1. API约定
1、 多个索引参数约定
大多数api都支持多索引执行(一次性操作多个索引)
| 多个索引: test1,test2,test3 所有索引: _all 通配符: 例如:test或test或tet或test,以及“排除”(-)的能力,例如:test,-test3。 |
|---|
不支持多索引的api:Document APIs 和 single-index alias APIs
2. 判断索引存在
1. 语法
2. 例子
索引存在

索引不存在

3. 打开/关闭索引
一个关闭的索引在集群上几乎没有开销(除了维护它的元数据之外),并且对于读/写操作阻塞。一个关闭的索引可以被打开,然后进行正常的恢复过程。可以打开和关闭多个索引。
1. 语法
POST /my_index/_close
POST /my_index/_open
2. 例子
关闭一个索引


打开一个索引


关闭多个(所有)索引


温馨提示1:
如果想禁用通过通配符或_all标识来关闭和开启索引,可以将配置文件中的action.destructive_requires_name设置为true来禁用。还可以通过集群更新设置api更改此设置。
温馨提示2:
关闭索引会消耗大量磁盘空间,这可能会导致管理环境中的问题。可以通过设置cluster. indics .close为false(默认值为true)来禁用索引关闭。
打开多个(所有)索引


4. 收缩索引 shrink index
shrink index API 是把一个源索引,收缩到另一个主分片更少的目标索引中。但是目标索引的分片数,必须是源索引分片数的因子。比如,源索引的分片数是:8,那么目标索引的分片数可以是:4, 2, 1;如果源索引的分片数是一个素数,那么目标索引的分片数只能是:1。在收缩之前,源索引中每个分片都要有一个副本在这个节点上。 收缩索引的步骤如下:
1) 以源索引的定义(设置)创建一个目标索引。但是目标索引的分片数量要小于源索引的分片数量。
2) 把源索引的段,硬链接到目标索引,如果文件系统不支持硬链接,那么只能复制到目标索引,这将是一个耗时操作。
3) 最后目标索引恢复使用,就像刚刚重新打开的一样。
5. 分解索引 Split Index
6. 翻转索引 Rollover Index
当认为现有索引太大或太旧时,rollover index API将别名滚转到新索引。
7. PUT mapping
PUT mapping API允许您向现有索引添加字段,或更改现有字段。
1. 语法
为单个索引添加字段
| PUT 索引名称/_mapping/类型名称 { “properties”: { “字段名称”: { “type”: “字段类型” } } } |
|---|
为多个索引添加字段
| PUT 多个索引名称/_mapping/类型名称 { “properties”: { “字段名称”: { “type”: “字段类型” } } } |
|---|
2. 例子
向一个索引新增字段
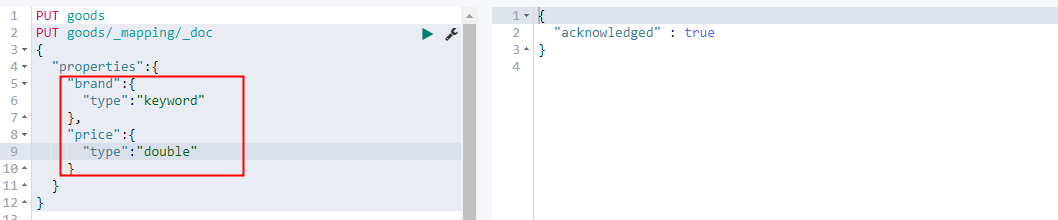
说明:使用PUT mapping API将名为brand、price的两个新字段添加到索引goods的类型_doc中。
向多个索引新增字段

8. 获取映射 Get Mapping
get mapping API允许检索索引或索引/类型的映射定义。
1. 获取单个索引(或索引类型)
语法
| GET 索引名称/_mapping GET 索引名称/_mapping/类型名称 |
|---|
例子

2. 获取多个索引(或索引类型)
语法
| GET 多个索引名称/_mapping GET 多个索引名称/_mapping/类型名称 |
|---|
例子

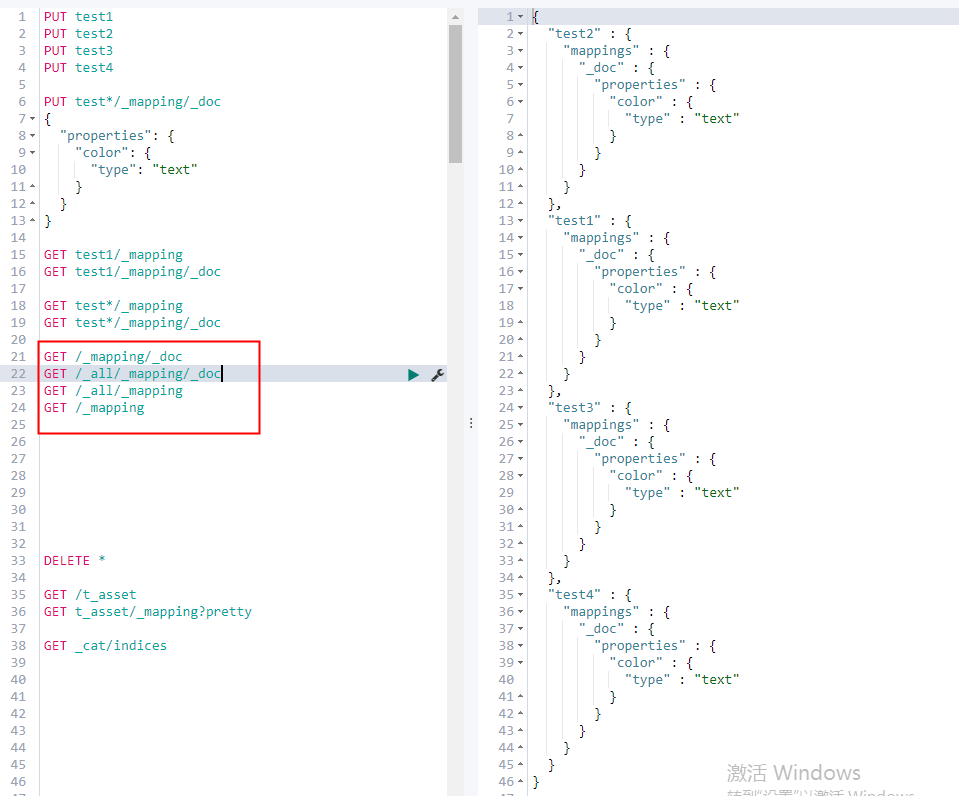
3. 获取所有索引(或索引类型)
语法
| GET /_mapping/类型名称 GET /_all/_mapping/类型名称 GET /_all/_mapping GET /_mapping |
|---|
例子
9. 获取字段映射 Get Field Mapping
0. 作用:
检索一个或多个字段的映射定义。类似MySQL中查询某个字段的定义。
1. 单个字段定义
| GET 索引名称/_mapping/类型名称/field/字段名称 |
|---|
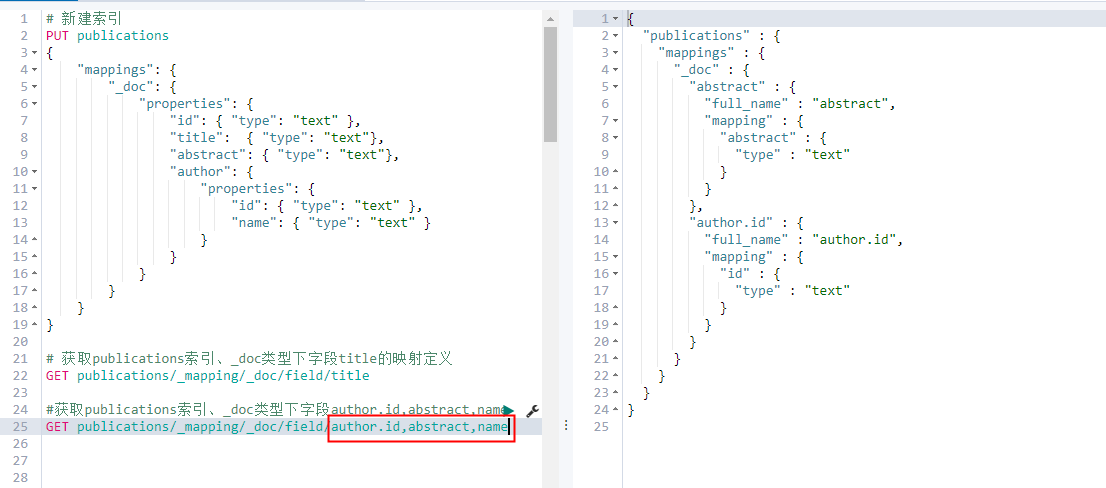
| # 新建索引 PUT publications { “mappings”: { “_doc”: { “properties”: { “id”: { “type”: “text” }, “title”: { “type”: “text”}, “abstract”: { “type”: “text”}, “author”: { “properties”: { “id”: { “type”: “text” }, “name”: { “type”: “text” } } } } } } } # 获取publications索引、_doc类型下字段title的映射定义 GET publications/_mapping/_doc/field/title #查询结果 { “publications” : { “mappings” : { “_doc” : { “title” : { “full_name” : “title”, “mapping” : { “title” : { “type” : “text” } } } } } } } |
|---|
2. 多个索引、类型和字段定义获取
语法:
host:port/{index}/{type}/_mapping/field/{field} 其中{index}、{type}和{field}可以表示用逗号分隔的名称列表或通配符 |
|---|
例子
| GET /twitter,kimchy/_mapping/field/message GET /_all/_mapping/_doc/field/message,user.id GET /_all/_mapping/_doc/field/*.id GET publications/_mapping/_doc/field/author.id,abstract,name |
|---|

10. 判断类型存在性 Types Exists
| HEAD 索引名称/_mapping/类型名称 |
|---|


11. 索引别名 Index Aliases
Es支持为索引起别名。es所有API都会自动将别名转换为实际的索引名称。一个别名可以映射到多个索引(也及时多个索引可以有共同的别名,别名与索引之间的关系是多对多的关系),别名可以与在搜索和路由值时自动应用的筛选器相关联。
注意:别名不能与索引具有相同的名称。
1. 新建别名
下面是一个将别名alias1与索引test1关联起来的示例
| POST /_aliases { “actions” : [ { “add” : { “index” : “test1”, “alias” : “alias1” } } ] } |
|---|

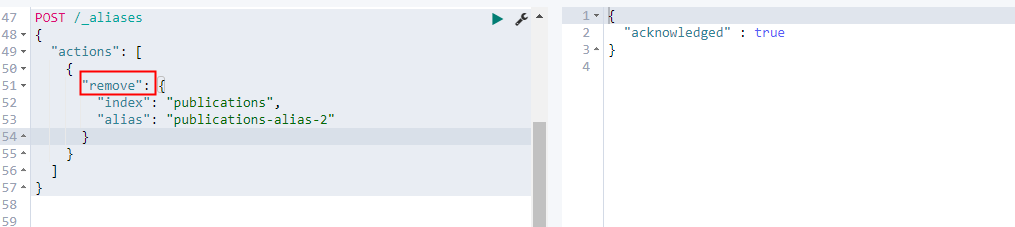
2. 移除别名
| POST /_aliases { “actions” : [ { “remove” : { “index” : “test1”, “alias” : “alias1” } } ] } |
|---|

3. 重命名别名
说明:在相同(同一个)的API中,重命名别名是一个简单的删除然后添加操作。这个操作是原子的,不需要担心短时间内的别名不指向一个索引:
| POST /_aliases { “actions” : [ { “remove” : { “index” : “test1”, “alias” : “alias1” } }, { “add” : { “index” : “ test1”, “alias” : “alias2” } } ] } |
|---|

4. 一个别名关联多个索引
将一个别名与多个索引关联只是同时对同多个索引做了几个添加操作:
方式一:一个action操作一个索引
| POST /_aliases { “actions” : [ { “add” : { “index” : “test1”, “alias” : “alias1” } }, { “add” : { “index” : “test2”, “alias” : “alias1” } } ] } |
|---|


方式二:一个action操作多个索引(索引数组)
| POST /_aliases { “actions” : [ { “add” : { “indices” : [“test1”, “test2”], “alias” : “alias1” } } ] } |
|---|


方式三:一个action操作多个索引(通配符)
| POST /_aliases { “actions” : [ { “add” : { “index” : “test*”, “alias” : “all_test_indices” } } ] } |
|---|


5. 带过滤器的别名 Filtered Aliases
带有过滤器的别名为创建相同索引的不同“视图”提供了一种简单的方法。可以使用查询DSL定义筛选器,并将其应用于所有搜索、计数、查询删除等类似的操作。
(类似MySQL中的试图)
6. 路由 Routing
可以将路由值与别名关联。此功能可以与筛选别名一起使用,以避免不必要的碎片操作。
7. 添加单个别名
语法:
| PUT /{index}/_alias/name 或 PUT /{index}/_aliases/name |
|---|
示例:
| PUT test1 PUT test2 PUT test3 PUT test4 GET test/_alias # 为test1索引增加别名test1-alias(单个) PUT /test1/_alias/test1-alias PUT /test1/_aliases/test1-alias # 为test开头的索引增加别名test-alias PUT /test/_alias/test-alias PUT /test*/_aliases/test-alias |
|---|
8. 删除别名(单个、多个,或全部)
| DELETE /{index}/_alias/{name} |
|---|
实例
| # 1、删除单个索引的别名 DELETE /test1/_alias/test1 # 2、删除多个索引的多个别名 DELETE /test/_alias/test* |
|---|
9. 检索别名 Retrieving existing aliases
| GET /{index}/_alias/{alias} |
|---|
10. 索引别名存在性判断
| HEAD /_alias/2016 HEAD /_alias/20 HEAD /index/_alias/ |
|---|
12. 获取配置 Get Settings
该API可用于通过单个调用获取多个索引的设置。该API的一般用法遵循以下语法:host:port/{index}/_settings,其中{index}可以表示用逗号分隔的索引名和别名列表。要获取所有索引的设置,可以使用_all。还支持通配符表达式。以下是一些例子:
| #获取索引test1,test2的settings GET /test1,test2/settings #获取所有索引的setting GET /_all/_settings #获取test开头的索引的setting GET /test/_settings #获取指定名称的settings GET /test/_settings/index.number* |
|---|
13. 更新索引配置 Update Indices Settings
1. 更新索引的配置项
| #更改特定索引的设置 PUT /test1/_settings { “index” : { “number_of_replicas” : 2 } } |
|---|
| #更改所有索引的设置 PUT /_settings { “index” : { “number_of_replicas” : 2 } } |
|---|
| # 若要将设置重置为默认值,请设置null。 PUT /{index}/_settings { “index” : { “refresh_interval” : null } } |
|---|
2. 更新索引的分析器
为索引定义新的分析器。但是需要先关闭索引,然后在进行更改后再打开它。
| # 1、关闭索引 POST /twitter/_close # 2、为索引增加的分析器 PUT /twitter/_settings { “analysis” : { “analyzer”:{ “content”:{ “type”:”custom”, “tokenizer”:”whitespace” } } } } # 3、开启索引 POST /twitter/_open |
|---|
14. 分析器 Analyze
对文本执行分析过程,并返回文本的标记分解。可以在不指定索引的情况下使用许多内置的分析器:
分析器可以包含三个部分,字符过滤器(character filters)、分词器(tokenizer)和分词过滤器(token filters)。一个分析器不一定这三个部分都有,但是一般会包含分词器。ES自带的分析器有如下几种:
1. 内置分词器:
| Standard Analyzer | (1)默认分词器,如果未指定,则使用该分词器。 (2)按词切分,支持多语言 (3)小写处理,它删除大多数标点符号、小写术语,并支持删除停止词。 |
|---|---|
| Simple Analyzer | (1)按照非字母切分,简单分词器在遇到不是字母的字符时将文本分解为术语 (2)小写处理,所有条款都是小写的。 |
| Whitespace Analyzer | 空白字符作为分隔符,当遇到任何空白字符,空白分词器将文本分成术语。 |
| Stop Analyzer | (1)类似于Simple Analyzer,但相比Simple Analyzer,支持删除停用词 (2)停用词指语气助词等修饰性词语,如the, an, is的, 这等 |
| 其他分词器 | Pattern Analyzer 模式分词器使用正则表达式将文本拆分为术语。 (1)通过正则表达式自定义分隔符 (2)默认是\W+,即非字词的符号作为分隔符 Language Analyzers ElasticSearch提供许多语言特定的分析工具,如英语或法语。 Fingerprint Analyzer 指纹分词器是一种专业的指纹分词器,它可以创建一个指纹,用于重复检测。 Custom analyzers 如果您找不到适合您需要的分词器,您可以创建一个自定义分词器,它结合了适当的字符过滤器、记号赋予器和记号过滤器。 |
2. 实例
GET _analyze { “analyzer” : “simple”, “text” : [“THIS is a test”, “the second text”] } GET _analyze { “analyzer” : “simple”, “text” : [“THIS is a test”, “the second text”] } GET _analyze { “analyzer” : “whitespace”, “text” : [“THIS is a test”, “the second text”] } GET _analyze { “analyzer” : “stop”, “text” : [“THIS is a test”, “the second text”] } |
|---|
15. 中文分析器ik-analyzer
ik 带有两个分词器
ik_max_word:会将文本做最细粒度的拆分;尽可能多的拆分出词语
ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有

若有收获,就点个赞吧
0 人点赞
