go运行时调度器做什么?
Go 调度器可以决定只在它知道内存一致的点进行调度。这意味着当我们停止垃圾收集时,我们只需要等待 CPU 内核上正在运行的线程。
讲解顺序:
小->大->详细
小:只是讲下 go-schedule的发展历史 及 所谓的GMP的结构
大:粗略的讲schedule的整个函数调用流程 函数到函数的调用
详细:具体函数的作用,以及gmp这几个结构的流转
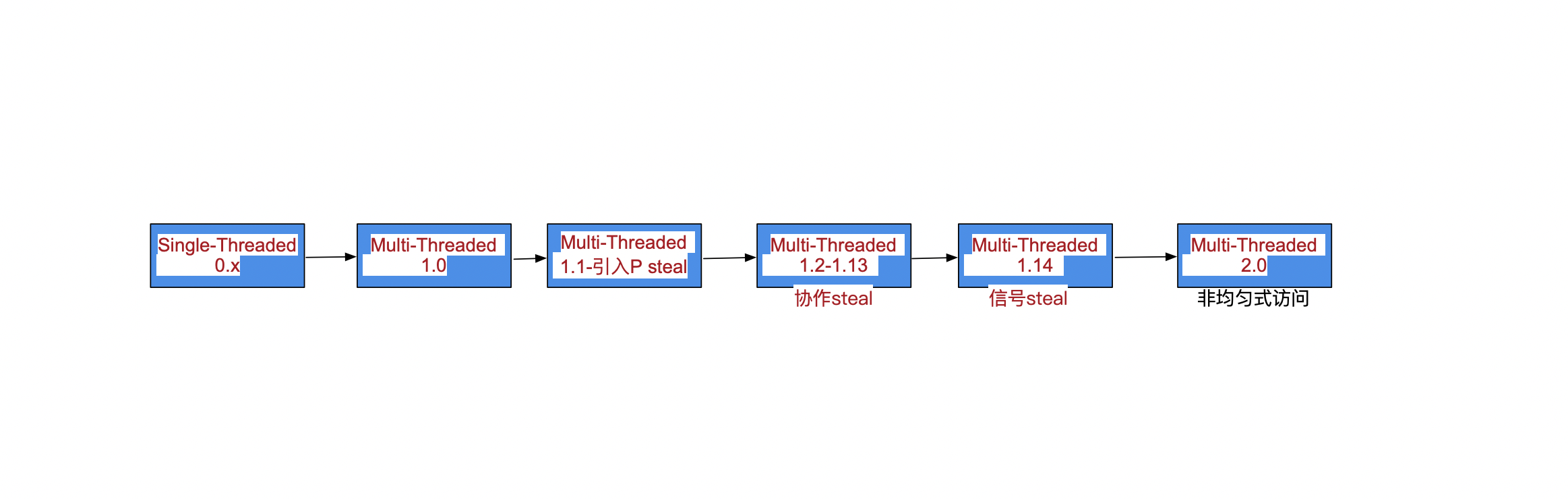
前生今世gmp
gmp的历史
- 单线程调度器 · 0.x
- 只包含 40 多行代码;
- 程序中只能存在一个活跃线程,由 G-M 模型组成;
- 多线程调度器 · 1.0
- 允许运行多线程的程序;
- 全局锁导致竞争严重;
- 任务窃取调度器 · 1.1
- 引入了处理器 P,构成了目前的 G-M-P 模型;
- 在处理器 P 的基础上实现了基于工作窃取的调度器;
- 在某些情况下,Goroutine 不会让出线程,进而造成饥饿问题;
- 时间过长的垃圾回收(Stop-the-world,STW)会导致程序长时间无法工作;
- 抢占式调度器 · 1.2 ~ 至今
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前 Goroutine 是否发起了抢占请求,实现基于协作的抢占式调度;
- Goroutine 可能会因为垃圾回收和循环长时间占用资源导致程序暂停;
- 基于信号的抢占式调度器 - 1.14 ~ 至今
- 实现基于信号的真抢占式调度;
- 垃圾回收在扫描栈时会触发抢占调度;
- 抢占的时间点不够多,还不能覆盖全部的边缘情况;
- 基于协作的抢占式调度器 - 1.2 ~ 1.13
- 非均匀存储访问调度器 · 提案
- 对运行时的各种资源进行分区;
- 实现非常复杂,到今天还没有提上日程;
go1.13版本之前的一个bug
func main() {var x intthreads := runtime.GOMAXPROCS(0)for i := 0; i < threads; i++ {go func() {for { x++ }}()}time.Sleep(time.Second)fmt.Println("x =", x)}
GMP 模型
G
type g struct {// Stack parameters.// stack describes the actual stack memory: [stack.lo, stack.hi).// stackguard0 is the stack pointer compared in the Go stack growth prologue.// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.// stackguard1 is the stack pointer compared in the C stack growth prologue.// It is stack.lo+StackGuard on g0 and gsignal stacks.// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).// ==> 堆栈参数。stack 描述了实际的堆栈内存:[stack.lo, stack.hi).stackguard0 是 Go 堆栈增长序言中比较的堆栈指针。//正常情况下是stack.lo+StackGuard,但也可以是StackPreempt来触发抢占。// stackguard1 是在 C 堆栈增长序言中比较的堆栈指针。在 g0 和 gsignal 堆栈上是 stack.lo+StackGuard。它在其他 goroutine 堆栈上为 ~0,以触发对 morestackc 的调用(并崩溃)。stack stack // offset known to runtime/cgo ==> goroutine 使用的栈stackguard0 uintptr // offset known to liblinkstackguard1 uintptr // offset known to liblink_panic *_panic // innermost panic - offset known to liblink_defer *_defer // innermost deferm *m // current m; offset known to arm liblink// goroutine 的运行现场sched gobufsyscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc ==> if status==Gsyscall, syscallsp = sched.sp 在 gc 期间使用syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc ==> if status==Gsyscall, syscallpc = sched.pc 在 gc 期间使用stktopsp uintptr // expected sp at top of stack, to check in traceback ==> 堆栈顶部的预期 sp,以检查回溯param unsafe.Pointer // passed parameter on wakeup ==> 唤醒时传递参数atomicstatus uint32stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatusgoid int64schedlink guintptrwaitsince int64 // approx time when the g become blocked ==> g 被阻塞的大约时间waitreason waitReason // if status==Gwaiting// 抢占调度标志。这个为 true 时,stackguard0 等于 stackpreemptpreempt bool // preemption signal, duplicates stackguard0 = stackpreempt ==> 抢占信号,复制 stackguard0 = stackpreemptpreemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule ==> 抢占时过渡到_Gpreempted;否则,只需取消计划preemptShrink bool // shrink stack at synchronous safe point ==> 在同步安全点收缩堆栈// asyncSafePoint is set if g is stopped at an asynchronous// safe point. This means there are frames on the stack// without precise pointer information. ==> 如果 g 在异步安全点停止,则设置 asyncSafePoint。 这意味着堆栈中存在没有精确指针信息的帧。asyncSafePoint boolpaniconfault bool // panic (instead of crash) on unexpected fault addressgcscandone bool // g has scanned stack; protected by _Gscan bit in statusthrowsplit bool // must not split stack// activeStackChans indicates that there are unlocked channels// pointing into this goroutine's stack. If true, stack// copying needs to acquire channel locks to protect these// areas of the stack. ===> activeStackChans 表示有指向此 goroutine 堆栈的未锁定通道。 如果为 true,堆栈复制需要获取通道锁以保护堆栈的这些区域。activeStackChans bool// parkingOnChan indicates that the goroutine is about to// park on a chansend or chanrecv. Used to signal an unsafe point// for stack shrinking. It's a boolean value, but is updated atomically.parkingOnChan uint8raceignore int8 // ignore race detection eventssysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutinesysexitticks int64 // cputicks when syscall has returned (for tracing)traceseq uint64 // trace event sequencertracelastp puintptr // last P emitted an event for this goroutine// 如果调用了 LockOsThread,那么这个 g 会绑定到某个 m 上lockedm muintptrsig uint32writebuf []bytesigcode0 uintptrsigcode1 uintptrsigpc uintptrgopc uintptr // pc of go statement that created this goroutine ===> 创建该 goroutine 的语句的指令地址ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)// goroutine 函数的指令地址startpc uintptr // pc of goroutine functionracectx uintptrwaiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock ordercgoCtxt []uintptr // cgo traceback contextlabels unsafe.Pointer // profiler labels// time.Sleep 缓存的定时器timer *timer // cached timer for time.SleepselectDone uint32 // are we participating in a select and did someone win the race?// Per-G GC state// gcAssistBytes is this G's GC assist credit in terms of// bytes allocated. If this is positive, then the G has credit// to allocate gcAssistBytes bytes without assisting. If this// is negative, then the G must correct this by performing// scan work. We track this in bytes to make it fast to update// and check for debt in the malloc hot path. The assist ratio// determines how this corresponds to scan work debt.gcAssistBytes int64}
G结构体下嵌套了两个重要的结构体
stack stack 表示 goroutine 运行时的栈
// Stack describes a Go execution stack.// The bounds of the stack are exactly [lo, hi),// with no implicit data structures on either side.\// ==> Stack 描述了一个 Go 执行栈。栈的边界正好是 [lo, hi),两边都没有隐含的数据结构。type stack struct {lo uintptr ==> // 栈顶,低地址hi uintptr ==> 栈低,高地址}
gobuf
Goroutine 运行时,光有栈还不行,至少还得包括 PC,SP 等寄存器,gobuf 就保存了这些值:
type gobuf struct {// The offsets of sp, pc, and g are known to (hard-coded in) libmach.//// ctxt is unusual with respect to GC: it may be a// heap-allocated funcval, so GC needs to track it, but it// needs to be set and cleared from assembly, where it's// difficult to have write barriers. However, ctxt is really a// saved, live register, and we only ever exchange it between// the real register and the gobuf. Hence, we treat it as a// root during stack scanning, which means assembly that saves// and restores it doesn't need write barriers. It's still// typed as a pointer so that any other writes from Go get// write barriers.sp uintptrpc uintptrg guintptrctxt unsafe.Pointerret sys.Uintreglr uintptrbp uintptr // for GOEXPERIMENT=framepointer}
M
当 M 没有工作可做的时候,在它休眠前,会“自旋”地来找工作:检查全局队列,查看 network poller,试图执行 gc 任务,或者“偷”工作。
type m struct {g0 *g // goroutine with scheduling stack ==>带有调度堆栈的 goroutinemorebuf gobuf // gobuf arg to morestack ==>gobuf arg 到 morestackdivmod uint32 // div/mod denominator for arm - known to liblink ==>arm 的 div/mod 分母 - liblink 已知// Fields not known to debuggers. ==>调试器不知道的字段。procid uint64 // for debuggers, but offset not hard-coded ==>用于调试器,但偏移量不是硬编码的gsignal *g // signal-handling g ==>信号处理ggoSigStack gsignalStack // Go-allocated signal handling stack ==>Go 分配的信号处理堆栈sigmask sigset // storage for saved signal mask ==>存储已保存的信号掩码tls [6]uintptr // thread-local storage (for x86 extern register) ==>线程本地存储(用于 x86 外部寄存器)mstartfn func()curg *g // current running goroutine ==>当前运行的 goroutinecaughtsig guintptr // goroutine running during fatal signal ==>goroutine 在致命信号期间运行p puintptr // attached p for executing go code (nil if not executing go code) ==>附加 p 用于执行 go 代码(如果不执行 go 代码,则为零)nextp puintptroldp puintptr // the p that was attached before executing a syscall ==> 在执行系统调用之前附加的 pid int64mallocing int32throwing int32preemptoff string // if != "", keep curg running on this m ==> 如果 != "", 继续在这个 m 上运行 curglocks int32dying int32profilehz int32spinning bool // m is out of work and is actively looking for work ==> m 失业了,正在积极找工作blocked bool // m is blocked on a note ==> m 在笔记上被屏蔽newSigstack bool // minit on C thread called sigaltstack ==> C 线程上的 minit 称为 sigaltstackprintlock int8incgo bool // m is executing a cgo call ==> m 正在执行一个 cgo 调用freeWait uint32 // if == 0, safe to free g0 and delete m (atomic) ==>if == 0,可以安全地释放 g0 并删除 m(原子)fastrand [2]uint32needextram booltraceback uint8ncgocall uint64 // number of cgo calls in total ==> cgo 调用总数ncgo int32 // number of cgo calls currently in progress ==>当前正在进行的 cgo 调用数cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily ==>如果非零,则暂时使用 cgoCallerscgoCallers *cgoCallers // cgo traceback if crashing in cgo call ==>如果在 cgo 调用中崩溃,则 cgo 回溯park notealllink *m // on allmschedlink muintptrmcache *mcachelockedg guintptrcreatestack [32]uintptr // stack that created this thread. ==> 创建此线程的堆栈。lockedExt uint32 // tracking for external LockOSThread ==> 跟踪外部 LockOSThreadlockedInt uint32 // tracking for internal lockOSThread ==> 跟踪内部 lockOSThreadnextwaitm muintptr // next m waiting for lock ==> 下一个等待锁定waitunlockf func(*g, unsafe.Pointer) boolwaitlock unsafe.Pointerwaittraceev bytewaittraceskip intstartingtrace boolsyscalltick uint32freelink *m // on sched.freem ==> 在 sched.freem 上// these are here because they are too large to be on the stack// of low-level NOSPLIT functions. ==> mFixup 用于同步 OS 相关的 m 状态(凭据等)使用互斥量访问。libcall libcalllibcallpc uintptr // for cpu profiler ==> 用于 CPU 分析器libcallsp uintptrlibcallg guintptrsyscall libcall // stores syscall parameters on windows ==> 在 Windows 上存储系统调用参数vdsoSP uintptr // SP for traceback while in VDSO call (0 if not in call) ==> 在 VDSO 调用中用于回溯的 SP(如果不在调用中,则为 0)vdsoPC uintptr // PC for traceback while in VDSO call ==> 在 VDSO 调用中用于回溯的 PC// preemptGen counts the number of completed preemption// signals. This is used to detect when a preemption is// requested, but fails. Accessed atomically.// ===> preemptGen 统计完成抢占的次数 信号。这用于检测何时发生抢占请求,但失败。以原子方式访问。preemptGen uint32// Whether this is a pending preemption signal on this M.// Accessed atomically. ===>这是否是此 M 上的未决抢占信号。原子访问。signalPending uint32dlogPerMmOS}
P
为 M 的执行提供“上下文”,保存 M 执行 G 时的一些资源,例如本地可运行 G 队列,memeory cache 等。
一个 M 只有绑定 P 才能执行 goroutine,当 M 被阻塞时,整个 P 会被传递给其他 M ,或者说整个 P 被接管。
type p struct {id int32status uint32 // one of pidle/prunning/...link puintptrschedtick uint32 // incremented on every scheduler call ==>在每次调度程序调用时递增syscalltick uint32 // incremented on every system call ==>在每次系统调用时递增sysmontick sysmontick // last tick observed by sysmon ==>sysmon 观察到的最后一个滴答声m muintptr // back-link to associated m (nil if idle) ==>反向链接到关联的 m(如果空闲则为零)mcache *mcachepcache pageCacheraceprocctx uintptrdeferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go) ==>不同大小的可用延迟结构池(参见 panic.go)deferpoolbuf [5][32]*_defer// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. ==>goroutine id 的缓存,分摊对 runtime·sched.goidgen 的访问。goidcache uint64goidcacheend uint64// Queue of runnable goroutines. Accessed without lock. ==>可运行的 goroutine 队列。无锁访问。runqhead uint32runqtail uint32runq [256]guintptr// runnext, if non-nil, is a runnable G that was ready'd by// the current G and should be run next instead of what's in// runq if there's time remaining in the running G's time// slice. It will inherit the time left in the current time// slice. If a set of goroutines is locked in a// communicate-and-wait pattern, this schedules that set as a// unit and eliminates the (potentially large) scheduling// latency that otherwise arises from adding the ready'd// goroutines to the end of the run queue.// runnext,如果非零,是一个可运行的 G,它已由当前 G 准备好,如果在运行 G 的时间片中有剩余时间,则应该运行下一个而不是 runq 中的内容。//它将继承当前时间片中剩余的时间。 如果一组 goroutine 被锁定在一个通信和等待模式,这种调度设置为一个单元,并消除了(可能很大)调度延迟,//否则由于将准备好的 goroutine 添加到运行队列的末尾而产生的调度延迟。runnext guintptr// Available G's (status == Gdead) ==> 可用 G(状态 == Gdead)gFree struct {gListn int32}sudogcache []*sudogsudogbuf [128]*sudog// Cache of mspan objects from the heap. ==>从堆缓存 mspan 对象。mspancache struct {// We need an explicit length here because this field is used// in allocation codepaths where write barriers are not allowed,// and eliminating the write barrier/keeping it eliminated from// slice updates is tricky, moreso than just managing the length// ourselves. ==> 我们在这里需要一个明确的长度,因为这个字段用于不允许写屏障的分配代码路径中,并且消除写屏障/保持它从切片更新中消除是棘手的,不仅仅是我们自己管理长度。len intbuf [128]*mspan}tracebuf traceBufPtr// traceSweep indicates the sweep events should be traced.// This is used to defer the sweep start event until a span// has actually been swept. ==> traceSweep 指示应该跟踪扫描事件。这用于推迟扫描开始事件,直到实际扫描了跨度。traceSweep bool// traceSwept and traceReclaimed track the number of bytes// swept and reclaimed by sweeping in the current sweep loop. ==> traceSwept 和 traceReclaimed 跟踪在当前扫描循环中通过扫描扫描和回收的字节数。traceSwept, traceReclaimed uintptrpalloc persistentAlloc // per-P to avoid mutex ==> per-P 避免互斥_ uint32 // Alignment for atomic fields below ==> 下面的原子场对齐// The when field of the first entry on the timer heap.// This is updated using atomic functions.// This is 0 if the timer heap is empty. ==> 定时器堆上第一个条目的 when 字段。这是使用原子函数更新的。 如果计时器堆为空,则为 0。timer0When uint64// Per-P GC stategcAssistTime int64 // Nanoseconds in assistAllocgcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)gcBgMarkWorker guintptr // (atomic)gcMarkWorkerMode gcMarkWorkerMode// gcMarkWorkerStartTime is the nanotime() at which this mark// worker started.gcMarkWorkerStartTime int64// gcw is this P's GC work buffer cache. The work buffer is// filled by write barriers, drained by mutator assists, and// disposed on certain GC state transitions.//==> gcw 是这个 P 的 GC 工作缓冲区缓存。工作缓冲区是由写屏障填充,由增变器辅助耗尽,以及处理某些 GC 状态转换。gcw gcWork// wbBuf is this P's GC write barrier buffer.//// TODO: Consider caching this in the running G.wbBuf wbBufrunSafePointFn uint32 // if 1, run sched.safePointFn at next safe point// Lock for timers. We normally access the timers while running// on this P, but the scheduler can also do it from a different P.//锁定计时器。我们通常在运行时访问计时器在这个 P 上,但调度器也可以从不同的 P 上做。timersLock mutex// Actions to take at some time. This is used to implement the// standard library's time package.// Must hold timersLock to access.// ==> 在某个时间采取的行动。 这是用来实现标准库的时间包的。必须持有timersLock才能访问。timers []*timer// Number of timers in P's heap.// Modified using atomic instructions.numTimers uint32// Number of timerModifiedEarlier timers on P's heap.// This should only be modified while holding timersLock,// or while the timer status is in a transient state// such as timerModifying.//==> P 堆上的 timerModifiedEarlier 定时器的数量。这应该只在持有 timersLock 时修改,或者当定时器状态处于诸如 timerModifying 的瞬态状态时。adjustTimers uint32// Number of timerDeleted timers in P's heap.// Modified using atomic instructions.//==> P 堆中 timerDeleted 定时器的数量。 使用原子指令修改。deletedTimers uint32// Race context used while executing timer functions. ==>执行计时器功能时使用的竞态上下文。timerRaceCtx uintptr// preempt is set to indicate that this P should be enter the// scheduler ASAP (regardless of what G is running on it).//==>preempt 设置为指示该 P 应尽快进入调度程序(无论 G 在其上运行什么)。preempt boolpad cpu.CacheLinePad}
保存调度器的状态信息、全局的可运行 G 队列等.
schedt 对象只有一份实体,它维护了调度器的所有信息
type schedt struct {// accessed atomically. keep at top to ensure alignment on 32-bit systems.goidgen uint64lastpoll uint64 // time of last network poll, 0 if currently pollingpollUntil uint64 // time to which current poll is sleepinglock mutex// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be// sure to call checkdead().midle muintptr // idle m's waiting for work ==> 由空闲的工作线程组成的链表nmidle int32 // number of idle m's waiting for work ==>空闲的工作线程数量nmidlelocked int32 // number of locked m's waiting for work ==> 空闲的且被 lock 的 m 计数mnext int64 // number of m's that have been created and next M IDmaxmcount int32 // maximum number of m's allowed (or die) ==> 表示最多所能创建的工作线程数量nmsys int32 // number of system m's not counted for deadlocknmfreed int64 // cumulative number of freed m'sngsys uint32 // number of system goroutines; updated atomically ==> goroutine 的数量,自动更新pidle puintptr // idle p's ==> 由空闲的 p 结构体对象组成的链表npidle uint32 // ==> 空闲的 p 结构体对象的数量nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.// Global runnable queue. ==>全局可运行的 G队列runq gQueuerunqsize int32 // ==> // 元素数量// disable controls selective disabling of the scheduler.//// Use schedEnableUser to control this.//// disable is protected by sched.lock.disable struct {// user disables scheduling of user goroutines.user boolrunnable gQueue // pending runnable Gsn int32 // length of runnable}// Global cache of dead G's.gFree struct {lock mutexstack gList // Gs with stacksnoStack gList // Gs without stacksn int32}// Central cache of sudog structs. ==>/ sudog 结构的集中缓存sudoglock mutexsudogcache *sudog// Central pool of available defer structs of different sizes.deferlock mutex // ==>不同大小的可用的 defer struct 的集中缓存池deferpool [5]*_defer// freem is the list of m's waiting to be freed when their// m.exited is set. Linked through m.freelink.freem *mgcwaiting uint32 // gc is waiting to runstopwait int32stopnote notesysmonwait uint32sysmonnote note// safepointFn should be called on each P at the next GC// safepoint if p.runSafePointFn is set.safePointFn func(*p)safePointWait int32safePointNote noteprofilehz int32 // cpu profiling rateprocresizetime int64 // nanotime() of last change to gomaxprocs ==> 上次修改 gomaxprocs 的纳秒时间totaltime int64 // ∫gomaxprocs dt up to procresizetime}
线程的几种状态
就绪 、 等待、 运行 ===> goroutine 不管再怎么运行,状态归类也会这么几类
| 状态 | 解释 |
|---|---|
| Waiting | 等待状态。线程在等待某件事的发生。例如等待网络数据、硬盘;调用操作系统 API;等待内存同步访问条件 ready,如 atomic, mutexes |
| Runnable | 就绪状态。只要给 CPU 资源我就能运行 |
| Executing | 运行状态。线程在执行指令,这是我们想要的 |
goroutine几种状态
- 等待中:Goroutine 正在等待某些条件满足,例如:系统调用结束等,包括 _Gwaiting、_Gsyscall 和 _Gpreempted 几个状态;
- 可运行:Goroutine 已经准备就绪,可以在线程运行,如果当前程序中有非常多的 Goroutine,每个 Goroutine 就可能会等待更多的时间,即 _Grunnable;
- 运行中:Goroutine 正在某个线程上运行,即 _Grunning;
goroutine和thread的区别
| 区分项 | thread | go |
|---|---|---|
| 内存空间 | 1M | 2KB |
| 耗费时间 | 线程切换会消耗 1000-1500 纳秒 | 200ns |
| 切换所需寄存器 | 16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc. | Program Counter, Stack Pointer and BP |
go的关键词整理
g0 :Go 必须在每个正在运行的线程上调度和管理 goroutine。这个角色被委托给一个特殊的 goroutine,称为 g0,它是为每个 OS 线程创建的第一个 goroutine
https://medium.com/a-journey-with-go/go-g0-special-goroutine-8c778c6704d8
go schedule 整体流程
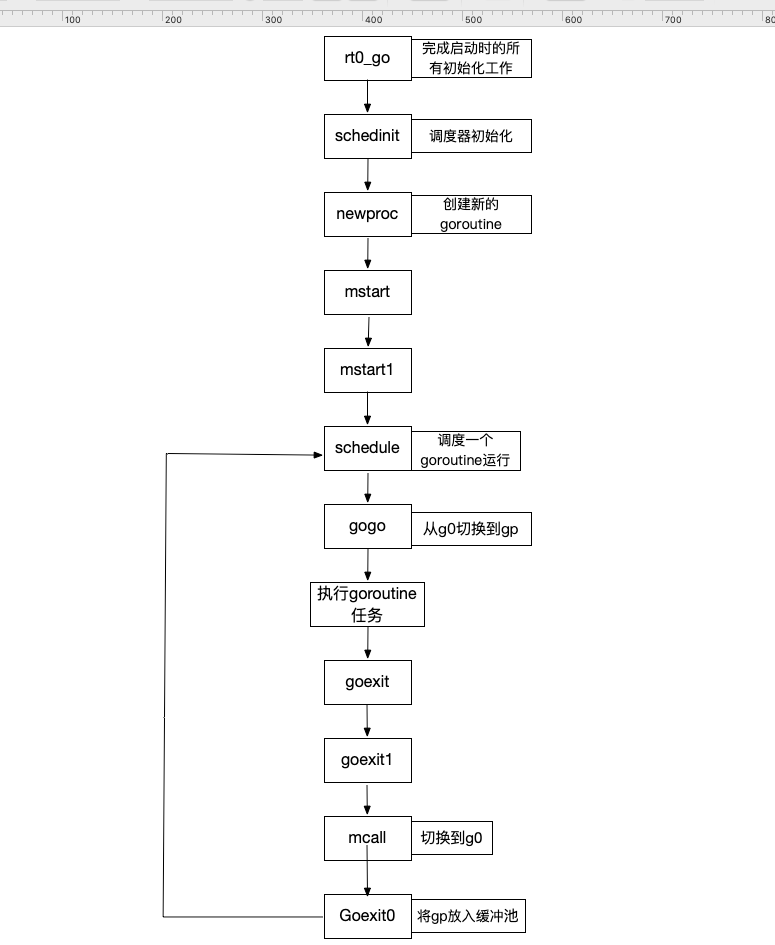
go 调度过程中的函数讲解
Go 程序的入口地址在 linux 上运行的,入口文件为 src/runtime/rt0_linux_amd64.s -_rt0_amd64_linux ==>/usr/local/go/src/runtime/asm_amd64.s -_rt0_amd64->TEXT runtime·rt0_go(SB),NOSPLIT,$0
TEXT runtime·rt0_go(SB),NOSPLIT,$0 ===>调度器运行始末
TEXT runtime·rt0_go(SB),NOSPLIT,$0// copy arguments forward on an even stackMOVQ DI, AX // argcMOVQ SI, BX // argvSUBQ $(4*8+7), SP // 2args 2autoANDQ $~15, SPMOVQ AX, 16(SP) //==> argc 放在 SP+16 字节处MOVQ BX, 24(SP) //==> argv 放在 SP+24 字节处// create istack out of the given (operating system) stack.// _cgo_init may update stackguard.MOVQ $runtime·g0(SB), DI //===> 把 g0 的地址存入 DILEAQ (-64*1024+104)(SP), BXMOVQ BX, g_stackguard0(DI)MOVQ BX, g_stackguard1(DI)MOVQ BX, (g_stack+stack_lo)(DI)MOVQ SP, (g_stack+stack_hi)(DI)// find out information about the processor we're onMOVL $0, AXCPUIDMOVL AX, SICMPL AX, $0JE nocpuinfo// Figure out how to serialize RDTSC.// On Intel processors LFENCE is enough. AMD requires MFENCE.// Don't know about the rest, so let's do MFENCE.CMPL BX, $0x756E6547 // "Genu"JNE notintelCMPL DX, $0x49656E69 // "ineI"JNE notintelCMPL CX, $0x6C65746E // "ntel"JNE notintelMOVB $1, runtime·isIntel(SB)MOVB $1, runtime·lfenceBeforeRdtsc(SB)notintel:// Load EAX=1 cpuid flagsMOVL $1, AXCPUIDMOVL AX, runtime·processorVersionInfo(SB)nocpuinfo:// if there is an _cgo_init, call it.MOVQ _cgo_init(SB), AXTESTQ AX, AXJZ needtls// arg 1: g0, already in DIMOVQ $setg_gcc<>(SB), SI // arg 2: setg_gcc#ifdef GOOS_androidMOVQ $runtime·tls_g(SB), DX // arg 3: &tls_g// arg 4: TLS base, stored in slot 0 (Android's TLS_SLOT_SELF).// Compensate for tls_g (+16).MOVQ -16(TLS), CX#elseMOVQ $0, DX // arg 3, 4: not used when using platform's TLSMOVQ $0, CX#endif#ifdef GOOS_windows// Adjust for the Win64 calling convention.MOVQ CX, R9 // arg 4MOVQ DX, R8 // arg 3MOVQ SI, DX // arg 2MOVQ DI, CX // arg 1#endifCALL AX// update stackguard after _cgo_initMOVQ $runtime·g0(SB), CXMOVQ (g_stack+stack_lo)(CX), AXADDQ $const__StackGuard, AXMOVQ AX, g_stackguard0(CX)MOVQ AX, g_stackguard1(CX)#ifndef GOOS_windowsJMP ok#endifneedtls:#ifdef GOOS_plan9// skip TLS setup on Plan 9JMP ok#endif#ifdef GOOS_solaris// skip TLS setup on SolarisJMP ok#endif#ifdef GOOS_illumos// skip TLS setup on illumosJMP ok#endif#ifdef GOOS_darwin// skip TLS setup on DarwinJMP ok#endif//=====> runtime 会启动多个工作线程,每个线程都会绑定一个 m0 初始化m0//=====> TLS 就是线程本地的私有的全局变量LEAQ runtime·m0+m_tls(SB), DICALL runtime·settls(SB)// store through it, to make sure it worksget_tls(BX) //===> 获取 fs 段基址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成MOVQ $0x123, g(BX)MOVQ runtime·m0+m_tls(SB), AXCMPQ AX, $0x123JEQ 2(PC)CALL runtime·abort(SB)ok:// set the per-goroutine and per-mach "registers"get_tls(BX) //====> 获取 fs 段基址到 BX 寄存器LEAQ runtime·g0(SB), CX //====> 将 g0 的地址存储到 CX,CX = &g0MOVQ CX, g(BX) //====> 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0LEAQ runtime·m0(SB), AX //====> 将 m0 的地址存储到 AX,AX = &m0// save m->g0 = g0MOVQ CX, m_g0(AX)// save m0 to g0->mMOVQ AX, g_m(CX)CLD // convention is D is always left clearedCALL runtime·check(SB)MOVL 16(SP), AX // copy argcMOVL AX, 0(SP)MOVQ 24(SP), AX // copy argvMOVQ AX, 8(SP)CALL runtime·args(SB)CALL runtime·osinit(SB) //====> 初始化系统核心数CALL runtime·schedinit(SB) //====> 调度器初始化// create a new goroutine to start programMOVQ $runtime·mainPC(SB), AX // entryPUSHQ AX //====> newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数PUSHQ $0 // arg size //====> newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小, 因为 runtime.main 没有参数,所以这里是 0//====> // 创建 main goroutineCALL runtime·newproc(SB)POPQ AXPOPQ AX// start this M ====>主线程进入调度循环,运行刚刚创建的 goroutineCALL runtime·mstart(SB)CALL runtime·abort(SB) // mstart should never returnRET// Prevent dead-code elimination of debugCallV1, which is// intended to be called by debuggers. //====> 永远不会返回,万一返回了,crash 掉MOVQ $runtime·debugCallV1(SB), AXRET
go调度的时机
- 主动挂起 — runtime.gopark -> runtime.park_m
- 系统调用 — runtime.exitsyscall -> runtime.exitsyscall0
- 协作式调度 — runtime.Gosched -> runtime.gosched_m -> runtime.goschedImpl
- 系统监控 — runtime.sysmon -> runtime.retake -> runtime.preemptone
reference
用 GODEBUG 看调度跟踪 https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/99785562
go -scheduler 剖析
上手小知识
线程切换
函数调用过程分析
CALL 指令类似 PUSH IP 和 JMP somefunc 两个指令的组合,首先将当前的 IP 指令寄存器的值压入栈中,然后通过 JMP 指令将要调用函数的地址写入到 IP 寄存器实现跳转。
而 RET 指令则是和 CALL 相反的操作,基本和 POP IP 指令等价,也就是将执行 CALL 指令时保存在 SP 中的返回地址重新载入到 IP 寄存器,实现函数的返回。
goroutine
什么是goroutine
goroutine 是thread的一层抽象,更加轻量级,可以单独执行。线程是调度的基本单位。
goroutine 和 thread的区别
参考资料【How Goroutines Work】https://blog.nindalf.com/posts/how-goroutines-work/)从三个角度进行区别: 内存消耗、 创建和销毁、 切换
内存消耗
创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。
创建和销毁
Thread 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池。而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。
切换
当 threads 切换时,需要保存各种寄存器,以便将来恢复:
16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc.
而 goroutines 切换只需保存三个寄存器:Program Counter, Stack Pointer and BP。
一般而言,线程切换会消耗 1000-1500 纳秒,一个纳秒平均可以执行 12-18 条指令。所以由于线程切换,执行指令的条数会减少 12000-18000。
Goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。
因此,goroutines 切换成本比 threads 要小得多。
| 对比项 | 线程(thread) | 协程(goroutine) |
|---|---|---|
| 内存消耗 | 1M | 2KB |
| 创建和销毁 | 内核级-使用线程池解决 | 用户级 |
| 切换 | 16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc. 16个通用寄存器、PC(程序计数器)、SP(堆栈指针)、段寄存器、16个XMM寄存器、FP协处理器状态、16个AVX寄存器、所有MSR等 |
切换消耗 1000-1500纳秒, 一纳秒平均执行
12-18条指令。线程切换执行指令为 121000-181000 | Program Counter, Stack Pointer and BP
goroutine 切换为200ns。 goroutine执行指令为 20012-20018 |
在同一时刻,一个线程上只能跑一个 goroutine。
go-scheduler
go程序执行由两层组成:GO Program,Runtime.及用户程序和运行时。 通过函数调用来实现内存管理、channel通信、goroutines创建等功能。
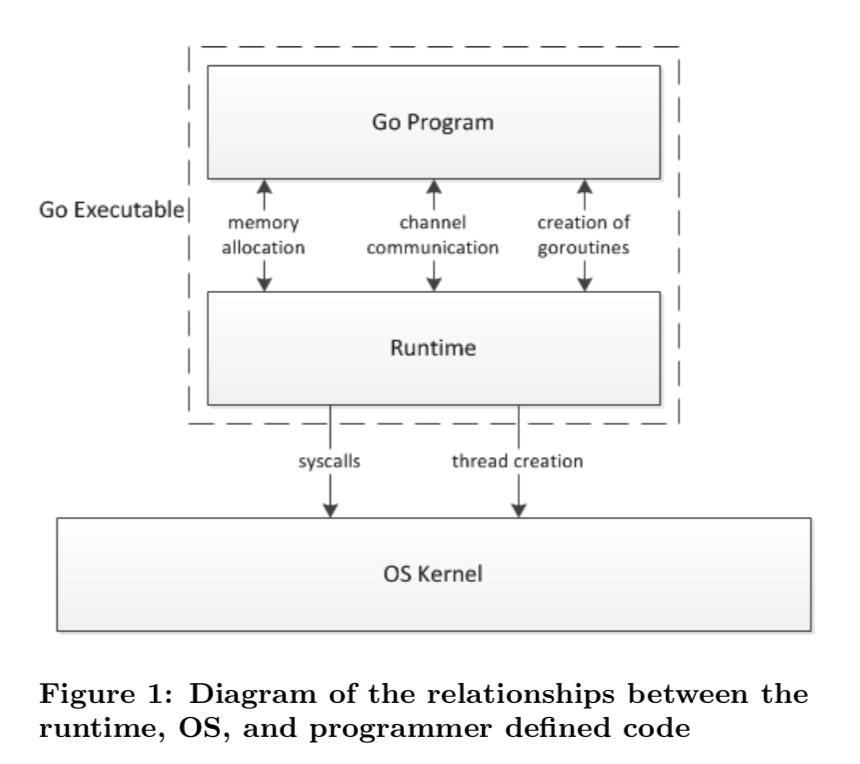
为什么要scheduler
runtime维护所有的goroutines,通过scheduler进行调度。 goroutines和thread是独立的。但是goroutine要依赖threads才能执行。
scheduler 底层原理
通过G、M、P 结构体来实现goroutine的调度。
g 代表一个 goroutine,它包含:表示 goroutine 栈的一些字段,指示当前 goroutine 的状态,指示当前运行到的指令地址,也就是 PC 值。
m 表示内核线程,包含正在运行的 goroutine 等字段。
p 代表一个虚拟的 Processor,它维护一个处于 Runnable 状态的 g 队列, m 需要获得 p 才能运行 g。
还有一个核心的结构体 sched。用来进行调度。
Runtime 起始时会启动一些 G:垃圾回收的 G,执行调度的 G,运行用户代码的 G;并且会创建一个 M 用来开始 G 的运行。随着时间的推移,更多的 G 会被创建出来,更多的 M 也会被创建出来。
Go scheduler 的核心思想是:
- reuse threads;
- 限制同时运行(不包含阻塞)的线程数为 N,N 等于 CPU 的核心数目;
- 线程私有的 runqueues,并且可以从其他线程 stealing goroutine 来运行,线程阻塞后,可以将 runqueues 传递给其他线程。
为什么要引入P
您现在可能想知道,为什么要有上下文?我们不能把运行队列放在线程上并摆脱上下文吗?并不真地。我们拥有上下文的原因是,如果正在运行的线程由于某种原因需要阻塞,我们可以将它们(P)交给其他线程。
我们需要阻塞的一个例子是当我们调用系统调用时。由于线程不能同时执行代码并在系统调用上被阻塞,我们需要交出上下文以便它可以继续调度。
当一个线程阻塞的时候,将和它绑定的 P 上的 goroutines 转移到其他线程。
Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 global runqueues。这是一个全局的 runqueue,优先级比较低,以示惩罚。
go scheduler调度的顺序
runtime.schedule() {// only 1/61 of the time, check the global runnable queue for a G.// if not found, check the local queue.// if not found,// try to steal from other Ps.// if not, check the global runnable queue.// if not found, poll network.}runtime.schedule() {// 只有 1/61 的时间,检查全局可运行队列中的 G。// 如果没有找到,检查本地队列。// 如果没有找到,// 尝试从其他 Ps 中窃取。// 如果没有,检查全局可运行队列。// 如果没有找到,轮询网络。}
汇编流程细节
TEXT runtime·rt0_go(SB),NOSPLIT,$0......主线程绑定m0LEAQ runtime·m0+m_tls(SB), DICALL runtime·settls(SB)// store through it, to make sure it worksget_tls(BX)MOVQ $0x123, g(BX)MOVQ runtime·m0+m_tls(SB), AXCMPQ AX, $0x123JEQ 2(PC)CALL runtime·abort(SB)
m0 是全局变量,而 m0 又要绑定到工作线程才能执行。runtime 会启动多个工作线程,每个线程都会绑定一个 m0。
TLS 就是线程本地的私有的全局变量。
ok:// set the per-goroutine and per-mach "registers"get_tls(BX)LEAQ runtime·g0(SB), CXMOVQ CX, g(BX)LEAQ runtime·m0(SB), AX// save m->g0 = g0MOVQ CX, m_g0(AX)// save m0 to g0->mMOVQ AX, g_m(CX)
通过 m.tls[0] 可以找到 g0,通过 g0 可以找到 m0(通过 g 结构体的 m 字段)。并且,通过 m 的字段 g0,m0 也可以找到 g0。于是,主线程和 m0,g0 就关联起来了。
保存在主线程本地存储中的值是 g0 的地址,也就是说工作线程的私有全局变量其实是一个指向 g 的指针而不是指向 m 的指针。 目前这个指针指向g0,表示代码正运行在 g0 栈。
初始化m0
src/runtime/proc.go/schedinit()/mcommoninit()
初始化allp
allp是全局的p, 从schedinit()入口进入,然后初始化系统核数个的p,然后调用 procresize() 函数进行 P0和m0关联
procesize()函数中循环遍历所有的allp,将 将第一个p0和m0关联,其他的通过runqempty() 函数判断是否是空闲的P,然后通过放入全局空闲链表pidleput(p)
- 使用 make([]p, nprocs) 初始化全局变量 allp,即 allp = make([]p, nprocs)
- 循环创建并初始化 nprocs 个 p 结构体对象并依次保存在 allp 切片之中
- 把 m0 和 allp[0] 绑定在一起,即 m0.p = allp[0],allp[0].m = m0
- 把除了 allp[0] 之外的所有 p 放入到全局变量 sched 的 pidle 空闲队列之中
newproc() 函数 会创建一个新的g来跑fn。 newproc如果不是初始化构建,而是执行函数比如 go func(){}() 本质也是调用newproc函数,
获取当前工作线程的g0,然后通过g0找到绑定的p0, 然后从p上获取一个没有使用的g.
newproc函数传递两个函数,一个是新创建的 goroutine 需要执行的任务,也就是 fn,它代表一个函数 func;还有一个是 fn 的参数大小。
goroutine 的初始栈比较小,只有 2K。可伸缩性。
main goroutine
// 创建一个新的 goroutine 来启动程序MOVQ $runtime·mainPC(SB), AX // entry// newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数// AX = &funcval{runtime·main},PUSHQ AX// newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小,// 因为 runtime.main 没有参数,所以这里是 0PUSHQ $0 // arg size// 创建 main goroutineCALL runtime·newproc(SB)POPQ AXPOPQ AX// start this M// 主线程进入调度循环,运行刚刚创建的 goroutineCALL runtime·mstart(SB)// 永远不会返回,万一返回了,crash 掉MOVL $0xf1, 0xf1 // crashRET
代码前面几行是在为调用 newproc 函数构“造栈”,执行完 runtime·newproc(SB) 后,就会以一个新的 goroutine 来执行 mainPC 也就是 runtime.main()函数。runtime.main() 函数最终会执行到我们写的 main 函数
g0栈和用户栈如何完成切换
src/runtime/proc.go/newproc1()函数中的
// 把newg.sched结构体成员的所有成员设置为0memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))// 设置newg 的sched成员,调度器需要依靠这些字段才能把goroutine调度到CPU上运行newg.sched.sp = spnewg.stktopsp = sp// newg.sched.pc 表示当 newg 被调度起来运行时从这个地址开始执行指令newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same functionnewg.sched.g = guintptr(unsafe.Pointer(newg))gostartcallfn(&newg.sched, fn)newg.gopc = callerpcnewg.ancestors = saveAncestors(callergp)newg.startpc = fn.fnif _g_.m.curg != nil {newg.labels = _g_.m.curg.labels}...runqput(_p_, newg, true)...
执行完成之后
src/runtime/proc.go/newproc1()函数中的 runqput() 调用的作用详解如下
runqput() 函数详解
// 将 G 放入 p 的本地待运行队列
// runqput 尝试将 g 放到本地可执行队列里。
// 如果 next 为假,runqput 将 g 添加到可运行队列的尾部
// 如果 next 为真,runqput 将 g 添加到 p.runnext 字段
// 如果 run queue 满了,runnext 将 g 放到全局队列里—> runqputslow()函数放入到全局队列
// runnext 成员中的 goroutine 会被优先调度起来运行
runqputslow() 函数讲解
// 将 g 和 p 本地队列的一半 goroutine 放入全局队列。
// 因为要获取锁,所以会慢
runqputslow()函数中调用—> globrunqputbatch(batch[0], batch[n], int32(n+1))
P 的本地可运行队列的长度为 256,它是一个循环队列,因此最多只能放下 256 个 goroutine
go-scheduler开始调度
// start this M// 主线程进入调度循环,运行刚刚创建的 goroutineCALL runtime·mstart(SB)
msart()->mstart1()->schedule()
schedule()方法 : 进入调度循环。永不返回
schedule函数详解:
// 执行一轮调度器的工作:找到一个 runnable 的 goroutine,并且执行它// 永不返回func schedule() {// _g_ = 每个工作线程 m 对应的 g0,初始化时是 m0 的 g0_g_ := getg()// ……………………top:// ……………………var gp *gvar inheritTime bool// ……………………if gp == nil {// Check the global runnable queue once in a while to ensure fairness.// Otherwise two goroutines can completely occupy the local runqueue// by constantly respawning each other.// 为了公平,每调用 schedule 函数 61 次就要从全局可运行 goroutine 队列中获取if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {lock(&sched.lock)// 从全局队列最大获取 1 个 gorutinegp = globrunqget(_g_.m.p.ptr(), 1)unlock(&sched.lock)}}// 从 P 本地获取 G 任务if gp == nil {gp, inheritTime = runqget(_g_.m.p.ptr())if gp != nil && _g_.m.spinning {throw("schedule: spinning with local work")}}if gp == nil {// 从本地运行队列和全局运行队列都没有找到需要运行的 goroutine,// 调用 findrunnable 函数从其它工作线程的运行队列中偷取,如果偷不到,则当前工作线程进入睡眠// 直到获取到 runnable goroutine 之后 findrunnable 函数才会返回。gp, inheritTime = findrunnable() // blocks until work is available}// This thread is going to run a goroutine and is not spinning anymore,// so if it was marked as spinning we need to reset it now and potentially// start a new spinning M.if _g_.m.spinning {resetspinning()}if gp.lockedm != nil {// Hands off own p to the locked m,// then blocks waiting for a new p.startlockedm(gp)goto top}// 执行 goroutine 任务函数// 当前运行的是 runtime 的代码,函数调用栈使用的是 g0 的栈空间// 调用 execute 切换到 gp 的代码和栈空间去运行execute(gp, inheritTime)}
为了公平,调度器每调度 61 次的时候,都会尝试从全局队列里取出待运行的 goroutine 来运行,调用 globrunqget;
如果还没找到,调用 runqget,从 P 本地可运行队列先选出一个可运行的 goroutine;
如果还没找到,就要去其他 P 里面去偷一些 goroutine 来执行,调用 findrunnable 函数。
schedule()中的execute()函数中调用gogo函数
execute()函数将 gp 的状态改为 _Grunning,将 m 和 gp 相互关联起来。最后,调用 gogo 完成从 g0 到 gp 的切换,CPU 的执行权将从 g0 转让到 gp。 gogo 函数用汇编语言写成
原因如下:
gogo 函数也是通过汇编语言编写的,这里之所以需要使用汇编,是因为 goroutine 的调度涉及不同执行流之间的切换。
前面我们在讨论操作系统切换线程时已经看到过,执行流的切换从本质上来说就是 CPU 寄存器以及函数调用栈的切换,然而不管是 go 还是 c 这种高级语言都无法精确控制 CPU 寄存器,因而高级语言在这里也就无能为力了,只能依靠汇编指令来达成目的。
汇编gogo详解
// func gogo(buf *gobuf)// restore state from Gobuf; longjmpTEXT runtime·gogo(SB), NOSPLIT, $16-8MOVQ buf+0(FP), BX // gobufMOVQ gobuf_g(BX), DXMOVQ 0(DX), CX // make sure g != nilget_tls(CX)....
第一行,将 gp.sched.g 保存到 DX 寄存器;第二行,我们见得已经比较多了, get_tls 将 tls 保存到 CX 寄存器,再将 gp.sched.g 放到 tls[0] 处。这样,当下次再调用 get_tls 时,取出的就是 gp,而不再是 g0,这一行完成从 g0 栈切换到 gp。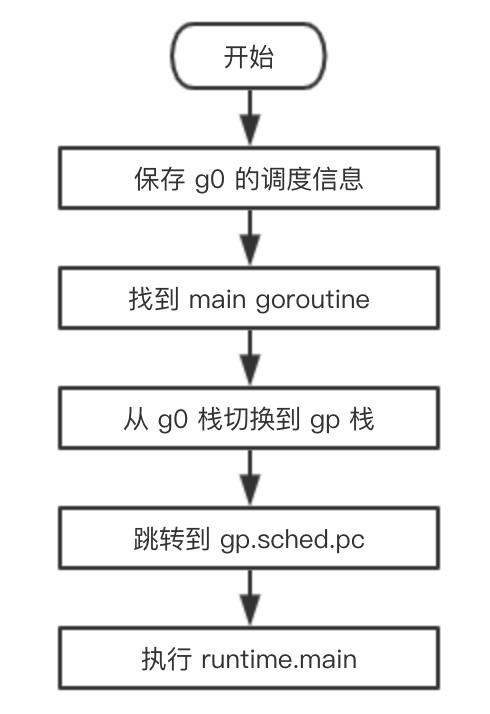
goroutine 从生到死
src/runtime/proc.go/main() 函数详解
// The main goroutine.func main() {// g = main goroutine,不再是 g0 了g := getg()...if GOARCH != "wasm" { // no threads on wasm yet, so no sysmonsystemstack(func() {// // 创建监控线程,该线程独立于调度器,不需要跟 p 关联即可运行newm(sysmon, nil)})}...// 调用 runtime 包的初始化函数,由编译器实现doInit(&runtime_inittask) // must be before deferif nanotime() == 0 {throw("nanotime returning zero")}// Defer unlock so that runtime.Goexit during init does the unlock too.needUnlock := truedefer func() {if needUnlock {unlockOSThread()}}()// Record when the world started.runtimeInitTime = nanotime()//// 开启垃圾回收器gcenable()main_init_done = make(chan bool)...// main 包的初始化,递归的调用我们 import 进来的包的初始化函数doInit(&main_inittask)close(main_init_done)// ……………………...// 调用 main.main 函数fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtimefn()if raceenabled {racefini()}// 进入系统调用,退出进程,可以看出 main goroutine 并未返回,而是直接进入系统调用退出进程了exit(0)// 保护性代码,如果 exit 意外返回,下面的代码会让该进程 crash 死掉for {var x *int32*x = 0}}
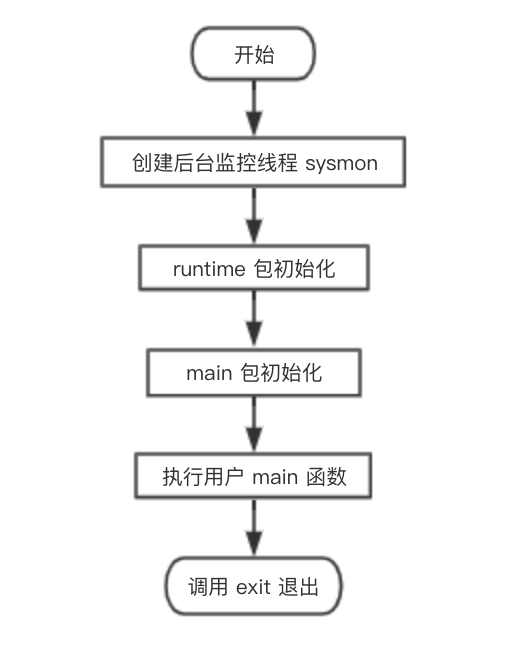
从流程图可知,main goroutine 执行完之后就直接调用 exit(0) 退出了,这会导致整个进程退出,太粗暴了。
不过,main goroutine 实际上就是代表用户的 main 函数,它都执行完了,肯定是用户的任务都执行完了,直接退出就可以了,就算有其他的 goroutine 没执行完,同样会直接退出。
主main.goroutine退出直接调用exit()退出了 。
如果是非main.goroutine退出则直接进行在 src/proc.go/newproc1()函数中调用汇编函数goexit(), 简称gp的退出。
汇编函数goexit()函数中调用src/proc.go/goexit1()函数,goexit1()函数中调用汇编函数mcall()函数。
mcall 函数里边调用goexit0()函数
goexit0函数详解
// goexit continuation on g0.//// 在 g0 上执行func goexit0(gp *g) {//// g0_g_ := getg()casgstatus(gp, _Grunning, _Gdead)if isSystemGoroutine(gp, false) {atomic.Xadd(&sched.ngsys, -1)}//// 清空 gp 的一些字段gp.m = nillocked := gp.lockedm != 0gp.lockedm = 0_g_.m.lockedg = 0gp.paniconfault = falsegp._defer = nil // should be true already but just in case.gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.gp.writebuf = nilgp.waitreason = 0gp.param = nilgp.labels = nilgp.timer = nil......// Note that gp's stack scan is now "valid" because it has no// stack.gp.gcscanvalid = true//// 解除 g 与 m 的关系dropg()if _g_.m.lockedInt != 0 {print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n")throw("internal lockOSThread error")}//// 将 g 放入 free 队列缓存起来gfput(_g_.m.p.ptr(), gp).......schedule()}
函数主要步骤解析
- 把 g 的状态从 _Grunning 更新为 _Gdead;
- 清空 g 的一些字段;
- 调用 dropg 函数解除 g 和 m 之间的关系,其实就是设置 g->m = nil, m->currg = nil;
- 把 g 放入 p 的 freeg 队列缓存起来供下次创建 g 时快速获取而不用从内存分配。freeg 就是 g 的一个对象池;
- 调用 schedule 函数再次进行调度。
gp完成之后放入到goroutine 缓存池,待下次任务重新启用。
而工作线程,又继续调用 schedule 函数进行新一轮的调度,整个过程形成了一个循环。
main goroutine 和普通 goroutine 的退出过程:
对于 main goroutine,在执行完用户定义的 main 函数的所有代码后,直接调用 exit(0) 退出整个进程,非常霸道。
对于普通 goroutine 则没这么“舒服”,需要经历一系列的过程。先是跳转到提前设置好的 goexit 函数的第二条指令,然后调用 runtime.goexit1,接着调用 mcall(goexit0),而 mcall 函数会切换到 g0 栈,运行 goexit0 函数,清理 goroutine 的一些字段,并将其添加到 goroutine 缓存池里,然后进入 schedule 调度循环。到这里,普通 goroutine 才算完成使命。
M如何找工作,如何窃取调度其他及全局的队列的goroutine
一从全局队列窃取
二从本地队列获取
三从其他地方找goroutine -其他P中窃取、从本地或全局队列中获取g、轮询网络
src/runtime/proc.go/findrunnable(()函数详解
func findrunnable() (gp *g, inheritTime bool) {_g_ := getg()top:_p_ := _g_.m.p.ptr()//......//从本地队列获取// local runqif gp, inheritTime := runqget(_p_); gp != nil {return gp, inheritTime}// global runq// 从全局队列获取if sched.runqsize != 0 {lock(&sched.lock)gp := globrunqget(_p_, 0)unlock(&sched.lock)if gp != nil {return gp, false}}// Poll network.// This netpoll is only an optimization before we resort to stealing.// We can safely skip it if there are no waiters or a thread is blocked// in netpoll already. If there is any kind of logical race with that// blocked thread (e.g. it has already returned from netpoll, but does// not set lastpoll yet), this thread will do blocking netpoll below// anyway.if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {if list := netpoll(false); !list.empty() { // non-blockinggp := list.pop()injectglist(&list)casgstatus(gp, _Gwaiting, _Grunnable)if trace.enabled {traceGoUnpark(gp, 0)}return gp, false}}// Steal work from other P's.// 如果其他的 P 都处于空闲状态,那肯定没有其他工作要做procs := uint32(gomaxprocs)if atomic.Load(&sched.npidle) == procs-1 {// Either GOMAXPROCS=1 or everybody, except for us, is idle already.// New work can appear from returning syscall/cgocall, network or timers.// Neither of that submits to local run queues, so no point in stealing.goto stop}////如果有很多工作线程在找工作,那我就停下休息。避免消耗太多 CPU// If number of spinning M's >= number of busy P's, block.// This is necessary to prevent excessive CPU consumption// when GOMAXPROCS>>1 but the program parallelism is low.if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {goto stop}if !_g_.m.spinning {//// 设置自旋状态为true_g_.m.spinning = true////自旋状态数加1atomic.Xadd(&sched.nmspinning, 1)}////从其他P的本地运行队列盗取goroutinefor i := 0; i < 4; i++ {for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {if sched.gcwaiting != 0 {goto top}stealRunNextG := i > 2 // first look for ready queues with more than 1 g//窃取函数if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil {return gp, false}}}stop://......// return P and blocklock(&sched.lock)if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {unlock(&sched.lock)goto top}if sched.runqsize != 0 {gp := globrunqget(_p_, 0)unlock(&sched.lock)return gp, false}//// 当前工作线程解除与P之间的绑定,准备去休眠if releasep() != _p_ {throw("findrunnable: wrong p")}////把p放入空闲队列pidleput(_p_)unlock(&sched.lock)wasSpinning := _g_.m.spinningif _g_.m.spinning {//// m即将睡眠,不在处于自旋_g_.m.spinning = falseif int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {throw("findrunnable: negative nmspinning")}}// check all runqueues once again////休眠之气前再检查一下所有的p,看一下是否有工作要做for _, _p_ := range allpSnapshot {if !runqempty(_p_) {lock(&sched.lock)_p_ = pidleget()unlock(&sched.lock)if _p_ != nil {acquirep(_p_)if wasSpinning {_g_.m.spinning = trueatomic.Xadd(&sched.nmspinning, 1)}goto top}break}}////......//// 休眠stopm()goto top}
runsteal窃取函数详解
// 从P2偷走一半的工作放到_p_的本地func runqsteal(_p_, p2 *p, stealRunNextG bool) *g {// 队尾t := _p_.runqtail// 从p2偷取工作,放到_p_.runq的队尾n := runqgrab(p2, &_p_.runq, t, stealRunNextG)if n == 0 {return nil}n--//// 找到最后一个g,准备返回gp := _p_.runq[(t+n)%uint32(len(_p_.runq))].ptr()if n == 0 {//说明只偷了一个greturn gp}//// 队列头h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers////判断是否偷太多了if t-h+n >= uint32(len(_p_.runq)) {throw("runqsteal: runq overflow")}////更新队尾,将偷来的工作加入队列atomic.StoreRel(&_p_.runqtail, t+n) // store-release, makes the item available for consumptionreturn gp}
调用 runqgrab 从 p2 偷走它一半的工作放到 p 本地。runqgrab 函数将从 p2 偷来的工作放到以 t 为地址的数组里,数组就是 p.runq。
窃取函数findrunnable()函数从其他地方找goroutine来执行。
findrunnable()函数中调用—>globrunqget()函数从全局队列获取—>检查其他的P是否都处于空闲状态,那肯定也没有工作—>如果现在有很多工作线程找工作,那么就停下来休息,避免消耗太多的CPU —>然后从其他P的本地运行队列窃取goroutine(外层循环次数,内层窃取次序)通过runqsteal()函数窃取 —>runsteal()函数中再调用runqgrab函数窃取一半的工作放到p本地—>然后返回findrunnable()函数执行stop代码块->执行releasep()函数接触p与m的关联—>执行stopm()函数 休眠,停止执行工作,直到有新工作需要做为止。
acquirep()函数的作用:
调用 acquirep(p) 绑定获取到的 p 和 m,主要的动作就是设置 p 的 m 字段,更改 p 的工作状态为 _Prunning,并且设置 m 的 p 字段。做完这些之后,再次进入 top 代码段,再走一遍之前找工作的过程。
// Stops execution of the current m until new work is available.// Returns with acquired P.////休眠,停止执行工作,直到有新的工作需要做为止func stopm() {//// 当前goroutine,g0_g_ := getg()// .......// 将 m 放到全局空闲链表里去mput(_g_.m)unlock(&sched.lock)//进入到睡眠状态notesleep(&_g_.m.park)//这里呗其他工作线程唤醒noteclear(&_g_.m.park)acquirep(_g_.m.nextp.ptr())_g_.m.nextp = 0}
最后m 找不到工作就会休眠,当其他线程发现有工作要做时,就会找到空闲的m,再通过m.park字段唤醒本线程。唤醒之后再回到findrunnable()函数,继续寻找goroutine,然后返回schedule函数。然后就会去运行找到的goroutine。
系统监控sysmon线程做了什么?
在 runtime.main() 函数中,执行 runtime_init() 前,会启动一个 sysmon 的监控线程,执行后台监控任务:
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmonsystemstack(func() {////创建监控线程,该线程独立于调度器,不需要跟 p 关联即可运行newm(sysmon, nil)})}
sysmon()函数做了什么
sysmon 执行一个无限循环,一开始每次循环休眠 20us,之后(1 ms 后)每次休眠时间倍增,最终每一轮都会休眠 10ms。
sysmon 中会进行 netpool(获取 fd 事件)、retake(抢占)、forcegc(按时间强制执行 gc),scavenge heap(释放自由列表中多余的项减少内存占用)等处理。
sysmon线程调度总结如下:
- 抢占处于系统调用的 P,让其他 m 接管它,以运行其他的 goroutine。
- 将运行时间过长的 goroutine 调度出去,给其他 goroutine 运行的机会。
调度相关的函数只需要关心retake函数,retake函数中针对处于_Psycall和_Pruning状态的p进行抢占。

若有收获,就点个赞吧
0 人点赞
