- 1. 解压程序
- 2.修改Spark1.6 配置文件
- Alternate conf dir. (Default: ${SPARK_HOME}/conf)
- Where log files are stored.(Default:${SPARK_HOME}/logs)
- Where the pid file is stored. (Default: /tmp)
- The java implementation to use.
- Memory for Master, Worker and history server (default: 1024MB)
- A string representing this instance of spark.(Default: $USER)
- The scheduling priority for daemons. (Default: 0)
- 新增需要的目录
- 复制 hadoop 配置文件到 spark 配置文件目录
- Alternate conf dir. (Default: ${SPARK_HOME}/conf)
- Where log files are stored.(Default:${SPARK_HOME}/logs)
- Where the pid file is stored. (Default: /tmp)
- The java implementation to use.
- Memory for Master, Worker and history server (default: 1024MB)
- A string representing this instance of spark.(Default: $USER)
- The scheduling priority for daemons. (Default: 0)
- 新增需要的目录
- 复制 hadoop 配置文件到 spark 配置文件目录
Spark 程序启动模式主要是三种:本地模式、集群模式、yarn模式。
我们通常使用 yarn 模式。因此集群模式需要的 master/slave 参数都不需要配置了。
所以后台的服务,只需要启动 history server ,可用通过 Spark UI 查看历史执行日志。
1. 解压程序
[hadoop@bigdata1 package]$ spark-1.6.2-bin-hadoop2.3.tgz [hadoop@bigdata1 package]$ tar -xzvf spark-2.2.2-bin-hadoop2.6.tgz [hadoop@bigdata1 package]$ mv spark-1.6.2-bin-hadoop2.3 ../spark162 [hadoop@bigdata1 package]$ mv spark-2.2.2-bin-hadoop2.6 ../spark222 [hadoop@bigdata1 package]$
2.修改Spark1.6 配置文件
[hadoop@bigdata1 conf]$ pwd /home/hadoop/spark162/conf [hadoop@bigdata1 conf]$ mv spark-env.sh.template spark-env.sh [hadoop@bigdata1 conf]$ mv spark-defaults.conf.template spark-defaults.conf [hadoop@bigdata1 conf]$
spark-env.sh
Alternate conf dir. (Default: ${SPARK_HOME}/conf)
export SPARK_CONF_DIR=/home/hadoop/spark162/conf
Where log files are stored.(Default:${SPARK_HOME}/logs)
export SPARK_LOG_DIR=/home/hadoop/spark162/logs
Where the pid file is stored. (Default: /tmp)
export SPARK_PID_DIR=/home/hadoop/spark162/pid
The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64
Memory for Master, Worker and history server (default: 1024MB)
export SPARK_DAEMON_MEMORY=1024m
A string representing this instance of spark.(Default: $USER)
SPARK_IDENT_STRING=$USER
The scheduling priority for daemons. (Default: 0)
SPARK_NICENESS=0
spark-defaults.conf
重点需要修改的是 history 相关的参数,比如服务主机地址、端口、日志存储hdfs位置
spark.yarn.historyServer.address=bigdata1:18080 spark.eventLog.enabled true spark.eventLog.compress true spark.history.ui.port 18080 spark.history.fs.update.interval 5
spark.eventLog.dir hdfs://bigdata1:8020/logs/spark1-history spark.history.fs.logDirectory hdfs://bigdata1:8020/logs/spark1-history
新增需要的目录、拷贝 hadop 配置文件
新增需要的目录
[hadoop@bigdata1 conf]$ mkdir /home/hadoop/spark162/logs [hadoop@bigdata1 conf]$ mkdir /home/hadoop/spark162/pid [hadoop@bigdata1 conf]$ [hadoop@bigdata1 conf]$ hadoop fs -mkdir hdfs://bigdata1:8020/logs [hadoop@bigdata1 conf]$ hadoop fs -mkdir hdfs://bigdata1:8020/logs/spark1-history [hadoop@bigdata1 conf]$
复制 hadoop 配置文件到 spark 配置文件目录
[hadoop@bigdata1 conf]$ pwd /home/hadoop/spark162/conf [hadoop@bigdata1 conf]$ cp /home/hadoop/hadoop260/etc/hadoop/core-site.xml ./ [hadoop@bigdata1 conf]$ cp /home/hadoop/hadoop260/etc/hadoop/hdfs-site.xml ./
[hadoop@bigdata1 conf]$ cp /home/hadoop/hadoop260/etc/hadoop/yarn-site.xml ./
[hadoop@bigdata1 conf]$
3.修改Spark2.2 配置文件
[hadoop@bigdata1 conf]$ cd /home/hadoop/spark222/conf [hadoop@bigdata1 conf]$ ls -lrt total 32 -rwxr-xr-x 1 hadoop hadoop 3764 Jun 27 2018 spark-env.sh.template -rw-r—r— 1 hadoop hadoop 1292 Jun 27 2018 spark-defaults.conf.template -rw-r—r— 1 hadoop hadoop 865 Jun 27 2018 slaves.template -rw-r—r— 1 hadoop hadoop 7313 Jun 27 2018 metrics.properties.template -rw-r—r— 1 hadoop hadoop 2025 Jun 27 2018 log4j.properties.template -rw-r—r— 1 hadoop hadoop 1105 Jun 27 2018 fairscheduler.xml.template -rw-r—r— 1 hadoop hadoop 996 Jun 27 2018 docker.properties.template [hadoop@bigdata1 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@bigdata1 conf]$ cp spark-defaults.conf.template spark-defaults.conf [hadoop@bigdata1 conf]$
spark-env.sh
Alternate conf dir. (Default: ${SPARK_HOME}/conf)
export SPARK_CONF_DIR=${SPARK_CONF_DIR:-/home/hadoop/spark222/conf}
Where log files are stored.(Default:${SPARK_HOME}/logs)
export SPARK_LOG_DIR=/home/hadoop/spark222/logs
Where the pid file is stored. (Default: /tmp)
export SPARK_PID_DIR=/home/hadoop/spark222/pid
The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64
Memory for Master, Worker and history server (default: 1024MB)
export SPARK_DAEMON_MEMORY=1024m
A string representing this instance of spark.(Default: $USER)
SPARK_IDENT_STRING=$USER
The scheduling priority for daemons. (Default: 0)
SPARK_NICENESS=0
spark-defaults.conf
重点需要修改的是 history 相关的参数,比如服务主机地址、端口、日志存储hdfs位置
spark.yarn.historyServer.address=bigdata1:18082 spark.eventLog.enabled true spark.eventLog.compress true spark.history.ui.port 18082 spark.history.fs.update.interval 5
spark.eventLog.dir hdfs://bigdata1:8020/logs/spark2-history spark.history.fs.logDirectory hdfs://bigdata1:8020/logs/spark2-history
新增需要的目录、拷贝 hadop 配置文件
新增需要的目录
[hadoop@bigdata1 conf]$ mkdir /home/hadoop/spark222/logs [hadoop@bigdata1 conf]$ mkdir /home/hadoop/spark222/pid [hadoop@bigdata1 conf]$ hadoop fs -mkdir hdfs://bigdata1:8020/logs/spark2-history [hadoop@bigdata1 conf]$
复制 hadoop 配置文件到 spark 配置文件目录
[hadoop@bigdata1 conf]$ pwd /home/hadoop/spark222/conf [hadoop@bigdata1 conf]$ cp /home/hadoop/hadoop260/etc/hadoop/core-site.xml ./ [hadoop@bigdata1 conf]$ cp /home/hadoop/hadoop260/etc/hadoop/hdfs-site.xml ./
[hadoop@bigdata1 conf]$ cp /home/hadoop/hadoop260/etc/hadoop/yarn-site.xml ./
[hadoop@bigdata1 conf]$
4.复制 spark 文件到所有节点,并启动 history server
[hadoop@bigdata1 conf]$ scp -r /home/hadoop/spark162 hadoop@bigdata2:/home/hadoop/ [hadoop@bigdata1 conf]$ scp -r /home/hadoop/spark222 hadoop@bigdata2:/home/hadoop/ [hadoop@bigdata1 conf]$ /home/hadoop/spark222/sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /home/hadoop/spark222/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-bigdata1.out [hadoop@bigdata1 conf]$ /home/hadoop/spark162/sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /home/hadoop/spark162/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-bigdata1.out [hadoop@bigdata1 conf]$ jps 22400 HistoryServer 22322 HistoryServer 21202 NameNode 28098 NodeManager 21431 DataNode 21609 SecondaryNameNode 27817 ResourceManager 22479 Jps [hadoop@bigdata1 conf]$
5.使用样例
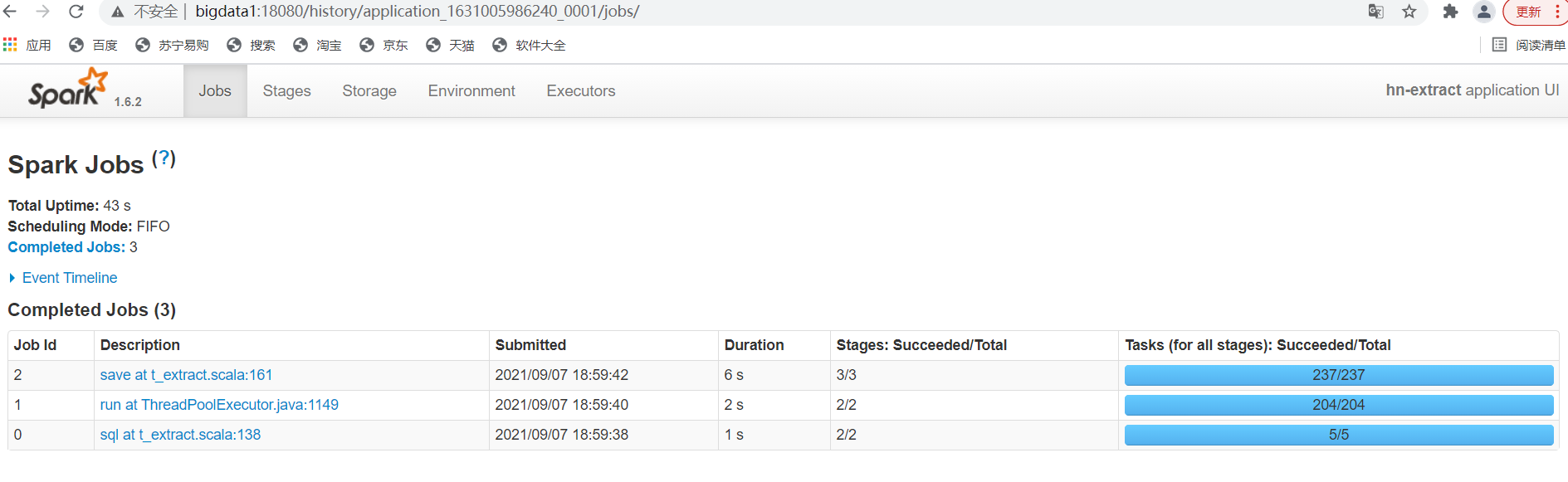
Spark 1.6.2 UI
http://bigdata1:18080
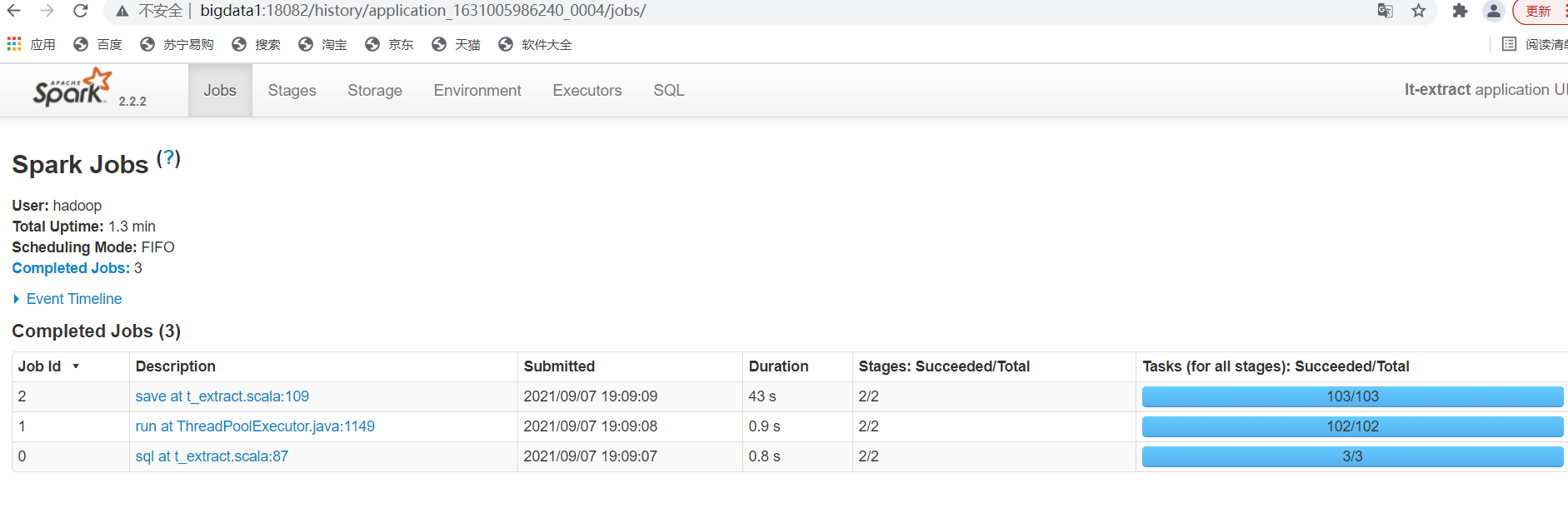
Spark 2.2.2 UI
http://bigdata1:18082
/home/hadoop/spark162/bin/spark-submit \ —master yarn \ —class com.pixel.dpi.textract \ —deploy-mode client \ —num-executors 3 \ —driver-memory 2g \ —executor-memory 4g \ —executor-cores 2 \ —conf spark.storage.memoryFraction=0.1 \ —conf spark.shuffle.memoryFraction=0.7 \ —driver-java-options “-Xss6m” \ —queue default \ —name hn-extract \ dpi-spark-hn-1.0.jar ${day} ${paramDir} ${outputDir} ${sourceDir} ${imeiDir} 30 > ./logs/start${day}_extract.log 2>&1
/home/hadoop/spark222/sbin/spark-submit \ —master yarn \ —class com.pixel.dpi.t_extract \ —deploy-mode client \ —num-executors 2 \ —driver-memory 3g \ —executor-memory 6g \ —executor-cores 2 \ —conf spark.sql.shuffle.partitions=100 \ —driver-java-options “-Xss6m” \ —queue ${queueName} \ —name lt-extract \ ../jar/ubd_zh_shangnie_label_03-1.0.jar ${day} ${paramDir}


若有收获,就点个赞吧
0 人点赞
