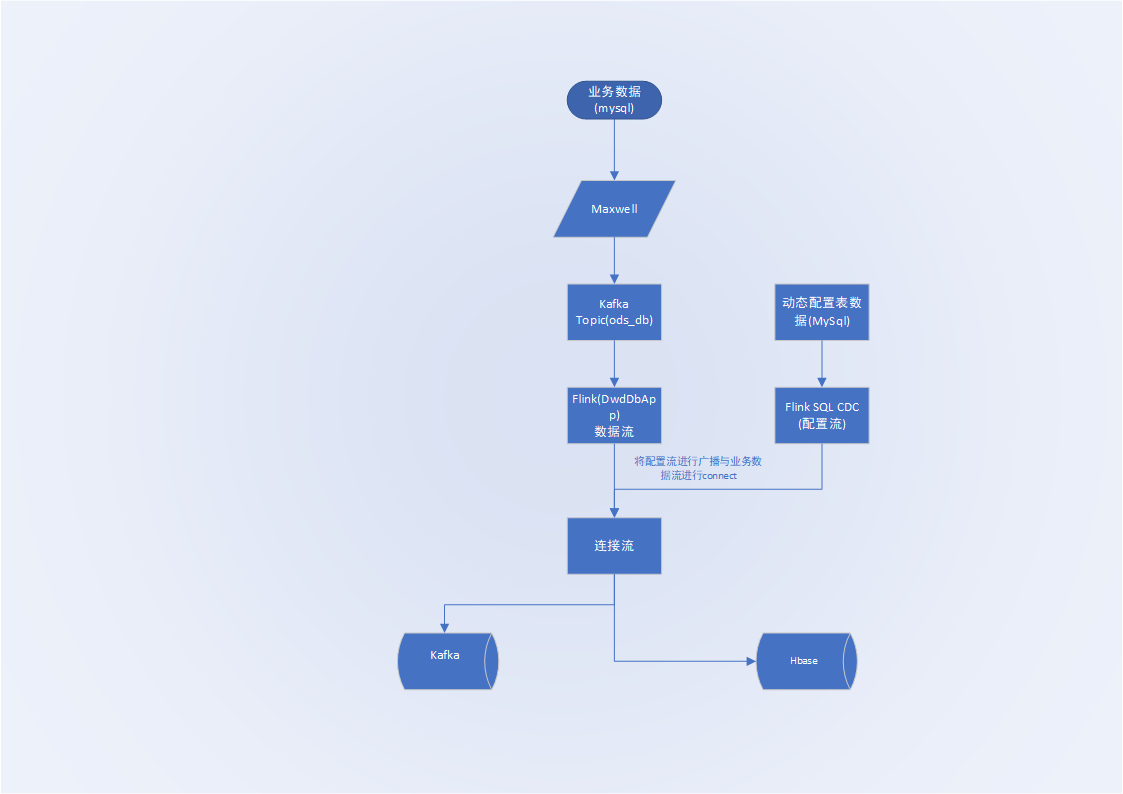
二.设计动态配置表
- 创建动态配置表并初始化数据
CREATE DATABASE `gmall2021_realtime` CHARACTER SET utf8 COLLATE utf8_general_ci;
USE gmall2021_realtime;
source /opt/software/mock/mock_db/table_process_init.sql;
- 配置表实体类
package com.atguigu.gmall.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@NoArgsConstructor
@AllArgsConstructor
@Data
public class TableProcess {
private String source_table;
private String operate_type;
private String sink_type;
private String sink_table;
private String sink_columns;
private String sink_pk;
private String sink_extend;
}
三.实现思路
- 业务数据: mysql->maxwell->kafka->flink
- 动态配置表的数据: mysql->flink-SQL-cdc
- 将动态配置表做成广播流与业务数据进行connect,从而实现动态控制业务数据的sink方向
四.读取动态配置表
使用flink-SQL-cdc来实现
- 修改mysql配置,增加对gmall2021_realtime监控
vim /etc/my.cnf
[mysqld]
server-id= 1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=gmall2021
binlog-do-db=gmall2021_realtime
- 重启mysql数据库
sudo systemctl restart mysqld
注意:修改mysql配置后,maxwell会被关闭,并且启动不了,需要删除mysql中对应的maxwell数据库
五.具体实现代码
- 导入CDC依赖
<!-- https://mvnrepository.com/artifact/com.alibaba.ververica/flink-connector-mysql-cdc -->
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.1.1</version>
</dependency>
- 读取ods层业务数据并ETL
/**
* 对业务数据做etl
* @param stream
*/
private SingleOutputStreamOperator<JSONObject> etl(DataStreamSource<String> stream) {
return stream.map(line -> JSON.parseObject(line.replaceAll("bootstrap-", "")))
.filter(obj ->
obj.containsKey("database")
&& obj.containsKey("table")
&& obj.containsKey("type")
&& ("insert".equals(obj.getString("type")) || "update".equals(obj.getString("type")))
&& obj.containsKey("data")
&& obj.getString("data").length() > 10
);
}
- 读取配置表的数据,做成配置流
/**
* 2.读取配置表的数据,配置流
* @param env
* @return
*/
private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment env) {
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
tenv.executeSql("CREATE TABLE tp (" +
" source_table string, " +
" operate_type string, " +
" sink_type string, " +
" sink_table string, " +
" sink_columns string, " +
" sink_pk string, " +
" sink_extend string, " +
" primary key(source_table, operate_type) not enforced " + //声明主键,但是不做强检验
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'hadoop162'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = 'aaaaaa'," +
" 'database-name' = 'gmall2021_realtime'," +
" 'table-name' = 'table_process', " +
" 'debezium.snapshot.mode' = 'initial' " + // 程序启动的时候读取表中所有的数据, 然后再使用bin_log监控所有的变化
")");
Table table = tenv.sqlQuery("select * from tp");
return tenv
.toRetractStream(table, TableProcess.class)
.filter(t -> t.f0)
.map(t -> t.f1);
}
- 将配置流进行广播得到广播流与数据流进行connect
/**
* 3.把配置流进行广播得到广播流与数据流进行connect
* @param dataStream
* @param tpStream
*/
private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectStreams(SingleOutputStreamOperator<JSONObject> dataStream, SingleOutputStreamOperator<TableProcess> tpStream) {
//每来一条数据 JSONObject,需要找到一个对应的TablaProcess对象
//把配置流做成广播流,然后进行连接,广播流中的元素就是map,可以设置key为userInfo:insert(source_table:operate_type)
MapStateDescriptor<String, TableProcess> tpStateDesc = new MapStateDescriptor<>("tpState", String.class, TableProcess.class);
BroadcastStream<TableProcess> tpBCStream = tpStream.broadcast(tpStateDesc);
return dataStream
.connect(tpBCStream)
.process(new BroadcastProcessFunction<JSONObject, TableProcess, Tuple2<JSONObject, TableProcess>>() {
@Override
public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception {
//处理数据流的数据
ReadOnlyBroadcastState<String, TableProcess> tpState = ctx.getBroadcastState(tpStateDesc);
String key = value.getString("table") + ":" + value.getString("type");
TableProcess tp = tpState.get(key);
//有些表不需要做sink所以配置文件中是没有配置,这里就是null
if (tp != null) {
out.collect(Tuple2.of(value.getJSONObject("data"), tp));
}
}
@Override
public void processBroadcastElement(TableProcess value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception {
//处理广播流的数据:其实就是将广播流的数据写入到广播状态中
BroadcastState<String, TableProcess> tpState = ctx.getBroadcastState(tpStateDesc);
String key = value.getSource_table() + ":" + value.getOperate_type();
tpState.put(key, value);
}
});
}
- 把数据中不需要的列过滤掉
/**
* 4.把数据中不需要的列过滤掉
* @param stream
*/
private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> filterColumns(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) {
//删除那些不要的列
return stream.map(new MapFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() {
@Override
public Tuple2<JSONObject, TableProcess> map(Tuple2<JSONObject, TableProcess> value) throws Exception {
JSONObject data = value.f0;
TableProcess tp = value.f1;
String sink_columns = tp.getSink_columns();
//删除掉data里map中的部分k-v
//data.keySet().removeIf(key -> !sink_columns.contains(key));
Set<String> keys = data.keySet();
Iterator<String> it = keys.iterator();
while (it.hasNext()) {
String key = it.next();
if(!sink_columns.contains(key)){
it.remove();
}
}
return value;
}
});
}
- 动态分流(Kafka,Hbase)
/**
* 5.动态分流(kafka,Hbase)
* 实现思路,主流到kafka,侧输出流到hbase
* @param stream
*/
private Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> dynamicSplit(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) {
OutputTag<Tuple2<JSONObject, TableProcess>> hbaseTag = new OutputTag<Tuple2<JSONObject, TableProcess>>("hbase") {};
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> kafkaStream = stream.process(new ProcessFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() {
@Override
public void processElement(Tuple2<JSONObject, TableProcess> value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception {
String sink_type = value.f1.getSink_type();
if (Constant.DWD_SINK_KAFKA.equals(sink_type)) {
out.collect(value);
} else if (Constant.DWD_SINK_HBASE.equals(sink_type)) {
ctx.output(hbaseTag, value);
}
}
});
DataStream<Tuple2<JSONObject, TableProcess>> hbaseStream = kafkaStream.getSideOutput(hbaseTag);
return Tuple2.of(kafkaStream, hbaseStream);
}
- 将动态分流后的数据写入kafka
一.更新FlinkSinkUtil
package com.atguigu.gmall.util;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.gmall.common.Constant;
import com.atguigu.gmall.pojo.TableProcess;
import com.atguigu.gmall.sink.PhoenixSink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
/**
* 向kafka指定的topic写数据
*/
public class FlinkSinkUtil {
public static SinkFunction<String> getKafkaSink(String topic){
Properties properties = new Properties();
properties.put("bootstrap.servers", Constant.KAFKA_BROKERS);
properties.put("transaction.timeout.ms",15 * 60 * 1000);
return new FlinkKafkaProducer<String>(
"default",
new KafkaSerializationSchema<String>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(String s, @Nullable Long aLong) {
return new ProducerRecord<byte[], byte[]>(topic,s.getBytes(StandardCharsets.UTF_8));
}
},
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
}
public static SinkFunction<Tuple2<JSONObject, TableProcess>> getKafkaSink(){
Properties properties = new Properties();
properties.put("bootstrap.servers", Constant.KAFKA_BROKERS);
properties.put("transaction.timeout.ms",15 * 60 * 1000);
return new FlinkKafkaProducer<Tuple2<JSONObject, TableProcess>>(
"default",
new KafkaSerializationSchema<Tuple2<JSONObject, TableProcess>>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<JSONObject, TableProcess> element, @Nullable Long aLong) {
String topic = element.f1.getSink_table();
String data = element.f0.toJSONString();
return new ProducerRecord<>(topic,data.getBytes(StandardCharsets.UTF_8));
}
},
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
}
public static SinkFunction<Tuple2<JSONObject,TableProcess>> getPhoenixSink(){
return new PhoenixSink();
}
}
二.将动态分流后的数据写入到kafka
/**
* 6.将动态分流后的数据写入到kafka
* @param stream
*/
private void writeToKafka(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) {
//写到同一个topic的数据,最好放在同一组,这样可以提升效率
stream.keyBy(t -> t.f1.getSink_table())
.addSink(FlinkSinkUtil.getKafkaSink());
}
- 将动态分流后的数据写入hbase
一.导入Phoenix相关依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>2.5.0</version>
</dependency>
二.PhoenixSink
将写到Phoenix的代码封装为一个工具类
package com.atguigu.gmall.sink;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.gmall.common.Constant;
import com.atguigu.gmall.pojo.TableProcess;
import com.atguigu.gmall.util.JdbcUtil;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class PhoenixSink extends RichSinkFunction<Tuple2<JSONObject, TableProcess>> {
private Connection conn;
private ValueState<Boolean> isFirst;
/**
* 建立到Phoenix的连接
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
String url = Constant.PHOENIX_URL;
conn = JdbcUtil.getPhoenixConnection(url);
isFirst = getRuntimeContext().getState(new ValueStateDescriptor<Boolean>("isFirst",Boolean.class));
}
/**
* 关闭连接
* @throws Exception
*/
@Override
public void close() throws Exception {
if(conn != null){
conn.close();
}
}
@Override
public void invoke(Tuple2<JSONObject, TableProcess> value, Context context) throws Exception {
//1.建表
checkTable(value);
//2.写数据
writeData(value);
}
private void writeData(Tuple2<JSONObject, TableProcess> value) throws SQLException {
JSONObject data = value.f0;
TableProcess tp = value.f1;
//拼接插入语句
//upsert into t(a,b,c) values(?,?,?)
StringBuilder sql = new StringBuilder();
sql.append("upsert into ")
.append(tp.getSink_table())
.append("(")
.append(tp.getSink_columns())
.append(")values(")
.append(tp.getSink_columns().replaceAll("[^,]+", "?"))
.append(")");
PreparedStatement ps = conn.prepareStatement(sql.toString());
//给占位符赋值,根据列名去data中取值
String[] cs = tp.getSink_columns().split(",");
for (int i = 0; i < cs.length; i++) {
String columnName = cs[i];
Object v = data.get(columnName);
ps.setString(i+1,v==null?null:v.toString());
}
//执行SQL
ps.execute();
conn.commit();
ps.close();
}
/**
* 在Phoenix中进行建表
* 执行建表语句
* @param value
*/
private void checkTable(Tuple2<JSONObject, TableProcess> value) throws IOException, SQLException {
if(isFirst.value() == null){
TableProcess tp = value.f1;
StringBuilder sql = new StringBuilder();
sql
.append("create table if not exists ")
.append(tp.getSink_table())
.append("(")
.append(tp.getSink_columns().replaceAll(",", " varchar, "))
.append(" varchar, constraint pk primary key(")
.append(tp.getSink_pk() == null? "id" : tp.getSink_pk())
.append("))")
.append(tp.getSink_extend() == null ? "" : tp.getSink_extend());
System.out.println(sql.toString());
PreparedStatement ps = conn.prepareStatement(sql.toString());
ps.execute();
conn.commit();
ps.close();
isFirst.update(true);
}
}
}
三.将动态分流后的数据写入到hbase
/**
* 7.将动态分流后的数据写入到hbase
* @param stream
*/
private void writeToHbase(DataStream<Tuple2<JSONObject, TableProcess>> stream) {
stream.keyBy(t -> t.f1.getSink_table())
.addSink(FlinkSinkUtil.getPhoenixSink());
}
六.完整代码
package com.atguigu.gmall.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.gmall.app.BaseAppV1;
import com.atguigu.gmall.common.Constant;
import com.atguigu.gmall.pojo.TableProcess;
import com.atguigu.gmall.util.FlinkSinkUtil;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.Iterator;
import java.util.Set;
/**
* bin/maxwell-bootstrap --user root --password aaaaaa --host hadoop162 --database gmall2021 --table user_info --client_id maxwell_1
*/
public class DwdDbApp extends BaseAppV1 {
public static void main(String[] args) {
new DwdDbApp().init(2002,1,"DwdDbApp","DwdDbApp", Constant.TOPIC_ODS_DB);
}
@Override
public void run(StreamExecutionEnvironment env, DataStreamSource<String> stream) {
//stream.print();
/**
* 1.对业务数据做etl 数据流
*/
SingleOutputStreamOperator<JSONObject> etledStream = etl(stream);
//etledStream.print();
/**
* 2.读取配置表的数据,配置流
*/
SingleOutputStreamOperator<TableProcess> tpStream = readTableProcess(env);
//tpStream.print();
/**
* 3.把配置流进行广播得到广播流与数据流进行connect
*/
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectedStream = connectStreams(etledStream, tpStream);
//connectedStream.print();
/**
* 4.把数据中不需要的列过滤掉
*/
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> filteredStream = filterColumns(connectedStream);
//filteredStream.print();
/**
* 5.根据配置流的配置信息,对数据流中的数据进行动态分流(到kafka的和到hbase的)
*/
Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> kafkaHbaseStreams = dynamicSplit(filteredStream);
//kafkaHbaseStreams.f0.print("kafka");
//kafkaHbaseStreams.f1.print("hbase");
/**
* 6.不同的流写入到不同的sink中
*/
writeToKafka(kafkaHbaseStreams.f0);
writeToHbase(kafkaHbaseStreams.f1);
}
/**
* 7.将动态分流后的数据写入到hbase
* @param stream
*/
private void writeToHbase(DataStream<Tuple2<JSONObject, TableProcess>> stream) {
stream.keyBy(t -> t.f1.getSink_table())
.addSink(FlinkSinkUtil.getPhoenixSink());
}
/**
* 6.将动态分流后的数据写入到kafka
* @param stream
*/
private void writeToKafka(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) {
//写到同一个topic的数据,最好放在同一组,这样可以提升效率
stream.keyBy(t -> t.f1.getSink_table())
.addSink(FlinkSinkUtil.getKafkaSink());
}
/**
* 5.动态分流(kafka,Hbase)
* 实现思路,主流到kafka,侧输出流到hbase
* @param stream
*/
private Tuple2<SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>>, DataStream<Tuple2<JSONObject, TableProcess>>> dynamicSplit(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) {
OutputTag<Tuple2<JSONObject, TableProcess>> hbaseTag = new OutputTag<Tuple2<JSONObject, TableProcess>>("hbase") {};
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> kafkaStream = stream.process(new ProcessFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() {
@Override
public void processElement(Tuple2<JSONObject, TableProcess> value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception {
String sink_type = value.f1.getSink_type();
if (Constant.DWD_SINK_KAFKA.equals(sink_type)) {
out.collect(value);
} else if (Constant.DWD_SINK_HBASE.equals(sink_type)) {
ctx.output(hbaseTag, value);
}
}
});
DataStream<Tuple2<JSONObject, TableProcess>> hbaseStream = kafkaStream.getSideOutput(hbaseTag);
return Tuple2.of(kafkaStream, hbaseStream);
}
/**
* 4.把数据中不需要的列过滤掉
* @param stream
*/
private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> filterColumns(SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> stream) {
//删除那些不要的列
return stream.map(new MapFunction<Tuple2<JSONObject, TableProcess>, Tuple2<JSONObject, TableProcess>>() {
@Override
public Tuple2<JSONObject, TableProcess> map(Tuple2<JSONObject, TableProcess> value) throws Exception {
JSONObject data = value.f0;
TableProcess tp = value.f1;
String sink_columns = tp.getSink_columns();
//删除掉data里map中的部分k-v
//data.keySet().removeIf(key -> !sink_columns.contains(key));
Set<String> keys = data.keySet();
Iterator<String> it = keys.iterator();
while (it.hasNext()) {
String key = it.next();
if(!sink_columns.contains(key)){
it.remove();
}
}
return value;
}
});
}
/**
* 3.把配置流进行广播得到广播流与数据流进行connect
* @param dataStream
* @param tpStream
*/
private SingleOutputStreamOperator<Tuple2<JSONObject, TableProcess>> connectStreams(SingleOutputStreamOperator<JSONObject> dataStream, SingleOutputStreamOperator<TableProcess> tpStream) {
//每来一条数据 JSONObject,需要找到一个对应的TablaProcess对象
//把配置流做成广播流,然后进行连接,广播流中的元素就是map,可以设置key为userInfo:insert(source_table:operate_type)
MapStateDescriptor<String, TableProcess> tpStateDesc = new MapStateDescriptor<>("tpState", String.class, TableProcess.class);
BroadcastStream<TableProcess> tpBCStream = tpStream.broadcast(tpStateDesc);
return dataStream
.connect(tpBCStream)
.process(new BroadcastProcessFunction<JSONObject, TableProcess, Tuple2<JSONObject, TableProcess>>() {
@Override
public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception {
//处理数据流的数据
ReadOnlyBroadcastState<String, TableProcess> tpState = ctx.getBroadcastState(tpStateDesc);
String key = value.getString("table") + ":" + value.getString("type");
TableProcess tp = tpState.get(key);
//有些表不需要做sink所以配置文件中是没有配置,这里就是null
if (tp != null) {
out.collect(Tuple2.of(value.getJSONObject("data"), tp));
}
}
@Override
public void processBroadcastElement(TableProcess value, Context ctx, Collector<Tuple2<JSONObject, TableProcess>> out) throws Exception {
//处理广播流的数据:其实就是将广播流的数据写入到广播状态中
BroadcastState<String, TableProcess> tpState = ctx.getBroadcastState(tpStateDesc);
String key = value.getSource_table() + ":" + value.getOperate_type();
tpState.put(key, value);
}
});
}
/**
* 2.读取配置表的数据,配置流
* @param env
* @return
*/
private SingleOutputStreamOperator<TableProcess> readTableProcess(StreamExecutionEnvironment env) {
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
tenv.executeSql("CREATE TABLE tp (" +
" source_table string, " +
" operate_type string, " +
" sink_type string, " +
" sink_table string, " +
" sink_columns string, " +
" sink_pk string, " +
" sink_extend string, " +
" primary key(source_table, operate_type) not enforced " + //声明主键,但是不做强检验
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'hadoop162'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = 'aaaaaa'," +
" 'database-name' = 'gmall2021_realtime'," +
" 'table-name' = 'table_process', " +
" 'debezium.snapshot.mode' = 'initial' " + // 程序启动的时候读取表中所有的数据, 然后再使用bin_log监控所有的变化
")");
Table table = tenv.sqlQuery("select * from tp");
return tenv
.toRetractStream(table, TableProcess.class)
.filter(t -> t.f0)
.map(t -> t.f1);
}
/**
* 对业务数据做etl
* @param stream
*/
private SingleOutputStreamOperator<JSONObject> etl(DataStreamSource<String> stream) {
return stream.map(line -> JSON.parseObject(line.replaceAll("bootstrap-", "")))
.filter(obj ->
obj.containsKey("database")
&& obj.containsKey("table")
&& obj.containsKey("type")
&& ("insert".equals(obj.getString("type")) || "update".equals(obj.getString("type")))
&& obj.containsKey("data")
&& obj.getString("data").length() > 10
);
}
}
七.测试
- 将项目重新打包并上传到linux服务器上
- 编写启动app的脚本
#!/bin/bash
flink=/opt/module/flink-yarn/bin/flink
app_jar=/opt/module/gmall-flink/gmall-realtime-1.0-SNAPSHOT.jar
# 数组, 获取到所有正在运行的app
runnings=`$flink list 2>/dev/null | awk '/RUNNING/{ print $(NF-1)}'`
# 定义数组
apps=(
com.atguigu.gmall.app.dwd.DwdLogApp
com.atguigu.gmall.app.dwd.DwdDbApp
)
for app in ${apps[*]} ; do
app_name=`echo $app | awk -F . '{print $NF}'`
# app_name是否存在于runnings中
if [[ ${runnings[@]} =~ $app_name ]]; then
echo "$app_name 已经启动, 不需要重新启动...."
else
# 如果不存在
echo "$app_name 开始启动...."
$flink run -d -c $app $app_jar
fi
done
- 启动hbase,Phoenix,hadoop,zookeeper,kafka,flink-yarn
- 启动脚本后发现报错
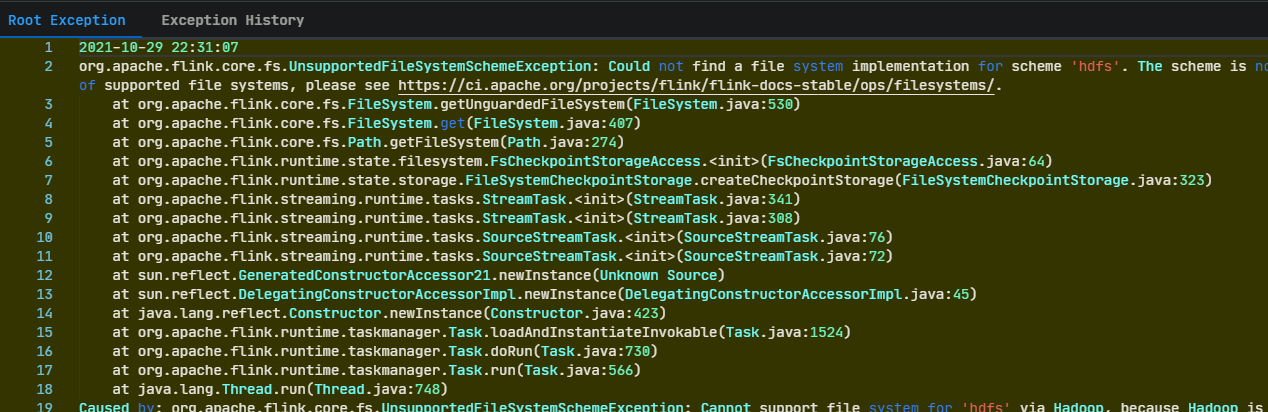
原因是项目打包会把hadoop相关的依赖也打进去,与集群产生冲突故需要在pom.xml中配置打包时不要打hadoop依赖
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<!--和hadoop相关的所有的依赖都不要打包-->
<exclude>org.apache.hadoop:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 重新打包并上传至服务器
- 重启flink-yarnsession,并执行脚本
/opt/module/flink-yarn » bin/yarn-session.sh -d
/opt/module/flink-yarn » realtime.sh
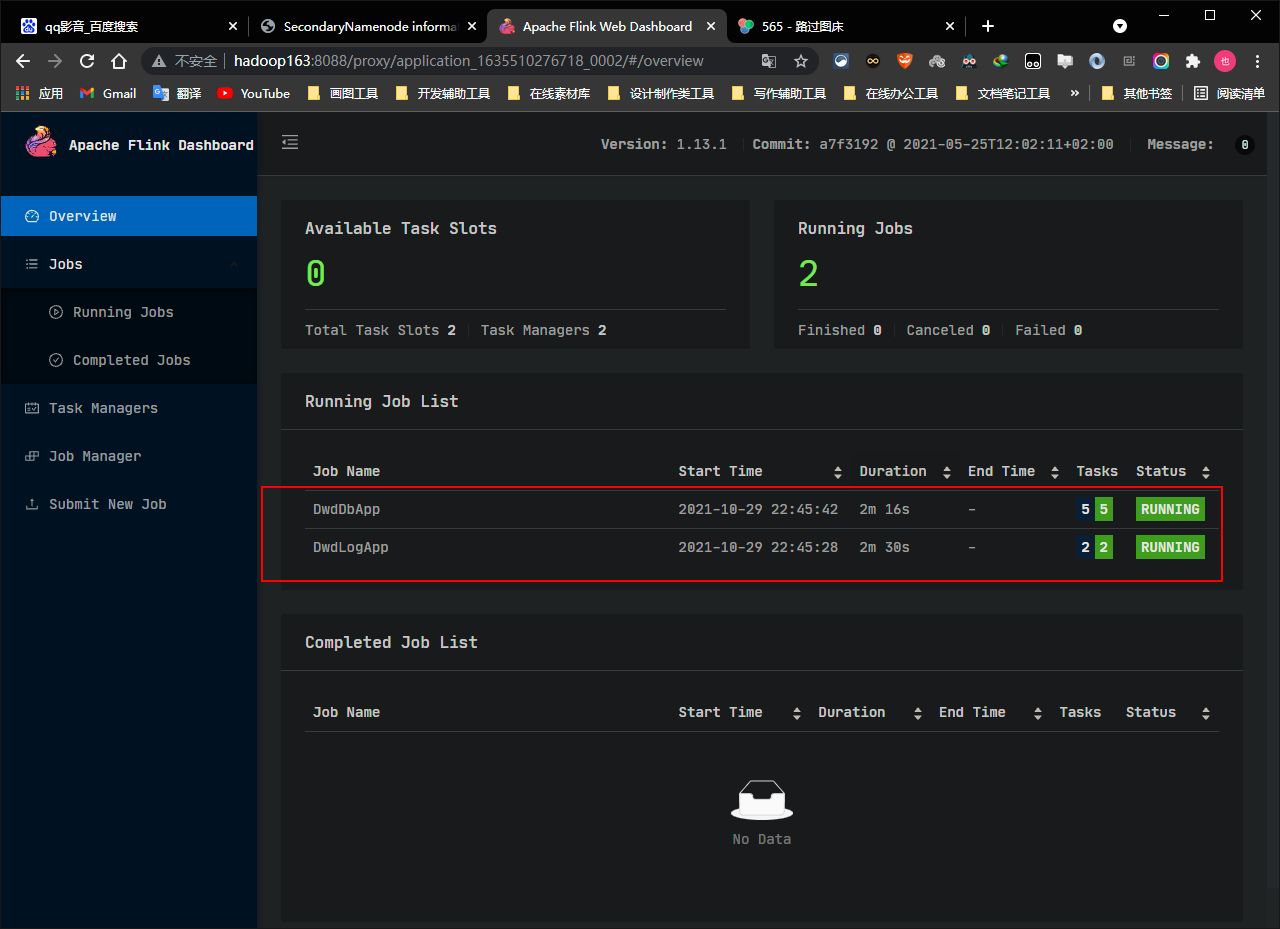
- 打开浏览器查看发现任务已经成功运行
- 模拟生成业务数据,查看数据是否已经写入到kafka和hbase
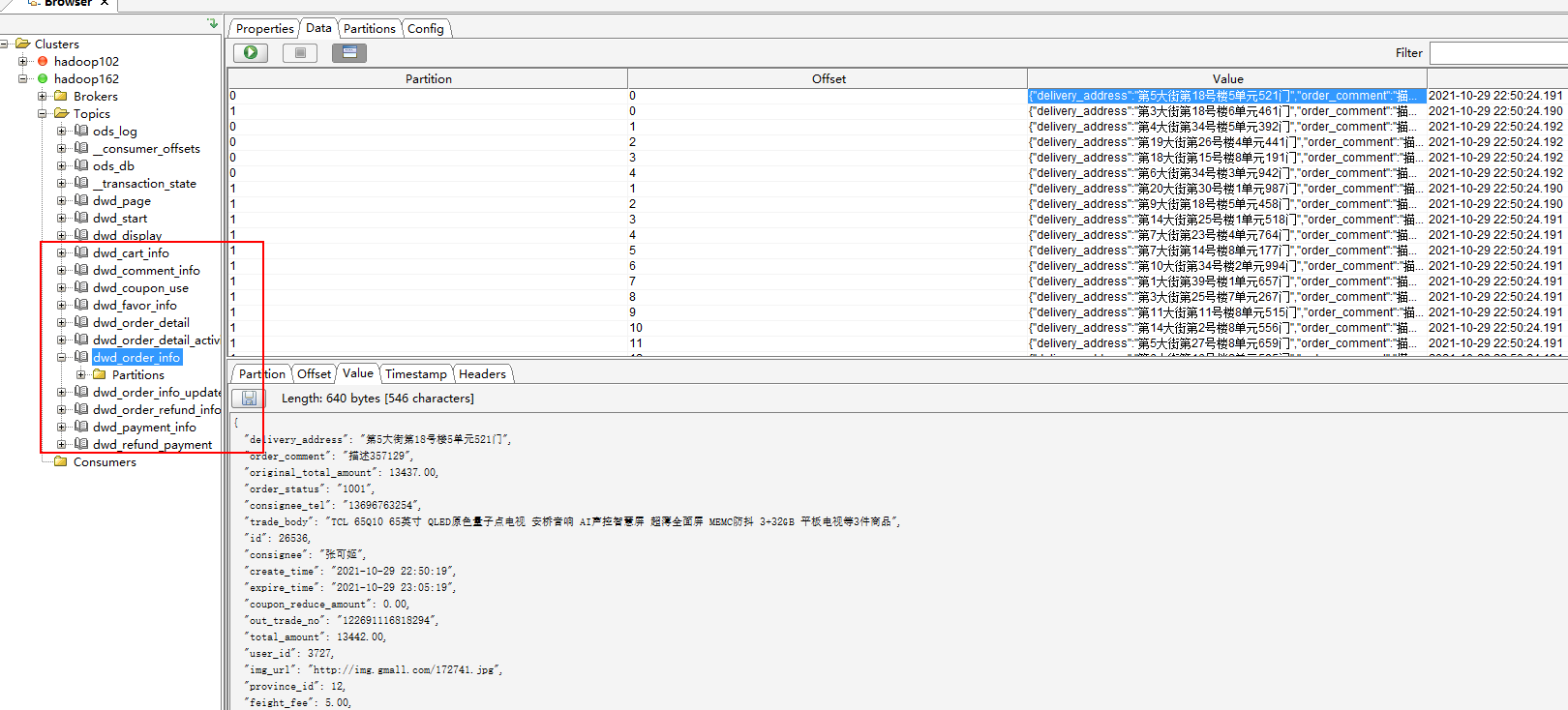
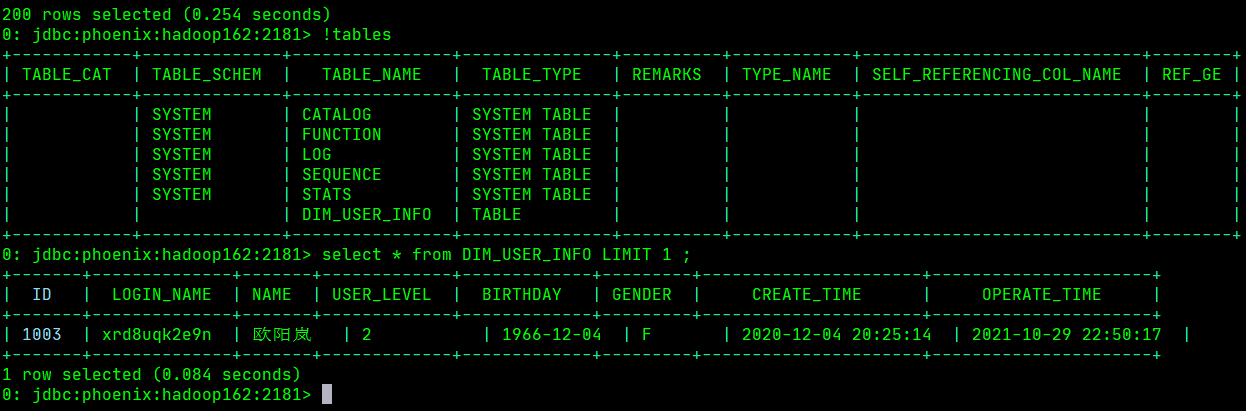
从上面两张图可以看出数据已经成功的写入到kafka和hbase中

若有收获,就点个赞吧
0 人点赞
