参考 分布式任务调度平台xxl-job
源码下载地址 https://github.com/xuxueli/xxl-job/releases
一、什么是xxl-job
XXL-JOB是一个轻量级分布式任务调度平台,支持通过 Web 页面对任务进行 CRUD 操作,支持动态修改任务状态、暂停/恢复任务,以及终止运行中任务,支持在线配置调度任务入参和在线查看调度结果。
它的特点有:
平台:
- 调度中心式设计
- 解耦
- 用DB实现注册中心,实现轻量级部署
- 弹性扩、缩容
- 故障转移:执行器集群某台机器出现故障,能够自动切换正常的执行器
- 分片广播:且支持动态分片,提升任务运行效率
- 路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 全异步化:异步调度和异步执行。
任务:
- 任务支持分布式执行
- 简单:支持通过web对任务进行crud
- 灵活:动态修改任务状态,自定义失败重试次数等,且即时生效
- 告警:任务失败,支持邮件告警
二、概念说明
任务
调度任务,系统角色中的最小单元
- 可通过webide(GLUE模式) 或者ide(BEAN模式)自定义任务内容
- 支持多种路由策略和阻塞处理策略的选择
- 支持自定义失败重试次数和任务超时时间
- 支持任务失败告警
- 支持动态修改任务状态和各个配置策略的修改
调度中心
统一管理任务调度平台上的调度任务,负责触发调度执行,并提供可视化平台管理执行器
主要负责接收“调度中心”的调度并执行
三、安装启动
下载
https://github.com/xuxueli/xxl-job
注意,调度中心和执行器的code version 必须一致!!
环境要求
sql脚本在源码内,用navicat工具导入即可
doc/db/tables_xxl_job.sql
- 调度数据库配置说明 ```java
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
xxl_job_user:系统用户表; ```
项目结构 ``` xxl-job-admin:调度中心 xxl-job-core:公共依赖 xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器) :xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式; :xxl-job-executor-sample-frameless:无框架版本;
- **配置部署“调度中心”(xxl-job-admin)**
- **更改配置**
web
server.port=8080 server.context-path=/xxl-job-admin
xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 spring.datasource.username=root spring.datasource.password=123456
xxl-job email
spring.mail.host=smtp.qq.com spring.mail.port=25 spring.mail.username=xxx@qq.com spring.mail.password=xxx
xxl-job, access token
xxl.job.accessToken=
xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200 xxl.job.triggerpool.slow.max=100
- **部署项目**
**方式一:项目打包部署**
- 打包xxl-job-admin
- 调度中心访问地址:[http://localhost:8080/xxl-job-admin](http://localhost:8080/xxl-job-admin) (该地址执行器将会使用到,作为回调地址)<br />默认登录账号:admin 默认登录密码:123456
**方式二:Docker镜像搭建**
- 下载镜像
docker pull xuxueli/xxl-job-admin
- 创建容器
> 由于官方镜像的配置文件(application.properties)是默认的,这里需要通过 "PARAMS" 指定,参数格式 RAMS="--key=value --key2=value2" 去修改
docker run -e PARAMS=”—spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?Unicode=true&characterEncoding=UTF-8” -p 8082:8080 -v /tmp:/data/applogs —name xxl-job-admin -d xuxueli/xxl-job-admin
- 运行
mvn clean package docker build -t xuxueli/xxl-job-admin ./xxl-job-admin docker run —name xxl-job-admin -p 8080:8080 -d xuxueli/xxl-job-admin
- **调度中心集群(可选 )**
调度中心支持集群部署,提升调度系统容灾和可用性。<br />调度中心集群部署时,几点要求和建议:
- DB配置保持一致;
- 登陆账号配置保持一致;
- 集群机器时钟保持一致(单机集群忽视);
- 建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行。
- **配置部署“执行器项目”(xxl-job-executor-sample)**
**引入xxl-job依赖**
```xml
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
执行器配置application.properties
# web port server.port=8081 # log config logging.config=classpath:logback.xml ### 调度中心部署跟地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册 xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin ### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册 xxl.job.executor.appname=xxl-job-executor-sample ### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务" xxl.job.executor.ip= ### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口 xxl.job.executor.port=9999 ### 执行器通讯TOKEN [选填]:非空时启用 xxl.job.accessToken= ### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径 xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler ### 执行器日志保存天数 [选填] :值大于3时生效,启用执行器Log文件定期清理功能,否则不生效 xxl.job.executor.logretentiondays=-1部署项目
官方提供了多种执行器的示例项目,这里默认使用springboot。
执行器集群(可选)
执行器支持集群部署,提升调度系统可用性,同时提升任务处理能力。执行器集群部署时,几点要求和建议:
- 执行器回调地址(xxl.job.admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
- 同一个执行器集群内AppName(xxl.job.executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
四、开发
任务运行模式主要有Bean模式和Gule模式(理解为脚本)
BEAN模式
在该模式下,任务的具体实现逻辑是 以JobHandler的形式存在于“执行器项目”中。
- 步骤一:新建执行器项目
这里只要copy 项目xxl-job-executor-sample-springboot 即可
步骤二:修改执行器appname
logging: config: "classpath:logback.xml" server: port: 8081 xxl: job: accessToken: '' admin: addresses: http://127.0.0.1:8080/xxl-job-admin executor: appname: xxl-job-executor-test ip: '' logpath: /data/applogs/xxl-job/jobhandler logretentiondays: -1 port: 9999步骤三:新建一个任务Handler:testJobHandler,shardingJobHandler ```java package com.xxl.job.executor.service.jobhandler;
import com.xxl.job.core.context.XxlJobHelper; import com.xxl.job.core.handler.annotation.XxlJob; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component;
import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.DataOutputStream; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.Arrays; import java.util.concurrent.TimeUnit;
/**
- XxlJob开发示例(Bean模式) *
- 开发步骤:
- 1、任务开发:在Spring Bean实例中,开发Job方法;
- 2、注解配置:为Job方法添加注解 “@XxlJob(value=”自定义jobhandler名称”, init = “JobHandler初始化方法”, destroy = “JobHandler销毁方法”)”,注解value值对应的是调度中心新建任务的JobHandler属性的值。
- 3、执行日志:需要通过 “XxlJobHelper.log” 打印执行日志;
- 4、任务结果:默认任务结果为 “成功” 状态,不需要主动设置;如有诉求,比如设置任务结果为失败,可以通过 “XxlJobHelper.handleFail/handleSuccess” 自主设置任务结果; *
- @author xuxueli 2019-12-11 21:52:51 */ @Component public class SampleXxlJob { private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("testJobHandler")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobHelper.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
// default success
}
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
// 业务逻辑
for (int i = 0; i < shardTotal; i++) {
if (i == shardIndex) {
XxlJobHelper.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobHelper.log("第 {} 片, 忽略", i);
}
}
}
}
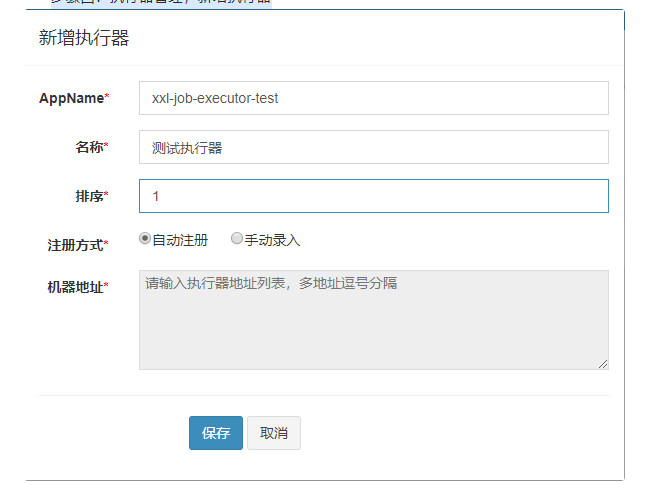
- 步骤四:执行器管理,新增执行器
- 步骤五:任务管理,新建调度任务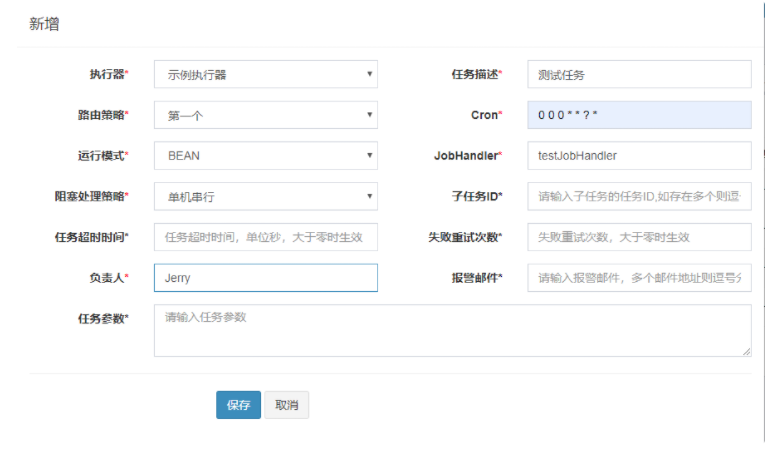
- 步骤六:执行任务,并查看日志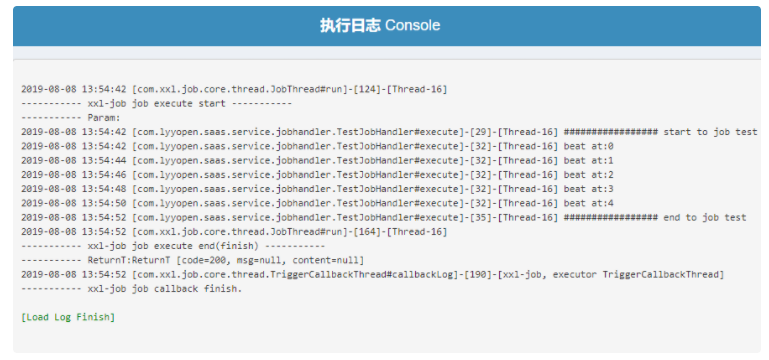
可以看到,这里成功执行了先前自定义的调度任务,并输出了log,结合代码分析,任务执行的log通过`XxlJobLogger.log`记录并写到日志表内,调度中心后台读取日志表得到详细的log。
<a name="8aWPg"></a>
## GLUE模式
> 任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler
拿GULE模式(JAVA)来解释,每一个GLUE模式的代码,在“执行器”接受到调度请求时,会通过Groovy类加载器加载出代码,并实例化成Java对象,同时注入此代码中声明的Spring服务(这里要确保代码中所引用的类或服务在“执行器项目中存在”),接着调用该对象的execute方法,执行具体的任务逻辑。
- **步骤二:点击操作,选择GLUE IDE,进入Web Ide界面**
<a name="1roc1"></a>
## 任务执行失败-邮件告警
- **步骤一:在之前 **`**更改配置**`**中,有相关邮件报警的发送方配置,配置即可**
```typescript
### 这里是用腾讯企业邮箱测试
spring.mail.host=smtp.exmail.qq.com
spring.mail.port=465
spring.mail.username=error@china-xinghan.com
spring.mail.password=123456
- 步骤二:在
**任务管理,新建调度任务**中,配置接收告警邮件的邮箱,多个用“,”隔开即可
相关的处理逻辑在调度中心的JobFailMonitorHelper类中
分片广播&动态分片
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务。 使用场景:
- 分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
- 广播任务场景:广播执行器机器运行shell脚本、广播集群节点进行缓存更新等
- 步骤一:执行器集群部署,暂设置为2个节点
执行器管理可以看到:一个APP有两个机器地址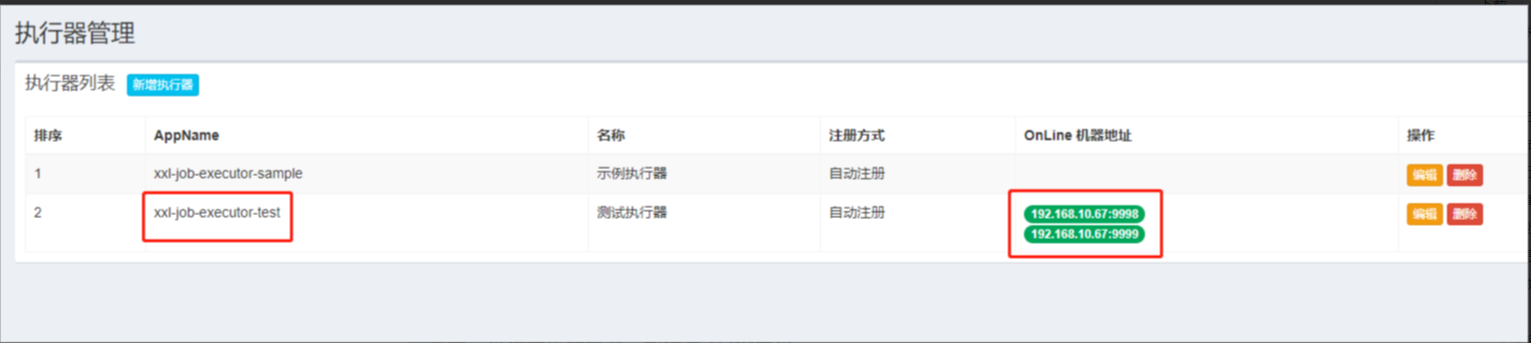
步骤二:新增or更新任务,更改路由策略为分片广播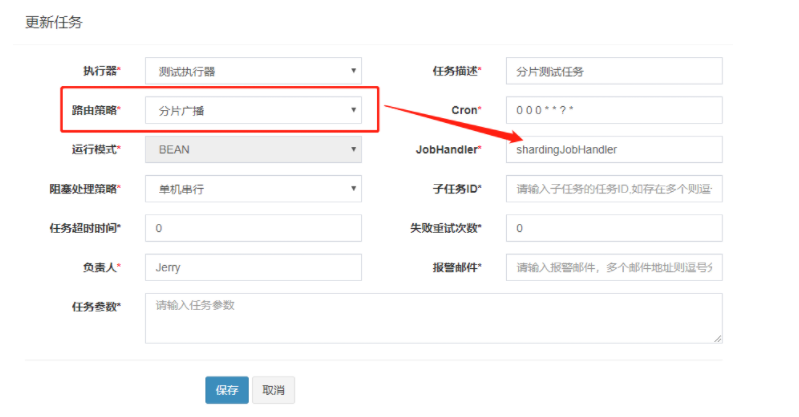
步骤三:编写业务代码
// 分片参数 ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo(); log.info("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal()); XxlJobLogger.log("分片参数1:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal()); // 业务逻辑 // ...-
五、架构设计
设计思想
实现 调度+任务 两者解耦
- 调度行为在调度中心(admin后台),负责发起调度请求
任务抽象化为一个个JobHandler,交由
执行器统一管理,执行器负责接收调度请求并找到对应的JobHandler,执行具体的业务逻辑(execute)系统组成
调度模块(调度中心): 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
执行模块(执行器): 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等。
架构图
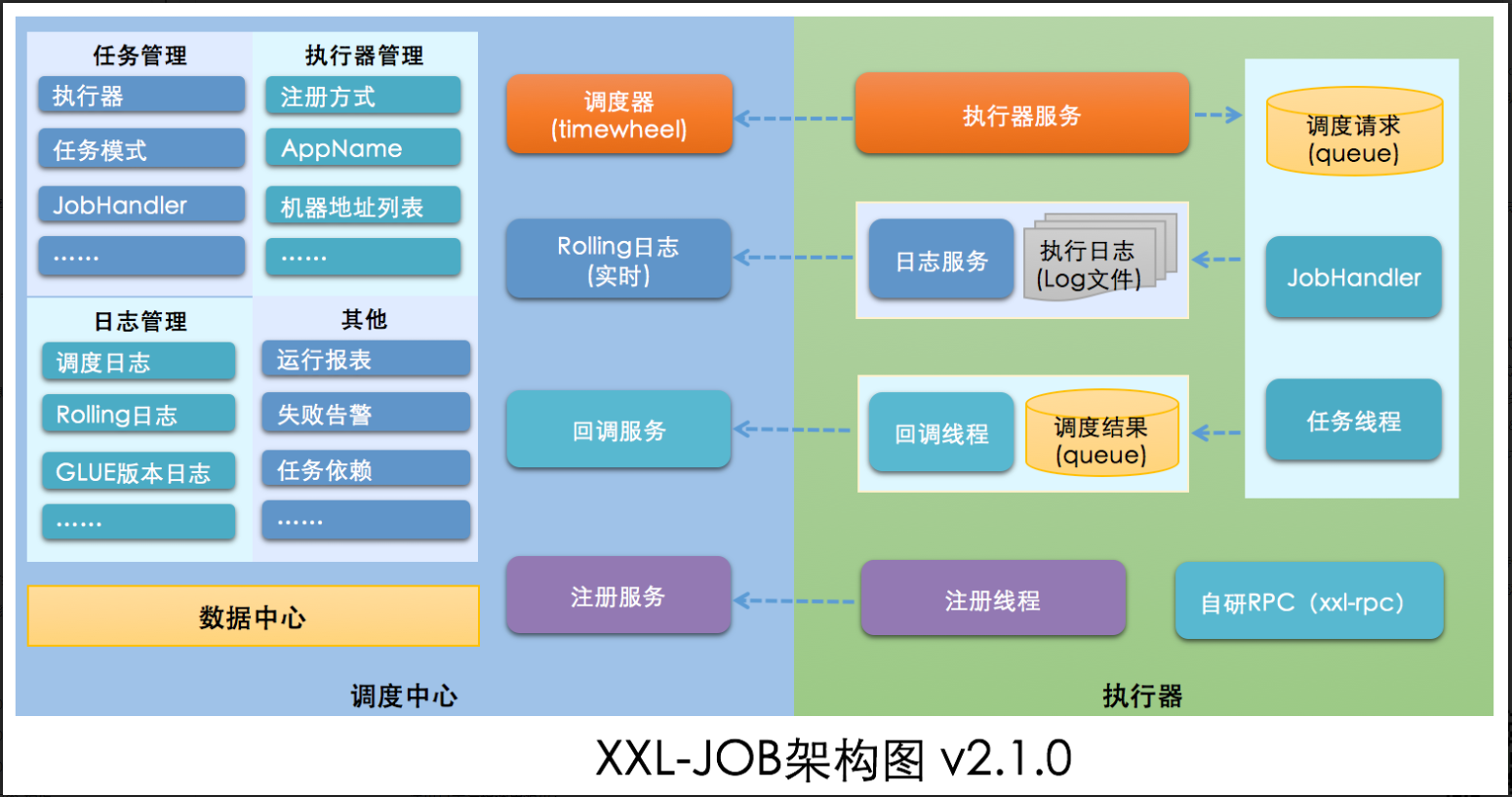
架构特性
解耦
调度中心通过类rpc的调用模式,调用执行器暴露的远程服务;
详见日志远程调用源码:com.xxl.rpc.remoting.invoker.reference.XxlRpcReferenceBean#getObject
- 线程池
调度采用线程池方式实现,避免用单线程出现阻塞而导致任务调度延迟; - 并行调度
调度模块采用并行机制,而调度传递到执行器则是串行执行 - 多种路由策略
- 过期处理策略
过期5s内立即触发一次,过期超5s则忽略 - 日志回调服务
“执行器”在收到调度请求并执行任务后,会将任务的执行结果回调通知给调度中心,调度中心再对应更新日志表。
执行器触发回调线程处理源码:com.xxl.job.core.thread.TriggerCallbackThread#doCallback
调度中心接受回调源码:
com.xxl.job.admin.service.impl.AdminBizImpl#callback(com.xxl.job.core.biz.model.HandleCallbackParam)任务集群
执行器如若集群部署,调度中心将会感知到在线的所有执行器- 全异步化
- 异步调度:调度中心每次任务触发时仅发送一次调度请求,该调度请求首先推送“异步调度队列”,然后异步推送给远程执行器
- 异步执行:执行器会将请求存入“异步执行队列”并且立即响应调度中心,异步运行。
轻量级设计
XXL-JOB调度中心中每个JOB逻辑非常 “轻”,在全异步化的基础上,单个JOB一次运行平均耗时基本在 “10ms” 之内(基本为一次请求的网络开销);因此,可以保证使用有限的线程支撑大量的JOB并发运行。通讯流程分析
xxl-job的执行流程
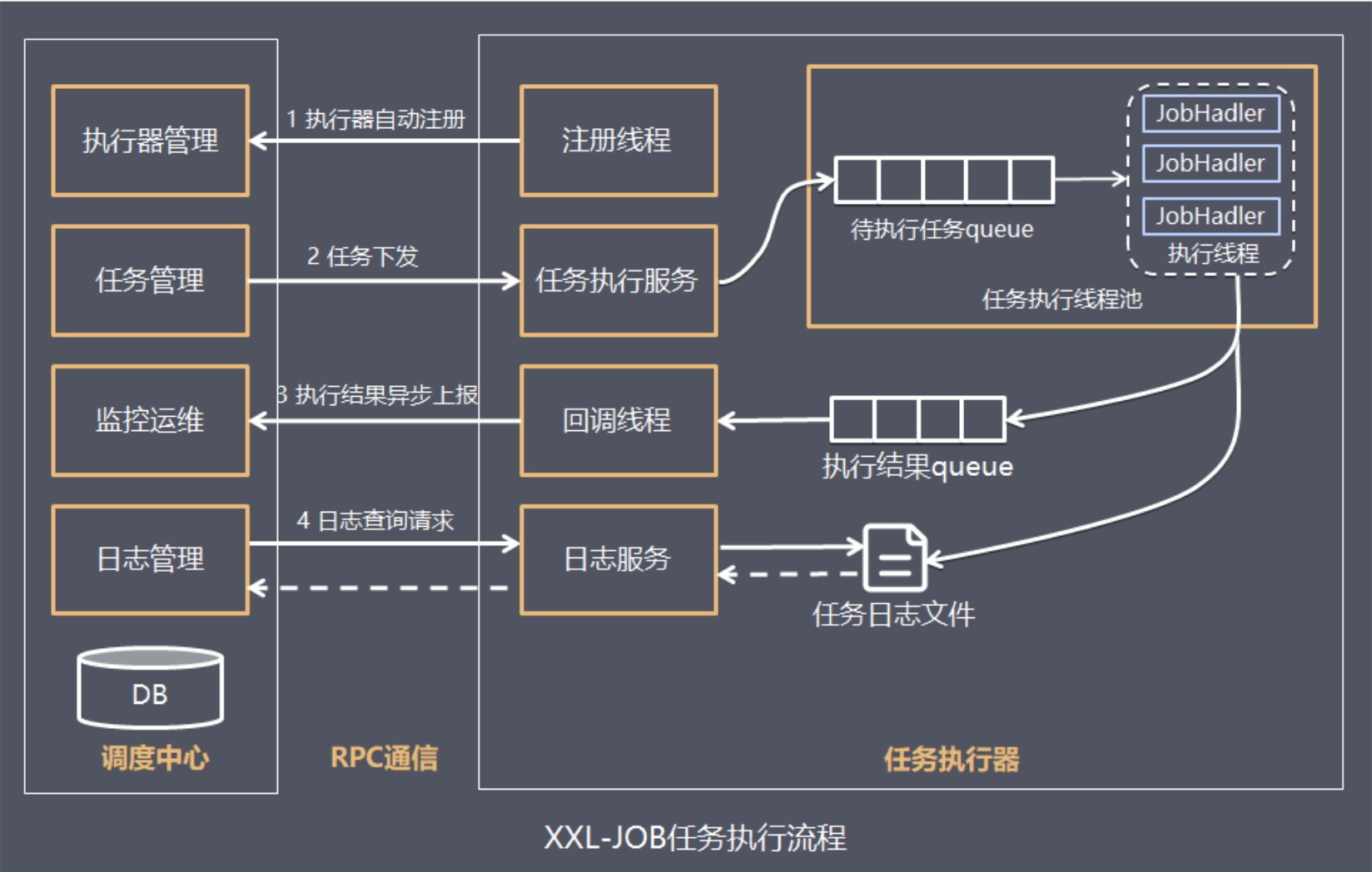
调度中心向执行器发送http调度请求: “执行器”中接收请求的服务,实际上是一台内嵌Server,默认端口9999;执行器执行任务逻辑执行器http回调调度中心调度结果:调度中心中接收回调的服务,是针对执行器开放一套API服务;六、源码分析
一、执行器注册
一、首先读取项目中的
@Xxl-Job注解// start @Override public void afterSingletonsInstantiated() { // init JobHandler Repository /*initJobHandlerRepository(applicationContext);*/ // init JobHandler Repository (for method)//获取所有任务放到一个map中 initJobHandlerMethodRepository(applicationContext); // refresh GlueFactory GlueFactory.refreshInstance(1); // super start try { super.start(); } catch (Exception e) { throw new RuntimeException(e); } }//任务放到一个map中等待调度中心调用 public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){ logger.info(">>>>>>>>>>> xxl-job register jobhandler success, name:{}, jobHandler:{}", name, jobHandler); return jobHandlerRepository.put(name, jobHandler); }二、初始化
XxlJobSpringExecutor,调用start方法@Bean public XxlJobSpringExecutor xxlJobExecutor() { logger.info(">>>>>>>>>>> xxl-job config init."); XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAppname(appname); xxlJobSpringExecutor.setAddress(address); xxlJobSpringExecutor.setIp(ip); xxlJobSpringExecutor.setPort(port); xxlJobSpringExecutor.setAccessToken(accessToken); xxlJobSpringExecutor.setLogPath(logPath); xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays); return xxlJobSpringExecutor; }```java public void start() throws Exception {
// 初始化日志路径 XxlJobFileAppender.initLogPath(logPath); // 初始化调度中心的本地列表 initAdminBizList(adminAddresses, accessToken); // 日志清除线程 JobLogFileCleanThread.getInstance().start(logRetentionDays); // 回调线程开启 TriggerCallbackThread.getInstance().start(); port = port>0?port: NetUtil.findAvailablePort(9999); ip = (ip!=null&&ip.trim().length()>0)?ip: IpUtil.getIp(); // 初始化服务器 initEmbedServer(ip, port, appName, accessToken);}
<a name="ZsHVE"></a>
#### 一、这里需要关注的是`initAdminBizList`和`initEmbedServer`,那么同样看代码。
```java
// ---------------------- admin-client (rpc invoker) ----------------------
private void initAdminBizList(String adminAddresses, String accessToken) throws Exception {
if (adminAddresses!=null && adminAddresses.trim().length()>0) {
for (String address: adminAddresses.trim().split(",")) {
if (address!=null && address.trim().length()>0) {
AdminBiz adminBiz = new AdminBizClient(address.trim(), accessToken);
if (adminBizList == null) {
adminBizList = new ArrayList<AdminBiz>();
}
adminBizList.add(adminBiz);
}
}
}
}
二、这里主要意思就是得到AdminBiz代理并放入到adminBizList集合中,然后接着看,接下来就是完成向任务调度中心发送请求进行服务注册操作,我们主要看如何发起请求的代码initEmbedServer
可以看到执行器本质上是启动了个netty开进行rpc调用
private void initEmbedServer(String address, String ip, int port, String appname, String accessToken) throws Exception {
//*
// start
embedServer = new EmbedServer();
embedServer.start(address, port, appname, accessToken);
}
//embedServer.start 启动netty进行一个端口注册到调度中心
public void start(final String address, final int port, final String appname, final String accessToken) {
executorBiz = new ExecutorBizImpl();
thread = new Thread(new Runnable() {
@Override
public void run() {
// param
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(
0,
200,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, EmbedServer bizThreadPool-" + r.hashCode());
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
throw new RuntimeException("xxl-job, EmbedServer bizThreadPool is EXHAUSTED!");
}
});
try {
// start server
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel channel) throws Exception {
channel.pipeline()
.addLast(new IdleStateHandler(0, 0, 30 * 3, TimeUnit.SECONDS)) // beat 3N, close if idle
.addLast(new HttpServerCodec())
.addLast(new HttpObjectAggregator(5 * 1024 * 1024)) // merge request & reponse to FULL
.addLast(new EmbedHttpServerHandler(executorBiz, accessToken, bizThreadPool));
}
})
.childOption(ChannelOption.SO_KEEPALIVE, true);
// bind
ChannelFuture future = bootstrap.bind(port).sync();
logger.info(">>>>>>>>>>> xxl-job remoting server start success, nettype = {}, port = {}", EmbedServer.class, port);
// start registry
startRegistry(appname, address);
// wait util stop
future.channel().closeFuture().sync();
} catch (InterruptedException e) {
if (e instanceof InterruptedException) {
logger.info(">>>>>>>>>>> xxl-job remoting server stop.");
} else {
logger.error(">>>>>>>>>>> xxl-job remoting server error.", e);
}
} finally {
// stop
try {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
});
thread.setDaemon(true); // daemon, service jvm, user thread leave >>> daemon leave >>> jvm leave
thread.start();
}
//startRegistry 将第一部的初始化AdminBiz执行器列表注册到注册中心
public void start(final String appname, final String address){
// valid
if (appname==null || appname.trim().length()==0) {
logger.warn(">>>>>>>>>>> xxl-job, executor registry config fail, appname is null.");
return;
}
if (XxlJobExecutor.getAdminBizList() == null) {
logger.warn(">>>>>>>>>>> xxl-job, executor registry config fail, adminAddresses is null.");
return;
}
registryThread = new Thread(new Runnable() {
@Override
public void run() {
// registry
while (!toStop) {
try {
RegistryParam registryParam = new RegistryParam(RegistryConfig.RegistType.EXECUTOR.name(), appname, address);
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
try {
ReturnT<String> registryResult = adminBiz.registry(registryParam);
if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {
registryResult = ReturnT.SUCCESS;
logger.debug(">>>>>>>>>>> xxl-job registry success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});
break;
} else {
logger.info(">>>>>>>>>>> xxl-job registry fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});
}
} catch (Exception e) {
logger.info(">>>>>>>>>>> xxl-job registry error, registryParam:{}", registryParam, e);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
try {
if (!toStop) {
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
}
} catch (InterruptedException e) {
if (!toStop) {
logger.warn(">>>>>>>>>>> xxl-job, executor registry thread interrupted, error msg:{}", e.getMessage());
}
}
}
// registry remove
try {
RegistryParam registryParam = new RegistryParam(RegistryConfig.RegistType.EXECUTOR.name(), appname, address);
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
try {
ReturnT<String> registryResult = adminBiz.registryRemove(registryParam);
if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {
registryResult = ReturnT.SUCCESS;
logger.info(">>>>>>>>>>> xxl-job registry-remove success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});
break;
} else {
logger.info(">>>>>>>>>>> xxl-job registry-remove fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});
}
} catch (Exception e) {
if (!toStop) {
logger.info(">>>>>>>>>>> xxl-job registry-remove error, registryParam:{}", registryParam, e);
}
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>>>> xxl-job, executor registry thread destroy.");
}
});
registryThread.setDaemon(true);
registryThread.setName("xxl-job, executor ExecutorRegistryThread");
registryThread.start();
}
三、小结

二、调度器的启动与执行
一、初始化配置
public void afterPropertiesSet() throws Exception {
adminConfig = this;
xxlJobScheduler = new XxlJobScheduler();
xxlJobScheduler.init();
}
二、初始化调度中心
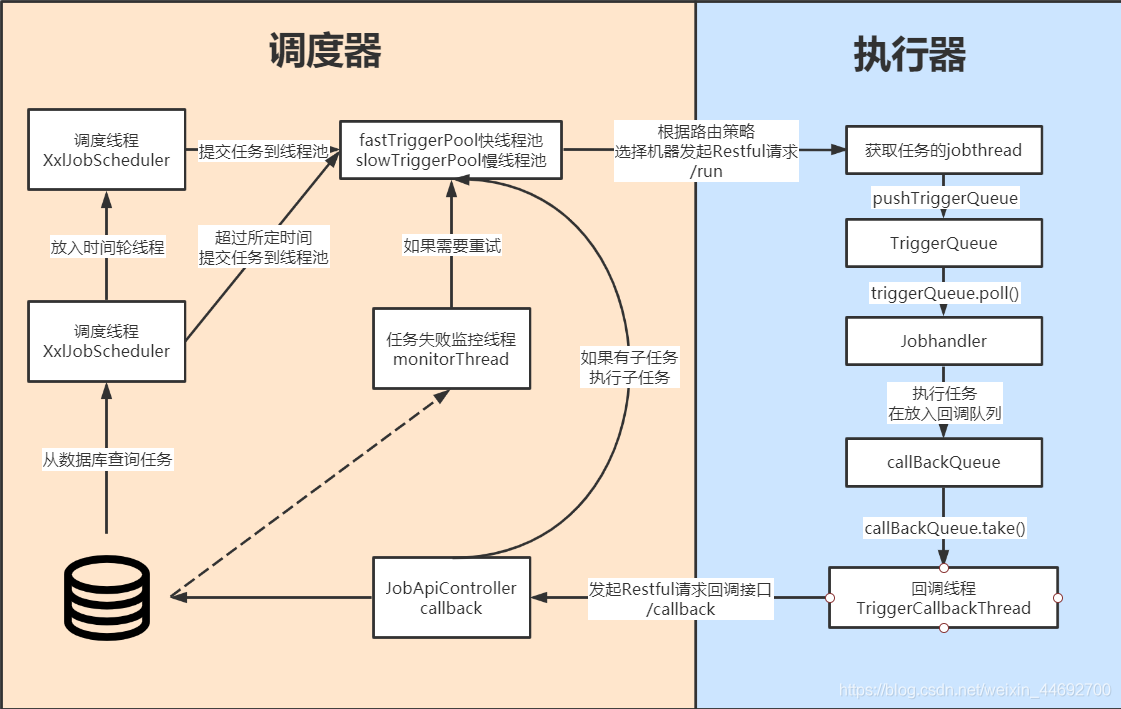
public void init() throws Exception {
// init i18n
initI18n();
// 1.任务注册监控器
JobRegistryMonitorHelper.getInstance().start();
// 2.任务调度失败监控器,失败重试,失败邮件发送
JobFailMonitorHelper.getInstance().start();
// 3.任务结果丢失处理
JobLosedMonitorHelper.getInstance().start();
// 4.trigger pool 启动 创建了两个调度线程池,一个快线程池,一个慢线程池
JobTriggerPoolHelper.toStart();
// 5.log report启动 报表线程
JobLogReportHelper.getInstance().start();
// 6.start-schedule 创建了两个线程,一个调度线程,一个时间论线程
JobScheduleHelper.getInstance().start();
logger.info(">>>>>>>>> init xxl-job admin success.");
}
(1)JobRegistryMonitorHelper.getInstance().start();
启动任务注册监控器线程,方法内单独启动了一个线程做while循环,30秒执行一次,那么我们直接看run()方法内的代码。
首先从表xxl_job_group中拿到所有自动注册的执行器(之所以不拿非自动注册的,是因为写死的执行器地址在执行器端配置文件中配置,不归调度中心管理)
不为空,则拿表xxl_job_registry中更新时间超过3次循环(90s)的地址,如果执行器处于活跃状态,每次while循环都会刷新更新时间,超过3次调度中心则认为它已经失活,从表xxl_job_registry中移除。
找到库中执行器处于活跃状态的执行器,因为调度中心支持多执行器多集群的形式注册,所以将执行器封装为一个Map<执行器名称,List<执行器地址>>
循环遍历每一个执行器,对表xxl_job_group中执行器进行更新(执行器id,执行器名称,执行器类型【自动注册,手动注册】,执行器地址列表(’,’分割))
该循环每30s执行一次。TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
@Override
public void run() {
while (!toStop) {
try {
// auto registry group 自动注册的执行器
List<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().findByAddressType(0);
if (groupList!=null && !groupList.isEmpty()) {
// 查询更新时间超过90s的执行器
List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findDead(RegistryConfig.DEAD_TIMEOUT, new Date());
if (ids!=null && ids.size()>0) {
//移除
XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids);
}
// 将执行器封装为一个HashMap<执行器名,该执行器IPs>
HashMap<String, List<String>> appAddressMap = new HashMap<String, List<String>>();
List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findAll(RegistryConfig.DEAD_TIMEOUT, new Date());
if (list != null) {
for (XxlJobRegistry item: list) {
if (RegistryConfig.RegistType.EXECUTOR.name().equals(item.getRegistryGroup())) {
String appname = item.getRegistryKey();
List<String> registryList = appAddressMap.get(appname);
if (registryList == null) {
registryList = new ArrayList<String>();
}
if (!registryList.contains(item.getRegistryValue())) {
registryList.add(item.getRegistryValue());
}
appAddressMap.put(appname, registryList);
}
}
}
// 循环遍历每一个执行器,更新app_name,title,address_type,address_list
for (XxlJobGroup group: groupList) {
List<String> registryList = appAddressMap.get(group.getAppname());
String addressListStr = null;
if (registryList!=null && !registryList.isEmpty()) {
Collections.sort(registryList);
addressListStr = "";
for (String item:registryList) {
addressListStr += item + ",";
}
addressListStr = addressListStr.substring(0, addressListStr.length()-1);
}
group.setAddressList(addressListStr);
XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}
try {
//每隔30秒循环一次
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, job registry monitor thread stop");
}
(2)JobScheduleHelper.getInstance().start();
此方法中创建了两个线程:scheduleThread、ringThread,我们分别看其run()方法。
① scheduleThread
- TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );先随机睡眠了4~5s,为了防止执行器集中启动过多而导致的资源竞争。
- preReadCount计算预读取的任务数,这里默认为6000。
- 获取数据库的排他锁,因为调度中心集群的所有节点连接的是同一个数据库,同一时间只允许有一台调度中心获取任务信息。(如果没有获取到锁,说明集群中有其他调度中心在加载任务,只能等其他节点提交事务或者回滚事务后才能获取到锁)
- 查找运行状态(status=1)且下次触发时间小于[现在时间+5s]的任务。也就是说查询5s内需要执行的启动中的任务。
- 接下来遍历所有任务,分了三种情况处理
nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS
[现在时间]大于[任务所定时间+5s],那么调度中心是不执行的,直接刷新该任务的下次执行时间(根据cron表达式计算)。
nowTime > jobInfo.getTriggerNextTime()
[现在时间]大于[任务所定时间],说明已经超过了任务规定的执行时间,应该立即触发调度,此时是正常触发。 直接通过JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);方法执行任务(内也是另起一个线程执行),然后刷新下次触发时间(根据cron表达式计算)。 更新完成后,再次判断此任务的执行时间与此时相比是否还在5s内,如果还在5s内,则放入时间轮内。 完成后再次刷新下次执行时间。
nowTime <= jobInfo.getTriggerNextTime()
[任务触发时间]大于[现在时间],且小于[现在时间+5s](最前面sql限制),也就是说5s内会到达此任务的下次执行时间。 此时直接放入时间轮中。再刷新下次任务执行时间(实际上此时任务在时间轮中还没有执行,但是提前刷新了任务的下次执行时间,意思就是放入时间轮交给时间轮线程执行。
三、调度任务
一、初始化调度任务信息
在①中的第二种情况,会直接触发任务,调用代码
JobTriggerPoolHelper.trigger(jobInfo.getId(),TriggerTypeEnum.CRON, -1, null, null, null);
//下一步
helper.addTrigger(jobId,triggerType,failRetryCount,executorShardingParam, executorParam, addressList);
在addTriger()方法中,使用了我们上面JobTriggerPoolHelper.toStart();创建的两个线程池[快线程池]和慢线程池。默认使用的是快线程池,如果任务执行时间超过500毫秒的次数超过了10次,则转为慢线程池,在方法的finally里面计算了任务执行时间和执行时间超过500毫秒的次数。这么做的好处是,快任务和慢任务做线程池隔离,避免慢任务数量过多影响其他任务调度的正常使用(任务执行时间超过500毫秒10次则用慢线程池中的线程执行)
// 选择线程池。快线程池、慢线程池
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) { // job-timeout 10 times in 1 min
triggerPool_ = slowTriggerPool;
}
二、开始执行真正的执行任务
XxlJobTrigger.trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);
- 根据任务id加载任务数据封装为XxlJobInfo
- 获取到任务执行时输入的参数param
- 获取到任务的失败重试次数,如果前面带过来的是小于0的,则用最新查出来的重试次数
- 通过XxlJobInfo中携带的group即执行器id查询出执行器的信息XxlJobGroup。包括执行器的地址、执行器的名称等等
- 先跳过分片广播任务直接来到 ```java processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
public static void trigger(int jobId, TriggerTypeEnum triggerType, int failRetryCount, String executorShardingParam, String executorParam, String addressList) {
// 加载任务数据
XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);
if (jobInfo == null) {
logger.warn(">>>>>>>>>>>> trigger fail, jobId invalid,jobId={}", jobId);
return;
}
if (executorParam != null) {
//获取到任务执行输入的参数
jobInfo.setExecutorParam(executorParam);
}
//获取到任务的失败重试次数,如果前面带过来的是小于0的,则用最新查出来的重试次数
int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();
//从数据库中查询到该任务的[执行器]信息XxlJobGroup,包括执行器的地址、执行器的名称等等
XxlJobGroup group = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());
// cover addressList
if (addressList!=null && addressList.trim().length()>0) {
group.setAddressType(1);
group.setAddressList(addressList.trim());
}
int[] shardingParam = null;
//如果是分片广播任务则走这个
if (executorShardingParam!=null){
String[] shardingArr = executorShardingParam.split("/");
if (shardingArr.length==2 && isNumeric(shardingArr[0]) && isNumeric(shardingArr[1])) {
shardingParam = new int[2];
shardingParam[0] = Integer.valueOf(shardingArr[0]);
shardingParam[1] = Integer.valueOf(shardingArr[1]);
}
}
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList()!=null && !group.getRegistryList().isEmpty()
&& shardingParam==null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
//执行任务调度
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
} else {
//如果不是分片任务,则传入0,1
if (shardingParam == null) {
shardingParam = new int[]{0, 1};
}
//执行任务调度
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
}
}
processTrigger
1. 此方法中前面是获取到一些参数,然后记录日志,初始化调度Trigger参数等操作
1. 然后根据路由策略选择执行方式。如果是分片广播,则所有节点都需要参与负载都需要执行(通过外层方法的for循环,传入total和index这里计算出本次实际需要执行的address)
1. 否则根据配置的策略获取执行器地址并封装到`routAddressResult`中,并判断机器是否正常可用,可用则放入address中。这里路由策略的选择使用的是`策略模式`。
<a name="I92n4"></a>
### 四、小结
<a name="oT74k"></a>
## 三、执行器执行任务
执行器端在启动的时候初始化了一个bizThreadPool业务线程池。并且启动了一个9999(默认)端口的Netty服务。
<a name="VkVTA"></a>
#### (1)EmbedHttpServerHandler
当调度器端打请求到执行器端时,会走到`EmbedServer`的内部类`EmbedHttpServerHandler`的`channelRead0()`方法中。在此方法,使用了`bizThreadPool`线程池中的线程来执行任务。<br />可以取出此次请求所携带的一些参数,比如uri。<br />在执行到其中的process方法中的`/run`条件方法
```java
@Override
protected void channelRead0(final ChannelHandlerContext ctx, FullHttpRequest msg) throws Exception {
// request parse
//final byte[] requestBytes = ByteBufUtil.getBytes(msg.content()); // byteBuf.toString(io.netty.util.CharsetUtil.UTF_8);
String requestData = msg.content().toString(CharsetUtil.UTF_8);
String uri = msg.uri();
HttpMethod httpMethod = msg.method();
boolean keepAlive = HttpUtil.isKeepAlive(msg);
String accessTokenReq = msg.headers().get(XxlJobRemotingUtil.XXL_JOB_ACCESS_TOKEN);
// invoke
bizThreadPool.execute(new Runnable() {
@Override
public void run() {
// do invoke
Object responseObj = process(httpMethod, uri, requestData, accessTokenReq);
// to json
String responseJson = GsonTool.toJson(responseObj);
// write response
writeResponse(ctx, keepAlive, responseJson);
}
});
}
//process方法
private Object process(HttpMethod httpMethod, String uri, String requestData, String accessTokenReq) {
// valid
if (HttpMethod.POST != httpMethod) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "invalid request, HttpMethod not support.");
}
if (uri==null || uri.trim().length()==0) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "invalid request, uri-mapping empty.");
}
if (accessToken!=null
&& accessToken.trim().length()>0
&& !accessToken.equals(accessTokenReq)) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "The access token is wrong.");
}
// services mapping
try {
if ("/beat".equals(uri)) {
return executorBiz.beat();
} else if ("/idleBeat".equals(uri)) {
IdleBeatParam idleBeatParam = GsonTool.fromJson(requestData, IdleBeatParam.class);
return executorBiz.idleBeat(idleBeatParam);
} else if ("/run".equals(uri)) {
TriggerParam triggerParam = GsonTool.fromJson(requestData, TriggerParam.class);
return executorBiz.run(triggerParam);
} else if ("/kill".equals(uri)) {
KillParam killParam = GsonTool.fromJson(requestData, KillParam.class);
return executorBiz.kill(killParam);
} else if ("/log".equals(uri)) {
LogParam logParam = GsonTool.fromJson(requestData, LogParam.class);
return executorBiz.log(logParam);
} else {
return new ReturnT<String>(ReturnT.FAIL_CODE, "invalid request, uri-mapping("+ uri +") not found.");
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
return new ReturnT<String>(ReturnT.FAIL_CODE, "request error:" + ThrowableUtil.toString(e));
}
}
(2)ExecutorBizImpl
- 第一步先从容器中根据任务id拿到任务的jobThread,再从jobThread中获取到jobhandler。(实际上每一个任务的第一次执行这里拿到的都是null,在执行完毕后再放入内存中存储为一个map:jobThreadRepository,再次调度的时候直接从内存中获取这个jobhandler)
ConcurrentMap<Integer, JobThread> jobThreadRepository;
- 然后根据参数传入的运行模式来选择执行哪段逻辑,这里是BEAN模式。
- 再根据任务ID获取到内存中的JobHandler(在执行器端启动的时候放入内存的一个mapjobHandlerRepository中,可以看上面执行器启动注册的时候做的动作)
//key是任务id,value是id对应的jobhandlerConcurrentMap<String, IJobHandler> jobHandlerRepository
- 判断如果由job线程中获取的handler为空的话,就将其赋值为最新的handler。
- (非第一次执行)需要根据配置的策略采取不同的措施,比如:
- DISCARD_LATER(丢弃后续调度):如果当前线程阻塞,后续任务不再执行,直接返回失败
- COVER_EARLY(覆盖之前调度):创建一个移除原因,新建一个线程去执行后续任务(杀掉当前线程)
- SERIAL_EXECUTION(单机穿行,默认):对当前线程不做任何处理,并在当前线程的队列里增加一个执行任务(一次只执行一个任务)
- 重置jobThread(为空则新建),之后启动此job线程,再放入内存中存储
- 最后调用jobThread的pushTriggerQueue方法把Trigger放入队列中。
LinkedBlockingQueue<TriggerParam> triggerQueue;
最后执行run方法
@Override
public ReturnT<String> run(TriggerParam triggerParam) {
// load old:jobHandler + jobThread
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
String removeOldReason = null;
// valid:jobHandler + jobThread
//bean模式
GlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());
if (GlueTypeEnum.BEAN == glueTypeEnum) {
// new jobhandler
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());
// valid old jobThread
if (jobThread!=null && jobHandler != newJobHandler) {
// change handler, need kill old thread
removeOldReason = "change jobhandler or glue type, and terminate the old job thread.";
jobThread = null;
jobHandler = null;
}
// valid handler
if (jobHandler == null) {
jobHandler = newJobHandler;
if (jobHandler == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "job handler [" + triggerParam.getExecutorHandler() + "] not found.");
}
}
//这里是bean模式先忽略GLUE
} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) {
...
} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) {
...
} else {
return new ReturnT<String>(ReturnT.FAIL_CODE, "glueType[" + triggerParam.getGlueType() + "] is not valid.");
}
// executor block strategy
if (jobThread != null) {
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {
// discard when running
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {
// kill running jobThread
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}
} else {
// just queue trigger
}
}
// replace thread (new or exists invalid)
if (jobThread == null) {
jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);
}
// push data to queue
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
return pushResult;
}
(3)JobThread
在(2)中我们知道,每个任务都会启动一个jobThread。
- 实际上JobThread继承了Thread,在start的时候会进入run方法的死循环,不断的从队列里面拿它的任务
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
- 如果任务设置了超时时间则用Feature来执行任务,超时就将executeResult设置为失败。
- 如果任务没有设置超时时间,则直接执行此任务。
- 然后根据自己业务代码的执行逻辑,返回执行结果executeResult。
- 最后在finally中,将执行结果executeResult放入到类TriggerCallbackThread的一个回调队列callBackQueue中。

若有收获,就点个赞吧
0 人点赞
