执行环境
首先通过了解js引擎来了解js的代码执行过程。js引擎是js代码的执行环境,虽然不同的js引擎的实现方式、解析原理不同,但是他们都必须按照ECMAScript的标准来实现。因此了解js的工作原理,我们可以只看其中有代表性的一个-v8。
首先来看一下v8的工作流程图: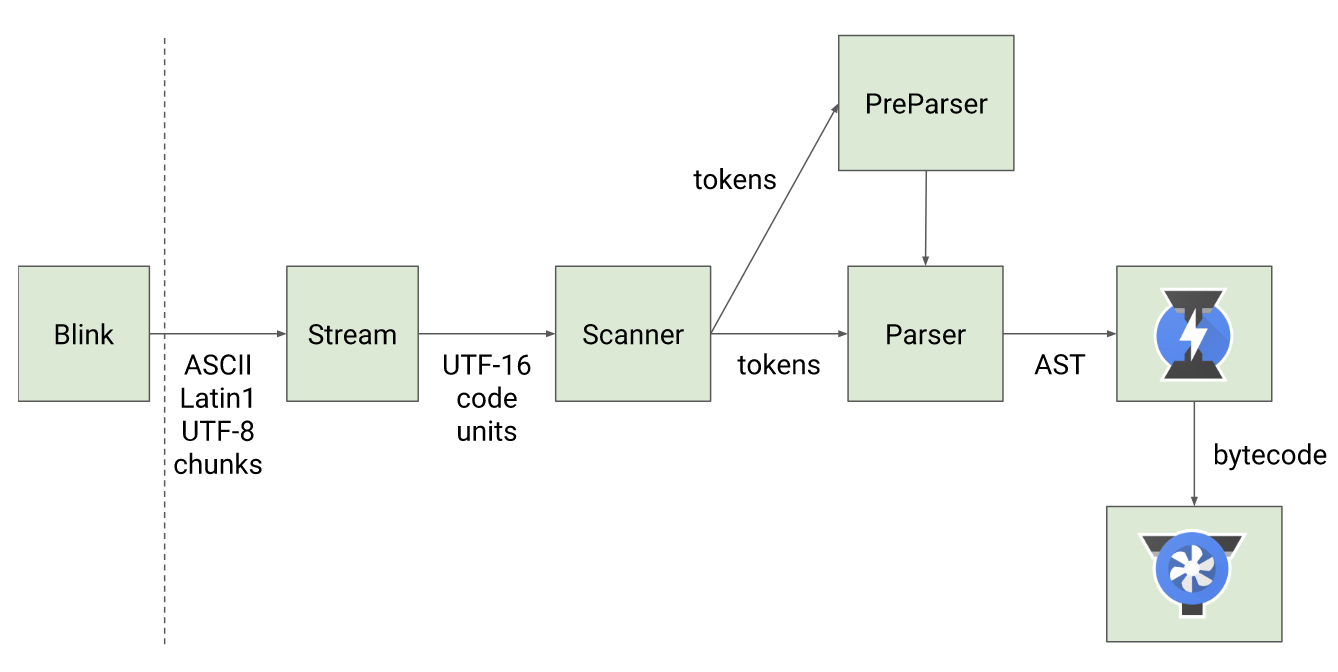
blick是chrome的渲染引擎,v8是他内置的JS引擎
scanner (扫描器)
scanner是一个扫描器,对js代码进行词法分析转换为tokens。tokens就是语法上不可分割的最小单位。
在线网站: https://esprima.org/demo/parse.html#
可以查看js扫描后的tokens
例如: let a = 1 转化为: “let”、”a”、”=”、”1”
parser(解析器)
parser 是将tokens转化为抽象语法树。
分为全量解析(eage)和预解析(layze)。原则上来说,本来应该全部解析掉,但是有大量定义未使用代码,多为项目中引入的依赖包中声明的函数。于是有了预解析方案。
// 声明时未调用,因此会被认为是不被执行的代码,进行预解析function foo1() {console.log('foo1')}// 声明时未调用,因此会被认为是不被执行的代码,进行预解析function foo2() {}// 函数立即执行,只进行一次全量解析(function foo3() {})()// 执行 foo,那么需要重新对 foo 函数进行全量解析,此时 foo 函数被解析了两次foo1();
预解析:
- 速度快
- 构建作用域链对象(不带有local的scopes信息)
- 抛出语法错误
全量解析过程:
- 解析代码产生AST
- 构建具体的作用域范围信息(scopes的全部信息)
- 抛出语法错误
ignition (解释器)
turboFan(编译器)
利用ignition转换的字节码转换为汇编代码,也就是最终运行代码。
ignition+turboFan是js边解释边执行的组合。同时,ignition转换出大量的字节码,交个turboFan去优化,满足优化条件的,会被直接优化为机器码。判断为不可优化的情况,则会执行de-optimize操作,代码逻辑会重新返回ignition中字节码的状态。
ts的优势之一,保证数据格式一致(对象、函数参数)产出可优化代码,不会重新回到解释器中。
函数调用栈
在js的执行过程中我们需要大量的函数来帮助我们完成各种功能,函数调用栈就是用来管理所有函数执行的。
明确一点,函数的声明和执行是两个不同的阶段。
声明
function foo() {}var bar = () => {}
两种声明方式都能创建函数体,函数体在js中本身是一个对象,在解析阶段创建后持久存储在内存中。
其他语言中,例如 Java,函数的声明会在代码打包的过程中就解析好,在内存中会专门提供一个静态的方法区,用于存放函数体。
但是 JS 是在代码运行过程中对函数进行解析,因此在内存分配中,JS 并没有一个类似方法区的静态区域用于存储函数体,而是将函数体看待成为一个对象,存放于堆内存中。
执行
函数执行会创建一个执行上下文。执行上下文与函数体是完全不同的。JavaScript 代码的执行,必须进入到一个执行上下文中:执行上下文可以理解为当前可执行代码的运行环境,他会按照函数体内编辑好的代码逻辑,实时的记录函数在执行过程中的所有状态与数据。
JavaScript 引擎,使用栈的方式来管理与跟踪多个执行上下文的运行情况,我们称之为函数调用栈。
在应用程序的运行过程中,栈底永远是全局上下文,并且不会出栈。栈顶是当前正在执行的上下文,也就意味着,无论任何时候,都只会有一个上下文正在执行。在执行过程中,如果遇到了新的函数执行,那么就会创建新的上下文,推入到栈顶,栈顶上下文执行完毕之后,就会出栈,并被垃圾回收器回收,新的栈顶上下文继续执行。
let text = '全局'function f1(){let text1 = 'f1'function f2() {let text2 = 'f2'console.log(text2)}f2()console.log(text1)}f1()function f3() {let text3 = 'f3'console.log(text3)}f3()console.log(text)
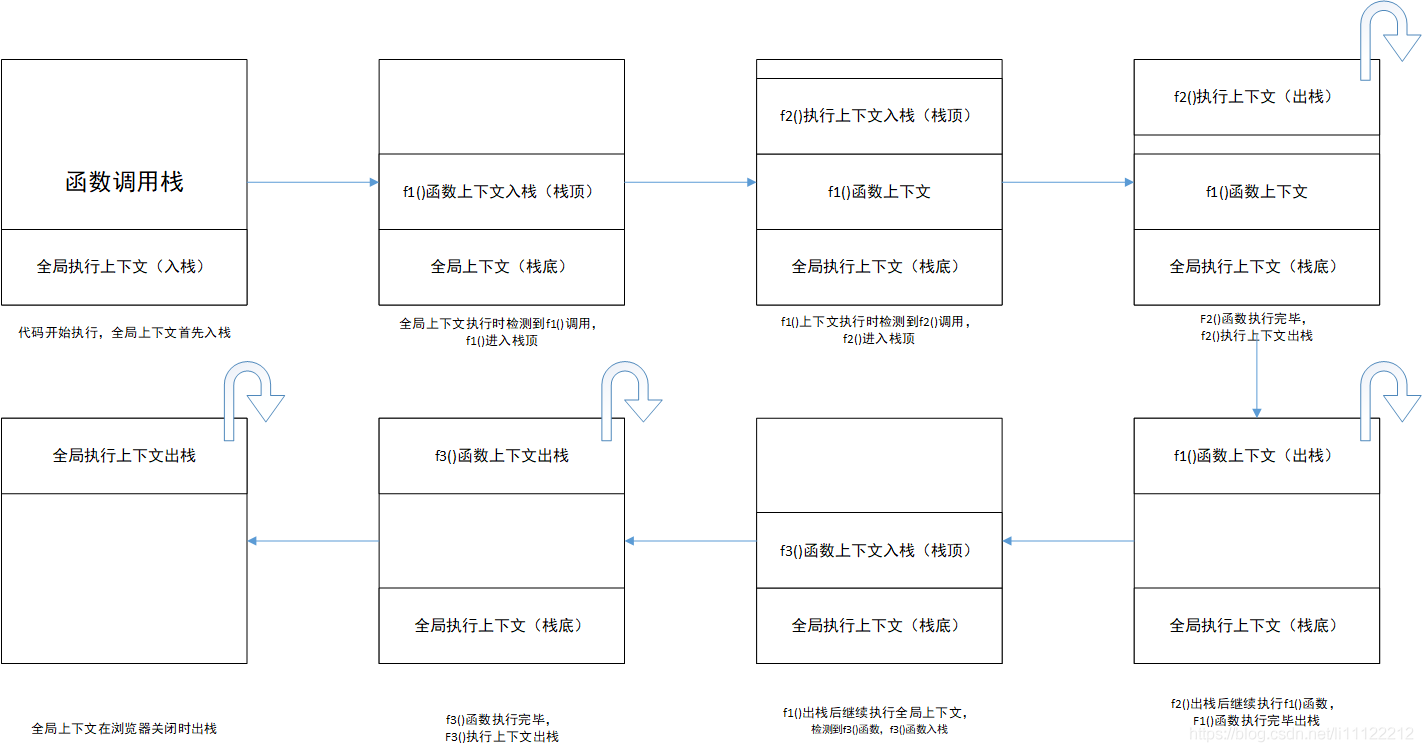
作业:
function f1() {var n = 999;function f2() {console.trace()alert(n);}return f2;}var result = f1();result();
事件循环
事件循环本身是html标准文档的一个定义 https://html.spec.whatwg.org/multipage/webappapis.html#event-loops
根据标准中对定义的描述,我们发现事件循环本质上是浏览器用于协调用户交互、脚本执行、渲染、网络等行为的一个机制。
了解到这个定义后我们能更清楚的知道,事件循环说是js提供的似乎就不太准确了,更合理的理解是js所在的浏览器(环境)的事件源交互机制。
简介来讲就是浏览器对执行事件的一个排队机制,这个排队行为以 JavaScript 开发者的角度来看,主要是分成两个队列:
宏任务队列
js外部的队列,也有人称之为外部队列,是浏览器协调各项任务的队列,标准文件中称之为 Task Queue。
浏览器中的事件源主要有:
- DOM 操作响应
- 用户交互 (鼠标、键盘)
- 网络请求 (Ajax 等)
- History API 操作
- 定时器 (setTimeout 等)
可以观察到,这些事件源可能很多。为了方便浏览器厂商优化, HTML 标准中明确指出一个事件循环有一个或多个宏任务队列, 每一个外部事件源都有一个对应的外部队列。不同事件源的队列可以有不不同的优先级(例如在网络事件和用户交互之间,浏览器可以优先处理鼠标行为,从 而让用户感觉更加流畅)。
微任务队列
js语言内部的事件队列,没有明确的规定,通常认为有以下几种
- Promise 的成功 (.then) 与失败 (.catch)
- MutationObserver
- Object.observe (已废弃)
既然已经知道宏任务、微任务队列是什么了,那我们来看一下事件循环产生的结果从而倒推它到底是怎么循环的:
console.log('1 script start');setTimeout(function() { console.log('2 setTimeout');}, 0);Promise.resolve().then(function() { console.log('3 promise1');}).then(function() { console.log('4 promise2');});console.log('5 script end');
- 从任务队列中取出一个宏任务并执行。
- 检查微任务队列,执行并清空微任务队列,如果在微任务的执行中又加入了新的微任务,也会在这一步一起执行。
html案例
<html><body><pre id="main"></pre></body><script>const main = document.querySelector('#main'); const callback = (i, fn) => () => {main.innerText += fn(i);};let i = 1;while(i++ < 10) {setTimeout(callback(i, (i) => '\n' + i + '<'))}while(i++ < 300) {Promise.resolve().then(callback(i, (i) => i +','))}console.log(i)main.innerText += '[end ' + i + ' ]\n'window.requestAnimationFrame(()=>{console.log(main.innerText,'requestAnimationFrame');});setTimeout(()=>{console.log(main.innerText);})</script></html>
按我个人的理解就是只有微任务全部做完,才算当前的任务完成,任务完成后浏览器会按照自己的逻辑再决定执行哪一个宏任务。

若有收获,就点个赞吧
0 人点赞
