索引是什么?
如果说数据是字典的话,索引就是字典的目录
mySQL 常用的索引有两种 B-Tree(实际上是 B+Tree)和 Hash
默认是前者(实际上 InnoDB 只是支持BTree)
创建索引 删除索引:
create index idx_email on student(email)drop index idx_email on studentcreate index idx_email using hash on student(email) #还是BTree
索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
-
索引的用处
快速查找匹配 WHERE 子句的行
- 从 consideration 中消除行,如果可以在多个索引之间进行选择,mysql 通常会使用找到最少行的索引
- 如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的 min 或 max 值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
索引的分类
- 主键索引
- 唯一索引
- 普通索引
- 全文索引
-
什么使用索引?
mySQL 数据存储在哪里?磁盘
- 查询数据比较慢,一般情况下卡在哪里?IO
- 提高 IO 效率
- 尽可能减少访问磁盘的次数
- 尽可能减少读取的数据量
- 提高 IO 效率
- 去磁盘读取数据的时候,是使用多少读取多少吗?
- 磁盘预读
- 内存跟磁盘在发生数据交互的时候,一般情况下有一个最小的逻辑单元,称之为页,datapage,页一般由操作系统决定是多大,一般是 4k 或者 8k,而我们在进行数据交互的时候,可以取页的整数倍来进行读取,innodb 存储引擎每次读取数据,读取 16k。
- 局部性原理
- 数据和程序都有聚集成群的倾向,同时之前被访问的数据很可能再次被查询,空间局部性,时间局部性
- 磁盘预读
- 索引存储在哪里?磁盘,查询数据的时候会优先将索引加载到内存中
- 索引在存储的时候需要什么信息?需要存储什么字段值?
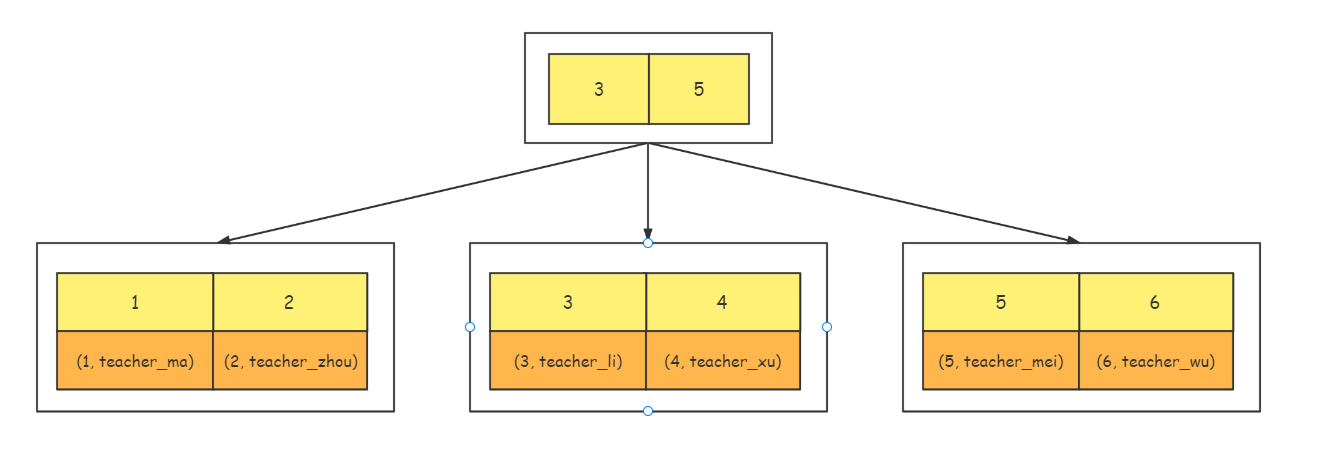
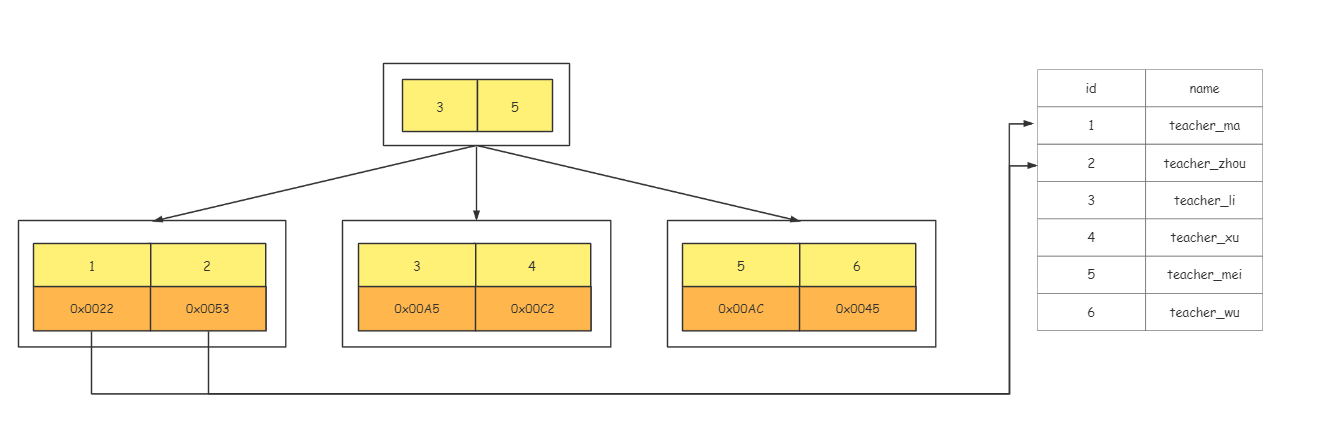
- InnoDB 中 B+ Tree 前面存储的是 key,最后一行存储的是 key + 整行的行记录
- myISAM 中 B+ Tree 前面存储的是 key,最后一行存储的是 key + 存储文件的地址
- OLAP(联机分析处理)
- 对海量历史数据进行分析,产生决策性的影响
- 数据仓库(key:文件地址 + offset偏移量)
- OLTP(联机事务处理)
- 要求在很短的时效内返回对应的结果
- 关系型数据库
- InnoDB 中 B+ Tree 前面存储的是 key,最后一行存储的是 key + 整行的行记录
- 聚簇索引和非聚簇索引
- 取决于数据和索引是否是放在一起的!
- innodb (frm,ibd)只能有一个聚簇索引,但是可以有很多非聚簇索引
- 向 innodb 插入数据的时候,必须要包含一个索引的 key 值
- 这个索引的 key 值,可以是主键,如果没有主键,那么就是唯一键,如果没有唯一键,那么就是一个自生成的 6 字节的 rowid。
回表
当根据普通索引查询到聚簇索引的 key 值之后,再根据 key 值再聚簇索引中获取所有行记录。-- 假设:有一个表table,其中包含 id, name, age, gender,id是主键,name是索引列select * from table where name='zhangsan';-- 会先根据name查询id,再根据id查询数据行,走了2颗B+ Tree,此时这中现象叫做回表。
索引覆盖
select id,name from table where name='zhangsan';-- 根据name可以直接查询到id,name两个列的值,直接返回即可,不需要从聚簇索引查询任何数据-- 这个时候叫做索引覆盖
最左匹配
在使用组合索引的时候,会优先比较组合索引中最左边的那个,然后在比较后面的。-- 假设有一张表,有id,name,age,gender,id是主键,name,age是组合主键-- 在使用组合主键的时候,需要先匹配name在匹配ageselect * from table where name=? and age=?;(生效)select * from table where name=?;(生效)select * from table where age=?;(无效)select * from table where age=? and name=?;(生效)-- mysql内部有优化器,会调整对应的顺序
索引下推
```sql select * from table where name=? and age=?; — 在没有索引下推之前: — 先根据name从存储引擎之后获取符合规则的数据,然后在从server层对age进行过滤
— 在有索引下推之后: — 直接根据name,age两个条件从存储引擎之中获取符合规则的数据 ```

若有收获,就点个赞吧
0 人点赞
