1. 概览
TypeScript 编译器源文件位于 src/compiler 目录下 (不过有一点差别的是 因为我这边参考的文档是 深入理解Typescript 它里面用的源码 是 参考的是 ntypescript 所以在往下面的源码介绍中 我用的也是这个。)
它分为以下几个部分
- Scanner 扫描器 (scanner.ts)
- Parser 解析器(parser.ts)
- Binder绑定器(binder.ts)
- Checker检查器(checker.ts)
- Emitter发射器(emitter)
他们的工作线路如下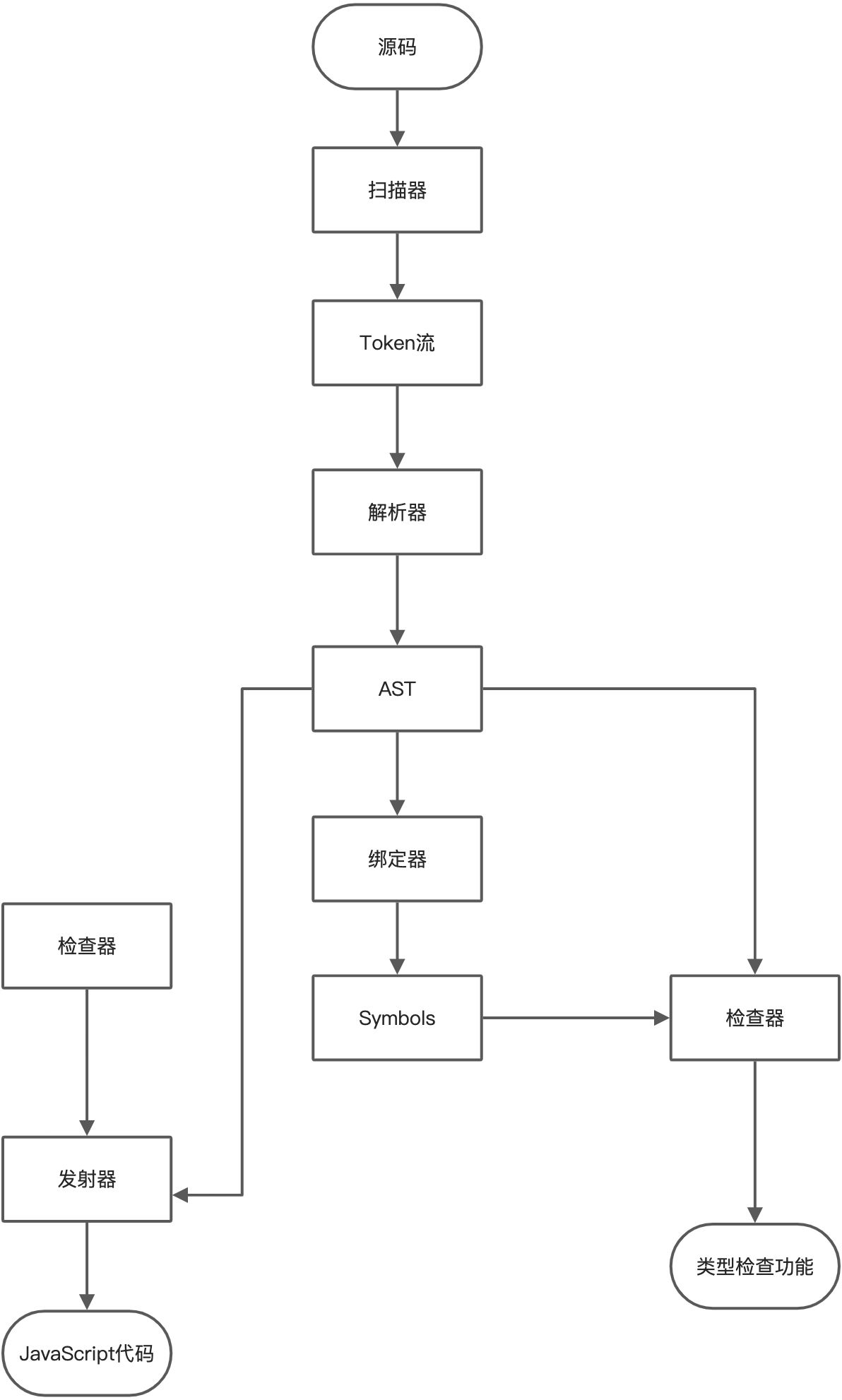
2. 解析器对扫描器的使用
因为这里我们其实还没有讲到解析器相关的知识 所以 我们在这里 先知道一个知识点就好了 扫描器的调用入口 其实是在 解析器中的。
下面有一个解析器中的代码简化版
import * as ts from 'ntypescript';// 单例扫描器const scanner = ts.createScanner(ts.ScriptTarget.Latest, /* 忽略杂项 */ true);// 此函数与初始化使用的 `initializeState` 函数相似function initializeState(text: string) {scanner.setText(text);scanner.setOnError((message: ts.DiagnosticMessage, length: number) => {console.error(message);});scanner.setScriptTarget(ts.ScriptTarget.ES5);scanner.setLanguageVariant(ts.LanguageVariant.Standard);}// 使用示例initializeState(`var foo = 123;`.trim());// 开始扫描var token = scanner.scan();while (token != ts.SyntaxKind.EndOfFileToken) {let currentToken = ts.formatSyntaxKind(token);let tokenStart = scanner.getStartPos();token = scanner.scan();let tokenEnd = scanner.getStartPos();console.log(currentToken, tokenStart, tokenEnd);}
运行上面的代码
ConstKeyword 0 5Identifier 5 9EqualsToken 9 11NumericLiteral 11 15SemicolonToken 15 16
2.1 createScanner
// Creates a scanner over a (possibly unspecified) range of a piece of text.export function createScanner(languageVersion: ScriptTarget,skipTrivia: boolean,languageVariant = LanguageVariant.Standard,text?: string,onError?: ErrorCallback,start?: number,length?: number): Scanner {// Current position (end position of text of current token)let pos: number;// end of textlet end: number;// Start position of whitespace before current tokenlet startPos: number;// Start position of text of current tokenlet tokenPos: number;let token: SyntaxKind;let tokenValue: string;let precedingLineBreak: boolean;let hasExtendedUnicodeEscape: boolean;let tokenIsUnterminated: boolean;let numericLiteralFlags: NumericLiteralFlags;setText(text, start, length);return {getStartPos: () => startPos,getTextPos: () => pos,getToken: () => token,getTokenPos: () => tokenPos,getTokenText: () => text.substring(tokenPos, pos),getTokenValue: () => tokenValue,hasExtendedUnicodeEscape: () => hasExtendedUnicodeEscape,hasPrecedingLineBreak: () => precedingLineBreak,isIdentifier: () => token === SyntaxKind.Identifier || token > SyntaxKind.LastReservedWord,isReservedWord: () => token >= SyntaxKind.FirstReservedWord && token <= SyntaxKind.LastReservedWord,isUnterminated: () => tokenIsUnterminated,getNumericLiteralFlags: () => numericLiteralFlags,// ...,scan,getText,setText,setScriptTarget,setLanguageVariant,setOnError,setTextPos,tryScan,lookAhead,scanRange,};
我们通过 createScanner 创建扫描器之后 是通过 scan 方法来进行源代码的扫描操作 我们可以继续往下看 scan 函数的执行逻辑
2.2 scan
首先 我们先根据定义来看
scan(): SyntaxKind;
我们可以看到 scan 方法执行完成之后 最后返回的是 SyntaxKind
SyntaxKind 是一个枚举 代码如下
export const enum SyntaxKind {Unknown,EndOfFileToken,SingleLineCommentTrivia,MultiLineCommentTrivia,NewLineTrivia,WhitespaceTrivia,// We detect and preserve #! on the first lineShebangTrivia,// We detect and provide better error recovery when we encounter a git merge marker. This// allows us to edit files with git-conflict markers in them in a much more pleasant manner.ConflictMarkerTrivia,// LiteralsNumericLiteral,StringLiteral,JsxText,// ...}
我们可以看到返回的是Token 的定义相关的内容 也就是 词法关键词的枚举
接下来我们看下 scan 的具体执行
function scan(): SyntaxKind {startPos = pos;hasExtendedUnicodeEscape = false;precedingLineBreak = false;tokenIsUnterminated = false;numericLiteralFlags = 0;while (true) {tokenPos = pos;if (pos >= end) {return token = SyntaxKind.EndOfFileToken;}let ch = text.charCodeAt(pos);// Special handling for shebangif (ch === CharacterCodes.hash && pos === 0 && isShebangTrivia(text, pos)) {pos = scanShebangTrivia(text, pos);if (skipTrivia) {continue;}else {return token = SyntaxKind.ShebangTrivia;}}switch (ch) {case CharacterCodes.lineFeed:case CharacterCodes.carriageReturn:precedingLineBreak = true;if (skipTrivia) {pos++;continue;}else {if (ch === CharacterCodes.carriageReturn && pos + 1 < end && text.charCodeAt(pos + 1) === CharacterCodes.lineFeed) {// consume both CR and LFpos += 2;}else {pos++;}return token = SyntaxKind.NewLineTrivia;}// ...default:if (isIdentifierStart(ch, languageVersion)) {pos++;while (pos < end && isIdentifierPart(ch = text.charCodeAt(pos), languageVersion)) pos++;tokenValue = text.substring(tokenPos, pos);if (ch === CharacterCodes.backslash) {tokenValue += scanIdentifierParts();}return token = getIdentifierToken();}else if (isWhiteSpaceSingleLine(ch)) {pos++;continue;}else if (isLineBreak(ch)) {precedingLineBreak = true;pos++;continue;}error(Diagnostics.Invalid_character);pos++;return token = SyntaxKind.Unknown;}}}
我们读这段代码 可以发现 其中对于整个 scan 逻辑 处理最重要的就是 let ch = text.charCodeAt(pos); 通过生成unicode 编码 从而得到扫描的结果
下面我们 简单分析 下 const foo = 123; 是如何解析出来的 首先 我们 const 走的是 default 会把 const 取出来 然后 走 return token = getIdentifierToken
function getIdentifierToken(): SyntaxKind {// Reserved words are between 2 and 11 characters long and start with a lowercase letterconst len = tokenValue.length;if (len >= 2 && len <= 11) {const ch = tokenValue.charCodeAt(0);if (ch >= CharacterCodes.a && ch <= CharacterCodes.z) {token = textToToken.get(tokenValue);if (token !== undefined) {return token;}}}return token = SyntaxKind.Identifier;}
我们发现 整个 const 属于 判断条件 之后 走的是 token = textToToken.get(tokenValue);
const textToToken = createMapFromTemplate({"abstract": SyntaxKind.AbstractKeyword,"any": SyntaxKind.AnyKeyword,"as": SyntaxKind.AsKeyword,"boolean": SyntaxKind.BooleanKeyword,"break": SyntaxKind.BreakKeyword,"case": SyntaxKind.CaseKeyword,"catch": SyntaxKind.CatchKeyword,"class": SyntaxKind.ClassKeyword,"continue": SyntaxKind.ContinueKeyword,"const": SyntaxKind.ConstKeyword,"constructor": SyntaxKind.ConstructorKeyword,"debugger": SyntaxKind.DebuggerKeyword,// ...});
最后 我们 可以 得到如下结果
- const -> ConstKeyword
- foo -> Identifier
- = -> EqualsToken
- 123 -> NumericLiterals
- ; -> SemicolonToken
3. 总结
在scan 函数中包含了 对各个符号的解析方法 有兴趣的话 可以自己打断点研究下

若有收获,就点个赞吧
0 人点赞
